1.本发明涉及计算机技术领域,尤其涉及基于循环折叠的二进制程序体积优化器。
背景技术:
2.现在程序体积(code size,也称为代码大小)正在变得越来越大,一个原因是程序功能更加复杂,另一个原因是程序所需的依赖库和依赖环境越来越多,同时许多程序都采用了迭代软件开发模式,新的功能会被不停的添加到程序中,这些都使得程序体积过大的现象变的十分常见。而各种平台往往对程序所需的磁盘空间、内存大小有一定的限制,体积过大的程序不光会占用有限的存储资源,还会影响程序运行效率,甚至导致系统无法正常运行。例如,嵌入式设备拥有的存储空间十分宝贵并且不易扩展,软件常常会被针对嵌入式平台做特定的优化以减少包大小;在服务器、超算系统上,大规模的程序的的代码体积往往更大,facebook服务器上运行的一个千万行代码的php程序会被编译为数百兆的机器代码,一个使用openmp实现的并行版本的程序要远大于它的串行版本,大文件不光占用的了大量存储空间,而且它们在服务器或超级计算机节点之间的传输会更加困难。然而,简单的在这些平台上增加存储空间或增加带宽往往是很困难的,这一方面是因为高度集成的芯片上空间十分的有限,另一方面是因为高昂的晶体管价格导致成本的快速上升。此外,小体积的程序意味着更少的指令将会被执行,这可以减少l1指令缓存和指令tlb的压力,从而提高程序性能并减少能耗。
3.编译器提供了一系列默认的优化级别以满足不同的需求。提高性能的优化会导致代码大小的增加,减少代码大小的优化同时也会损害性能。循环展开通常被认为是会增加代码大小的性能优化方法,它作为编译器中经常使用的方法,循环展开将循环体复制若干次以减少迭代次数,这可以减少循环的开销。在更大的循环体中,循环展开可以从指令并行、寄存器分配、内存分层中受获得性能提升,并且可以利用硬件特性来组合指令。但是同时,通过循环展开产生的代码可能引入了大量的中间变量,这可能导致寄存器溢出、不连续的内存访问和指令缓存溢出。同时也存在对性能的影响不大的关于代码大小的优化。常见的解决方案是减少公共或死代码段。公共子表达式消除法搜索相同表达式的实例,并分析是否值得用一个持有计算值的单一变量来取代它们。死代码消除试图删除那些不影响程序结果的代码。这些方法都是删除无用的代码或多余的计算,以缩小程序的大小。
4.循环展开是影响程序体积的重要因素,不同的编译器对循环展开有不同的策略。gcc甚至在-03的优化等级时也不会展开大多数循环,除非用户指定-funroll-loops或使用性能剖析的优化。默认情况下,gcc只选择的进行完全展开循环,这些循环要求具有较小且编译时已知循环数。相反,即使使用-o1优化等级,llvm也会进行展开循环。尽管在现代编译系统中可以接受这样激进的循环展开策略,因为这通常可以提高性能,但很难说哪种策略在现有程序中更好,因为单个函数的优化情况可能会因最终编译成的应用程序而异。但是这样激进的展开策略使得代码大小问题愈加严重。那些很少被执行的循环被全部展开,增大了代码大小,但是这对性能并没有任何帮助。
5.尽管大多数现代编译器都支持性能剖析指导优化(pgo),但现在它也有一些限制和缺点。性能数据的准确性对于pgo非常重要,严重影响最终效果。不仅是收集数据的真实环境,如何将性能数据映射到代码也很重要。gcc、llvm和其他优化器将性能数据映射回编译器的中间表示(ir)或源代码。但测试性能时的二进制代码与原始源代码相比往往存在差异,可能无法准确映射性能数据。
技术实现要素:
6.有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是提供基于循环折叠的二进制程序体积优化器,解决激进的循环展开策略导致代码大小过大的问题,可以在对原有程序性能影响很小的情况下减少代码大小,使用性能剖析数据来精细控制优化策略,并且不需要从源代码重新编译,就可以对二进制程序进行优化。
7.为实现上述目的,本发明提供了基于循环折叠的二进制程序体积优化器,其执行包括以下步骤:
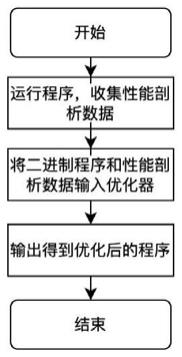
8.步骤1、运行程序,收集性能剖析数据;
9.步骤2、将二进制程序和性能剖析数据输入优化器;
10.步骤3、输出得到优化后的程序。
11.进一步的,所述将二进制程序和性能剖析数据输入优化器后,优化器的优化步骤包括:
12.步骤1-1、解析性能剖析数据,获得关于循环代码的时间和指令信息;
13.步骤1-2、计算每个循环的循环折叠等级;
14.步骤1-3、进行循环折叠,包括对连续内存访问的循环折叠和对迭代的循环折叠;
15.步骤1-4、生成优化的可执行文件。
16.进一步的,所述计算每个循环的循环折叠等级具体包括:计算三级循环折叠等级,高等级的完全折叠循环体仅包含一次迭代的循环,中层将展开因子减半,最低等级保持原有循环不变,具体使用以下策略来判断循环对应的的折叠等级:
17.s=0.5*time/total_loop_time 0.5*exec_num/total_exe_num
18.其中,s为最后的折叠分数,time为该循环的墙上运行时间,total_loop_time为所有循环运行的总时间,exec_num为该循环执行次数、total_exe_num为所有循环的总执行次数;如果分数小于0.25,将其折叠在最高级别,如果分数大于0.25且小于0.5,将其折叠在中间级别;如果分数大于0.5,不折叠。
19.进一步的,所述对连续内存访问的循环折叠包括:
20.步骤2-1、反汇编二进制文件,识别所有循环,寻找连续内存访问的迭代寄存器;
21.步骤2-2、调度迭代寄存器更新指令,更新与迭代寄存器相关的内存地址;
22.步骤2-3、计算循环展开系数和步长,然后进行相关性分析和指令替换。
23.进一步的,所述对迭代的循环折叠包括:
24.步骤3-1、反汇编二进制文件,识别所有循环,识别完全重复的代码结构,去掉除头尾的其他代码片段;
25.步骤3-2、识别循环之后,优化器解析循环体中是否存在连续的完全相同的指令序列,所述指令序列拥有一致的操作符和操作数;
26.步骤3-3、将除头尾的其他代码删除,替换为最后的循环体代码。
27.进一步的,所述对迭代的循环折叠中,如果在识别和替换的过程中发生了异常,则跳过该循环并恢复原指令。
28.本发明的有益效果是:
29.对比现有代码大小优化方法,本发明在二进制层面进行优化,降低优化门槛,同时利用程序的性能剖析数据,针对现有循环展开策略的不足,设计实现了更精细控制的优化策略。对比现有的二进制优化器,本发明关注了程序体积的优化,在不影响原有性能的前提下优化程序体积。
30.以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
31.图1是本发明中基于循环折叠的二进制程序体积优化器的使用流程图。
32.图2是本发明中优化器具体实施的优化流程图。
33.图3是本发明对连续内存访问的循环折叠的过程流程图。
34.图4是本发明对连续内存访问的循环折叠的过程寄存器代码截图。
35.图5是本发明对迭代的循环折叠过程流程图。
具体实施方式
36.如图1所示,本发明提供了基于循环折叠的二进制程序体积优化器,其执行包括以下步骤:步骤1、运行程序,收集性能剖析数据;步骤2、将二进制程序和性能剖析数据输入优化器;步骤3、输出得到优化后的程序。对于已有的二进制文件,首先需要收集它的性能剖析数据,使用linux perf工具在真实环境和真实数据下运行目标程序,可以得到peri.data文件,包含了程序的cpu数据、指令数据、分支预测情况等数据。然后将该性能剖析文件和对应的二进制文件作为优化器输入,优化器会自动分析并优化,最后得到有更小体积的、同时保持相近性能的优化后的二进制文件。
37.如图2所示,将二进制程序和性能剖析数据输入优化器后,优化器的优化步骤包括:步骤1-1、解析性能剖析数据;步骤1-2、计算每个循环的循环折叠等级;步骤1-3、进行循环折叠,包括对连续内存访问的循环折叠和对迭代的循环折叠;步骤1-4、生成优化的可执行文件。
38.首先需要解析性能剖析数据,并从中获得关于循环代码的时间和指令相关信息。然后计算每个循环的折叠等级。从性能剖析数据中,可以知道每个循环的执行次数和迭代次数。提供有三级循环折叠等级可应用于每个循环。高等级的完全折叠循环体仅包含一次迭代的循环。它可以最多可以节省空间,但也会影响性能。中层将展开因子减半,最低等级保持原有循环不变。使用以下策略来判断循环对应的的折叠等级,具体为:
39.s=0.5*time/total_loop_time 0.5*exec_num/total_exe_mum
40.其中,s为最后的折叠分数,time为该循环的墙上运行时间,total_loop_time为所有循环运行的总时间,exec_num为该循环执行次数、total_exe_num为所有循环的总执行次数。如果分数小于0.25,将其折叠在最高级别,如果分数大于0.25且小于0.5,将其折叠在中
间级别。如果分数大于0.5,不折叠它。
41.然后就可以根据确定的折叠等级实施循环折叠。循环折叠之后,由于缩减了代码的程度,会在程序中留下空洞,也就是空白的代码段。为了减小最终的程序大小,必须将空白的代码段删去。重新解析整个程序,使用双指针来记录程序中的空白代码,当识别带空白代码时,其中一个指针跳过空白区域,记录下一段代码的开始地址,并调整后面代码的偏移量,从而生成最后的优化程序。
42.如图3所示,上述对连续内存访问的循环折叠包括:步骤2-1、反汇编二进制文件,识别所有循环,寻找连续内存访问的迭代寄存器;步骤2-2、调度迭代寄存器更新指令,更新与迭代寄存器相关的内存地址;步骤2-3、计算循环展开系数和步长,然后进行相关性分析和指令替换。首先先反汇编二进制文件,循环嵌套中最内层的循环往往的编译器进行循环展开的主要目标,它往往只有一个基本块(basic block),识别、过滤其中所有最内层循环并检查它是否已展开。由于长度为4、8或更大数的连续内存访问是展开循环的显着特征,所以找到连续内存访问的迭代寄存器对于计算展开因子和步长很重要。对于每个循环,迭代器寄存器必须在每次迭代中更新,因此必须有一条加法指令,将立即数添加到寄存器中。如果有连续的内存访问,将检查每个立即数加法指令中的寄存器。图4(a)中地址0x0000001e处指令所操作的寄存器是迭代器寄存器。由于指令调度,这条更新指令可能出现循环体中的任何地方。所以它应该移动到循环的顶部或底部,以便可以顺利找到展开因子。选择将此指令移到底部,因为这也是大多数编译器默认行为。因为改变了更新指令的位置,所以需要为所有与此寄存器相关的指令增加一个偏移量来更新所有相关的内存地址。然后我根据迭代寄存器的所有内存偏移量来进行相关性分析。这些偏移量会被分成几组,每组中的偏移量形成一个子序列。当所有子序列具有相同的长度(即展开因子)时,该循环可以是展开循环。如果该因子大于1,则意味着可以折叠循环。接下来尝试移除循环的展开部分并根据想要的折叠级别修改更新指令中的立即数。如果只想完全折叠循环,只保留原始部分并移除展开循环的所有其他部分。最后用的新指令替换原来的循环。由于循环折叠的每个阶段都可能发生失败,所以可以捕捉异常并跳过该循环。
43.如图5所示,上述对迭代的循环折叠包括:步骤3-1、反汇编二进制文件,识别所有循环,识别完全重复的代码结构,去掉除头尾的其他代码片段;步骤3-2、识别循环之后,优化器解析循环体中是否存在连续的完全相同的指令序列,指令序列拥有一致的操作符和操作数;步骤3-3、将除头尾的其他代码删除,替换为最后的循环体代码。对于一些没有序列内存访问的展开循环,例如迭代,这些循环只在几个寄存器中进行计算。这些情况往往很难识别,但如果重复部分是规则的,即重复部分拥有完全相同的代码结构,保留头尾部分,去掉其他部分。在识别循环之后,优化器会解析循环体中是否存在连续的完全相同的指令序列,这些指令序列拥有一致的操作符和操作数,然后将除头尾的其他代码删除,替换为最后的循环体代码。类似的,如果在识别和替换的过程中发生了异常,则跳过该循环并恢复原指令。
44.对比现有代码大小优化方法,本发明在二进制层面进行优化,降低优化门槛,同时利用程序的性能剖析数据,针对现有循环展开策略的不足,设计实现了更精细控制的优化策略。对比现有的二进制优化器,本发明关注了程序体积的优化,在不影响原有性能的前提下优化程序体积。
45.以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思做出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
