1.本发明涉及港口码头堆场管理技术领域,具体涉及一种集装箱提箱序列的预测方法、系统和存储介质。
背景技术:
2.随着经济全球化、经济一体化的不断发展,国际贸易呈现蓬勃发展的态势,而集装箱运输作为航海运输最为常见的运输方式,依赖于港口码头、场站和仓库等基建设施的高效作业。近些年来,港口码头的吞吐量呈现爆发式增长,面对越来越大堆场管理压力,粗犷的装卸计划,缺乏数据支撑的调度决策带来的如作业效率低、作业成本高等问题愈发凸显,而如果集装箱的提箱序列能够预测,即代表集装箱在港口码头的堆存天数能够提前预测(堆存天数越大证明提柜时间越晚),那么码头堆场管理人员在制定装卸计划或在翻箱落位选择上,可以根据提箱序列来确定集装箱的堆垛方案,从而尽可能减少翻箱、频繁大车移动等作业,实现降本增效的目的。
3.目前,集装箱提箱序列主要通过集装箱卡车(简称集卡)到港作业前的预约机制来确定,部分小规模的集装箱码头甚至没有预约机制,而即使港口具备预约机制,也存在以下缺点:(1)集装箱的预约提箱操作在集装箱已经从货运船卸入堆场之后,因此无法在卸船时间点依据预测的提箱顺序确定集装箱堆存计划;(2)预约提箱一般以时间段为单位进行预约,加之如道路拥堵、天气等不可控因素,预约时间是否具备参考意义有待考证。
技术实现要素:
4.为此,需要提供一种集装箱提箱序列的预测的解决方案,用以解决现有的集装箱预约机制停留在货运船卸入堆场之后,导致集装箱提取流程滞后,影响货物提取效率的问题。
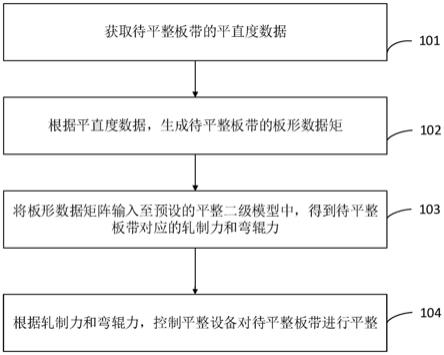
5.为实现上述目的,在第一方面,本发明提供了一种集装箱提箱序列预测方法,包括以下步骤:
6.s1:采集集装箱历史数据;所述历史数据包括集装箱的历史堆存天数和集装箱对应的属性参数信息;
7.s2:对所述集装箱历史数据进行数据清洗,获得模型输入数据;
8.s3:将所述模型输入数据输入到训练模型进行训练,得到训练完成的模型;
9.s4:获取待预测的集装箱的属性参数信息并将其输入到训练完成的模型中,以输出该待预测的集装箱对应的预测堆存天数。
10.作为一种可选的实施例,所述属性参数信息包括集装箱标识信息、集装箱货物信息、集装箱作业单信息、监管部门的监管信息中的任一项或多项。
11.作为一种可选的实施例,所述模型输入数据包括训练集和验证集,所述训练集用于对所述训练模型进行训练,所述验证集用于对所述训练完成的模型的训练结果进行验证。
12.作为一种可选的实施例,所述属性参数信息包括非数值型数据或缺失值,所述对所述集装箱历史数据进行数据清洗包括:
13.对所述属性参数信息中的非数值型数据或缺失值进行处理,以使其满足所述训练模型的输入要求。
14.作为一种可选的实施例,所述属性参数信息包括集装箱标识信息或集装箱货物信息;
15.对所述属性参数信息中的非数值型数据或缺失值进行处理包括:
16.对所述集装箱标识信息中的非数值型数据采用数值型数据进行替代,或者对所述集装箱货物信息中的缺失值采用其他历史数据中与该集装箱装有相同货物和相同集装箱中的数据的均值进行替代。
17.作为一种可选的实施例,将所述模型输入数据输入到训练模型进行训练包括:
18.将所述模型输入数据按照以下格式进行编辑后输入到所述训练模型进行训练:
19.x
″
(i)=[x
′
(i),a
′
(i),o
′
(i),s
′
(i),c
′
(i),g
′
(i),p
′
(i),w
′
(i),d
′
(i),u
′
(i)]
[0020]
其中,a’为控箱公司名称,o'为集装箱的箱型,c’为货主名、g’为货物名、t’表征贸易类型、p’为付款人名称、w’为作业类型、d’为运输方式、u’为包装。
[0021]
作为一种可选的实施例,所述方法包括:
[0022]
获取所述验证集中所有集装箱的实际堆存天数,并将所述验证集中的数据按照集装箱实际堆存天数的大小进行排序,绘制实际堆存天数曲线并对排序编号进行记录;
[0023]
按照所述排序编号依次将验证集中的各个数据输入到训练完成的模型中,得到验证集中所有数据的预测堆存天数,按照与所述实际堆存天数排序相适配的顺序对所述预测堆存天数进行排序,得到预测堆存天数曲线;
[0024]
判断所述实际堆存天数曲线与所述预测堆存天数曲线的拟合性以对所述训练完成的模型的预测效果进行评估。
[0025]
作为一种可选的实施例,步骤s4后还包括步骤s5:基于所述预测堆存天数生成集装箱提箱序列。
[0026]
在第二方面,本发明提供了一种存储介质,所述存储介质中存储有计算机程序,所述计算机程序被处理器执行时实现如本发明第一方面任一项所述的方法步骤。
[0027]
在第三方面,本发明提供了一种集装箱提箱序列预测系统,所述系统包括处理器和存储介质,所述存储介质为如本发明第二方面所述的存储介质,所述处理器用于执行所述存储介质中存储的计算机程序。
[0028]
区别于现有技术,上述技术方案提供的一种集装箱提箱序列的预测方法、系统和存储介质,所述方法包括以下步骤:s1:采集集装箱历史数据;所述历史数据包括集装箱的历史堆存天数和集装箱对应的属性参数信息;s2:对所述集装箱历史数据进行数据清洗,获得模型输入数据;s3:将所述模型输入数据输入到训练模型进行训练,得到训练完成的模型;s4:获取待预测的集装箱的属性参数信息并将其输入到训练完成的模型中,以输出该待预测的集装箱对应的预测堆存天数。上述方案通过采集集装箱作业的历史数据,基于机器学习的回归预测算法实现堆存天数的预测,进而确定集装箱的提箱序列,有效提升了集装箱的预约提取效率。
附图说明
[0029]
图1为本发明一实施例涉及的集装箱提箱序列的预测方法的流程图;
[0030]
图2为本发明另一实施例涉及的集装箱提箱序列的预测方法的流程图;
[0031]
图3为本发明一实施例涉及的基于第一输入特征统计堆存天数的直方图;
[0032]
图4为本发明一实施例涉及的基于第二输入特征统计堆存天数的直方图;
[0033]
图5为本发明一实施例涉及的不同船名航次分组的集装箱实际堆存天数曲线与预测堆存天数曲线的示意图;
[0034]
图6为本发明一实施例涉及的实际堆存天数曲线与预测堆存天数曲线拟合的示意图;
[0035]
图7为本发明一实施例涉及的集装箱提箱序列的预测系统的模块示意图。
[0036]
附图标记说明:
[0037]
101、存储介质;
[0038]
102、处理器。
具体实施方式
[0039]
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
[0040]
如图1所示,为本发明一实施例涉及的集装箱提箱序列的预测方法的流程图。所述方法包括以下步骤:
[0041]
s1:采集集装箱历史数据;所述历史数据包括集装箱的历史堆存天数和集装箱对应的属性参数信息;
[0042]
s2:对所述集装箱历史数据进行数据清洗,获得模型输入数据;
[0043]
s3:将所述模型输入数据输入到训练模型进行训练,得到训练完成的模型;
[0044]
s4:获取待预测的集装箱的属性参数信息并将其输入到训练完成的模型中,以输出该待预测的集装箱对应的预测堆存天数。
[0045]
上述方案通过采集集装箱作业的历史数据,基于机器学习的回归预测算法实现堆存天数的预测,进而确定集装箱的提箱序列,有效提升了集装箱的预约提取效率。
[0046]
优选的,步骤s4后还包括步骤s5:基于所述预测堆存天数生成集装箱提箱序列。通常,集装箱提箱序列是包含有提箱的时间日期,预测堆存天数越多,提箱序列中包含的提箱时间日期就距离现在的时间点越远。本技术通过事先基于集装箱的属性参数信息来预测集装箱的堆存天数,并基于堆存天数来生成集装箱提箱序列,可以将预测序列生成的时间节点提前到卸船、卸车前,帮助计划调度人员更为合理的制定堆场堆存计划,极大地减少堆场机械的无功作业量,缩短作业等待时间,大幅提升作业效率,实现降本增效。
[0047]
作为一种可选的实施例,所述属性参数信息包括集装箱标识信息、集装箱货物信息、集装箱作业单信息、监管部门的监管信息中的任一项或多项。集装箱标识信息包括集装箱的唯一标识ci、箱型cs、箱状态cw(重或吉)、内外贸c
t
、进出口ce、控箱公司ca、箱属公司go等。集装箱货物信息包括货名gn、货主go、包装g
p
、重量gw、件数gc、体积gv等。集装箱作业单信息包括当前集装箱属于哪个船名航次mn,何时办单w
t
,何种作业单wk,何时提柜p
t
等。监管部门的监管信息包括放行时间r
t
等。通过输入集装箱标识信息、集装箱货物信息、集装箱作业
单信息、监管部门的监管信息,可以充分考虑到各种属性信息不同的集装箱堆存天数,提升模型训练的样本量和识别精准度。
[0048]
当然,在另一些实施例中,集装箱的属性参数信息还包括基于专家经验或者统计判断后与集装箱在港堆存天数可能有关的字段特征。假设源数据集为x
′
,单行记录为x
′
(i),则其表达式为:
[0049]
x
′
(i)=[ci,cs,cw,c
t
,ce,ca,gn,gc,g
p
,gw,gc,gv,mn,w
t
,wk,p
t
,r
t
,
…
]
[0050]
在某些实施例中,所述属性参数信息包括非数值型数据或缺失值,所述对所述集装箱历史数据进行数据清洗包括:对所述属性参数信息中的非数值型数据或缺失值进行处理,以使其满足所述训练模型的输入要求。
[0051]
优选的,所述属性参数信息包括集装箱标识信息或集装箱货物信息;对所述属性参数信息中的非数值型数据或缺失值进行处理包括:对所述集装箱标识信息中的非数值型数据采用数值型数据进行替代,或者对所述集装箱货物信息中的缺失值采用其他历史数据中与该集装箱装有相同货物和相同集装箱中的数据的均值进行替代。
[0052]
在某些实施例中,所述模型输入数据包括训练集和验证集,所述训练集用于对所述训练模型进行训练,所述验证集用于对所述训练完成的模型的训练结果进行验证。训练集是指包含大量训练数据的集合,验证集是指包含大量验证数据的集合。优选的,验证集可以是在训练集的基础上通过修改调整部分或全部的属性参数信息得到。通过设置验证集对于训练好的模型进行验证,可以有效获知当前模型训练的准确性进行校验。
[0053]
以训练模型为svr模型为例,步骤s2中对所述集装箱历史数据进行数据清洗包括:
[0054]
步骤s21:根据集装箱的唯一id对数据进行去重处理;
[0055]
步骤s22:对集装箱的货物明细信息中的如控箱公司、箱属公司、货主、包装、货名等中文特征(即前文提及的非数值型数据)进行归纳分类,并用数值进行替换;
[0056]
步骤s23,对如包装、重量、体积等货物明细的缺失值,使用相同货物和相同箱型的均值进行填充;
[0057]
步骤s24,按照控箱公司(a)、箱属公司(o)、箱型(s)、货主(c)、货名(g)、内外贸(t)、付款人(p)、作业类型(w)、运输方式(d)、包装(u)对记录数、堆存天数、放行天数、办单天数、绑定天数、预约天数进行统计,取其平均值,并作为补充特征完善预测集,如控箱公司,其补充特征定义如表1所示,表达式为:
[0058][0059]
补充特征如下方表1所示:
[0060][0061]
表1补充特征(控箱公司为例)
[0062]
在本实施方式中,将所述模型输入数据输入到训练模型进行训练包括:将所述模型输入数据按照以下格式进行编辑后输入到所述训练模型进行训练:
[0063]
x
″
(i)=[x
′
(i),a
′
(i),o
′
(i),s
′
(i),c
′
(i),g
′
(i),t
′
(i),p
′
(i),w
′
(i),d
′
(i),u
′
(i)]
[0064]
其中,a’为控箱公司名称,o'为集装箱的箱型,c’为货主名、g’为货物名、t’表征贸易类型、p’为付款人名称、w’为作业类型、d’为运输方式、u’为包装。
[0065]
在某些实施例中,所述方法包括:获取所述验证集中所有集装箱的实际堆存天数,并将所述验证集中的数据按照集装箱实际堆存天数的大小进行排序,绘制实际堆存天数曲线并对排序编号进行记录;按照所述排序编号依次将验证集中的各个数据输入到训练完成的模型中,得到验证集中所有数据的预测堆存天数,按照与所述实际堆存天数排序相适配的顺序对所述预测堆存天数进行排序,得到预测堆存天数曲线;判断所述实际堆存天数曲线与所述预测堆存天数曲线的拟合性以对所述训练完成的模型的预测效果进行评估。
[0066]
在本实施方式中,经过步骤s2处理完的数据集进行划分,分为训练集和测试集。但对于提箱序列的预测,仅依靠预测堆存天数是不足够的,因此,本发明在结合均方误差mse评估预测结果的同时,引入了曲线单调性对模型预测效果进行评估,其步骤如下:
[0067]
步骤61,将验证集所有集装箱按照船名加航次进行分组,分组内按照集装箱的实际堆存天数从小到大进行排序,并以x轴为集装箱索引,y轴为堆存天数绘制曲线,该曲线图像是一个单调递增的曲线;
[0068]
步骤62,根据步骤61中集装箱的顺序将预测堆存天数同样绘制曲线,如果预测堆存天数的曲线是单调递增,证明预测提箱序列与实际相符;
[0069]
步骤63,对于非单调递增的曲线,通过判断曲线中出现斜率为负数的次数ec,即原本较晚提的集装箱被预测为较早提,求解其占对应船名航次全部集装箱ea的占比,即为错误率,错误率越低,证明预测效果越好,均方误差mse和单调性错误率er表达式如下:
[0070][0071]
单调性错误率表达式如下:er[0072][0073]
本发明提供了一种集装箱提箱序列的预测方法以及针对预测结果的评估方式,与现有发明相比,本发明的有益效果:
[0074]
(1)充分利用了集装箱历史数据,通过统计学方式从数据中挖掘与堆存天数相关的特征,无需提箱序列预测的先验知识。
[0075]
(2)基于svr回归预测模型建立特征与堆存天数的非线性关系,利用本发明可以通过预测集装箱堆存天数来确定提箱序列,且相比于现有确定提箱序列的方法,本发明可以将预测的时间节点提前到卸船、卸车前,帮助计划调度人员更为合理的制定堆场堆存计划,极大地减少堆场机械的无功作业量,缩短作业等待时间,大幅提升作业效率,实现“降本增效”。
[0076]
(3)本发明算法为解决翻箱落位优选、集装箱堆场不完全信息决策等问题提供了预测提箱序列的基础,有利于推进关联问题的进一步研究。
[0077]
如图2所示,为本发明另一实施例涉及的集装箱提箱序列的预测方法的流程图。具体包括以下步骤:
[0078]
s201:获取集装箱历史数据;
[0079]
s202:统计分析提取特征;
[0080]
s203:数据清洗特征工程;
[0081]
s204:svr模型;
[0082]
s205:堆存天数预测;
[0083]
s206:mse曲线单调性判断;
[0084]
s207:提箱序列确定。
[0085]
下面结合具体的实施例及附图3-6对本发明的方法作进一步详细的描述,但本发明的实施方式不限于此。以珠三角某二类码头长期以来堆场进口箱翻箱率维持在较高的水平(80%以上),翻箱率计算公式如下:
[0086][0087]
其中rr代表翻箱率,pn提箱数,pr代表提箱产生的翻箱次数。
[0088]
装卸船计划仅能依据经验规则进行制定,经常出现“计划赶不上变化”的情况,因此,基于历史箱数据和svr进行堆存天数预测模型的设计,求解提箱序列,该方法的步骤如下:
[0089]
步骤1,选取该码头2021-01-08到2021-08-16共计72387条历史箱原始数据,特征选择方面通过统计方法,对可能与堆存天数存在相关关系的特征进行筛选,该实施例通过观察筛选,选择了箱型、箱状态、控箱公司、货主等特征;
[0090]
步骤2-1,根据集装箱唯一id对数据进行去重处理,去重后原始数据集压缩至
10789条;
[0091]
步骤2-2,对中文类型的特征进行归纳分类,并使用数值进行替换,如货名特征,“葡萄酒”、“胶粒”、“木方”等使用0,1,2,
……
进行替换。
[0092]
步骤2-3,对于货物体积、重量缺失的数据,使用货物 箱型的统计均值进行替换。
[0093]
步骤2-4,按照控箱公司、箱属公司、箱型等统计纬度对堆存天数、办单天数等进行统计,如附图2和图3所示,求解其均值作为补充特征合并到原始数据集中,如“箱型20gp”的集装箱的补充特征如下表2所示:
[0094][0095][0096]
表2箱型补充特征
[0097]
进行特征工程后,单个历史箱记录特征拓展到85个;
[0098]
步骤2-5,按照约6:4的比例对数据处理和特征工程后的原始数据集进行切分,训练集为一个5953
×
86的矩阵,预测集是一个4836
×
86的矩阵;
[0099]
步骤3,针对当前选取特征和目标输出变量,使用训练集数据对支持向量回归模型进行训练,最终的模型参数采用网络搜索的策略得到。其中,svr模型通过求解式(1)得到最终表达式(2):
[0100][0101][0102][0103]
其中,参数ε为间隔带宽度,c为惩罚系数,m为训练样本个数,x是输入数据,y是输出数据,ai和b是模型待求参数。k(x,xi)是核函数,本发明选用如式(3)所示的高斯核函数,σ是核函数的带宽;
[0104][0105]
将堆存天数作为输出变量,使用网格搜索对模型超参ε、c、σ进行确定,确定ε、c、σ分别为0.1、6、9.09时,配合步骤4的评估方法可以确定一个预测效果比较好的提箱序列预测svr模型;
[0106]
步骤4-1,输入验证集数据,得到模型预测的集装箱堆存天数,并将集装箱记录按照船名航次(即同一艘船到达港口码头)进行分组(共156组,即156艘船),并将分组内的集装箱实际堆存天数按照从小到大进行排序,按照x轴为集装箱索引,y轴为堆存天数进行绘制;
[0107]
步骤4-2,根据步骤4-1中集装箱的索引顺序将模型预测的堆存天数同样绘制曲线,如果预测堆存天数的曲线是单调递增,可以初步证明预测的提箱序列与实际较为相符,绘制后图像整体如附图5所示;
[0108]
步骤4-3,模型预测效果的评估采用两种方式进行评估,首先是常用的均方误差评估,统计所有船舶分组实际堆存天数与预测堆存天数的平均均方误差为1.24天,单纯通过均方误差无法满足提箱序列预测的场景,因此,本发明引入通过判断曲线的单调性来确定预测与实际的相对序列是否匹配,即在步骤4-1、4-2的基础上,判断预测堆存天数曲线的单调性,即判断是否存在本来堆存天数大的被预测为堆存天数小的,如附图6所示,当前船名航次共35个集装箱,出现斜率为负数的次数为红圈标识的3次,故当前船名航次的错误率为:
[0109][0110]
经过统计所有分组,平均错误率为9.23%,进一步的,提箱序列预测错误并不意味着一定会造成无功作业,且与其他类型的回归预测算法进行对比,svr有更为优秀的表现
(决策树类错误率32.34%),该错误率已经能满足计划调度人员更科学、更有效的制定装卸计划,验证了本发明对提箱序列预测的有效性及结果的合理性。
[0111]
在第二方面,本技术提供了一种存储介质101,存储介质101存储有计算机程序,计算机程序被处理器执行时实现如本技术第一方面的方法步骤。
[0112]
如图7所示,在第三方面,本技术提供了一种集装箱提箱序列的预测系统,包括处理器102和存储介质101,存储介质101为前文第二方面的存储介质,处理器102用于执行存储介质中存储的计算机程序。优选的,该系统为计算机设备。
[0113]
存储介质包含计算机存储媒体及通信媒体两者,通信媒体包含可经启用以将计算机程序从一处传送到另一处的任何媒体。存储媒体可以是可通过计算机访问的任何可供使用的媒体。以实例说明而非限制,非暂时性媒体可包含ram、rom、eeprom、cd-rom或其它光盘存储装置、磁盘存储装置或其它磁性存储装置,或可用于以指令或数据结构形式存储所要程序代码且可由计算机存取的任何其它媒体。而且,可将任何连接恰当地称为计算机可读媒体。如本文所使用的磁盘和光盘包含压缩光盘(cd)、激光光盘、光学光盘、数字多功能光盘(dvd)、软盘和蓝光光盘,其中磁盘通常是以磁性方式再现数据,而光盘是用激光以光学方式再现数据。以上的组合也应包含在计算机可读媒体的范围内。另外,方法或算法的操作可作为代码和指令中的任一者或任何组合或集合驻留于可并入到计算机程序产品中的机器可读媒体或计算机可读媒体上。
[0114]
处理器包括通用单芯片或多芯片处理器、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或其它可编程逻辑装置、离散门或晶体管逻辑、离散硬件组件或其经设计以执行本文所描述的功能的任何组合。通用处理器可为微处理器或任何常规处理器、控制器、微控制器或状态机。处理器也可实施为计算装置的组合,例如dsp和微处理器的组合、多个微处理器、与dsp核心结合的一或多个微处理器,或任何其它此类配置。在一些实施方案中,特定过程及方法可由特定针对给定功能的电路执行。
[0115]
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括
……”
或“包含
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的要素。此外,在本文中,“大于”、“小于”、“超过”等理解为不包括本数;“以上”、“以下”、“以内”等理解为包括本数。
[0116]
尽管已经对上述各实施例进行了描述,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改,所以以上所述仅为本发明的实施例,并非因此限制本发明的专利保护范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。