1.本发明涉及一种结合远程监督和有监督的关系分类方法。
背景技术:
2.伴随着互联网的高速发展,世界上每天都会出现大量的信息。为了更加高效地组织和利用这些信息,谷歌在2012年提出了知识图谱的概念。知识图谱能够将互联网上的信息、数据以及链接关系聚集为知识,使得信息资源更易于计算和理解。这些客观存在的知识通常以《头实体(head entity),关系(relation),尾实体(tail entity)》这样结构化的三元组形式存在于知识图谱中。作为知识图谱构建的关键技术,关系分类技术近几年来受到了学术界和工业界广泛的关注。关系分类旨在判断文本(句子或者文档)表达了目标实体对的何种关系。
3.目前关系分类技术主要有两条路线,基于有监督或者基于远程监督。基于有监督学习的关系分类技术精度较高,但其需要大量高质量的人工标注样本。这带来了标注成本高且标注时间较长的问题。为了解决数据缺乏的问题,远程监督的方法被提出。它可以用于自动标注大规模的训练数据。远程监督通过把知识库中的关系事实与文本中的实体对齐实现自动标注。但由于其假设过强,不可避免地引入了标注噪音的问题。为了发挥有监督和远程监督技术各自的优势,需要将这两项技术进行有效的结合。
4.【论文一】combining distant and direct supervision for neural relation extraction.
1.该论文提出了一种有效的神经网络模型,通过句子级别的有监督数据训练的二分类器来改善远程监督模型。该模型在多任务学习设置中对两种类型的监督进行联合训练,其中直接监督数据训练得到的二分类器向远程监督模型提供了注意力权重的监督信号,从而达到降噪的目的。
5.【论文二】dual supervision framework for relation extraction with distant supervision and human annotation.
2.6.该论文采用两个独立的预测网络分别使用有监督和远程监督的数据来训练,以防止因远程监督的错误标记而导致有监督模型的准确性下降。该论文提出了一个额外损失项,用于惩罚有监督模型和远程监督模型的分歧,通过该损失项使得有监督模型能够从远程监督的标签中学习。
7.【论文三】denoising relation extraction from document-level distant supervision.
3.8.该论文首先应用预去噪模块从所有文档中筛选出一些na实例。然后在文档级远程监督数据集上使用三个预训练任务预训练文档编码器。这三个预训练任务包括实体提及-实体的匹配、关系发现和事实对齐。最后,在人工标注的数据集上微调模型。
9.论文一通过有监督数据训练一个判断句子是否表达了关系的二分类器向远程监督模型提供注意力权重的监督信号,起到了降噪的作用,但是只使用有监督数据训练二分类器,没有充分利用有监督数据的关系标签。论文二使用了两个独立的网络来防止远程监
督数据噪声对有监督模型的影响,同时通过分歧惩罚使得有监督模型从远程监督标签中学习,但该方法忽视了从大量远程监督数据中学到的抽取特征的能力,未能充分利用远程监督数据。论文三设计了几个预训练任务在远程监督数据上预训练文档编码器,在降噪的同时提供了强大的特征抽取能力。但该方法设计的预训练任务只针对文档级别的关系分类,缺乏普适性。在降噪时未能利用有监督数据,降噪效果较为一般。
技术实现要素:
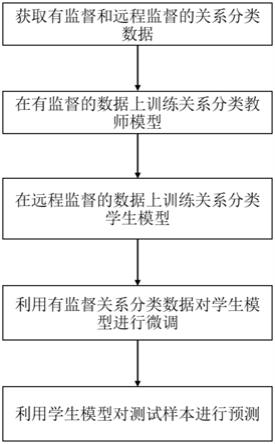
10.发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种结合远程监督和有监督的关系分类方法,包括以下步骤:
11.步骤1,获取关系分类文本数据,包括有监督的关系分类文本数据和远程监督的关系分类文本数据;
12.步骤2,在有监督的关系分类文本数据上训练关系分类教师模型;
13.步骤3,在远程监督的关系分类文本数据上训练关系分类学生模型,通过实体遮掩和蒸馏技术对远程监督数据进行降噪;
14.步骤4,在有监督的关系分类文本数据上微调步骤3训练得到的学生模型;
15.步骤5,使用步骤4训练好的教师模型进行关系预测。
16.步骤1包括:
17.步骤1-1,通过人工标注的方式获取有监督的关系分类文本数据;
18.步骤1-2,通过远程监督技术获取自动标注的关系分类文本数据。
19.步骤1-2包括:
20.步骤1-2-1,获取知识图谱中的三元组信息,三元组信息包含实体对和实体对之间的关系,构成三元组集合r={(h1,t1,r1),...,(hi,ti,ri),...,(hn,tn,rn)},其中,n为收集得到的三元组的数量,hi表示第i个三元组中的头实体,ri表示第i个三元组中的关系,ti表示第i个三元组中的尾实体;
21.步骤1-2-2,从互联网或者其他来源获取文本,构建非结构化的语料库d={(text1,h1,t1),...,(texti,hi,ti),...,(textm,hm,tm)},其中,m表示收集到的文本的数量,texti表示第i个文本;
22.步骤1-2-3,使用远程监督方法,对于文本语料库d中的每一个文本text,标记其中出现的头尾实体对(h,r)的关系,基于远程监督的假设进行标注:如果实体对在三元组r中出现,则标注为r中指示的关系,如果三元组没有在r中出现,则标注为没有关系;
23.远程监督的假设过强,没有考虑实体对所在的文本,因此得到的标注数据存在着大量的噪声;将通过远程监督标注得到的数据集记为大量的噪声;将通过远程监督标注得到的数据集记为其中,m表示远程监督标注样本的数量,表示远程监督得到的第i个标注样本的标签,以独热方式进行编码,标注的关系对应位置为1,其余位置为0。
24.步骤2包括:
25.步骤2-1,初始化教师模型的参数θ
t
;
26.步骤2-2,输入有监督的关系分类文本数据
其中,n表示有监督的样本数量,满足n<<m,即有监督的样本数量远小于远程监督的样本数量,texti表示第i个样本的文本,hi和ti表示第i个样本中的头实体和尾实体,表示第i个人工标注样本的标签,采用独热方式进行编码;
27.步骤2-3,教师模型进行前向计算:通过编码器编码输入的人工标注样本x
t
={w1,...,wi,...,h,...,t,...,wn},得到每个词token的表示e={e1,...,ei,...,eh,...,e
t
,...,en}。其中,wi表示上下文中的第i个单词,h和t分别表示头尾实体,ei代表经过编码器编码之后第i个单词的表示,eh和e
t
分别代表经过编码器编码之后头实体的表示和尾实体的表示;
28.步骤2-4,获取eh和e
t
,将它们输入双线性层,得到每个关系类别上的输出结果zi,计算公式为:zi=ehw
iet
。其中wi表示第i个关系类别对应的参数矩阵,i={1,2,
…
,c},c表示关系类别总数;再经过softmax函数得到每个关系上的预测概率:其中,exp代表指数函数,表示第i个关系的概率值;
29.步骤2-5,计算概率分布和人工标注的标签y
t
的交叉熵损失loss
t
::将交叉熵损失作为教师模型的预测损失;其中,为第i个关系的真实标签,表示教师模型在第i个关系上的预测概率;
30.步骤2-6,计算梯度,反向传播更新教师模型的参数θ
t
;
31.步骤2-7,经过迭代训练后,得到教师模型。
32.步骤3包括:
33.步骤3-1,初始化学生模型的参数θs;
34.步骤3-2,输入远程监督的关系分类文本数据;
35.步骤3-3,利用步骤2训练得到的教师模型对输入的远程监督标注样本x
ds
={w1,...,wi,h,...,t,...,wn}进行预测,得到每个关系上的输出结果{z1,...,zi,...,zc},zi表示教师模型在第i个关系上归一化前的预测结果;经过softmax函数计算得到每个关系上的概率值相比步骤2-4,多了一个参数t,用于表示蒸馏的温度。t越大产生的概率分布越平滑。这里计算得到的概率分布称为soft target;
36.步骤3-4,对输入的远程监督数据样本x
ds
中的实体部分进行随机遮掩,随机遮掩的变量m服从伯努利分布,遮掩的概率为p(m=1)=q,q是一个超参数,用于控制遮掩实体的比例,输入的远程监督数据样本表示为:
[0037][0038]
其中,[e1]和[e2]是两个特殊的符号,分别用来遮掩头实体和尾实体;实体遮掩可以使学生模型更加注重上下文信息,而不是简单地依赖实体进行判断,缓解模型对远程监督假设的偏好,从而提高学生模型的抗噪能力;
[0039]
步骤3-5,学生模型进行前向计算:通过编码器编码输入的样本,编码得到的结果表示为e:
[0040][0041]e[e1]
和e
[e2]
分别表示遮掩后的头、尾实体经过编码之后的表示,ei表示第i个单词经过编码器编码之后的表示;
[0042]
步骤3-6,获取3-5中的实体表示,当m=1时,取e
[e1]
和e
[e2]
;当m=0时,取eh和e
t
;将实体表示输入双线性层和softmax层,得到学生模型预测的概率分布ps;
[0043]
步骤3-7,计算概率分布ps和远程监督的标签y
ds
的交叉熵损失loss
ds
;
[0044]
步骤3-8,计算学生模型预测的概率分布和教师模型预测的概率分布之间的差异。
[0045]
步骤3-9,将步骤3-6和步骤3-7中的损失相加,作为学生模型最终的预测损失losss;
[0046]
步骤3-10,计算梯度,反向传播更新学生模型的参数θs;
[0047]
步骤3-11,经过迭代训练后,得到学生模型。
[0048]
步骤3-7包括:采用如下公式计算概率分布ps和远程监督的标签y
ds
的交叉熵损失loss
ds
:其中,为第i个关系的远程监督标签,表示学生模型在第i个关系上的预测概率。
[0049]
步骤3-8包括:选择kl(kullback-leibler divergence)作散度作为衡量方式,具体计算公式为:loss
kl
表示了学生模型和教师模型预测概率分布的kl散度值。该项损失利用教师模型的预测结果对学生模型进行指导,使得学生模型拟合教师模型的预测结果,从而达到降噪的目的;
[0050]
步骤3-9包括:losss计算公式为:losss=α*loss
ds
(1-α)*loss
kl
,其中α是一个超参数,用于控制两个损失项的比重;
[0051]
有益效果:从技术层面来说,本发明的技术方案首次提出利用实体遮掩和知识蒸馏结合远程监督和有监督的关系分类模型;通过实体遮掩减轻学生模型对实体信息的依赖,增加对文本上下文内容的关注,提高学生模型的抗噪能力;通过知识蒸馏技术利用有监督数据训练得到的教师模型对学生模型进行指导,从而降低远程监督数据的标注噪音;在有监督数据上对学生模型进行微调,能够利用干净的有监督数据对学生模型进行进一步的修正。
[0052]
从应用层面来说,本发明的技术方案能够自动化地从海量文本数据中挖掘出结构化的三元组信息,可以大幅减少填充知识图谱所需的人工成本。有效地结合了远程监督的带噪音数据和人工标注的干净数据,提升了关系分类模型的性能,同时减少了对有监督数据的依赖,有助于降低开发关系分类模型的人工成本。
附图说明
[0053]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
[0054]
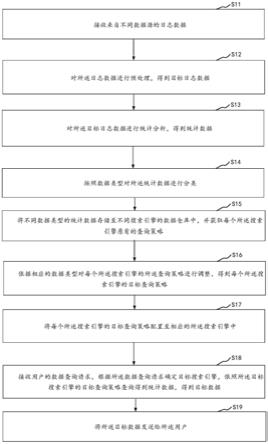
图1是本发明方法流程图。
[0055]
图2是通过远程监督技术自动标注数据的流程。
[0056]
图3是训练关系分类教师模型的流程。
[0057]
图4是训练关系分类学生模型的流程。
具体实施方式
[0058]
实施例
[0059]
本发明整体流程如图1、图4所示,包括:
[0060]
步骤1,获取关系分类文本数据。具体包括:
[0061]
步骤1-1,通过人工标注的方式获取有监督的关系分类文本数据。在本发明中使用docred人工标注数据集,共有5053篇文档,包含63427条实例,涉及96种关系。其中,33.3%的关系是科学相关的,11.5%的关系是艺术相关的,8.3%的关系是时间相关的,4.2%的关系和个人生活相关。将有监督关系分类文本数据划分为训练集、验证集和测试集。训练集有3053篇文档,验证集和测试集分别有1000篇文档。
[0062]
步骤1-2,通过远程监督技术获取自动标注的关系分类文本数据,流程如图2所示,包括:
[0063]
步骤1-2-1,获取wikidata中的三元组信息,三元组包含实体对和实体对之间的关系;
[0064]
步骤1-2-2,获取wikipedia中的部分文档或句子,构建非结构化的文本语料库;
[0065]
步骤1-2-3,使用远程监督方法,对文档或句子中的实体对标注它们的关系,如果实体对在wikidata中出现,则标注为wikidata中的关系,否则标记为没有关系,得到远程监督的关系分类文本数据集。在本发明中,使用的是docred远程监督数据集,共有101873篇文档,包括1508320条实例,涉及97种关系(包括none关系)。这里的关系类别和步骤1-1中的关系类别一致。
[0066]
步骤2,在有监督的关系分类文本数据上训练关系分类教师模型。具体的训练流程如图3所示。
[0067]
步骤2-1,初始化教师模型的参数θ
t
。为了利用预训练模型强大的编码能力以及在大规模语料上学到的通用知识,本发明采用bert作为编码器。对于bert部分的参数,采用预训练模型的参数进行初始化;对于教师模型的双线性层,采用随机初始化的方式进行初始化;
[0068]
步骤2-2,输入有监督的关系分类文本数据训练集;
[0069]
步骤2-3,教师模型进行前向计算。通过编码器编码输入的样本,编码得到的结果表示为e;
[0070]
步骤2-4,获取头尾实体表示eh和e
t
,将它们输入双线性层,得到每个关系类别上的输出结果zi,计算公式为:zi=ehw
iet
。其中wi表示第i个关系类别对应的参数矩阵,i={1,2,
…
,c},c表示关系类别总数,在本示例中取值为97;再经过softmax函数得到每个关系上的预测概率:其中,exp代表指数函数,表示第i个关系的概率值;
[0071]
步骤2-5,计算概率分布和人工标注的标签y
t
的交叉熵损失loss
t
::将交叉熵损失作为教师模型的预测损失;其中,为第i个关系的真实标
签,表示教师模型在第i个关系上的预测概率;
[0072]
步骤2-6,计算梯度,反向传播更新教师模型的参数θ
t
。本发明采用adam作为优化器,学习率为2e-5,批次大小设置为30;
[0073]
步骤2-7,迭代训练,训练轮次epoch设置为300,选取在验证集上f1最高的轮次对应的模型作为教师模型。
[0074]
步骤3-1,初始化学生模型的参数θs,学生模型和教师模型的网络结构相同,也采用同样的初始化方式;
[0075]
步骤3-2,输入远程监督的关系分类文本数据;
[0076]
步骤3-3,利用步骤2训练得到的教师模型对输入的远程监督标注样本x
ds
={w1,...,wi,...,h,...,t,...,wn}进行预测,得到每个关系上的输出结果{z1,...,zi,...,zc},zi表示教师模型在第i个关系上归一化前的预测结果;经过softmax函数计算得到每个关系上的概率值参数t用于表示蒸馏的温度。本发明中使用的t为1。这里以句子“史蒂夫
·
乔布斯回归苹果公司。”以及实体对“史蒂夫
·
乔布斯”和“苹果”为例进行说明。对于该例子,教师模型在预先定义的关系上预测的概率值都低于0.05,而在特殊关系类别none上的预测值约为0.9,即教师模型预测的概率向量为:[0.01,
…
,0.02,
…
,0.90]。这表明,教师模型正确地判断出了在该句子中,实体对“史蒂夫
·
乔布斯”和“苹果”没有预先定义的关系;
[0077]
步骤3-4,对输入的远程监督数据样本x
ds
中的实体部分进行随机遮掩,随机遮掩的变量m服从伯努利分布,遮掩的概率为p(m=1)=q,q值选取为0.7。同样以句子“史蒂夫
·
乔布斯回归苹果公司。”以及句中的实体“史蒂夫
·
乔布斯”、“苹果”为例,当m=1时,进行实体遮掩,遮掩后的文本为“[e1]回归[e2]。”;当m=0时,实体不进行遮掩,依然为原文本“史蒂夫
·
乔布斯回归苹果公司。”;
[0078]
步骤3-5,学生模型进行前向计算。通过编码器编码输入的样本,编码得到的结果表示为e;
[0079]
步骤3-6,获取3-5中的实体表示,将实体表示输入双线性层和softmax层,得到学生模型预测的概率分布ps,ps是一个97维的向量;
[0080]
步骤3-7,计算概率分布ps和远程监督的标签y
ds
的交叉熵损失loss
ds
:其中,为第i个关系的远程监督标签,表示学生模型在第i个关系上的预测概率;由于从wikidata收集到的三元组信息中有《史蒂夫
·
乔布斯,创建,苹果》,在利用远程监督技术标记时,会认为句子“史蒂夫
·
乔布斯回归苹果公司。”表达了“史蒂夫
·
乔布斯创建了苹果”,因而,在这个例子中,得到的远程监督标签是错误的,此时计算得到的交叉熵损失也是有误的;
[0081]
步骤3-8,计算学生模型预测的概率分布和教师模型预测的概率分布之间的差异:对于上述例子,教师模型的预测结果是正确的,这里计算得到的损失相比上一步骤中的损失更为合理;
[0082]
步骤3-9,将步骤3-6和步骤3-7中的损失相加,作为学生模型最终的预测损失
losss,计算公式为:losss=α*loss
ds
(1-α)*loss
kl
,其中α是一个超参数,用于控制两个损失项的比重。α取值为0.4。可以看到,通过加权两个损失项的方式,综合考虑了远程监督的标签和教师模型预测的概率分布。对于上述例子,远程监督的标签是错误的,此时,教师模型正确的预测结果能够对整体损失项起到纠正的作用,从而引导学生模型进行正确的训练;
[0083]
步骤3-10,计算梯度,反向传播更新学生模型的参数θs。本发明采用adam作为优化器,学习率为2e-5,批次大小设置为30;
[0084]
步骤3-11,迭代训练,训练轮次epoch设置为20,选取在验证集上f1最高的轮次对应的模型作为学生模型。
[0085]
步骤4,在有监督的关系分类文本数据上微调步骤3训练得到的学生模型。微调的轮数为20轮;
[0086]
步骤5,结束训练模型,使用训练好的学生模型对测试集中的样本进行预测。如表1所示,在docred数据集上,本发明中描述方法和现存在的主流方法的对比结果表明,本发明在验证集和测试集上,在f1-score评价标准上具有明显的优势。
[0087]
表1
[0088][0089]
本发明提供了一种结合远程监督和有监督的关系分类方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。