一种基于多模态特征融合的rgb-d图像语义分割方法
技术领域
1.本发明属于计算机视觉领域,具体涉及一种基于多模态特征融合的rgb-d图像语义分割方法。
背景技术:
2.图像语义分割是计算机视觉领域重点研究的基础任务,目的是为图像的每个像素分配一个类别标签,实现像素级的场景理解,广泛应用于医学影像、自动驾驶、人脸识别、目标检测等方面。一般情况下,由于室内场景环境复杂、物体杂乱且琐碎、遮挡严重,对分割算法的性能要求更高且更具有挑战性。根据是否应用深度神经网络,图像语义分割方法可划分为传统方法和基于深度学习的方法,其中传统方法可分为基于阈值、边缘、区域、聚类、图论及特定理论等六类方法。而需要大量语义信息的分割任务不适合采用传统的图像分割方法,因此将深度学习引入到图像分割领域的方法应运而生,此方法可以充分利用图像的语义信息。
3.早期的图像分割方法是从彩色图像(rgb图像)中提取特征信息进行分割。2014年long等人提出了全卷积神经网络(fcn),可以使用任意尺寸的图像作为输入数据,是第一个实现端到端处理的分割网络模型。fcn网络在下采样时图像分辨率减少,丢失部分特征信息,分割效果不理想,针对该问题lin等人、ronneberger等人和zhao等人分别提出了使用解码器恢复图像分辨率、结合高级语义信息和低级细节特征、聚合不同尺度的上下文信息等方法提高分割性能。rgb图像分割的问题在于图像只提供颜色、纹理、形状等二维视觉信息,对于具有相似颜色、纹理的物体缺乏相应的几何信息,容易造成许多像素分类错误,不能得到较好的语义分割结果,因此开启了rgb-d图像语义分割方法的研究。
4.直接将rgb和深度信息简单地拼接或相加输入到已存在的单模态rgb分割网络中,虽然分割效果有所提高,但并未充分利用深度图所提供的几何信息,不能有效地融合rgb和深度信息。而使用两个独立的网络分支分别处理rgb和深度信息,并设计特征融合模块有利于高效利用rgb和深度特征。尽管这些方法已经取得了不错的分割效果,但如何充分利用两种模态之间的互补性和差异性,如何增强编码器中信息的交互、传递以及特征提取能力等仍是需要深入研究的问题。
技术实现要素:
5.本发明的目的是提供一种高效的rgb-d室内场景语义分割方法,引入深度图像增强图像特征表示,从而解决rgb图像分割的限制性。根据端到端的rgb-d分割网络结构,设计一种基于多模态特征融合的rgb-d室内场景语义分割网络,高效地解决计算机视觉领域地语义分割任务。
6.为了达到上述目的,本发明采用了下列技术方案:
7.一种基于多模态特征融合的rgb-d图像语义分割方法,包括以下步骤:
8.步骤1,数据预处理,将单通道的深度图像转化为三通道的hha图像;
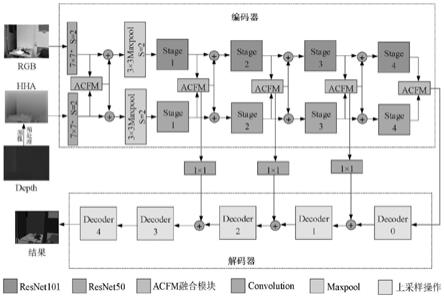
9.步骤2,将rgb和hha图像作为输入数据,输入注意力引导多模态交叉融合分割网络模型(acfne),所述模型遵循编码器-解码器结构,所述编码器从输入中提取语义特征,所述解码器采用上采样技术恢复输入分辨率,为每个输入像素分配一个语义类别。
10.进一步,所述步骤1中hha图像包含更多的空间信息,三通道分别表示水平视差高于地面的高度、像素的局部表面法线、推断的重力方向的角度。
11.进一步,所述步骤2中编码器对rgb和hha图像使用非对称双流分支,包括rgb编码器和深度编码器,所述rgb编码器和深度编码器分别以resnet-101网络和resnet-50网络作为主干网络,所述resnet-101网络和resnet-50网络均包括7
×
7卷积、最大池化操作和stage1、stage2、stage3和stage4四个阶段,并且改进组成主干网络的基本块,即在bottleneck中加入maxpool并行模块,记为mp_bottleneck,通过增加网络宽度的方式提高特征提取性能,如式(1)所示:
12.f
e_out
=w3(cat(w2(w1(f
in
)),m_p(w1(f
in
))
ꢀꢀꢀꢀ
(1)
13.其中,f
in
∈rh×w×c,h、w和c分别表示特征图的高度、宽度和通道数,w1,w2,w3分别表示1
×
1,3
×
3,1
×
1卷积操作,cat表示拼接操作,m_p表示最大池化操作,f
e_out
表示resnet网络每阶段的输出。
14.再进一步,在所述rgb编码器的stage1、stage2、stage3、stage4四个阶段添加全局特征提取模块,使用全局特征提取模块处理f
e_out
提取全局特征,并且将最终的全局特征和局部特征通过相加的方式结合起来,组成全局-局部特征提取模块,上述过程如式(2)~(4)所示:
15.f
gl
=f
e_out
gc(f
e_out
)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
16.gc=x conv1
×
1(relu(ln(conv1
×
1(y))))
ꢀꢀꢀꢀ
(3)
17.y=x
×
softmax(conv1
×
1(x))
ꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
18.其中,x表示全局特征提取模块模块的输入,gc表示全局特征,f
gl
表示全局-局部特征,conv1×1表示1
×
1卷积操作,ln表示批归一化操作。
19.更进一步,所述编码器还包括特征融合模块,在7
×
7卷积和每个阶段之后均进行rgb特征和深度特征的融合,并且将融合后的特征传输到rgb编码器和深度编码器,在编码器的每个阶段分别对rgb特征和深度特征重新加权,并在所述特征融合模块引入注意力机制,在通道和空间维度上进行注意力操作,如式(5)~(8)所示:
20.f
a_rgb
=cbam(f
rgb_in
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
21.f
a_hha
=cbam(f
hha_in
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
22.cbam=ca
×
σ(conv7×7(cat(avgpool(ca),maxpool(ca)))
ꢀꢀꢀꢀꢀꢀꢀ
(7)
23.ca=x
×
σ(mlp(avgpool(x) mlp(maxpool(x))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
24.其中,cbam表示注意力机制采用cbam模块,x表示cbam模块的输入,f
rgb_in
、f
hha_in
分别表示输入特征融合模块的rgb特征和深度特征,f
a_rgb
、f
a_hha
表示经cbam注意力机制处理后的特征输出,σ表示sigmoid激活函数,conv7×7表示7
×
7卷积操作,cat表示拼接操作,avgpool和maxpool分别表示平均池化和最大池化操作,mlp表示由两个1
×
1卷积层组成的多层感知机。
25.再进一步,所述特征融合模块使用交叉相乘的方式,选择经注意力机制处理后的一种模态特征乘以未经处理的另一种模态特征,从一种模态中选择可区分的信息辅助修正
另一种模态,之后进行交叉残差连接,使用经cbam模块处理后的特征与经另一模态信息修正后的原始模态信息交叉相加,进一步重用在网络处理过程中丢失的细节信息,增强两种模态之间的互补性,最后将两种模态信息通过相加的方式进行融合,如式(9)~(11)所示:
26.f
m_rgb
=f
rgb_in
×fa_hha
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
27.f
m_hha
=f
hha_in
×fa_rgb
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
28.f
f_out
=(f
a_rgb
f
m_hha
) (f
a_hha
f
m_rgb
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
29.其中,
×
表示逐元素相乘操作,f
m_rgb
、f
m_hha
分别表示经相乘操作修正后的特征输出,f
f_out
表示特征融合模块的最终输出结果。
30.进一步,所述解码器由5个相同的解码器单元组成,每个解码器单元由卷积层 bn层 relu激活函数和上采样操作组成,并在其中加入短接连接重用在训练过程中丢失的信息,短接连接使用1
×
1卷积改变编码器阶段的输出通道数,使其与解码器对应阶段的通道数相同可以进行相加操作。
31.再进一步,所述卷积层包括一个1
×
1卷积和两个3
×
3卷积,所述上采样操作采用双线性插值方法,经过5次上采样操作后图像分辨率恢复到输入大小。
32.更进一步,所述第一个解码器单元的输入通道数为2048,在图像分辨率增加的过程中通道数逐渐减少,最后一个解码器单元用于输出网络预测结果,去除其最后一个卷积层之后的批归一化操作,并且设置输出通道数为语义类别个数。
33.与现有技术相比本发明具有以下优点:
34.(1)为了改进resnet网络提取图像局部特征的不足,在rgb编码器中添加全局-局部特征提取模块。
35.(2)为有效融合rgb和深度特征,将注意力机制应用到特征融合模块,提出了注意力引导特征交叉融合模块,充分利用了两种模态之间的互补性和差异性,以更好地在多阶段利用融合的增强特征表示。
36.(3)本发明所提出的acfnet优于现有的大多数方法,在nyud v2数据集上表现出具有竞争力的分割性能,能够较好地适应室内场景的复杂性和多样性,表明了本文所提方法有效性
附图说明
37.图1为本发明的acfnet网络模型的整体架构;
38.图2为编码器详细设计结构,其中(a)为mp_bottleneck,(b)为全局特征提取模块(gc),(c)为全局-局部特征提取模块(gl);
39.图3为特征融合模块具体结构,其中(a)为cbam模块,(b)为acfm融合模块;
40.图4为解码器单元;
41.图5为本发明在nyud v2数据集上的分割结果可视化对比。
具体实施方式
42.实施例1
43.一种基于多模态特征融合的rgb-d图像语义分割方法,包括以下步骤:
44.步骤1,数据预处理,将单通道的深度图像转化为三通道的hha图像,三通道分别表
示水平视差高于地面的高度、像素的局部表面法线、推断的重力方向的角度;
45.步骤2,将rgb和hha图像作为输入数据,输入注意力引导多模态交叉融合分割网络模型(如图1所示),所述模型遵循编码器-解码器结构,所述编码器从输入中提取语义特征,所述解码器采用上采样技术恢复输入分辨率,为每个输入像素分配一个语义类别。
46.编码器对rgb和hha图像使用非对称双流分支,包括rgb编码器和深度编码器,所述rgb编码器和深度编码器分别以resnet-101网络和resnet-50网络作为主干网络,所述resnet-101网络和resnet-50网络均包括7
×
7卷积、最大池化操作和stage1、stage2、stage3和stage4四个阶段,并且改进组成主干网络的基本块,即在bottleneck中加入maxpool并行模块,记为mp_bottleneck,如图2中(a)所示,通过增加网络宽度的方式提高特征提取性能,如式(1)所示:
47.f
e_out
=w3(cat(w2(w1(f
in
)),m_p(w1(f
in
))
ꢀꢀꢀꢀ
(1)
48.其中,f
in
∈rh×w×c,h、w和c分别表示特征图的高度、宽度和通道数,w1,w2,w3分别表示1
×
1,3
×
3,1
×
1卷积操作,cat表示拼接操作,m_p表示最大池化操作,f
e_out
表示resnet网络每阶段的输出。
49.在所述rgb编码器的stage1、stage2、stage3、stage4四个阶段添加全局特征提取模块(gc),如图2中(b)所示,使用全局特征提取模块处理f
e_out
提取全局特征,并且将最终的全局特征和局部特征通过相加的方式结合起来,组成全局-局部特征提取模块(gl),如图2中(c)所示,上述过程如式(2)~(4)所示:
50.f
gl
=f
e_out
gc(f
e_out
)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
51.gc=x conv1
×
1(relu(ln(conv1
×
1(y))))
ꢀꢀꢀꢀ
(3)
52.y=x
×
softmax(conv1
×
1(x))
ꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
53.其中,x表示全局特征提取模块模块的输入,gc表示全局特征,f
gl
表示全局-局部特征,conv1×1表示1
×
1卷积操作,ln表示批归一化操作。
54.所述编码器还包括特征融合模块,在7
×
7卷积和每个阶段之后均进行rgb特征和深度特征的融合,并且将融合后的特征传输到rgb编码器和深度编码器,在编码器的每个阶段分别对rgb特征和深度特征重新加权,并在所述特征融合模块引入注意力机制,在通道和空间维度上进行注意力操作,如式(5)~(8)所示:
55.f
a_rgb
=cbam(f
rgb_in
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
56.f
a_hha
=cbam(f
hha_in
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
57.cbam=ca
×
σ(conv7×7(cat(avgpool(c a),maxpool(ca)))
ꢀꢀꢀꢀꢀꢀꢀ
(7)
58.ca=x
×
σ(mlp(avgpool(x) mlp(maxpool(x))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
59.其中,cbam表示注意力机制采用cbam模块(如图3中(a)所示),x表示cbam模块的输入,f
rgb_in
、f
hha_in
分别表示输入特征融合模块的rgb特征和深度特征,f
a_rgb
、f
a_hha
表示经cbam注意力机制处理后的特征输出,σ表示sigmoid激活函数,conv7×7表示7
×
7卷积操作,cat表示拼接操作,avgpool和maxpool分别表示平均池化和最大池化操作,mlp表示由两个1
×
1卷积层组成的多层感知机。
60.所述特征融合模块如图3中(b)所示,使用交叉相乘的方式,选择经注意力机制处理后的一种模态特征乘以未经处理的另一种模态特征,从一种模态中选择可区分的信息辅助修正另一种模态,之后进行交叉残差连接,使用经cbam模块处理后的特征与经另一模态
信息修正后的原始模态信息交叉相加,进一步重用在网络处理过程中丢失的细节信息,增强两种模态之间的互补性,最后将两种模态信息通过相加的方式进行融合,如式(9)~(11)所示:
61.f
m_rgb
=f
rgb_in
×fa_hha
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
62.f
m_hha
=f
hha_in
×fa_rgb
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
63.f
f_out
=(f
a_rgb
f
m_hha
) (f
a_hha
f
m_rgb
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
64.其中,
×
表示逐元素相乘操作,f
m_rgb
、f
m_hha
分别表示经相乘操作修正后的特征输出,f
f_out
表示特征融合模块的最终输出结果。
65.所述解码器由5个相同的解码器单元组成,如图4所示,每个解码器单元由卷积层 bn层 relu激活函数和上采样操作组成,并在其中加入短接连接重用在训练过程中丢失的信息,短接连接使用1
×
1卷积改变编码器阶段的输出通道数,使其与解码器对应阶段的通道数相同可以进行相加操作。
66.所述卷积层包括一个1
×
1卷积和两个3
×
3卷积,所述上采样操作采用双线性插值方法,经过5次上采样操作后图像分辨率恢复到输入大小。
67.所述第一个解码器单元的输入通道数为2048,在图像分辨率增加的过程中通道数逐渐减少,最后一个解码器单元用于输出网络预测结果,去除其最后一个卷积层之后的批归一化操作,并且设置输出通道数为语义类别个数,即40。
68.实施例2
69.在公共的rgb-d室内数据集nyud v2上应用本发明提出的分割网络模型,通过实验表明网络模型的有效性。
70.nyud v2数据集包含来自3个城市464个不同室内场景的1449张带有标签的rgb-d图像对,其中796张图像对用于训练,654张图像对用于测试环节,使用将894个不同物体分为40个类别的分类方式。通过提供分割可视化对比结果表明本发明所提分割网络acfnet的有效性。将去除特征融合模块acfm和全局-局部特征提取模块(gl)之后的网络结构记为基线网络(baseline),在图5中显示了acfnet在公共数据集nyud v2上的部分可视化结果,其中第一、二、三列依次表示rgb图像、hha图像和语义标签,第四、五列分别表示基线网络和acfnet的语义分割结果,并且用方框标记出对比区域。
71.本发明使用的语义分割性能度量标准为常见的像素精度(pixacc)、平均交并比(miou),其中pixacc为表示标记正确的像素占总像素的比例,其计算公式如式(12)所示;miou即求取所有物体类别交并比(iou)的平均值,本质为求真实值(ground truth)和预测值两个集合的交并比,其计算公式如式(13)所示:
[0072][0073][0074]
其中,k 1表示类别总数,i表示真实值,j表示预测值,p
ij
表示将真实值为i预测为j
的数量,p
ii
表示预测正确的数量,p
ij
和p
ji
分别表示假正(fp)和假负(fn)的数量。
[0075]
在nyud v2数据集上将本发明提出的acfnet与其他现有的方法进行比较,nyud v2数据集划分为40个语义类别,结果如表1所示,列出了本发明方法与其他方法在像素精度(pixacc)、平均交并比(miou)上的分割性能。
[0076]
表1在nyud v2数据集上与其他方法的比较
[0077][0078]
如表1所示,本发明方法以resnet-101 resnet-50为主干网络,在40个语义类别的nyud v2数据集上进行实验,两个评估指标像素精度和平均交并比分别为77.0%和51.5%。
[0079]
与仅使用rgb图像作为输入的refinenet相比,像素精度和平均交并比分别提高了3.4%和5.0%,实验结果表明加入深度特征对于分割性能有一定的提高;
[0080]
与同样使用注意力机制的acnet和canet相比,平均交并比分别提高了3.2%和0.3%;
[0081]
与主干网络使用resnet-101的sgnet相比,不仅网络模型有所简化,像素精度和平均交并比也分别提高了0.2%和0.5%;
[0082]
与融合特征同样使用双向多级传播策略的rafnet相比,像素精度和平均交并比分别提高了3.2%和4.0%;
[0083]
与较新的分割算法tsnet和rgb
×
d相比较,虽然网络层数相对较多,但平均交并比也有很大提高,分别提高了5.4%和0.4%。
[0084]
综上所述,本发明所提出的acfnet优于现有的大多数方法,在nyud v2数据集上表现出具有竞争力的分割性能,能够较好地适应室内场景的复杂性和多样性,表明了本文所提方法有效性。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。