1.本发明属于软件调试领域,具体涉及一种基于树的漏洞修复系统及修复方法。
背景技术:
2.随着软件的演化,漏洞的引入与产生难以避免,且随着软件规模的增加,软件漏洞的修复难度也随之增加。漏洞的产生对软件安全产生了威胁,它们的到来可能会给企业或者个人带来一些数据泄漏或者经济损失等问题。因此,为了更好的提高软件可靠性并且降低开发成本,研究人员提出了关于自动化的漏洞修复技术来自动修复具有漏洞的软件程序。
3.传统的漏洞修复方法大多依靠于bug修复方法,但近年来随着对漏洞的研究的增多,越来越多的研究人员发现漏洞与bug在代码数据以及报告上的区别,因此从漏洞的数据进行出发,才能更好的研究出适用于漏洞的自动修复方法。
技术实现要素:
4.发明目的:本发明的目的是提供一种修复正确率高、漏洞特征提取能力优异、泛化能力强的漏洞修复系统;本发明的另一目的是提供一种漏洞修复方法。
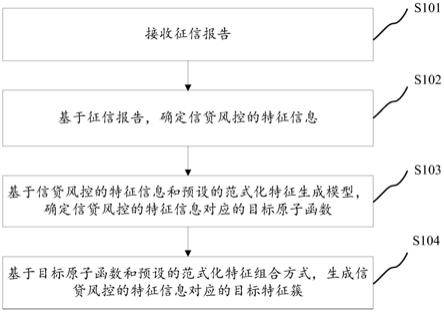
5.技术方案:本发明所述的漏洞修复系统,包括:漏洞数据集构建模块,用以从漏洞数据库cve中以特定的关键词来爬取漏洞数据,对该漏洞数据进行筛选并形成初步数据集;在开源代码库github中收集初步数据集中的漏洞的引入提交与修复提交并构建为引入-修复对,将引入-修复对中的代码注释进行删除并形成漏洞数据集;语法树生成模块,用以将漏洞数据集中的代码生成语法树ast,对语法树ast进行差异操作,在进行差异操作后的语法树ast上添加数据流依赖和控制流依赖并形成新的语法树ast;数据抽象化规范化处理模块,用以对新的语法树ast进行抽象化和规范化处理得到token序列;模型训练模块,用以将漏洞数据集分为训练集与测试集,将token序列以及训练集输入至seq2seq模型中进行训练得到训练好的seq2seq模型;其中,seq2seq模型中采取带有自注意力机制的transformer模型;漏洞修复模块,用以将测试集转换为输入序列并输入至训练好的seq2seq模型中,得到修复的测试集的代码。
6.进一步的,在漏洞数据集构建模块中,
7.在漏洞数据库cve中对包含漏洞引入特征的特定的关键字,使用python爬虫进行漏洞数据的爬取,对漏洞数据进行筛选并形成初步数据集;在初步数据集中寻找漏洞的引入提交与修复提交并构建为引入-修复对;寻找的方法为:在开源代码库github中的漏洞报告中查看参考链接,寻找相关评论中的漏洞的引入提交与修复提交;或者在开源代码库github中直接搜索漏洞cve-id,找到漏洞的引入提交与修复提交;将引入-修复对中的代码注释进行删除,将删除代码注释后的引入-修复对构建为漏洞数据集。
8.进一步的,在语法树生成模块中,
9.数据流依赖和控制流依赖是利用上下文流图中的概念添加到进行差异操作后的
语法树ast上并形成新的语法树ast;其中,上下文流图中的概念的具体规则如下:
10.第一次遍历语句,寻找漏洞读取llvm ir语句一次,存储函数名和返回语句;
11.第二次遍历语句,根据以下规则集添加节点和边:
12.一个基本块内的数据依赖是连接的;块间依赖关系既可以直接连接,也可以通过标签标识符连接;没有数据流父节点的标识符连接到它们的根。
13.进一步的,在数据抽象化规范化处理模块中,
14.对新的语法树ast进行抽象化和规范化处理的过程为:将新的语法树ast中代码的变量名、方法名、数值分别表示为var、fun、num,得到表示后的代码;将表示后的代码拆分为token序列。
15.进一步的,在模型训练模块中,
16.在transformer模型中,编码器用于映射一个符号表示的输入序列(x1,
…
,xn)到嵌入表示z=(z1,
…
),映射信息包含了输入的各个部分信息,且各个部分是相互关联的;解码器利用嵌入表示z来合并上下文信息并生成一个输出序列符号(y1,
…
,ym);在每一步中,当生成下一个输出序列符号时,transformer模型将先前生成的所有输出序列符号作为额外的输入使用;在生成的输出序列符号中使用beam search算法选择最优的输出序列符号并作为最终的输出结果。
17.本发明所述的漏洞修复方法,包括:
18.(1)从漏洞数据库cve中以特定的关键词来爬取漏洞数据,对该漏洞数据进行筛选并形成初步数据集;在开源代码库github中收集初步数据集中的漏洞的引入提交与修复提交并构建为引入-修复对,将引入-修复对中的代码注释进行删除并形成漏洞数据集;
19.(2)将漏洞数据集中的代码生成语法树ast,对语法树ast进行差异操作,在进行差异操作后的语法树ast上添加数据流依赖和控制流依赖并形成新的语法树ast;
20.(3)对新的语法树ast进行抽象化和规范化处理得到token序列;
21.(4)将漏洞数据集分为训练集与测试集,将token序列以及训练集输入至seq2seq模型中进行训练得到训练好的seq2seq模型;其中,seq2seq模型中采取带有自注意力机制的transformer模型;
22.(5)将测试集转换为输入序列并输入至训练好的seq2seq模型中,得到修复的测试集的代码。
23.进一步的,在步骤(1)中,
24.在漏洞数据库cve中对包含漏洞引入特征的特定的关键字,使用python爬虫进行漏洞数据的爬取,对漏洞数据进行筛选并形成初步数据集;在初步数据集中寻找漏洞的引入提交与修复提交并构建为引入-修复对;寻找的方法为:在开源代码库github中的漏洞报告中查看参考链接,寻找相关评论中的漏洞的引入提交与修复提交;或者在开源代码库github中直接搜索漏洞cve-id,找到漏洞的引入提交与修复提交;将引入-修复对中的代码注释进行删除,将删除代码注释后的引入-修复对构建为漏洞数据集。
25.进一步的,在步骤(2)中,
26.数据流依赖和控制流依赖是利用上下文流图中的概念添加到进行差异操作后的语法树ast上并形成新的语法树ast;其中,上下文流图中的概念的具体规则如下:
27.第一次遍历语句,寻找漏洞读取llvm ir语句一次,存储函数名和返回语句;
28.第二次遍历语句,根据以下规则集添加节点和边:
29.一个基本块内的数据依赖是连接的;块间依赖关系既可以直接连接,也可以通过标签标识符连接;没有数据流父节点的标识符连接到它们的根。
30.进一步的,在步骤(3)中,
31.对新的语法树ast进行抽象化和规范化处理的过程为:将新的语法树ast中代码的变量名、方法名、数值分别表示为var、fun、num,得到表示后的代码;将表示后的代码拆分为token序列。
32.进一步的,在步骤(4)中,
33.在transformer模型中,编码器用于映射一个符号表示的输入序列(x1,
…
,xn)到嵌入表示z=(z1,
…
),映射信息包含了输入的各个部分信息,且各个部分是相互关联的;解码器利用嵌入表示z来合并上下文信息并生成一个输出序列符号(y1,
…
,ym);在每一步中,当生成下一个输出序列符号时,transformer模型将先前生成的所有输出序列符号作为额外的输入使用;在生成的输出序列符号中使用beam search算法选择最优的输出序列符号并作为最终的输出结果。
34.有益效果:本发明与现有技术相比,其显著优点是:1、修复正确率高:使用带有自注意力机制的transformer模型,从而提升修复的正确率;2、漏洞特征提取能力优异:基于漏洞引入的启发式规则,对漏洞的引入提交与修复提交进行相关语义的表示,更好的提取漏洞特征;3、泛化能力强:基于树的语义表征在转换为序列时,相对序列较小,更好的让seq2seq模型学习特征,从而生成修复模版,提升了seq2seq模型的泛化能力。
附图说明
35.图1是本发明的流程图;
36.图2是seq2seq模型内部的处理流程图。
具体实施方式
37.以下结合附图对本发明的具体实施方式进行说明。
38.实施例1
39.如图1所示,所述的漏洞修复系统,包括:
40.漏洞数据集构建模块,用以从漏洞数据库cve中以特定的关键词来爬取漏洞数据,对该漏洞数据进行筛选并形成初步数据集;在开源代码库github中收集初步数据集中的漏洞的引入提交与修复提交并构建为引入-修复对,将引入-修复对中的代码注释进行删除并形成漏洞数据集。
41.在漏洞数据库cve中对包含漏洞引入特征的特定的关键字(如“introduced”,“caused by”,“because of”等),使用python爬虫进行漏洞数据的爬取,对漏洞数据进行筛选并形成初步数据集;在初步数据集中寻找漏洞的引入提交与修复提交并构建为引入-修复对;寻找的方法为:在开源代码库github中的漏洞报告中查看参考链接,寻找相关评论中的漏洞的引入提交与修复提交;或者在开源代码库github中直接搜索漏洞cve-id,找到漏洞的引入提交与修复提交;将引入-修复对中的代码注释进行删除,将删除代码注释后的引入-修复对构建为漏洞数据集。
42.表1展示了漏洞数据集中的某一样本;其中,代码语言为c语言。
43.表1漏洞数据集中某一样本
[0044][0045][0046]
语法树生成模块,用以将漏洞数据集中的代码生成语法树ast,对语法树ast进行差异操作,在进行差异操作后的语法树ast上添加数据流依赖和控制流依赖并形成新的语法树ast。其中java语言选用gumtree工具,c语言选用clang工具进行差异(diff)操作。
[0047]
数据流依赖和控制流依赖是利用上下文流图中的概念添加到进行差异操作后的语法树ast上并形成新的语法树ast;其中,上下文流图中的概念的具体规则如下:
[0048]
第一次遍历语句,寻找漏洞读取llvm ir语句一次,存储函数名和返回语句。
[0049]
第二次遍历语句,根据以下规则集添加节点和边:
[0050]
一个基本块内的数据依赖是连接的;块间依赖关系既可以直接连接,也可以通过标签标识符连接;没有数据流父节点的标识符连接到它们的根。
[0051]
数据抽象化规范化处理模块,用以对新的语法树ast进行抽象化和规范化处理得到token序列。
[0052]
对新的语法树ast进行抽象化和规范化处理的过程为:将新的语法树ast中代码的变量名、方法名、数值分别表示为var、fun、num,得到表示后的代码;将表示后的代码拆分为token序列。
[0053]
模型训练模块,用以将漏洞数据集分为训练集与测试集(漏洞数据集的80%作为训练集,剩下的20%作为测试集),将token序列以及训练集输入至seq2seq模型中进行训练得到训练好的seq2seq模型;其中,seq2seq模型中采取带有自注意力机制的transformer模型。其中,seq2seq模型内部的处理流程如图2所示。
[0054]
在transformer模型中,编码器(encoder)包括六个相同的层,将需要输入的序列输入到编码器中,每一层由两个子层组成:自注意力机制和前馈神经网络;自注意机制从编码器中获取一组输入编码,权衡输入编码之间的相关性并生成一组输出编码;然后前馈神经网络单独处理每个输出编码,这些输出编码最后作为输入传递给下一个编码器,最终生
成编码。解码器(decoder)包括六层,且每一层包括三个子层;解码器从编码器生成的编码中提取相关信息。
[0055]
编码器用于映射一个符号表示的输入序列(x1,
…
,xn)到嵌入表示z=(z1,
…
),映射信息包含了输入的各个部分信息,且各个部分是相互关联的;解码器利用嵌入表示z来合并上下文信息并生成一个输出序列符号(y1,
…
,ym);在每一步中,当生成下一个输出序列符号时,transformer模型将先前生成的所有输出序列符号作为额外的输入使用;在生成的输出序列符号中使用beam search算法选择最优的输出序列符号并作为最终的输出结果;其中,beam search算法在使用的时候,设置超参数b(束宽)为3,用来每一次挑选top b的结果。
[0056]
漏洞修复模块,用以将测试集转换为输入序列并输入至训练好的seq2seq模型中,得到修复的测试集的代码。
[0057]
实施例2
[0058]
如图1所示,所述的漏洞修复方法,包括:
[0059]
(1)从漏洞数据库cve中以特定的关键词来爬取漏洞数据,对该漏洞数据进行筛选并形成初步数据集;在开源代码库github中收集初步数据集中的漏洞的引入提交与修复提交并构建为引入-修复对,将引入-修复对中的代码注释进行删除并形成漏洞数据集。
[0060]
在漏洞数据库cve中对包含漏洞引入特征的特定的关键字(如“introduced”,“caused by”,“because of”等),使用python爬虫进行漏洞数据的爬取,对漏洞数据进行筛选并形成初步数据集;在初步数据集中寻找漏洞的引入提交与修复提交并构建为引入-修复对;寻找的方法为:在开源代码库github中的漏洞报告中查看参考链接,寻找相关评论中的漏洞的引入提交与修复提交;或者在开源代码库github中直接搜索漏洞cve-id,找到漏洞的引入提交与修复提交;将引入-修复对中的代码注释进行删除,将删除代码注释后的引入-修复对构建为漏洞数据集。
[0061]
表1展示了漏洞数据集中的某一样本;其中,代码语言为c语言。
[0062]
表1漏洞数据集中某一样本
[0063]
[0064][0065]
(2)将漏洞数据集中的代码生成语法树ast,对语法树ast进行差异操作,在进行差异操作后的语法树ast上添加数据流依赖和控制流依赖并形成新的语法树ast。其中java语言选用gumtree工具,c语言选用clang工具进行差异(diff)操作。
[0066]
数据流依赖和控制流依赖是利用上下文流图中的概念添加到进行差异操作后的语法树ast上并形成新的语法树ast;其中,上下文流图中的概念的具体规则如下:
[0067]
第一次遍历语句,寻找漏洞读取llvm ir语句一次,存储函数名和返回语句。
[0068]
第二次遍历语句,根据以下规则集添加节点和边:
[0069]
一个基本块内的数据依赖是连接的;块间依赖关系既可以直接连接,也可以通过标签标识符连接;没有数据流父节点的标识符连接到它们的根。
[0070]
(3)对新的语法树ast进行抽象化和规范化处理得到token序列。
[0071]
对新的语法树ast进行抽象化和规范化处理的过程为:将新的语法树ast中代码的变量名、方法名、数值分别表示为var、fun、num,得到表示后的代码;将表示后的代码拆分为token序列。
[0072]
(4)将漏洞数据集分为训练集与测试集(漏洞数据集的80%作为训练集,剩下的20%作为测试集),将token序列以及训练集输入至seq2seq模型中进行训练得到训练好的seq2seq模型;其中,seq2seq模型中采取带有自注意力机制的transformer模型。其中,seq2seq模型内部的处理流程如图2所示。
[0073]
在transformer模型中,编码器(encoder)包括六个相同的层,将需要输入的序列输入到编码器中,每一层由两个子层组成:自注意力机制和前馈神经网络;自注意机制从编码器中获取一组输入编码,权衡输入编码之间的相关性并生成一组输出编码;然后前馈神经网络单独处理每个输出编码,这些输出编码最后作为输入传递给下一个编码器,最终生成编码。解码器(decoder)包括六层,且每一层包括三个子层;解码器从编码器生成的编码中提取相关信息。
[0074]
编码器用于映射一个符号表示的输入序列(x1,
…
,xn)到嵌入表示z=(z1,
…
),映射信息包含了输入的各个部分信息,且各个部分是相互关联的;解码器利用嵌入表示z来合并上下文信息并生成一个输出序列符号(y1,
…
,ym);在每一步中,当生成下一个输出序列符号时,transformer模型将先前生成的所有输出序列符号作为额外的输入使用;在生成的输出序列符号中使用beam search算法选择最优的输出序列符号并作为最终的输出结果;其中,beam search算法在使用的时候,设置超参数b(束宽)为3,用来每一次挑选top b的结果。
[0075]
(5)将测试集转换为输入序列并输入至训练好的seq2seq模型中,得到修复的测试集的代码。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。