1.本发明属于自然语言处理技术领域,具体涉及一种生成式文本摘要方法。
背景技术:
2.随着当今时代在计算机硬件设备技术的提升下计算机性能也随之飞速提高,以及互联网行业的蓬勃发展。个人计算机的普及和迅速发展的互联网行业导致了各种文本信息通过各种各样的载体出现在人们的日常生活中。由于这个时代信息量巨大,人们面临着一个不可避免的、具有挑战性的信息过载问题,同时由于网络上庞大的信息量,也给信息检索带来了困难。因此,如何解决信息过载造成的数据灾难问题,有效解决人们从文本中获取信息困难的问题,是目前全球领域内关注的热点内容之一。文本摘要旨在将文本或文本集合转换为包含关键信息的简短摘要,该技术的出现解决了信息过载的问题。
3.早期自动文本摘要技术研究采用基于规则的方法和基于传统机器学习的方法,但其因为很难按照人类理解文章那样来学习文章导致其生成摘要不尽人意。随着深度学习相关研究的发展,循环神经网络模型具有灵活的计算步骤,其输出依赖于之前的计算,这使得它能够捕获语言中的上下文依赖关系,并能够对各种文本长度建模。但传统的基于循环神经网络的框架存在一个潜在的问题,在实际模型预测过程中,由于在预测时模型预测的词汇是开放的,假如预测文本中存在没有在生成单词的词表中的词,模型将无法对其进行处理和生成,这就是未登录词(out-of-vocabulary,oov)问题。因为在摘要生成过程中原文某些生僻词可能包含重要的信息,但是因为其频率比较低导致在训练时无法加入词表,并且由于现在模型越来越大,加入新词后模型重新训练代价十分高,导致传统方法并不能很好解决oov问题。
技术实现要素:
4.本发明的目的在于,针对背景技术存在的缺陷,提出了一种生成式文本摘要方法。
5.为实现上述目的,本发明采用的技术方案如下:
6.一种生成式文本摘要方法,包括以下步骤:
7.步骤1、数据爬取:
8.数据源网站爬取新闻文本原始语料,进行解析后,得到新闻文本;
9.步骤2、数据预处理:
10.s21.数据清洗:对步骤1得到的新闻文本进行数据清洗,得到清洗后的新闻文本;
11.s22.数据格式处理:对清洗后的新闻文本进行数据格式处理,得到处理后的新闻文本;
12.s23.分词:对处理后的新闻文本采用语法分析分词算法进行分词处理,得到分词后的新闻文本;
13.s24.音节标注:对分词后的新闻文本,采用语音和谐规律处理算法进行音节标注,采用1表示元音、0表示辅音,构造与分词后的新闻文本相同维度的音节向量,得到新闻文本
音节数据;
14.步骤3、文本特征表示:
15.s31.初始化:首先,遍历步骤s23得到的分词后的新闻文本,得到分词后的新闻文本中词的个数v以及每个词的词频,将v个词按照词频从大到小的顺序排列,构建词汇表vocab:{w1,w2,
…
,wi,
…
,wv},wi代表词汇表中的第i个词;根据词在词汇表中的位置,生成v维度的one-hot编码,对于第i个词wi,其生成的one-hot编码记为one_hoti;
16.s32.生成词向量并迭代训练:采用步骤s31中生成的one-hot编码进行词向量的生成;对于词wi,生成过程具体为:
17.a.定义词向量的长度为n,窗口大小为c;
18.b.随机初始化权重矩阵wv×n,计算得到中间层的隐藏向量hi:
[0019][0020]
c.随机初始化权重矩阵w
′n×v,计算词wi的概率分布y:
[0021]
y=softmax(hi·w′n×v)
[0022]
d.迭代训练:采用梯度下降的方法,不断迭代训练,当one_hot
i-y低于预设的阈值时,停止迭代,得到训练后的中间层的隐藏向量hi′
,训练后的中间层的隐藏向量hi′
为词wi训练后的词向量hi′
;
[0023]
s33.音节信息的融入:将步骤s24得到的音节向量与步骤s32得到的词向量 hi′
拼接,得到融入音节信息的词向量h
″i;
[0024]
s34.基于神经网络的词向量调整:从分词后的新闻文本中随机抽取一个包含词wi的句子w,假设句子w由m个词组成,词wi在句子w中排第j位,记为wj, w={w1,w2,
…
wm},句子w对应的融入音节信息的句向量为其中表示在句子w中排第j位的词wj对应的融入音节信息的词向量;然后,将融入音节信息的句向量h中的每一个词向量输入神经网络中,得到隐层向量g={g1,g2,
…
,gj,
…
,gm},其中,gj为词向量的隐层向量;
[0025]
s35.基于注意力机制的词向量调整:
[0026]
a.针对隐层向量g={g1,g2,
…
,gj,
…
,gm},计算注意力权重:
[0027][0028]
其中,v
′
和m
′
为随机初始化的矩阵,v
′
为1行、x列的矩阵,m
′
为x行、1 列的矩阵,x为预设的值,b为随机初始化的值;
[0029]
b.采用梯度下降法训练v
′
、m
′
和b,得到训练好的注意力权重a
′
= [a1′
,a2′
...,aj′
...,am′
];
[0030]
c.采用训练好的注意力权重对隐层向量gj进行更新,得到更新后的隐层向量g
′j:
[0031][0032]
步骤4、新闻摘要生成:
[0033]
s41.词向量表示:假设新闻向量s由k个句向量构成,s={s1,
…
,s
p
,
…
,sk},其中,
句向量s
p
由m
′
个词向量组成,s
p
={g
′1,
…
,g
′q,
…
,g
′m′
},g
′q表示在句向量s
p
中位置为q的词向量;
[0034]
s42.编码:将步骤s41的新闻向量s输入lstm模型进行编码,得到语义向量t:
[0035]
t=lstm(s)
[0036]
s43.解码:将步骤s42得到的语义向量t输入另一个lstm模型进行解码,生成文本摘要向量s
′
:
[0037]s′
=lstm(t)
[0038]
文本摘要向量s
′
由k
′
个句向量构成,s
′
={s1′
,
…
,s
p
′
′…
,sk′
′
},其中句向量s
p
′
′
由m
″
个词向量组成;
[0039]
s44.未登录词复制:
[0040]
a.计算句向量s
p
中词向量g
′q的概率分布:
[0041]
p
vocab
(g
′q)=softmax(v
″
(v
″′
[s
p
,s
p
′
′
] b
′
) b
″
)
[0042]
其中,[s
p
,s
p
′
′
]表示将步骤s41得到的句向量s
p
和步骤s43得到的句向量s
p
′
′
进行向量拼接操作;v
″
和v
″′
为随机初始化得到的矩阵,v
″
的维度为1*x
′
,v
″′
的维度为x
′
*1,x
′
为预设的值;b
′
和b
″
为随机初始化的数值;
[0043]
b.计算词向量g
′q的生成概率p
gen
:
[0044]
p
gen
=sigmoid(s
p
·
m1 sp
′
′
·
m2 a
′
·
m3 b
gen
)
[0045]
其中,m1、m2和m3为随机初始化得到的矩阵,m1、m2、m3的维度分别为 m
′
*m
″
、m
″
*m
″
、m
′
*m
″
;b
gen
为随机初始化的数值;
[0046]
c.得到词向量g
′q的最终生成概率:
[0047][0048]
其中aj表示步骤s35的注意力权重;
[0049]
d.若p
vocab
(g
′q)为0向量,则从新闻向量s中更新词向量g
′q到s
′
中覆盖注意力权重最高的词向量;若p
vocab
(g
′q)为非零向量,则将生成文本摘要向量s
′
中注意力权重最高的词向量更新为最终生成概率最高的词向量;
[0050]
s45.映射:对于步骤s44更新后的生成文本摘要向量s
′
,将其中每个词向量映射成词,得到最终的文本摘要。
[0051]
本发明的有益效果为:
[0052]
本发明提供的一种生成式文本摘要方法,在word2vec的cbow模型基础上进行改进,融入了音节标注信息增强了文本的特征表示能力;采用基于lstm 的encoder-decoder框架实现新闻摘要生成,并在生成过程中着力解决未登录词问题,有效提升了新闻摘要生成的效果。
附图说明
[0053]
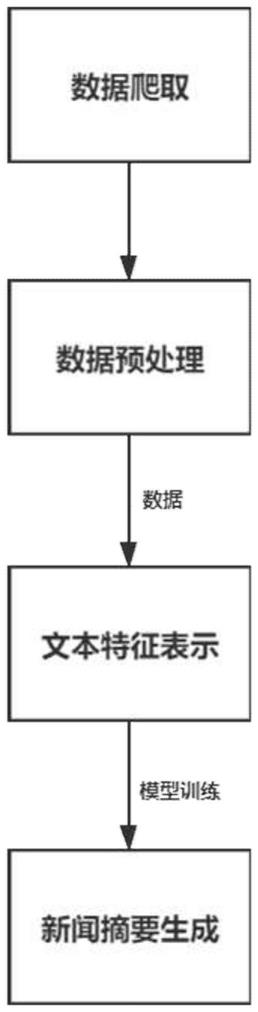
图1为本发明提供的一种生成式文本摘要方法的流程图。
具体实施方式
[0054]
下面结合附图对本发明的方案进行详细阐述。
[0055]
一种生成式文本摘要方法,具体包括以下步骤:
[0056]
步骤1、数据爬取:
[0057]
本发明实施例爬取新闻网站上的新闻文本作为后续数据预处理的基础数据,比如中央广播网上的新闻文本;具体步骤如下:
[0058]
s11.数据采集:在scrapy爬虫框架中输入目标数据源网站的url地址,获得格式为json字符串的新闻文本原始语料;
[0059]
s12.数据解析:对步骤s11得到的新闻文本原始语料进行正则表达式解析,得到新闻文本;所述新闻文本由多个句子组成,句子由多个词组成;
[0060]
步骤2、数据预处理:
[0061]
该步骤主要涉及对步骤s12得到的新闻文本进行预处理,以提高下游模型的数据分析处理能力。数据预处理过程包括:数据清洗、数据格式处理、分词和音节标注。具体为:
[0062]
s21.数据清洗:对步骤s12得到的新闻文本采用基于sql(structuredquerylanguage,结构化查询语言)或者excel的人工校对方法进行数据清洗,具体可以采用完整性检查、拼写检查更正、去除非文本信息、丢弃无效数据等手段,得到清洗后的新闻文本;
[0063]
s22.数据格式处理:对清洗后的新闻文本采用基于sql或者excel的人工校对方法进行数据格式处理,具体包括大小写转换、数值格式统一等,得到处理后的新闻文本;
[0064]
s23.分词:对处理后的新闻文本采用语法分析分词算法进行分词处理,得到分词后的新闻文本;分词后的新闻文本由句子组成,句子由词组成;该步骤的分词处理,是对处理后的新闻文本进行分词,在新闻文本中某些字与字之间添加标识符,用来表示新闻文本中哪些字组成了一个词,并不是分词处理后就变成了词汇表;例如[我/喜欢/吃/苹果]就是文本[我喜欢吃苹果]的分词处理结果。
[0065]
s24.音节标注:的元音和辅音区分明显,同时元音的和辅音的表达含义有一定的区别,根据此特征,本发明采用1和0区分该词是元音还是辅音,采用1表示元音、0表示辅音。对分词后的新闻文本,采用语音和谐规律处理算法进行音节标注,构造与分词后的新闻文本相同维度的音节向量,获得新闻文本音节数据。
[0066]
步骤3、文本特征表示:
[0067]
该步骤主要是针对传统文本特征表示方法生成文本特征离散稀疏的问题,在word2vec的cbow(continuousbag-of-wordsmodel)模型基础上进行改进,融入了音节标注信息以增强模型的文本特征表示能力,并利用bi-lstm和注意力机制对文本表征能力进行提升。
[0068]
s31.初始化:采用步骤s23得到的分词后的新闻文本生成one-hot编码。具体过程为:首先,遍历分词后的新闻文本,得到分词后的新闻文本中词的个数v以及每个词的词频,将v个词按照词频从大到小的顺序排列,构建词汇表vocab:{w1,w2,
…
,wi,
…
,wv},wi代表词汇表中的第i个词;根据每个词在词汇表中的位置,生成一个v维度的one-hot编码,对于第i个词wi,表示它在词汇表vocab中排在第i位,其生成的one-hot编码记为one_hoti,具体生成过程如下:
[0069]
对于词wi,它在词汇表vocab中排在第i位,则其对应的one-hot编码one_hoti为:
[0,0...,1,0,0...,0],该编码的维度为v,第i位为1,其余所有位均为 0。
[0070]
s32.生成词向量并迭代训练:采用步骤s31中生成的one-hot编码来生成词向量;对于词wi,生成过程具体为:
[0071]
a.定义词向量的长度为n,窗口大小为c;
[0072]
b.按照高斯分布,随机初始化一个权重矩阵wv×n,其中v表示该矩阵的行数,即one-hot编码的维度v,n表示该矩阵的列数,即定义的词向量长度n;将词wi的前面c个词w
i-c
,w
i-c 1
...,w
i-1
和后面c个词w
i 1
,w
i 2
...,w
i c
的one-hot 编码,即 one_hot
i-c
,one_hot
i-c 1
,...,one_hot
i-1
,one_hot
i 1
,one_hot
i 2
,...,one_hot
i c
分别与wv×n相乘后再取平均,得到中间层的隐藏向量hi;计算公式如下:
[0073][0074]
c.按照高斯分布,随机初始化一个权重矩阵w
′n×v,其中n表示该矩阵的行数,即定义的词向量长度n,v表示该矩阵的列数,即one-hot编码的维度v;将隐藏向量hi右乘w
′n×v,再经过激活函数softmax,得到词wi的概率分布y:
[0075]
y=softmax(hi·w′n×v)
[0076]
d.迭代训练:迭代训练的目标是使得词wi的概率分布y最接近真实的概率分布,即最接近词wi的one-hot编码。具体为:采用梯度下降的方法,将one_hot
i-y 的梯度反向传播给wv×n和w
′n×v,不断修正wv×n和w
′n×v的参数,使得 one_hot
i-y逐渐减小;当one_hot
i-y低于一个预设的阈值时(该阈值为自定义,设定时一般选取趋于0的数值,例如0.001)停止迭代,即可得到训练后的中间层的隐藏向量hi′
,该隐藏向量即为词wi训练后的词向量hi′
;
[0077]
s33.音节信息的融入:将步骤s24得到的音节向量与步骤s32得到的词向量 hi′
拼接,得到词wi融入音节信息的词向量h
″i;
[0078]
s34.基于bi-lstm(双向长短期记忆网络)进行词向量调整:通过 bi-lstm(双向长短期记忆网络)可以使得步骤s33得到的词wi融入音节信息的词向量h
″i中包含更多的上下文信息,具体过程如下:
[0079]
对步骤s33得到的词wi融入音节信息的词向量h
″i进行调整,首先从分词后的新闻文本中随机抽取一个包含词wi的句子w,假设这个句子w由m个词组成,词wi在句子w中排在第j位,表示为wj,则该句子可表示成词的集合w= {w1,w2,
…
wj,
…
wm}(步骤s31提到的词wi,是指在词汇表vocab中排第i位的词,而此处的w1,w2,
…
wm指的是在句子w中位置为1,2,...,m的词)。该句子对应的融入音节信息的句向量为其中表示在句子w中排第j位的词wj对应的融入音节信息的词向量;然后,将融入音节信息的句向量h 中的每一个融入音节信息的词向量依次输入一个由 bi-lstm单元构成的神经网络中,得到对应的隐层向量:
[0080][0081]
其中,gj是融入音节信息的词向量的隐层向量,g是句子w中m个词的融入音节信息的词向量对应的隐层向量g1,g2,
…
,gm组成的集合;
[0082]
s35.基于注意力机制的词向量调整:不同的词对其他词的影响程度不同,利用注意力机制对步骤s34获得的词wj的隐层向量gj进行调整,接收其他词不同程度的影响。具体
为:
[0083]
a.针对m个词的隐层向量g={g1,g2,
…
,gj,
…
,gm},计算注意力权重 [a1,a2...,aj...,am],公式如下:
[0084][0085]
其中,a表示注意力权重a1,a2...,aj...,am组成的向量,aj是一个数值, softmax函数会得到一个m维度的向量,aj就是softmax函数输出的向量中第j位的数值;v
′
和m
′
是两个按照高斯分布随机初始化的矩阵,v
′
为1行、x列的矩阵, m
′
为x行、1列的矩阵(此处的x是一个预设的值,其取值最好趋近于向量gj的长度),b是一个按照高斯分布随机初始化的值;
[0086]
b.采用梯度下降法训练上述公式中的v
′
、m
′
和b,得到训练好的注意力权重 a
′
=[a1′
,a2′
...,aj′
...,am′
];
[0087]
c.采用训练好的注意力权重a
′
=[a1′
,a2′
...,aj′
...,am′
]对隐层向量gj进行更新:
[0088][0089]
得到词wj的更新后的隐层向量g
′j;
[0090]
步骤4、新闻摘要生成:
[0091]
该步骤主要针对传统新闻摘要生成方法效果不佳的问题,采用基于lstm的 encoder-decoder框架实现新闻摘要生成,并在生成过程中着力解决未登录词 (out-of-vocabulary,oov)问题,以提升新闻摘要生成的效果。
[0092]
s41.词向量表示:对步骤s23得到的分词后的新闻文本进行摘要生成。假设新闻向量s由k个句向量构成,即s={s1,
…
,s
p
,
…
,sk},其中,句向量s
p
由m
′
个词向量组成,s
p
={g
′1,
…
,g
′q,
…
,g
′m′
},其中g
′q表示在句向量s
p
中位置为q的词向量;
[0093]
s42.编码:
[0094]
将步骤s41的新闻向量s输入单向lstm模型进行编码,lstm基于新闻向量s生成一个语义向量t:
[0095]
t=lstm(s)
[0096]
该语义向量t包含了该新闻的全部信息。
[0097]
s43.解码:将步骤s42得到的语义向量t输入另一个不同的单向lstm模型进行解码,生成文本摘要向量s
′
;生成的文本摘要向量s
′
由k
′
个句向量构成, s
′
={s1′
,
…
,s
p
′
′…
,sk′
′
},其中句向量s
p
′
′
由m
″
个词向量组成,s
p
′
′
={g
′1,
…g′
′
,
…ꢀg′m″
},g
′q′
为句向量s
p
′
′
中位置为q
′
的词向量表示(lstm用作解码时,可以将一个向量扩展为多个向量):
[0098]s′
=lstm(t)
[0099]
s44.未登录词复制:在步骤s43获得文本摘要向量s
′
后,需判断s
′
中的每个词向量是否是未登录词的向量(即判断vocab词汇表中是否有词对应的词向量与s
′
中的词向量一致,如果是,则需要进行词复制操作)。具体过程为:
[0100]
a.计算句向量s
p
中词向量g
′q的概率分布p
vocab
,公式如下:
[0101]
p
vocab
(g
′q)=softmax(v
″
(v
″′
[s
p
,s
p
′
′
] b
′
) b
″
)
[0102]
其中[s
p
,s
p
′
′
]表示将步骤s41得到的句向量s
p
和步骤s43得到的句向量s
p
′
′
进行向量拼接操作;v
″
和v
″′
是两个根据高斯分布随机初始化得到的矩阵,v
″
的维度为1*x
′
,v
″′
的维度为x
′
*1(x
′
是一个预设的值,其取值在1000左右);b
′
和b
″
是两个根据高斯分布随机初始化的数值;v
″
和v
″′
、b
′
和b
″
都需要通过梯度下降法不断修正它们的参数,以提高p
vocab
(g
′q)的精确度。
[0103]
b.计算词向量g
′q的生成概率p
gen
:
[0104]
p
gen
=sigmoid(s
p
·
m1 s
p
′
′
·
m2 a
′
·
m3 b
gen
)
[0105]
其中,m1、m2和m3是根据高斯分布随机初始化得到的矩阵,s
p
是步骤s41 得到的句向量,s
p
′
′
是骤s43得到的句向量,a
′
是步骤s35得到的训练好的注意力权重的集合,b
gen
是根据高斯分布随机初始化的数值;m1、m2、m3的维度分别为m
′
*m
″
、m
″
*m
″
、m
′
*m
″
;m1、m2、m3和b
gen
都需要通过梯度下降法不断修正它们的参数,以提高p
gen
的精确度。
[0106]
c.综合上述的概率分布p
vocab
和生成概率p
gen
,即可得到词向量g
′q的最终生成概率:
[0107][0108]
其中aj表示步骤s35的注意力权重,m
′
表示步骤s41的句向量长度。
[0109]
d.若p
vocab
(g
′q)计算出来为0向量,说明步骤s31的词汇表vocab中所有词对应的词向量与g
′q都不相同,此时需要直接从s中更新词向量g
′q到s
′
中覆盖注意力a
′
权重最高的词向量;若p
vocab
(g
′q)计算出来为非零向量,则说明词向量g
′q对应的词存在于步骤s31的词汇表vocab中,此时则根据p(g
′q)的概率分布,选择生成概率最高的词向量,即将生成文本摘要向量s
′
中注意力a
′
权重最高的词向量更新为最终生成概率最高的词向量,从而解决了oov问题;
[0110]
s45.映射:对于步骤s44更新后得到的生成文本摘要向量s
′
,将s
′
中每个句向量s
p
′
′
中的词向量g
′q′
映射成词,即可得到最终的文本摘要s
final
={w
1final
,
···
,w
ifinal
,
…
,wk′
final
},其中句子w
ifinal
由m
′
个词组成,w
ifinal
={w1,w2,
…
wm′
},其中w1,w2,
…
wm′
是词。
[0111]
至此,本发明实现了一种生成式文本摘要方法。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。