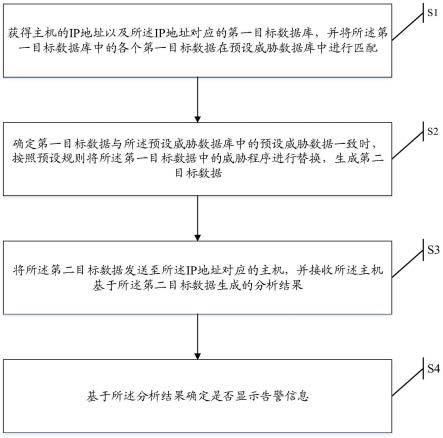
1.本发明属于文本挖掘技术领域,具体涉及一种基于最优运输的动态主题质量评价方法。
背景技术:
2.随着文本数据的大量涌现,主题模型已经成为文本分析的主要研究方法。主题模型作为一种文本内容的概率生成式模型,能够较好地解决词汇、主题、文本之间的关联问题。目前最常用的是潜在狄利克雷分布(lda)主题模型,它属于词袋模型,且仅分析静态主题。对于一些文档,比如:新闻或者科学期刊等,它们随着时间的推移而发展,所以出现了动态主题模型。动态主题模型研究文档集合随着时间的推移而演变,新主题出现,旧主题衰落,对文本分析有着关键的影响。大多数的文本数据都呈现出随时间演化的特征,因此,提高文本主题挖掘以及动态演化趋势的准确性是非常有必要的。
3.对于主题演化研究基本都是从两个方面出发:一方面是在每一个时间点上建立主题模型进行演化;另一方面是随时间变化对主题内容进行研究。显然后者考虑主题的演化更具有合理性。但主题的评价是个关键难题。
4.目前对于主题模型的评价主要集中在每一主题下的词是否能集中表达同一个主题。使用最广泛的方法是主题一致性,主要采用点互信息(pmi)方法来衡量一个主题内的词是否是一致的。也有一部分指标来评价各主题之间的距离,大多是用相似性度量指标来计算的。对于文本数据来说,相似性度量指标有一个缺点就是计算的文本距离不足以表达语义之间的距离。
技术实现要素:
5.针对目前文本主题挖掘以及动态演化趋势准确性的问题,本发明提供了一种基于最优运输的动态主题质量评价方法。
6.结合主题一致性和最优运输理论,使用(ot距离)来计算主题转移距离,用来评估在整个演化过程中的主题相关性;同时计算每一个主题下的主题一致性,用来评价整个模型的可解释性。最后结合两个指标提出一种新的动态主题质量评价方法来评价动态模型的演化效果。
7.为了达到上述目的,本发明采用了下列技术方案:
8.一种基于最优运输的动态主题质量评价方法,包括以下步骤:
9.步骤1,对每篇文本进行预处理;
10.步骤2,通过word2vec模型对步骤1预处理后文本中的词进行训练,得到词嵌入矩阵ρ;
11.步骤3,然后使用欧氏距离的计算方法对得到的词嵌入矩阵ρ求内积,得到成本矩阵c,即:c=euclidean(ρ);
12.步骤4,确定主题个数;
13.步骤4.1,采用多维尺度法进行初步的主题个数确定;
14.步骤4.2,通过困惑度指标的大小确定最终的主题个数;
15.步骤5,建立动态主题模型和动态嵌入式主题模型;
16.步骤5.1:建立动态主题模型(dynamic topic models,dtm):这个模型是通过主题随时间的变化来分析时间序列的语料库。
17.步骤5.1.1,对每个文档d生成主题比例
18.其中,θd表示每个文档d的主题比例,它服从均值为方差-协方差矩阵为a2i的渐近正态分布,θd的先验取决于文档d的时间戳;ln表示渐近正态分布,是一个潜在的变量,它控制着在t时刻文档d对主题比例的先验平均值,t∈{1,2,
…
,t}:t表示时刻,t表示时刻个数;a表示模型的超参数;i表示单位矩阵;
19.步骤5.1.2,对于文档d中的第n个词生成主题分配和生成词;
20.z
dn
~cat(θd)
[0021][0022]
其中,z
dn
表示文档d中的第n个词的主题分配,cat(
·
)表示分类分布;w
dn
表示文档d的第n个词,表示在t时刻文档d中的词在主题z
dn
上的分布比例;
[0023]
步骤5.1.3,将主题在时间上的演化通过马尔科夫链表示:
[0024][0025][0026]
η
t
|η
t 1
~n(η
t 1
,δ2i);
[0027]
其中,表示转换后的主题,r表示实数向量空间,v表示表示维数,将映射到softmax函数上,得到了主题n(
·
)表示正态分布;超参数σ和δ控制了马尔可夫链的光滑度;
[0028]
步骤5.2:建立动态嵌入式主题模型(d-etm),d-etm是一个动态的主题模型,使用的是嵌入表示的单词和主题。
[0029]
步骤5.2.1,生成初始的主题嵌入和主题比例均值:
[0030][0031]
η0~n(0,i)
[0032]
其中,表示0时刻的主题k的嵌入,它是单词语义空间中第k个主题的分布式表示,它服从均值为0,方差-协方差矩阵为单位阵的正态分布;η0为初始的主题比例均值,它服从均值为0,方差-协方差矩阵为单位阵的正态分布;
[0033]
步骤5.2.2,对于时刻t生成主题嵌入和主题比例均值:
[0034][0035]
η
t
~n(η
t-1
,δ2i);
[0036]
其中,表示t时刻的主题k的嵌入,它服从均值为方差-协方差矩阵为γ2i的正态分布,γ2表示高斯噪声的方差;η
t
表示t时刻的主题比例均值,它服从均值为η
t-1
,方差-协方差矩阵为δ2i的正态分布;
[0037]
步骤5.2.3,对于每篇文档d生成主题比例其中,θd的先验依赖于一个潜在变量td是文档d的时间戳;
[0038]
步骤5.2.4,对于每篇文档中的词n生成主题分配和生成词;
[0039]zdn
~cat(θd)
[0040][0041]
其中,w
dn
表示文档d的第n个词,它服从参数为的分类分布,表示在t时刻文档d的主题z
dn
的嵌入,ρ表示词的嵌入表示;
[0042]
步骤6,计算不同时刻主题之间的转移距离;
[0043]
设x={x1,
…
,xn}和y={y1,
…
,ym}是一组度量空间中的两组点,x1,
…
,xn表示x的坐标,y1,
…
,ym表示y的坐标,表示n个元素上的概率,表示m个元素上的概率,p,q是两个在x,y上的离散的概率分布,即p∈δn,q∈δm,所以有p,q之间的1-wasserstein距离为:
[0044][0045]
其中,w1表示1-wasserstein距离,c表示的是成本矩阵,c
ij
=l(xi,yj)表示距离,通过表达式中的约束,γ表示为了匹配p,q而得到的传输矩阵;
[0046]
计算主题转移距离:
[0047][0048][0049]
其中,表示的是在t时刻第k个主题在词上分布的第i个分量。
[0050]
步骤7,通过遍历所有主题,计算出所有主题的演化距离,通过归一化并求平均,即:
[0051][0052]
其中,s表示演化距离,即主题k在t时刻到t 1时刻的转移距离;越小代表同一个主题在前后两个时刻的演化过程中所要转移的距离越小也就越相关,即主题的演化效果越好。k表示主题个数,k表示主题,t表示时刻个数,t表示时刻,表示归一化后的值,β表示在t时刻词在主题k上的分布比例;
[0053]
步骤8,计算主题一致性,主题一致性越高,同一个主题下的词相关性越高,主题所表达的意思越集中,这个主题的解释性就越好。表示为:
[0054][0055][0056]
其中topic-coherence表示主题一致性,k表示主题个数,n表示选取的每个主题下的前n个词,c表示成本矩阵,f表示与的函数,表示第k个主题的第i个词,表示第k个主题的第j个词;p(wi,wj)表示词wi和wj之间的点互信息;
[0057]
步骤9,将两种指标相结合来综合评价主题模型的质量,表示为:
[0058][0059]
topic quality表示主题模型质量,这个值越小,说明这个模型的质量越好。
[0060]
与现有技术相比本发明具有以下优点:
[0061]
本发明方法结合主题一致性和最优运输理论,使用最优运输距离(ot距离)来计算主题转移距离,其能够观察到主题在随时间演化的过程产生了多大的转移,即可以观察到主题随时间的变化过程,相比于用余弦相似度的方法计算主题相似度,本文使用ot距离的方式计算更能提现主题的语义变化。同时,计算每一个主题下的主题一致性,可以看出每一个主题内部的聚集性,最后结合两个指标来共同评价一个动态主题模型,相比于单个的评价指标来说,更能体现模型的整体性。
附图说明
[0062]
图1为d-etm的图形示意图;
[0063]
图2为多维尺度分析图;
[0064]
图3为困惑度随主题数变化示意图;
[0065]
图4为dtm(左)和d-etm(右)转移距离的热点图。
具体实施方式
[0066]
实施例1
[0067]
一种基于最优运输的动态主题质量评价方法,包括以下步骤:
[0068]
步骤1,对每篇文本进行预处理;
[0069]
本实施例选择的是搜狐新闻网中一个月的新闻数据,这里选取新闻数量总共是9000条。其中,随机选取这9000条数据中的85%作为训练集,10%作为测试集,剩下的5%作为验证集。对数据进行去停用词和分词的处理,采用python中的jieba分词的精确模型对新闻文本做分词处理。分词处理之后建立词汇表,去除出现次数小于20的词,得到最终的词汇表,总计8763个词。
[0070]
步骤2,通过word2vec模型对步骤1预处理后文本中的词进行训练,得到词嵌入矩阵ρ;
[0071]
步骤3,然后使用欧氏距离的计算方法对得到的词嵌入矩阵ρ求内积,得到成本矩阵c,即:c=euclidean(ρ)
[0072]
步骤4,确定主题个数。第一步,使用多维尺度法进行初步的主题个数确定,由于数据量过大,将原数据全部表示在图中会连接成一片,无法进行判断,于是就随机选择9000个数据中的百分之十进行可视化,通过观察图2中各个点的分布情况,我们可以大致将其分为15类作为初始的主题个数;第二步,通过困惑度指标的大小确定最终的主题个数,分别设置主题数为:10,11,12,13,14,15,16,17,18,并对每个主题数目下的测试集的困惑度进行比较,图3中可以看出,主题数目为13和17时,是两个困惑度比较低的点,为17时最低,但是在主题数从13到17的这个过程中,困惑度的值是先上升在下降的,这种情况的出现有可能造成过拟合,因此我们就选择第一个困惑度较低的点作为最终的主题数,也就是13。
[0073]
步骤5,建立动态主题模型和动态嵌入式主题模型;
[0074]
步骤5.1:建立动态主题模型:
[0075]
步骤5.1.1,对每个文档d生成主题比例
[0076]
其中,θd表示每个文档d的主题比例,θd的先验取决于文档d的时间戳;ln表示渐近正态分布,是一个潜在的变量,它控制着在t时刻文档d对主题比例的先验平均值,t∈{1,2,
…
,t}:t表示时刻,t表示时刻个数;a表示模型的超参数;i表示单位矩阵;
[0077]
步骤5.1.2,对于文档d中的第n个词生成主题分配和生成词;
[0078]zdn
~cat(θd)
[0079][0080]
其中,z
dn
表示文档d中的第n个词的主题分配,cat(
·
)表示分类分布;w
dn
表示文档d的第n个词,表示在t时刻文档d中的词在主题z
dn
上的分布比例;
[0081]
步骤5.1.3,将主题在时间上的演化通过马尔科夫链表示:
[0082][0083][0084]
η
t
|η
t 1
~n(η
t 1
,δ2i);
[0085]
其中,表示转换后的主题,r表示实数向量空间,v表示表示维数,将映射到softmax函数上,得到了主题n(
·
)表示正态分布;超参数σ和δ控制了马尔可夫链的光滑度;
[0086]
步骤5.2:建立动态嵌入式主题模型;
[0087]
步骤5.2.1,生成初始的主题嵌入和主题比例均值:
[0088][0089]
η0~n(0,i)
[0090]
其中,表示0时刻的主题k的嵌入,它是单词语义空间中第k个主题的分布式表示,它服从均值为0,方差-协方差矩阵为单位阵的正态分布;η0为初始的主题比例均值,它服从均值为0,方差-协方差矩阵为单位阵的正态分布;
[0091]
步骤5.2.2,对于时刻t生成主题嵌入和主题比例均值:
[0092]
k=1,
…
k;t=1,.....t;
[0093]
η
t
~n(η
t-1
,δ2i);
[0094]
其中,表示t时刻的主题k的嵌入,它服从均值为方差-协方差矩阵为γ2i的正态分布,γ2表示高斯噪声的方差;η
t
表示t时刻的主题比例均值,它服从均值为η
t-1
,方差-协方差矩阵为δ2i的正态分布;
[0095]
步骤5.2.3,对于每篇文档d生成主题比例其中,θd的先验依赖于一个潜在变量td是文档d的时间戳;
[0096]
步骤5.2.4,对于每篇文档中的词n生成主题分配和生成词;
[0097]zdn
~cat(θd)
[0098][0099]
其中,w
dn
表示文档d的第n个词,它服从参数为的分类分布,表示在t时刻文档d的主题z
dn
的嵌入,ρ表示词的嵌入表示;
[0100]
步骤6,计算不同时刻主题之间的转移距离;
[0101]
将两种动态主题模型拟合之后得到的主题-词在时间上的矩阵分别设为b1和b2,其中k是主题数,t是时间索引,v是单词数,其中β
(t)
代表是t时刻所得到的
的主题-词的矩阵,代表在t时刻第k个主题在词上的分布。最后就可以根据以上的变量计算主题之间的ot距离。在这里,由于是计算不同时刻的主题之间的距离,所以在此称为转移距离。即:
[0102][0103]
其中,
[0104][0105]
表示的是在t时刻第k个主题在词上分布的第i个分量。
[0106]
步骤7,通过遍历所有的主题,计算出所有主题的演化距离,通过归一化并求平均,即:
[0107][0108]
其中表示归一化后的值,这个距离代表主题k在t时刻到t 1时刻的转移距离,越小代表同一个主题在前后两个时刻的演化过程中索要转移的距离越小也就越相关,越相关代表主题的演化效果也就越好。
[0109]
最终算出,dtm模型的主题演化率(主题转移距离)为0.0874,d-etm模型的主题演化率为0.0666;
[0110]
步骤8,计算主题一致性,表示为:
[0111][0112][0113]
其中topic-coherence表示主题一致性,k表示主题个数,n表示选取的每个主题下的前n个词,c表示成本矩阵,f表示与的函数,表示第k个主题的第i个词,表示第k个主题的第j个词;p(wi,wj)表示词wi和wj之间的点互信息;
[0114]
最终算出,dtm模型的主题一致性为0.2137,d-etm模型的主题一致性为0.2523;
[0115]
步骤9,将两种指标相结合来综合评价主题模型的质量,表示为:
[0116]
[0117]
最终算出,dtm模型的动态主题质量为2.4451,d-etm模型的动态主题质量为3.7883;
[0118]
表1动态主题模型评价指标表
[0119]
模型主题演化率主题一致性动态演化质量dtm0.08740.21370.4089d-etm0.06660.25230.2630
[0120]
从表1的结果中,我们可以看出,无论是在主题演化率还是主题一致性方面,改进后通过词嵌入的方法来建立动态主题模型的效果高于使用传统的方法建立动态主题模型的效果,尤其是在主题演化率这个指标中,d-etm的效果明显好于传统的dtm的效果。
[0121]
对两个模型的动态过程中的转移距离绘制热点图,直观的去比较演化效果。转移距离越大,说明前一个主题向后一个主题转移的相关性越小,演化效果就相对差一点,在图中所展示出的颜色越深。
[0122]
如图4所示,左边是dtm转移距离的热点图,右边是d-etm转移距离的热点图。很显然,总体来说dtm所绘制的热点图比d-etm的颜色更深一点。再分别看两个图,dtm的主题在转移过程中,有几次非常的深,达到了红色,说明在红色的这个演化过程中,主题相关性小,语义距离大。而有的颜色是先浅后深再浅,说明主题演化的过程不够稳定。d-etm的主题在转移过程中以浅色居多,说明同一个主题内的相关性强。且整体的演化过程没有强烈的颜色变化,相比于dtm来说,主题演化过程相对稳定一点。
[0123]
结果显示,将本方法应用在d-etm和dtm两个模型中时,d-etm在可视化图和定量分析的结果都表现出更好的结果,这和dieng在所得到的结果是相一致的。d-etm的每个主题在主题演化的过程中,主题转移距离比dtm小,这就说明,相邻时刻下同一主题的相关性较大,语义距离更小。同时平均每个时刻的每一个主题下的主题一致性较高,主题内部的相关性很高。综合两个值来看,d-etm确实要比dtm的模型要好,证明本方法是符合实际的,而且更能捕捉主题转移过程中的语义信息。
[0124]
本发明说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。