1.本发明涉及信息技术领域,尤其涉及一种战争类研究报告的信息抽取方法。
背景技术:
2.美国国防部发布的一些战争类的研究报告对于毁伤领域研究非常有意义,如“海湾战争”,“阿富汗战争”,“朝鲜战争”等。通过分析一些战争类研究报告可以掌握在战争中各个国家的协同,各类部队所扮演的角色,各种武器的运用以及之间的关系等等,甚至可以挖掘和推断出一些隐含的关键信息。因此从一些战争类研究报告中抽取其中的关键信息以及各个信息之间的关系对于毁伤领域的研究以及国防安全具有相当重要的意义。
3.信息抽取是将自然语言文本作为输入,并生成由某些标准指定的结构化信息的任务。信息抽取的各种子任务(例如,命名实体识别,关系抽取,共指解析,命名实体链接,知识库推理等)构成了各种下游自然语言处理(nlp)任务(例如机器翻译、问题回答系统、自然语言理解、文本摘要和siri和cortana等智能机器助理)。实体关系关系抽取是为了从非结构化文本中抽取出(头实体,关系,尾实体)这样的结构化三元组知识,是信息抽取重要任务之一,主要分为半监督、监督学习两种,其作为信息抽取、自然语言理解、信息检索等领域的核心任务和重要环节,能够从文本中抽取实体和实体之间的语义关系。随着知识图谱的广泛应用,作为图谱构建的关键技术,实体关系抽取正得到越来越多的研究人员的关注。
4.半监督学习方法不需要太多的训练样本,但是其抽取的查全率很低。因此目前研究主要集中在监督学习抽取,其中又分为流水线式关系抽取方法(pipline)和联合关系抽取方法(joint model)。其中联合抽取由于可以将实体抽取任务和关系抽取任务合并为一个任务完成,因此解决了流水线式关系抽取方法误差传播问题。
技术实现要素:
5.为解决现有技术中存在的问题,本发明提出一种战争类研究报告的信息抽取方法,解决了利用神经网络算法对战争类研究报告进行信息抽取的问题并充分利用了大量的已知知识从而提升了联合关系抽取的效果。
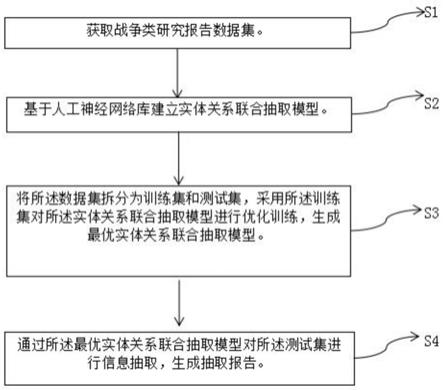
6.为实现上述目的,本发明提供了如下方案:一种战争类研究报告的信息抽取方法,包括:
7.s1.获取战争类研究报告数据集;
8.s2.基于人工神经网络库构建实体关系联合抽取模型;
9.s3.将所述数据集拆分为训练集和测试集,采用所述训练集对所述实体关系联合抽取模型进行优化训练,当特征参数达到设定阈值时,生成最优实体关系联合抽取模型;
10.s4.通过所述最优实体关系联合抽取模型对所述测试集进行信息抽取,生成抽取报告。
11.优选地,所述获取战争类研究报告数据集包括以下步骤:
12.s11.提取所述战争类研究报告,获取文本,利用正则表达式对所述文本进行过滤,
获得过滤后的文本,将所述过滤后的文本以句子为单位进行分割,获得分割后的文本;
13.s12.对所述分割后的文本进行人工标注,获得标注的数据集;
14.步骤三,将所述标注的数据集划分训练集和测试集。
15.优选地,所述实体关系联合抽取模型包括:输入层、bert编码层、头先验知识层、头实体预测层、尾实体先验知识层、特定关系和尾实体预测层;
16.所述输入层用于对输入文本进行切分以及分割;
17.所述bert编码层用于对所述分割后的文本进行编码,转化为transformer块输出的向量;
18.所述头先验知识层用于将当前的头实体先验知识融合到所述头实体预测层,将生成的头实体先验矩阵与所述bert编码层输出的向量拼接成第一向量矩阵;
19.所述头实体预测层用于从所述第一向量矩阵中识别并保存所有头实体;
20.所述尾实体先验知识层用于从先验知识中根据头实体先验信息和对应关系先验信息预测尾实体的先验信息,将生成的尾实体先验矩阵与所述bert编码层输出的向量拼接成第二向量矩阵;
21.所述特定关系和尾实体预测层用于从所述第二向量矩阵中,根据所述头实体预测层预测出的所有头实体,对应每种特定关系预测出对应的尾实体。
22.优选地,所述bert编码层表达式为:
23.h
α
=trans(h
α-1
),α∈[1,n]
[0024]
其中h
α
为bert编码层中的第α层transformer块输出的向量,n为transformer块的数量。
[0025]
优选地,所述头实体预测层表达式为:
[0026]
p
istart_n
=σ(w
start
xi b
start
)
[0027]
p
iend_n
=σ(w
end
xi b
end
)
[0028][0029]
其中p
istart_h
为句子切分后序列x第i个字符是头实体开始字符的概率,p
iend_h
为第i个字符是头实体结尾字符的概率,w
start
为头实体开始位置的训练权重参数,b
start
为头实体开始位置的偏置项,w
end
为头实体结束位置的训练权重参数,b
end
为头实体结束位置的偏置项,xi为第i个字符位置对应的向量,σ为激活函数,s
input
为bert编码层处理后的文本;l为序列s
input
的长度,t∈{start_h,end_h}代表t位于头实体开始字符和结尾字符范围内,为第i个字符是头实体的第t个字符的概率,为句子切分后序列s
input
的第i个字符的头实体第t个字符的二分类标签,为0或1;代表是否正确,代表正确,否则为0,代表是否正确,代表正确,否则为0,p
θ(h|x)
为头实体预测层优化拟然函数。
[0030]
优选地,所述特定关系和尾实体预测层表达式为:
[0031][0032][0033][0034]
p
istart_t
为预测在s
input
序列中的第i个字符为开始字符的概率,p
iend_t
为预测在s
input
序列中第i个字符为结束字符的概率,为第k个头实体编码,为当前字符的一维向量。为特定关系对应的尾实体开始位置的训练权重参数,为特定关系对应的尾实体结束位置的训练权重参数,为特定关系对应的尾实体开始位置的偏置项,为特定关系对应的尾实体结束位置的偏置项,t∈{start_h,end_h}代表t位于特定关系对应的尾实体开始字符和结尾字符范围内,为第i个字符是尾实体的第t个字符的概率,是句子切分后序列x的第i个字符为尾实体第t个字符的二分类标签,为0或1;为特定关系和尾实体预测的优化似然函数。
[0035]
优选地,获得所述实体关系联合抽取模型后,还包括:获取待抽取文件,将所述待抽取文件以句号进行分割,分割之后输入到所述最优实体关系联合抽取模型中,完成对所述待抽取文件的关系抽取。
[0036]
优选地,所述最优实体关系联合抽取模型中包含先验知识,所述先验知识为基于所述训练集中的标注数据转化而成的三元组。
[0037]
优选的,所述数据集按照7:3的比例将数据集拆分为训练集和测试集。
[0038]
本发明公开了以下技术效果:
[0039]
本发明公开了一种战争类研究报告的信息抽取方法,通过构建实体关系联合抽取模型,有效处理文件信息抽取过程中出现的“头尾重叠问题”、“seo问题”和“epo问题”,通过对实体关系联合抽取模型引入了先验知识,使抽取效果得到了进一步的提升,进一步提高识别准确率,从而完全抽取出文本中的三元组,以供专家查看文本中含有的实体关系或者是直接存入图形数据库中以作为之后毁伤领域知识图谱构建的储备数据。
附图说明
[0040]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0041]
图1为本发明实施例中一种战争类研究报告的信息抽取方法方法的流程图;
[0042]
图2为本发明实施例中实体关系联合抽取模型;
[0043]
图3为本发明实施例中标准标注流程图;
[0044]
图4(a)、图4(b)、图4(c)分别为本发明实施例中每个epoch下f1值变化、每个epoch下precise值变化、每个epoch下recall值变化。
具体实施方式
[0045]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0046]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0047]
参照图1所示,本实施例提供一种战争类研究报告的信息抽取方法方法,包括:
[0048]
s1.获取战争类研究报告数据集,包括以下步骤:
[0049]
s11.提取战争类研究报告,获取文本,利用正则表达式对所述文本进行过滤,获得过滤后的文本,将过滤后的文本以句子为单位进行分割,获得分割后的文本;
[0050]
s12.对分割后的文本进行人工标注,获得标注的数据集;
[0051]
为了保证标注的准确性,本发明设计了标准标注流程,其标注具体过程为:采用双人标注,一人审核的方式进行标注,即由两位掌握领域相关知识的研究人员a和b对数据分别进行标注,而由另一位研究人员c对标注后的数据进行审核,如果审核不通过则将当前的数据交由另外一位研究人员进行标注,如果审核仍然不通过,则当前数据会被存储下来,之后由三人共同讨论,再进行标注。
[0052]
s2.基于人工神经网络库建立实体关系联合抽取模型。
[0053]
实体关系联合抽取模型包括:输入层、bert编码层、头先验知识层、头实体预测层、尾实体先验知识层、特定关系和尾实体预测层;
[0054]
输入层用于对输入文本进行切分以及分割;
[0055]
bert编码层用于对所述分割后的文本进行编码,转化为transformer块输出的向量;
[0056]
bert编码层表达式为:
[0057]hα
=trans(h
α-1
),α∈[1,n]
[0058]
其中h
α
为bert编码层中的第α层transformer块输出的向量,n为transformer块的数量。
[0059]
头先验知识层用于将当前的头实体先验知识融合到头实体预测层,将生成的头实体先验矩阵与bert编码层输出的向量拼接成第一向量矩阵;
[0060]
头实体预测层用于从所述第一向量矩阵中识别并保存所有头实体;
[0061]
头实体预测层表达式为:
[0062]
p
istart_n
=σ(w
start
xi b
start
)
[0063]
p
iend_n
=σ(w
end
xi b
end
)
[0064][0065]
其中p
istart_h
为句子切分后序列x第i个字符是头实体开始字符的概率,p
iend_h
为第i个字符是头实体结尾字符的概率,w
start
为头实体开始位置的训练权重参数,b
start
为头实体开始位置的偏置项,w
end
为头实体结束位置的训练权重参数,b
end
为头实体结束位置的偏置项,xi为第i个字符位置对应的向量,σ为激活函数,s
input
为bert编码层处理后的文本;l为序
列s
input
的长度,t∈{start_h,end_h}代表t位于头实体开始字符和结尾字符范围内,为第i个字符是头实体的第t个字符的概率,为句子切分后序列s
input
的第i个字符的头实体第t个字符的二分类标签,为0或1;代表是否正确,代表正确,否则为0,代表是否正确,代表正确,否则为0,p
θ(h|x)
为头实体预测层优化拟然函数。
[0066]
尾实体先验知识层用于从先验知识中根据头实体先验信息和对应关系先验信息预测尾实体的先验信息,将生成的尾实体先验矩阵与所述bert编码层输出的向量拼接成第二向量矩阵。
[0067]
特定关系和尾实体预测层用于从所述第二向量矩阵中,根据头实体预测层预测出的所有头实体,对应每种特定关系预测出对应的尾实体;
[0068]
特定关系和尾实体预测层表达式为:
[0069][0070][0071][0072]
p
istart_t
为预测在s
input
序列中的第i个字符为开始字符的概率,p
iend_t
为预测在s
input
序列中第i个字符为结束字符的概率,为第k个头实体编码,为当前字符的一维向量。为特定关系对应的尾实体开始位置的训练权重参数,为特定关系对应的尾实体结束位置的训练权重参数,为特定关系对应的尾实体开始位置的偏置项,为特定关系对应的尾实体结束位置的偏置项,t∈{start_h,end_h}代表t位于特定关系对应的尾实体开始字符和结尾字符范围内,为第i个字符是尾实体的第t个字符的概率,是句子切分后序列x的第i个字符为尾实体第t个字符的二分类标签,为0或1;为特定关系和尾实体预测的优化似然函数。
[0073]
s3.将数据集拆分为训练集和测试集,采用训练集对实体关系联合抽取模型进行优化训练,当特征参数达到设定阈值时,生成最优实体关系联合抽取模型;其中根据7:3的比例将数据集拆分为训练集和测试集,当参数epochs=600时,停止训练,得出最优实体关系联合抽取模型。
[0074]
s4.通过所述最优实体关系联合抽取模型对所述测试集进行信息抽取,生成抽取报告。
[0075]
获得实体关系联合抽取模型后,还包括:获取待抽取文件,将待抽取文件以句号进行分割,分割之后输入到最优实体关系联合抽取模型中,完成对待抽取文件的关系抽取。
[0076]
最优实体关系联合抽取模型中包含先验知识,先验知识为基于所述训练集中的标注数据转化而成的三元组。
[0077]
为了更好理解本发明,下面结合实施例对本发明做进一步地详细说明:
[0078]
下面结合如图1所示的战争类研究报告的信息抽取方法的流程和图2所示的实体关系联合抽取模型,以《海湾战争-美国国防部致国会最后的报告(上)》的翻译版为例,说明本发明的具体实施方法:
[0079]
步骤1:将《海湾战争-美国国防部致国会最后的报告(上)》翻译版的pdf版本利用pdfminer将文本提取后,利用正则表达式进行文本过滤,之后以句子为单位进行分割,将其中含有领域专家感兴趣的实体以及关系保留,最终构造成一个437条的长文本小型语料库。
[0080]
总结语料中保留的关系种类,其关系种类见表1,之后利用图3所示的标准标注流程对提取的文本进行标注,得到3554个标注关系。所构建的战争类研究报告的数据集简写为wrr(war research report),所标注的数据集格式采用json格式存储,数据集示例如表1所示:
[0081]
表1
[0082][0083]
分析标注关系可能存在的问题,其存在头尾重叠问题,seo问题和epo问题,每种关系可能存在的问题如表1标注所示。
[0084]
步骤2:利用人工神经网络构建实体关系联合抽取模型,其实体关系联合抽取模型如图2所示,其中的先验知识主要是基于训练集中已有的标注数据以及从环球军事网站中所爬取的相关三元组转为本发明所需要的三元组,如在环球军事网站爬取的“武器生产国”关系可以转换为本文中所需要的“隶属于”关系,如存在三元组(f16战斗机,生产国,美国)这种关系,可以转换为本发明所需要的先验知识(f16战斗机,隶属于,美国)的先验知识。
[0085]
步骤3:将数据集根据7:3的比例随机划分为训练集和测试集。将本技术中加入先验知识的模型命名为dis-casrel,设置一组未加入先验知识的模型命名为casrel。对测试集进行实验,得到如图4(a)、图4(b)、图4(c)所示的实验结果,根据其实验结果可见在特征参数达到特定阈值即epoch=600的时候两模型的f1值几乎不再上升,因此将模型进行停止,并保存在600个epoch下各个效果最好的模型,由图4(a)可以看到,在180个左右epoch以后,dis-casrel的f1值效果开始高于casrel,这是由于dis-casrel此时的召回率变高的原因并且同时此刻的精确率也依然较高。由图4(b)和图4(c)可以看出,dis-casrel在同等条件下能够以较少的训练次数达到比casrel更好的抽取效果。
[0086]
将得到dis-casrel与casrel的最佳预测效果下的模型对测试集进行抽取,得到表2所示的效果,其中dis-casrel相比casrel的预测效果f1值提升了6.6%,提升较为明显,显示了在加入先验知识后的最优实体关系联合抽取模型其更好的抽取效果。
[0087]
表2
[0088]
方法精确率(%)召回率(%)f1(%)casrel59.834.844.0dis-casrel81.736.650.6
[0089]
步骤4:得到的抽取效果最佳模型即为最优实体关系联合抽取模型,最优实体关系联合抽取模型用于对待抽取文件进行实体关系抽取,将待抽取文件以句号进行分割,分割之后输入到训练好的实体关系联合抽取模型中,完成对所述待抽取文件的关系抽取。
[0090]
在本发明的描述中,需要理解的是,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
[0091]
以上所述的实施例仅是对本发明的优选方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。