1.本发明属于人工智能领域,尤其涉及一种基于马氏距离和对比学习的新意图数据识别方法。
背景技术:
2.随着人工智能技术的发展,任务型对话式智能助手产品开始涌现,如手机语音助手,电商智能客服,智能音箱等产品,极大方便了人们的生活。其中,意图识别(intent detection)是任务型对话系统的(task-oriented dialogue system)的重要模块之一,负责识别当前使用者的输入中包含的意图信息,并根据识别结果执行后续的动作。因此,意图识别的准确与否直接影响了后续步骤的执行情况和用户对系统的满意度。然而,在真实的应用场景中,用户的输入的表述可能会包含一些全新的意图,这些意图从未被系统所见过,超出了系统的识别能力,被称为新意图。正确识别新意图能够防止系统执行错误的操作并给出不相关回复,从而提高用户的使用体验。
3.目前主流的意图识别技术方案是将新意图识别任务转化为文本分类任务,首先利用已意图样本和对应的标签训练一个文本多分类模型,并将通过文本分类模型得到的置信度分数作为新意图识别任务的打分函数,如果样本置信度分数低于某个阈值,则会被视为新意图样本。
4.【专利一】cn111382270a基于文本分类器的意图识别方法、装置、设备及存储介质。
5.该发明使用文本分类模型进行意图分类,同时判断文本分类模型得到的置信度分数是否大于阈值来判断当前意图是否为新意图。
6.【论文二】out-of-domain detection for natural language understanding in dialog systems.
7.该论文通过生成负样本并引入文本分类模型的训练过程中,从而增强模型对新意图的识别能力。
8.【论文三】modeling discriminative representations for out-of-domain detection with supervised contrastive learning.
9.该论文引入样本和其他类别样本的对比学习,增强文本分类模型的分类能力。
10.专利一通过文本分类模型获取置信度分数来作为新意图打分函数,并设定阈值来检测新意图。但是,基于神经网络的文本分类模型通常会面临过自信(over confident)的问题,即输入样本即使不属于已知意图,但某些特征与已知意图相似,导致新意图样本仍然以较高的置信度分类到错误的类别。这是由于神经网络训练集的有限性导致的,分类模型会利用分类所需的尽可能少的特征进行分类,而忽略其他一些重要的类别特征。由于分类模型从未见过新意图样本,因此很难捕获新意图的重要特征,容易把它分类到相似的意图类别里(如播放音乐和播放电影)。
11.针对这个问题,论文二在模型训练过程中引入负样本来增强模型对类别特征的捕获能力。模型通过gan技术来生成伪造的负样本并引入训练过程中,要求模型对负样本预测
的熵尽可能大,即模型得到的置信度分数尽可能小,从而缓解模型过自信的问题。然而使用gan生成的负样本难以保证质量,即是否为真正的新意图样本。论文三在分类模型的训练过程中引入了对比学习来获取更有区分度的特征,它将统一类别的样本作为正样本,其他类别的样本作为负样本进行对比学习,从而捕获类别之间更有区分度特征。然而,这种特征的捕获仍局限于区分已知意图类别的样本之间的不同特征,而不能捕获到完整的样本特征来区分和已知意图比较接近的新意图样本。
技术实现要素:
12.发明目的:本发明要解决的技术问题是如何学习到更完整的样本特征来区分已知意图和新意图,并在计算打分函数尽可能避免特征损失,从而使模型对新意图样本有更好的识别能力,尤其是与已知意图样本非常相似的新意图样本。
13.本发明具体提供了一种基于马氏距离和对比学习的新意图数据识别方法,包括以下步骤:、
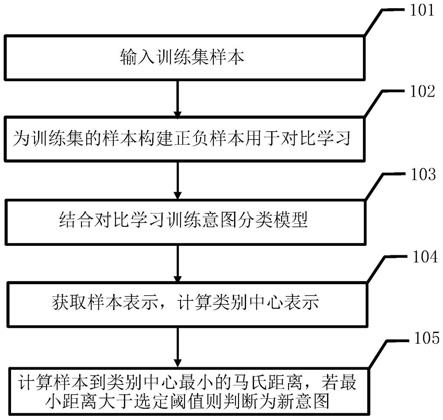
14.步骤1,输入训练集中的所有样本和标注的标签;
15.步骤2,为训练集中的已知意图样本构建正样本和负样本,用于对比学习训练;
16.步骤3,结合对比学习训练意图分类模型,通过分类模型来获取样本表示;
17.步骤4,计算类别中心;
18.步骤5,计算样本到类别中心的最小马氏距离,并判定是否为新意图样本。
19.步骤2包括:
20.步骤2-1,识别所有输入样本的槽位,获取样本拥有的槽位类型;
21.步骤2-2,将训练集中拥有相同槽位类型的样本进行两两配对,即样本x1=t1(s1=v1,s2=v2),样本x2=t2(s1=v3,s2=v4),其中,si代表第i个槽位类型,vi代表第i个槽位值,ti代表第i个句子模版;
22.步骤2-3,为样本x1构造正样本为样本x2构造正样本为样本x1构造负样本为样本x2构造负样本
23.步骤3包括:
24.步骤3-1,输入原始训练集d={(x,y)}和对比学习训练集d
′
=(x,x
,x-);
25.步骤3-2,意图识别模型进行前向计算;
26.步骤3-3,计算样本的预测概率分布与真实标签之间的交叉熵ce;
27.步骤3-4,计算损失函数值对于每个模型参数的梯度,使用反向传播算法更新模型参数;
28.步骤3-5,使用验证集评估模型性能;
29.步骤3-6,判断模型性能是否提升,如果有提升则返回步骤3-2继续迭代训练,否则执行步骤3-7;
30.步骤3-7,结束训练模型。
31.步骤3-1包括:原始训练集d用于分类任务的训练,x={w1,w2,...,wn}为原始样本,包含了n个单词w1,w2,...,wn,y为对应的意图标签;
32.对比学习训练集d
‘
用于对比学习的训练,x
,x-分别为原始样本x对应的正、负样本;其中,意图样本标签进行独热编码,记为集合其中m为已知意图数目,yi表示第i个意图标签,中当前正样本对应意图标签的位置为1,其余位置值为0;输入的原始样本按照4∶1的比例划分为训练集和验证集,训练集输入模型用于训练;
33.步骤3-2包括:获取单词wi的词嵌入ei,即样本x
′
={e1,e2,...,en};
34.使用门控循环单元gru(gate recurrent unit)网络编码输入原始样本x
′
,即将每个词嵌入输入一个门控单元中,得到每个词的输出,为每个词状态的隐层表示,即{h1,h2,..,hn}=gru(e1,e2,...,en),其中hi表示第i个词ei的输出,gru()代表将一系列词嵌入输入门控循环单元网络中,即h
t
=z
t
⊙ht-1
(1-z
t
)
⊙
g(e
t
,h
t-1
,θ),z
t
∈[0,1]为更新门,z
t
=σ(wzx
t
u
zht-1
bz),wz,uz和bz为可训练参数;函数g(e
t
,h
t-1
,θ)=tanh(w
het
uh(r
t
·ht-1
) bh),其中wh,uh和bh为可训练参数;r
t
∈[0,1]为重置门,r
t
=σ(w
ret
urht-1
br),其中wr,ur和br为可训练参数;
[0035]
取所有状态的隐层表示的均值作为样本的表示
[0036]
将样本的特征空间做l2正则限制,限制样本模长为α,即得到原始样本表示h
x
和正负样本表示将原始样本表示h
x
输入线性层和softmax层,得到标签分布p={p1,p2,...,pm},其中pm表示模型将样本预测为第m个意图标签ym的概率,m为意图的数目;
[0037]
步骤3-3包括:采用如下公式计算样本的预测概率分布与真实标签之间的交叉熵
[0038]
计算样本x和正负样本x
、x-之间的三元组损失tl(x,x
,x-)=max(d(x,x
)-d(x,x-) m,0),其中样本x到样本y的距离其中h
x
=(a1,a2,...,ad),hy=(b1,b1,...,bd),d为h的维度,m为超参数;最终模型的损失函数为l=ce λ
·
tl,其中λ为超参数;
[0039]
步骤4包括:类别i的类别中心表示为其中,nc为训练集中类别i的样本数目,为样本xi的的句子表示。
[0040]
步骤4包括:计算样本到类别中心的最小马氏距离:首先计算训练集的协方差其中c代表类别标签;
[0041]
计算样本x到类别中心的最小马氏距离其中minc代表使得马氏距离最小的类别c。如果m(x)大于选定阈值,则判断样本x为新意图样本。
[0042]
本发明在分类模型的训练过程中引入对比学习来获取更完整的样本特征,并基于样本的特征向量使用马氏距离来作为打分函数,来防止特征经过分类层之后有所损失,有
助于模型提升识别新意图样本的能力。
[0043]
有益效果:
[0044]
从技术层面来说,本发明的技术方案(1)将对比学习引入模型的训练,能够学习到更完整的特征。(2)使用马氏距离作为打分函数,避免学习到的特征经过分类层产生损失。
[0045]
从应用层面来说,本发明技术方案(1)利用数据集自带的槽位类型信息自动构造出正负样本用于特征学习。(2)经过对比学习的模型能够学习到更完整的特征,对于与已知意图相似的新意图有更好的区分度,能够避免系统输出错误,优化用户体验。
附图说明
[0046]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
[0047]
图1是本发明流程图。
[0048]
图2是正负样本构建流程图。
[0049]
图3是模型训练流程图。
具体实施方式
[0050]
如图1所示,本发明提供了一种基于马氏距离和对比学习的新意图数据识别方法,包括:
[0051]
步骤1,输入训练集中的所有样本和人工标注的标签。有训练新意图模型需要事先确定好意图标签体系,依据体系里的语料和标签作为已知意图,用于模型学习。本发明采用snips数据集,是一个语音助手语料转化为文字后得到的数据集。共有7个类别,分别为“播放音乐”,“询问天气”,“添加到播放列表”,“书籍评分”,“预定餐厅”,“搜索创造力的作品”以及“搜索电影信息”。特别地,在这里将“搜索创造力的作品”以及“添加到播放列表”视作新意图样本,这是一组比较有挑战性的设定。该数据对于每条数据都标注了槽位类型,如歌手名字,歌曲名称。
[0052]
步骤2,为训练集中的已知意图样本构建正样本和负样本用于对比学习训练。具体的正负样本构造流程如图2所示:
[0053]
步骤2-1,识别所有输入样本的槽位,获取样本的拥有的槽位类型。对于样本“你能播放周杰伦的音乐菊花台吗”,它有两个槽位,即“你能播放【歌手名】的音乐【歌名】吗”,槽位【歌手名】的值为周杰伦,槽位【歌名】的值为菊花台。
[0054]
步骤2-2,将训练集中拥有相同槽位类型的样本进行两两配对,即样本x1=t1(s1=v1,s2=v2),x2=t2(s1=v3,s2=v4)。其中,si代表槽位类型,vi代表槽位值,pi代表句子模式(除去槽位值以外的部分)。例如,样本1(你能播放【周杰伦】的音乐【菊花台】吗),样本2(播放【林俊杰】的音乐【江南】)为一组样本对,他们都拥有相同的槽位类型:歌手名,歌名。拥有相同的槽位类型的样本往往有着语义相近的句子模式,将他们的槽位值替换则会得到新的样本。
[0055]
步骤2-3,为了让模型关注到完整的语义信息,把表述不同,但拥有相同语义信息的样本视为正样本。如果两个样本的槽位值相同,句子模式相近,则认为它们的语义相近。即为样本x1构造正样本为样本x2构造正样本
如果两个样本槽位值不同,即使句子模式一致,也代表了不同的语义。即为样本x1构造负样本样本x2构造负样本例如,对于样本“你能播放【周杰伦】的音乐【菊花台】吗”而言,它的正样本为“播放【周杰伦】的音乐【菊花台】”,负样本为“你能播放【林俊杰】的音乐【江南】吗”。通过让模型区分原样本和负样本的区别,能够关注到更完整的语义信息。表1展示了一例用于对比学习的样本。
[0056]
表1
[0057][0058][0059]
步骤3,结合对比学习训练意图分类模型,通过分类模型来获取样本表示。具体训练流程如图3所示:
[0060]
步骤3-1,输入原始样本x=w1,w2,...,wn和对应标签y用于分类模型的训练,输入原始样本x和对应的正负样本x
,x-用于对比学习的训练。其中,意图样本标签进行独热编码,记为集合其中m为已知意图数目,yi表示第i个意图标签,y中当前正样本对应意图标签的位置为1,其余位置值为0。输入样本按4∶1划分为训练集和验证集,训练集输入模型用于训练,验证集待后续部分使用。
[0061]
步骤3-2,意图识别模型进行前向计算:首先获取单词wi的词嵌入ei,即样本x
′
={e1,e2,...,en};
[0062]
使用门控循环单元gru(gate recurrent unit)网络编码输入原始样本x
′
,即将每个词嵌入ei输入一个门控单元中,得到输出hi,为每个词状态的隐层表示,即{h1,h2,..,hn}=gru(e1,e2,...,en),其中gru()代表将一系列词嵌入输入门控循环单元网络中,即h
t
=z
t
⊙ht-1
(1-z
t
)
⊙
g(e
t
,h
t-1
,θ),z
t
∈[0,1]为更新门,z
t
=σ(wzx
t
u
zht-1
bz),wz,uz和bz为可训练参数;函数g(e
t
,h
t-1
,θ)=tanh(w
het
uh(r
t
·ht-1
) bh),其中wh,uh和bh为可训练参数;r
t
∈[0,1]为重置门,r
t
=σ(w
ret
u
rht-1
br),其中wr,ur和br为可训练参数。取所有状态的隐层表示的均值作为样本的表示
[0063]
将样本的特征空间做l2正则限制,限制样本模长为α,即得到原始样本表示h
x
和正负样本表示将原始样本表示h
x
输入线性层和softmax层,得到标签分布p={p1,p2,...,pm},其中pm表示模型将样本预测为第m个意图标签ym的概率,m为意图的数目;
[0064]
步骤3-3,计算样本的预测概率分布与真实标签之间的交叉熵(cross entropy),记为计算样本和正负样本之间的三元组损失(tripletloss),记为
tl(x,x
,x-)=max(d(x,x
)-d(x,x-) m,0),其中d(x,y)=||h
x-hy||2,为样本x到样本y的距离,m为超参数。最终模型的损失函数为l=ce λ
·
tl,其中λ为超参数。
[0065]
步骤3-4,计算损失函数值对于每个模型参数的梯度,使用反向传播算法更新模型参数。
[0066]
步骤3-5,使用验证集评估模型性能,这里评估模型的准确率。
[0067]
步骤3-6,判断模型性能是否提升,若有提升则返回步骤3-2继续迭代训练,否则执行步骤3-7。
[0068]
步骤3-7,结束训练模型。
[0069]
步骤4,获取样本表示h
x
,计算类别中心。类别i的类别中心表示为其中,nc为训练集中类别i的样本数目。
[0070]
步骤5,计算样本到类别中心的最小马氏距离。首先计算训练集的协方差,其中c代表类别标签。计算样本x到类别中心的最小马氏距离如果m(x)大于选定阈值,则判断为新意图样本。
[0071]
本实施例中,本发明在测试集上的实验结果如下表2所示:
[0072]
表2
[0073]
modelauroc(%)aupr(%)mah93.7684.64mah l2-norm96.5991.74mah l2-norm contrastive loss96.7392.31
[0074]
其中,mah指使用马氏距离作为打分函数并基于分类模型得到的结果,mah l2-norm指对特征空间做了l2正则限制后的结果,mah l2-norm contrastive loss指我们加上对比学习后的最终方案。其中,auroc(area under receiver operating characteristic curve)指接收者操作特征曲线下的面积,aupr(area under precision recall curve)指精确召回曲线下的面积。从实验结果可以看出,对特征空间做正则限制之后,马氏距离的效果有了较大的提升,在此之上对模型引入对比学习,效果有了进一步的提升。
[0075]
本发明提供了一种基于马氏距离和对比学习的新意图数据识别方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
