1.本发明涉及人机交互技术领域,具体地,涉及一种基于多模态分析的多感官车载交互方法及系统。
背景技术:
2.在人机共驾阶段,多感官通道融合交互将建立人与机器的全新交互体验,通过对人的表情、语音、温湿度等进行采集分析,可以综合判断用户情绪状态和意图,将被动交互转变为主动交互。同时,以视觉、语音、嗅觉、触觉的交互方式与用户交流,可以显著提升驾乘体验。
3.在申请号为cn201910764559.4的中国专利,公开了“一种基于人工智能的自适应多感官睡眠辅助系统”,该系统通过检测压力信号和与睡眠相关的环境信号,实时判断睡眠状态和环境信息,从而控制光照、声音、气味、智能家电。该技术没有考量人体状态因素,不能全面、准确地反映人体状态特征。
4.在申请号为cn201480019946.0的中国专利,公开了“用于在车辆中产生不同的多感官环境的车辆功能构件的控制方法”,该技术可以控制车内的声音、照明、香味,但仅限于根据预设场景控制每个构件,不具有实时主动交互特征和个性化调节功能。
技术实现要素:
5.针对现有技术中的缺陷,本发明的目的是提供一种基于多模态分析的多感官车载交互方法及系统。
6.根据本发明提供的一种基于多模态分析的多感官车载交互方法,包括以下步骤:
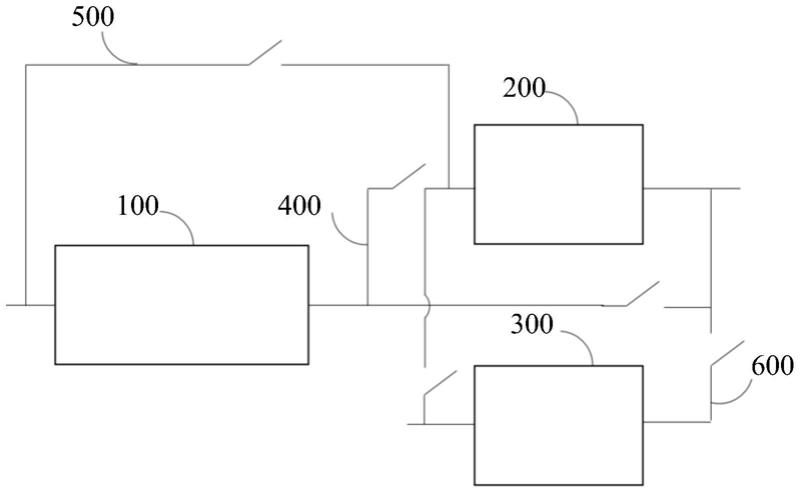
7.步骤s1:通过车载摄像头、麦克风、温湿度传感器实时捕获并存储驾驶员的多模态源数据;
8.步骤s2:实时解析所述驾驶员的多模态源数据,提取多模态源数据中的特征向量;
9.步骤s3:将多个特征向量进行拼接并转换到同一维度,得到处理后数据;
10.步骤s4:将处理后数据输入bp神经网络进行训练,判定驾驶员的实时状态;
11.步骤s5:根据驾驶员的实时状态,主动为驾驶员提供相应的交互服务。
12.优选地,所述车载摄像头采集:
[0013]-眼睛数据:包括眨眼次数以及上下眼睑距离;
[0014]-面部表情:包括打呵欠次数以及低头次数;
[0015]
所述麦克风采集:用户的语音、语调以及语速;
[0016]
所述温湿度传感器采集:人体温度、车内温度以及指车内湿度。
[0017]
优选地,所述步骤s2包括:将多模态源数据进行编码,将模态源数据用向量序列隐层表示,通过特征提取工具对多模态源数据进行特征抽取,包括facet和covarep,抽取后得到每个模态对应的特征表示,并对每个模态进行区分和标注,生成对应的序列。
[0018]
优选地,所述步骤s3包括以下子步骤:
[0019]
步骤s3.1:利用解码器隐层状态对序列进行计算得分,分别得到注意力向量;
[0020]
步骤s3.2:利用解码器隐层表示对注意力向量计算权重分布;
[0021]
步骤s3.3:根据权重融合多个注意力向量
[0022]
优选地,所述步骤s5包括以下步骤:
[0023]
步骤s5.1:获取驾驶员的实时状态,包括自然、疲劳、愤怒、悲伤、开心;
[0024]
步骤s5.2:根据驾驶员的实时状态变化,向驾驶员提供主动交互服务,包括车内的氛围灯颜色、虚拟管家表情、音乐类型、香氛类型、车内温湿度;
[0025]
步骤s5.3:通过对比第一时间段与第二时间段内驾驶员状态的变化,判定并优化主动交互服务的效果。
[0026]
根据本发明提供的一种基于多模态分析的多感官车载交互系统,包括以下模块:
[0027]
模块m1:通过车载摄像头、麦克风、温湿度传感器实时捕获并存储驾驶员的多模态源数据;
[0028]
模块m2:实时解析所述驾驶员的多模态源数据,提取多模态源数据中的特征向量;
[0029]
模块m3:将多个特征向量进行拼接并转换到同一维度,得到处理后数据;
[0030]
模块m4:将处理后数据输入bp神经网络进行训练,判定驾驶员的实时状态;
[0031]
模块m5:根据驾驶员的实时状态,主动为驾驶员提供相应的交互服务。
[0032]
优选地,所述车载摄像头采集:
[0033]-眼睛数据:包括眨眼次数以及上下眼睑距离;
[0034]-面部表情:包括打呵欠次数以及低头次数;
[0035]
所述麦克风采集:用户的语音、语调以及语速;
[0036]
所述温湿度传感器采集:人体温度、车内温度以及指车内湿度。
[0037]
优选地,所述模块m2包括:将多模态源数据进行编码,将模态源数据用向量序列隐层表示,通过特征提取工具对多模态源数据进行特征抽取,包括facet和covarep,抽取后得到每个模态对应的特征表示,并对每个模态进行区分和标注,生成对应的序列。
[0038]
优选地,所述模块m3包括以下子步骤:
[0039]
模块m3.1:利用解码器隐层状态对序列进行计算得分,分别得到注意力向量;
[0040]
模块m3.2:利用解码器隐层表示对注意力向量计算权重分布;
[0041]
模块m3.3:根据权重融合多个注意力向量
[0042]
优选地,所述模块m5包括以下步骤:
[0043]
模块m5.1:获取驾驶员的实时状态,包括自然、疲劳、愤怒、悲伤、开心;
[0044]
模块m5.2:根据驾驶员的实时状态变化,向驾驶员提供主动交互服务,包括车内的氛围灯颜色、虚拟管家表情、音乐类型、香氛类型、车内温湿度;
[0045]
模块m5.3:通过对比第一时间段与第二时间段内驾驶员状态的变化,判定并优化主动交互服务的效果。
[0046]
与现有技术相比,本发明具有如下的有益效果:
[0047]
1、本发明通过采用多模态信息处理手段,可以综合判断驾驶员实时状态并提供主动式交互服务,提高理解用户情绪、意图的准确度;通过bp神经网络训练模型,实现车载交互系统的自我优化。
附图说明
[0048]
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
[0049]
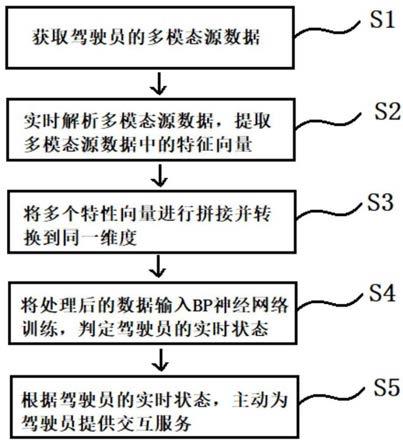
图1为本发明实施例基于多模态分析的多感官车载交互方法的流程示意图。
具体实施方式
[0050]
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
[0051]
参照图1,本发明公开了一种基于多模态分析的多感官车载交互方法,包括以下步骤:
[0052]
步骤s1:通过车载摄像头、麦克风、温湿度传感器实时捕获并存储驾驶员的多模态源数据。
[0053]
所述车载摄像头采集:
[0054]-眼睛数据:包括眨眼次数以及上下眼睑距离;
[0055]-面部表情:包括打呵欠次数以及低头次数;
[0056]
所述麦克风采集:用户的语音、语调以及语速;
[0057]
所述温湿度传感器采集:人体温度、车内温度以及指车内湿度。
[0058]
步骤s2:实时解析所述驾驶员的多模态源数据,提取多模态源数据中的特征向量;
[0059]
其中,解析过程包括:将多模态源数据进行编码,将模态源数据用向量序列隐层表示,通过特征提取工具对多模态源数据进行特征抽取,包括facet和covarep,抽取后得到每个模态对应的特征表示,并对每个模态进行区分和标注,生成对应的序列。其中,facet表示视觉特征(visual features)的抽取工具包,进行面部表情分析(30hz)。covarep表示声学特征(acoustic features)的抽取工具包,进行声音分析(100hz)。
[0060]
步骤s3:将多个特征向量进行拼接并转换到同一维度,得到处理后数据。
[0061]
具体包括以下子步骤:
[0062]
步骤s3.1:利用解码器隐层状态对序列进行计算得分,分别得到注意力向量;
[0063]
步骤s3.2:利用解码器隐层表示对注意力向量计算权重分布;
[0064]
步骤s3.3:根据权重融合多个注意力向量
[0065]
步骤s4:将处理后数据输入bp神经网络进行训练,判定驾驶员的实时状态;
[0066]
步骤s5:根据驾驶员的实时状态,主动为驾驶员提供相应的交互服务。
[0067]
步骤s5.1:获取驾驶员的实时状态,包括自然、疲劳、愤怒、悲伤、开心;
[0068]
步骤s5.2:根据驾驶员的实时状态变化,向驾驶员提供主动交互服务,包括车内的氛围灯颜色、虚拟管家表情、音乐类型、香氛类型、车内温湿度;
[0069]
步骤s5.3:通过对比第一时间段与第二时间段内驾驶员状态的变化,判定并优化主动交互服务的效果。
[0070]
本发明还公开了一种基于多模态分析的多感官车载交互系统,包括以下模块:
[0071]
模块m1:通过车载摄像头、麦克风、温湿度传感器实时捕获并存储驾驶员的多模态
源数据。
[0072]
所述车载摄像头采集:
[0073]-眼睛数据:包括眨眼次数以及上下眼睑距离;
[0074]-面部表情:包括打呵欠次数以及低头次数;
[0075]
所述麦克风采集:用户的语音、语调以及语速;
[0076]
所述温湿度传感器采集:人体温度、车内温度以及指车内湿度。
[0077]
模块m2:实时解析所述驾驶员的多模态源数据,提取多模态源数据中的特征向量。
[0078]
具体的解析过程包括:将多模态源数据进行编码,将模态源数据用向量序列隐层表示,通过特征提取工具对多模态源数据进行特征抽取,包括facet和covarep,抽取后得到每个模态对应的特征表示,并对每个模态进行区分和标注,生成对应的序列。
[0079]
模块m3:将多个特征向量进行拼接并转换到同一维度,得到处理后数据。
[0080]
所述模块m3包括以下子步骤:
[0081]
模块m3.1:利用解码器隐层状态对序列进行计算得分,分别得到注意力向量;
[0082]
模块m3.2:利用解码器隐层表示对注意力向量计算权重分布;
[0083]
模块m3.3:根据权重融合多个注意力向量
[0084]
模块m4:将处理后数据输入bp神经网络进行训练,判定驾驶员的实时状态;
[0085]
模块m5:根据驾驶员的实时状态,主动为驾驶员提供相应的交互服务。
[0086]
模块m5包括以下步骤:
[0087]
模块m5.1:获取驾驶员的实时状态,包括自然、疲劳、愤怒、悲伤、开心;
[0088]
模块m5.2:根据驾驶员的实时状态变化,向驾驶员提供主动交互服务,包括车内的氛围灯颜色、虚拟管家表情、音乐类型、香氛类型、车内温湿度;
[0089]
模块m5.3:通过对比第一时间段与第二时间段内驾驶员状态的变化,判定并优化主动交互服务的效果。
[0090]
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置、模块、单元以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置、模块、单元以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置、模块、单元可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置、模块、单元也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置、模块、单元视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
[0091]
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本技术的实施例和实施例中的特征可以任意相互组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。