一种基于机器学习的小麦白粉病发生程度预测方法
(一)技术领域
1.本发明“一种基于机器学习的小麦白粉病发生程度预测方法”可用于小麦白粉病发生程度的预测,属于植物病害领域。
(二)
背景技术:
2.小麦白粉病是由专性寄生真菌blumeria graminis f.sp.tritici引起的气传性病害,在世界各小麦种植区内广泛发生。现已成为我国20多个省(直辖市)小麦生产上的常发性病害之一。近年来,每年的发生面积一直保持在600-1000万公顷。小麦白粉病发生早且重的情况下,会严重影响小麦的生长发育,造成小麦分蘖数、成穗数和穗粒数等减少,千粒重下降,导致小麦产量降低,严重流行年份产量损失可达30%以上,甚至绝产。
3.病害预测是病害防治的重要依据,建立准确性较高的预测模型对小麦白粉病的防控有重要意义。前人在小麦白粉病的预测预报研究方面确实做了不少工作,其方法主要包括经验法或类比法、数理统计模型、系统模拟模型、专家评估、专家系统等。但已有的这些预测方法各自均存在不同的缺点或缺陷,以小麦白粉病建模研究较多的数理统计模型为例,由于其应用受地域限制,普适性差,所以严重影响此类模型预测准确性和实用性,因此对于小麦白粉病的预测来说,急需适用范围广且准确性高的预测方法。
4.机器学习是一门多领域交叉学科,能通过训练并优化构建适应于样本规律的预测模型,帮助人们展示样本发生发展的基本规律,发掘各个数据间人们难以注意的隐藏关系,指导人们对样本的发展趋势做出准确高效的预测,因此机器学习在病虫害预测预报特别是小麦白粉病建模中的应用,为解决原有的预测预报方法存在问题提供了有效的工具。从已有的研究文献报道可发现,目前机器学习用于小麦白粉病的预测研究还比较少。
(三)
技术实现要素:
5.技术问题
6.本发明的目的是运用机器学习算法建立小麦白粉病发生程度的预测模型。该方法能够有效提升小麦白粉病发生程度预测模型的普适性、准确率性、实用性等,从而为小麦白粉病发生程度的预测模型在生产上大面积应用奠定基础。
7.本发明的目的是通过以下技术方案实现的:
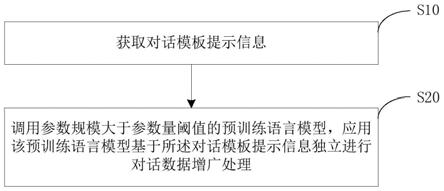
8.步骤一:获取小麦白粉病病情资料和相关气象资料;
9.步骤二:将小麦白粉病病情资料划为3类,利用过拟合方法将各类数据补齐,并对数据进行标准化;
10.步骤三:通过特征工程中的方差过滤方法对气象资料进行筛选,得到合适的预测因子;
11.步骤四:利用筛选后的预测因子,构建基于机器学习的小麦白粉病发生程度分类预测模型,并对其进行验证。
12.本发明内容
13.基于人工神经网络的小麦白粉病发生程度预测方法,包括:
14.步骤一:获取小麦白粉病病情资料和相关气象资料
15.小麦白粉病病情资料:选取四川南充(1985-1995,2009-2021)、巴中(1980-1995, 2009-2019)和江油(2020和2021)、河南南阳(1981-1996,2009-2019)、安阳(1991-2000, 2009-2019)、唐河(2020和2021)、新乡(2020和2021)和原阳(2020和2021),山东章丘(1982-1996,2012-2018)和淄博(2020和2021),江苏高邮(1981-1999)、睢宁(1981-1996)、徐州(2020和2021)和扬州(2020和2021),安徽六安(2020和2021)和庐江(2020和 2021)共172个数据。
16.气象数据:选取小麦扬花期初始日期为起点,以5d为一个时间段,分别选择小麦扬花期前1~5d、6~10d、11~15d、16~20d、21~25d和26~30d的平均气温(x1、x5、x9、 x
13
、x
17
、x
21
)、平均降水量(x2、x6、x
10
、x
14
、x
18
、x
22
)、平均相对湿度(x3、x7、 x
11
、x
15
、x
19
、x
23
)和平均日照时间(x4、x8、x
12
、x
16
、x
20
、x
24
)。
17.步骤二:将小麦白粉病病情资料划为3类,利用过拟合方法将各类数据补齐,并对数据进行标准化
18.将各地172个病情资料按发生程度分3类:0、1、2级划分为不发生或轻发生,共96个; 3级划分为中等发生,共42个;发生程度为4,5级划分为重发生,共34个。将病情资料与气象数据结合,利用过拟合方法将各类数据补齐,将每类数据均补为96,共得到288类数据。对这288类数据进行标准化,数据标准化的方法为新数据=(原数据-所有样本均值)/标准差。
19.步骤三:通过特征工程对气象资料进行筛选,得到合适的预测因子。
20.通过特征工程中的方差过滤处理288类数据,筛选得到适合的预测因子。
21.步骤四:利用筛选后的预测因子,构建一种基于机器学习的小麦白粉病发生程度的分类预测模型,并对其进行验证
22.利用上述筛选出的两个预测因子,将病情资料和气象资料按9∶1分为训练集和测试集,通过机器学习方法(k-近邻、随机森林、支持向量机和人工神经网络等)建立小麦白粉病发生程度的分类预测模型并对其进行检验,检验方法为:准确性(%)=测试集分类正确数/测试集总数*100%。
23.有效结果
24.本发明基于一种机器学习的小麦白粉病发生程度预测方法,即通过对四种机器学习方法筛选检验,建立了基于人工神经网络的小麦白粉病发生程度预测方法,此方法可用来预测全国各地的小麦白粉病发生程度,与国内外现有方法相比,本发明具有以下的技术优势:
25.1)预测因子符合流行学规律,适用性好,并易于获取。
26.2)预测模型适用范围广,准确性高,能够对全国各地的小麦白粉病发生程度进行预测。
具体实施方式
27.实施例:基于人工神经网络的小麦白粉病发生程度预测方法
28.步骤一:获取小麦白粉病病情资料和相关气象资料
29.小麦白粉病病情资料:选取四川南充(1985-1995,2009-2021)、巴中(1980-1995, 2009-2019)和江油(2020和2021)、河南南阳(1981-1996,2009-2019)、安阳(1991-2000, 2009-2019)、唐河(2020和2021)、新乡(2020和2021)和原阳(2020和2021),山东章丘(1982-1996,2012-2018)和淄博(2020和2021),江苏高邮(1981-1999)、睢宁(1981-1996)、徐州(2020和2021)和扬州(2020和2021),安徽六安(2020和2021)和庐江(2020和 2021)共172个数据。
30.气象数据:选取小麦扬花期初始日期为起点,以5d为一个时间段,分别选择小麦扬花期前1~5d、6~10d、11~15d、16~20d、21~25d和26~30d的平均气温(x1、x5、x9、 x
13
、x
17
、x
21
)、平均降水量(x2、x6、x
10
、x
14
、x
18
、x
22
)、平均相对湿度(x3、x7、 x
11
、x
15
、x
19
、x
23
)和平均日照时间(x4、x8、x
12
、x
16
、x
20
、x
24
)。
31.步骤二:将小麦白粉病病情资料划为3类,利用过拟合方法将各类数据补齐,并对数据进行标准化
32.将各地172个病情资料按发生程度分3类:0、1、2级划分为不发生或轻发生,共96个;3级划分为中等发生,共42个;发生程度为4,5级划分为重发生,共34个。将病情资料与气象数据结合,利用过拟合方法将各类数据补齐,将每类数据均补为96,共得到288类数据。对这288类数据进行标准化,数据标准化的方法为新数据=(原数据-所有样本均值)/标准差。
33.步骤三:通过特征工程对气象资料进行筛选,得到合适的预测因子;
34.通过特征工程中的方差过滤处理288数据,得到:抽穗期前6-10天平均相对湿度(x7)、抽穗期前11-15天平均相对湿度(x
11
)、抽穗期前16-20天平均相对湿度(x
15
)和抽穗期前 26-30天平均相对湿度(x
23
)这4个因子;将抽穗期前6-10天平均相对湿度(x7)、抽穗期前11-15天平均相对湿度(x
11
)和抽穗期前16-20天平均相对湿度(x
15
)进行合并,最终得到小麦抽穗期前6-20天平均相对湿度,小麦抽穗期前26-30天平均相对湿度这两个预测因子。步骤四:利用筛选后的预测因子,构建基于人工神经网络的小麦白粉病发生程度的分类预测模型,并对其进行验证
35.本实施方式中一种基于机器学习的小麦白粉病发生程度预测方法,所述全连接神经网络共有5层,包括一个输入层、三个隐含层和一个输出层;采用relu激活函数,优化函数为1bfgs。该全连接神经网络的输入为小麦抽穗期前6-20天平均相对湿度,小麦抽穗期前26-30天平均相对湿度这两个预测因子,输出为轻发生或不发生、中等发生和重发生3类。训练好的模型对于小麦白粉病发生程度的预测准确性可达83%。
附图说明
36.图1为一种基于机器学习的小麦白粉病发生程度预测方法的流程图。
(一)技术领域
1.本发明“一种基于机器学习的小麦白粉病发生程度预测方法”可用于小麦白粉病发生程度的预测,属于植物病害领域。
(二)
背景技术:
2.小麦白粉病是由专性寄生真菌blumeria graminis f.sp.tritici引起的气传性病害,在世界各小麦种植区内广泛发生。现已成为我国20多个省(直辖市)小麦生产上的常发性病害之一。近年来,每年的发生面积一直保持在600-1000万公顷。小麦白粉病发生早且重的情况下,会严重影响小麦的生长发育,造成小麦分蘖数、成穗数和穗粒数等减少,千粒重下降,导致小麦产量降低,严重流行年份产量损失可达30%以上,甚至绝产。
3.病害预测是病害防治的重要依据,建立准确性较高的预测模型对小麦白粉病的防控有重要意义。前人在小麦白粉病的预测预报研究方面确实做了不少工作,其方法主要包括经验法或类比法、数理统计模型、系统模拟模型、专家评估、专家系统等。但已有的这些预测方法各自均存在不同的缺点或缺陷,以小麦白粉病建模研究较多的数理统计模型为例,由于其应用受地域限制,普适性差,所以严重影响此类模型预测准确性和实用性,因此对于小麦白粉病的预测来说,急需适用范围广且准确性高的预测方法。
4.机器学习是一门多领域交叉学科,能通过训练并优化构建适应于样本规律的预测模型,帮助人们展示样本发生发展的基本规律,发掘各个数据间人们难以注意的隐藏关系,指导人们对样本的发展趋势做出准确高效的预测,因此机器学习在病虫害预测预报特别是小麦白粉病建模中的应用,为解决原有的预测预报方法存在问题提供了有效的工具。从已有的研究文献报道可发现,目前机器学习用于小麦白粉病的预测研究还比较少。
(三)
技术实现要素:
5.技术问题
6.本发明的目的是运用机器学习算法建立小麦白粉病发生程度的预测模型。该方法能够有效提升小麦白粉病发生程度预测模型的普适性、准确率性、实用性等,从而为小麦白粉病发生程度的预测模型在生产上大面积应用奠定基础。
7.本发明的目的是通过以下技术方案实现的:
8.步骤一:获取小麦白粉病病情资料和相关气象资料;
9.步骤二:将小麦白粉病病情资料划为3类,利用过拟合方法将各类数据补齐,并对数据进行标准化;
10.步骤三:通过特征工程中的方差过滤方法对气象资料进行筛选,得到合适的预测因子;
11.步骤四:利用筛选后的预测因子,构建基于机器学习的小麦白粉病发生程度分类预测模型,并对其进行验证。
12.本发明内容
13.基于人工神经网络的小麦白粉病发生程度预测方法,包括:
14.步骤一:获取小麦白粉病病情资料和相关气象资料
15.小麦白粉病病情资料:选取四川南充(1985-1995,2009-2021)、巴中(1980-1995, 2009-2019)和江油(2020和2021)、河南南阳(1981-1996,2009-2019)、安阳(1991-2000, 2009-2019)、唐河(2020和2021)、新乡(2020和2021)和原阳(2020和2021),山东章丘(1982-1996,2012-2018)和淄博(2020和2021),江苏高邮(1981-1999)、睢宁(1981-1996)、徐州(2020和2021)和扬州(2020和2021),安徽六安(2020和2021)和庐江(2020和 2021)共172个数据。
16.气象数据:选取小麦扬花期初始日期为起点,以5d为一个时间段,分别选择小麦扬花期前1~5d、6~10d、11~15d、16~20d、21~25d和26~30d的平均气温(x1、x5、x9、 x
13
、x
17
、x
21
)、平均降水量(x2、x6、x
10
、x
14
、x
18
、x
22
)、平均相对湿度(x3、x7、 x
11
、x
15
、x
19
、x
23
)和平均日照时间(x4、x8、x
12
、x
16
、x
20
、x
24
)。
17.步骤二:将小麦白粉病病情资料划为3类,利用过拟合方法将各类数据补齐,并对数据进行标准化
18.将各地172个病情资料按发生程度分3类:0、1、2级划分为不发生或轻发生,共96个; 3级划分为中等发生,共42个;发生程度为4,5级划分为重发生,共34个。将病情资料与气象数据结合,利用过拟合方法将各类数据补齐,将每类数据均补为96,共得到288类数据。对这288类数据进行标准化,数据标准化的方法为新数据=(原数据-所有样本均值)/标准差。
19.步骤三:通过特征工程对气象资料进行筛选,得到合适的预测因子。
20.通过特征工程中的方差过滤处理288类数据,筛选得到适合的预测因子。
21.步骤四:利用筛选后的预测因子,构建一种基于机器学习的小麦白粉病发生程度的分类预测模型,并对其进行验证
22.利用上述筛选出的两个预测因子,将病情资料和气象资料按9∶1分为训练集和测试集,通过机器学习方法(k-近邻、随机森林、支持向量机和人工神经网络等)建立小麦白粉病发生程度的分类预测模型并对其进行检验,检验方法为:准确性(%)=测试集分类正确数/测试集总数*100%。
23.有效结果
24.本发明基于一种机器学习的小麦白粉病发生程度预测方法,即通过对四种机器学习方法筛选检验,建立了基于人工神经网络的小麦白粉病发生程度预测方法,此方法可用来预测全国各地的小麦白粉病发生程度,与国内外现有方法相比,本发明具有以下的技术优势:
25.1)预测因子符合流行学规律,适用性好,并易于获取。
26.2)预测模型适用范围广,准确性高,能够对全国各地的小麦白粉病发生程度进行预测。
具体实施方式
27.实施例:基于人工神经网络的小麦白粉病发生程度预测方法
28.步骤一:获取小麦白粉病病情资料和相关气象资料
29.小麦白粉病病情资料:选取四川南充(1985-1995,2009-2021)、巴中(1980-1995, 2009-2019)和江油(2020和2021)、河南南阳(1981-1996,2009-2019)、安阳(1991-2000, 2009-2019)、唐河(2020和2021)、新乡(2020和2021)和原阳(2020和2021),山东章丘(1982-1996,2012-2018)和淄博(2020和2021),江苏高邮(1981-1999)、睢宁(1981-1996)、徐州(2020和2021)和扬州(2020和2021),安徽六安(2020和2021)和庐江(2020和 2021)共172个数据。
30.气象数据:选取小麦扬花期初始日期为起点,以5d为一个时间段,分别选择小麦扬花期前1~5d、6~10d、11~15d、16~20d、21~25d和26~30d的平均气温(x1、x5、x9、 x
13
、x
17
、x
21
)、平均降水量(x2、x6、x
10
、x
14
、x
18
、x
22
)、平均相对湿度(x3、x7、 x
11
、x
15
、x
19
、x
23
)和平均日照时间(x4、x8、x
12
、x
16
、x
20
、x
24
)。
31.步骤二:将小麦白粉病病情资料划为3类,利用过拟合方法将各类数据补齐,并对数据进行标准化
32.将各地172个病情资料按发生程度分3类:0、1、2级划分为不发生或轻发生,共96个;3级划分为中等发生,共42个;发生程度为4,5级划分为重发生,共34个。将病情资料与气象数据结合,利用过拟合方法将各类数据补齐,将每类数据均补为96,共得到288类数据。对这288类数据进行标准化,数据标准化的方法为新数据=(原数据-所有样本均值)/标准差。
33.步骤三:通过特征工程对气象资料进行筛选,得到合适的预测因子;
34.通过特征工程中的方差过滤处理288数据,得到:抽穗期前6-10天平均相对湿度(x7)、抽穗期前11-15天平均相对湿度(x
11
)、抽穗期前16-20天平均相对湿度(x
15
)和抽穗期前 26-30天平均相对湿度(x
23
)这4个因子;将抽穗期前6-10天平均相对湿度(x7)、抽穗期前11-15天平均相对湿度(x
11
)和抽穗期前16-20天平均相对湿度(x
15
)进行合并,最终得到小麦抽穗期前6-20天平均相对湿度,小麦抽穗期前26-30天平均相对湿度这两个预测因子。步骤四:利用筛选后的预测因子,构建基于人工神经网络的小麦白粉病发生程度的分类预测模型,并对其进行验证
35.本实施方式中一种基于机器学习的小麦白粉病发生程度预测方法,所述全连接神经网络共有5层,包括一个输入层、三个隐含层和一个输出层;采用relu激活函数,优化函数为1bfgs。该全连接神经网络的输入为小麦抽穗期前6-20天平均相对湿度,小麦抽穗期前26-30天平均相对湿度这两个预测因子,输出为轻发生或不发生、中等发生和重发生3类。训练好的模型对于小麦白粉病发生程度的预测准确性可达83%。
附图说明
36.图1为一种基于机器学习的小麦白粉病发生程度预测方法的流程图。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。