1.本发明涉及文字短信有害信息监测领域,特别是涉及一种基于大数据识别短信内容中有害信息的方法。
背景技术:
2.近年来,在移动终端、新媒体技术、互联网等诸多方面日新月异的发展过程中,移动终端已成为了信息传播的主流渠道之一,移动终端带来的经济效益、便利性是有目共睹的。但由于移动终端的大众化与缺乏网络监管手段,导致网络信息安全问题越来越严重,特别是不法分子通过网络平台发布各种有害信息,严重影响了国家安全和社会的稳定。
3.现有技术通过ai智能有害信息识别系统针对违法违规的词、句、拼音、拼音缩写、语义等进行监测、筛选、拦截等动作,不仅有效净化了网络平台保障国家安全和社会稳定也为企业节约了大量的人力成本。
技术实现要素:
4.本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种基于大数据识别短信内容中有害信息的方法。
5.为了实现本发明的上述目的,本发明提供了一种基于大数据识别短信内容中有害信息的方法,包括以下步骤:
6.s1,通过包含黑名单和白名单的数据集对ai智能识别系统进行训练;以及采用分词技术提取数据集中的关键信息,对ai智能识别系统训练;
7.s2,通过正则表达式对短信做初步筛查,判断短信内容中是否包含手机号码、链接、ip地址、验证码之一或者任意组合,若存在,则拦截率增加o,执行步骤s5;若不存在,o为0,执行下一步骤;其中o表示基于初步筛查的短信有害概率值;
8.s3,将短信输入训练好的ai智能识别系统,对短信采用分词技术,计算最大信息冗余mir,然后进行第一次通过判断,若通过所述第一次通过判断且o为0,则短信通过;若不通过所述第一次通过判断则计算出基于短信冗余度的短信有害概率值q1;
9.s4,将分词插入到分词词库中,计算基于分词属性的短信有害概率值q2,然后进行第二次通过判断,若通过所述第二次通过判断且o为0,则短信通过;若不通过所述第二次通过判断则计算出拦截率q;
10.s5,将拦截率q与最小阈值、最大阈值进行比较:若小于最小阈值则短信通过,若大于最大阈值则短信拦截;若处于最小阈值~最大阈值之间则将该条短信将转至人工审核库,待人工审核进行通过;其中最小阈值小于最大阈值。
11.进一步地,所述ai智能识别系统包括cnn卷积网络。
12.进一步地,所述s3包括:
13.s3-1,运用word分词技术将短信的文本内容拆分成若干个词;
14.s3-2,删除停用词;
15.s3-3,将各个分词进行排列得到特征向量,作为ai智能识别系统卷积层的输入;
16.s3-4,计算最大信息冗余mir,并进行第一次通过判断,若不通过则执行下一步骤;
17.s3-5,计算出基于短信冗余度的短信有害概率值q1。
18.进一步地,所述s3-3中的卷积层采用多个不同尺寸的卷积核,有助于捕捉不同维度的信息。
19.所述每个卷积核提取出不同的类型特征,得到不同的特征维度信息:
[0020][0021]
其中jk表示第k个卷积核对应的特征维度信息;
[0022]
θ(
·
)表示激活函数;
[0023]
k表示卷积核的个数;
[0024]dk
表示第k个卷积核的特征值;
[0025]
为卷积运算;
[0026]fik
表示第k个卷积核时第i层的特征;
[0027]fik-1
表示第k-1个卷积核时第i层的特征;
[0028]
b表示影响因子。
[0029]
进一步地,所述s3-4包括:
[0030]
mir=[y(x)-t]
[0031]
其中x表示短信的字符数;
[0032]
y(x)表示x的冗余值;
[0033]
t表示当前信号通道值;
[0034]
[]表示截断取整;
[0035]
冗余值y(x)的计算公式如下:
[0036][0037]
其中m、n表示偏移调整系数;
[0038]
s表示短信的来源种类数,有网站公司,虚拟平台,以及个人用户端;
[0039]hs
表示来源s的信道频率系数;
[0040]
p(x)表示x需要的网关通信量;
[0041]
然后对冗余值y(x)进行第一次通过判断:
[0042]
(1)当x趋近于0时,趋近于一个常数,
[0043]
(2)mir≤δ,δ为设定的最大冗余值,
[0044]
若通过第一次通过判断且基于初步筛查的短信有害概率值o=0,则拦截率q为0,短信通过;此时短信为无效内容,例如空白短信,单纯无逻辑的符号等。
[0045]
进一步地,所述s3-5包括:
[0046]
[0047]
其中q1表示基于短信冗余度的短信有害概率值;
[0048]
l表示特征向量的行列数,若不足位数,则用0进行补位;
[0049]
y(x)表示x的冗余值;
[0050]
x表示短信的字符数;
[0051]
表示wi的转置;
[0052]
wi表示特征向量第i行的有害概率值;
[0053]
wj表示特征向量第j行的有害概率值。
[0054]
进一步地,所述s4包括:
[0055]
s4-1,根据分词词库中的分词属性,能得到基于分词属性的短信有害概率值q2:
[0056]
q2=max(xwu)
[0057]
其中max(
·
)表示取最大值;
[0058]
xwu表示分词u的拦截率;
[0059]
s4-2,进行第二次通过判断:如果q2<λ且基于初步筛查的短信有害概率值o=0,则拦截率q为0,短信通过,其中λ表示分词筛选阈值;如果q2>λ,则基于分词属性的短信有害概率值变为q3:
[0060][0061]
其中i表示分词集合;
[0062]
xw
uv
表示分词u、v共同出现时的拦截率;
[0063]cuv
表示第u个分词相关联的第v个分词;
[0064]
fw
uv
表示分词u、v共同出现的词频数;
[0065]
s4-3,得到拦截率q:
[0066]
q=αq1 βq3 o
[0067]
其中α为基于短信冗余度的短信有害概率权重系数;
[0068]
β为基于分词属性的短信有害概率权重系数;
[0069]
q1表示基于短信冗余度的短信有害概率值;
[0070]
o为基于初步筛查的短信有害概率值。
[0071]
综上所述,由于采用了上述技术方案,本发明能够:通过ai智能有害信息识别系统针对违法违规的词、句、拼音、拼音缩写、语义等进行监测、筛选、拦截等动作,能快速精准的识别出短信内容中的有害信息。
[0072]
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
[0073]
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
[0074]
图1是本发明的结构示意图。
[0075]
图2是本发明的具体实施流程示意图。
具体实施方式
[0076]
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
[0077]
本发明提供了一种基于大数据识别短信内容中有害信息的方法,包括以下步骤:
[0078]
s001,通过正则表达式对短信做初步筛查,判断短信内容中是否包含手机号码、链接、ip地址、验证码等。若存在,则拦截率增加o。根据需求对此类短信做拦截、通过或人工审核动作。该功能主要是对ai智能识别系统做技术补充。
[0079]
s002,利用大数据分析技术对ai智能识别系统进行算法学习,通过包含黑名单和白名单的数据集训练ai智能识别系统,基于数据集训练的模型,形成初步的审核能力;
[0080]
其中数据集中包含若干条可直接通过的文本内容即白名单和应该被拦截的文本内容即黑名单。
[0081]
s003,提取数据集中的关键信息,运用word分词技术将短信的文本内容拆分成若干个词,然后删除停用词;
[0082]
例如:“欢迎各位游客前来参加本次草原音乐节”这段可直接通过的短信内容,通过word分词技术将会拆分成“欢迎、各位、游客、前来、参加、本次、草原、音乐节”。
[0083]
然后,将各个分词进行排列得到特征向量,作为ai智能识别系统卷积层的输入。所述卷积层采用多个不同尺寸的卷积核,有助于捕捉不同维度的信息。
[0084]
每个卷积核提取出不同的类型特征,得到不同的特征维度:
[0085][0086]
其中jk表示第k个卷积核对应的特征维度信息,θ(
·
)表示激活函数,k表示表示卷积核的个数,dk表示第k个卷积核的特征值,为卷积运算,f
ik
表示第k个卷积核时第i层的特征,f
ik-1
表示第k-1个卷积核时第i层的特征,b表示影响因子。
[0087]
我们把信息中排除了冗余后的平均信息量称为信息熵,作为池化层的输出。有助于减少维度,避免参数过多,防止过拟合的情况出现。然后经过全连接层将不同的特征维度通过权值矩阵组装成完整的图。
[0088]
接下来,计算最大信息冗余mir:
[0089]
mir=[y(x)-t];
[0090]
其中x表示短信的字符数,y(x)表示x的冗余值,t表示当前信号通道值,[]表示截断取整。
[0091]
冗余值y(x)的计算公式如下:
[0092][0093]
其中m、n表示偏移调整系数,s表示短信的来源种类数,有网站公司,虚拟平台,以及个人用户端。hs表示来源s的信道频率系数,p(x)表示x需要的网关通信量,x表示短信的字符数。
[0094]
对冗余值y(x)进行筛选,若符合以下条件且o=0则短信有害概率值q为0:
[0095]
(1)当x趋近于0时,趋近于一个常数。
[0096]
(2)mir≤δ,δ为设定的最大冗余值。
[0097]
此时短信为无效内容,例如空白短信,单纯无逻辑的符号等。
[0098]
若符合(1)和/或(2)的短信,则通过目标函数求出基于短信冗余度的短信有害概率值q1,目标函数的式子如下:
[0099][0100]
其中q1表示基于短信冗余度的短信有害概率值,l表示特征向量的行列数,若不足位数,则用0进行补位。y(x)表示x的冗余值,表示wi的转置,wi表示特征向量第i行的有害概率值,wj表示特征向量第j行的有害概率值。
[0101]
s004,当ai智能识别系统学习完步骤s002中的内容后,将会把“欢迎、各位、游客、前来、参加、本次、草原、音乐节”这些分词插入到分词词库中,若某分词为分词词库已有数据,则更改该分词的属性。
[0102]
例如:“欢迎”的词库编号为1,词频数为1,通过数为1,拦截数为0,通过率为100%,拦截率为0%;若ai智能识别系统学习了一条包含“欢迎”这个词语的被拦截文本内容后,那么“欢迎”这个词在词库的属性将更改为:词库编号为1,词频数为2,通过数为1,拦截数为1,通过率为50%,拦截率为50%。
[0103]
根据分词词库中的分词属性,能得到基于分词属性的短信有害概率值q2:
[0104]
q2=max(xwu)
[0105]
如果q2<λ且基于初步筛查的短信有害概率值o=0,则短信有害概率值q为0。
[0106]
如果q2>λ,则基于分词属性的短信有害概率值变为q3:
[0107][0108]
其中λ表示分词筛选阈值,i表示分词集合,xwu表示分词u的拦截率,cu表示第u个分词,xw
uv
表示分词u、v共同出现时的拦截率,c
uv
表示第u个分词相关联的第v个分词,
⊙
表示内积,fw
uv
表示分词u、v共同出现的词频数。
[0109]
由此,得到拦截率q:
[0110]
q=αq1 βq3 o
[0111]
其中α为基于短信冗余度的有害概率权重系数、β为基于分词属性的短信有害概率权重系数。
[0112]
例如:“欢迎各位、游客、前来、参加、本次、草原、音乐节”该段文本内容中:“欢迎”的拦截率为:8%,“各位”的拦截率为:10%“游客”的拦截率为:7%“前来”的拦截率为:9%“参加”的拦截率为:11%“本次”的拦截率为:1%“草原”的拦截率为:15%“音乐节”的拦截率为:3%。其中拦截率最高的分词为“草原”,拦截率15%,小于λ=20%,则q2=20%。
[0113]
s005,设定拦截和通过的阈值,根据一条文本内容中拦截率最高的分词来设定阈值,若该拦截率大于等于最大阈值,如80%,则拦截该条短信;若拦截率小于等于最小阈值,如20%,则该条短信审核通过,若拦截率在最小阈值~最大阈值之间,如20%-80%,则该条短信将转至人工审核库,待人工审核。
[0114]
根据s005求得的拦截率q,与设定的阈值比较,若大于该阈值则进行拦截,若小于阈值则通过。
[0115]
s006,审核结果的输出。若该文本内容中有分词拦截率大于等于80%,则向用户前端输出“该短信内容包含不合法内容,请重新编辑”;若该文本内容中最高拦截率的分词小于等于20%,则向用户前端输出“审核通过,可正常发送”;若该文本内容中最高拦截率的分词处于20%-80%之间,则向人工审核前端输出“***分词拦截率在**%,可能涉及不合法内容,请人工审核确认。”[0116]
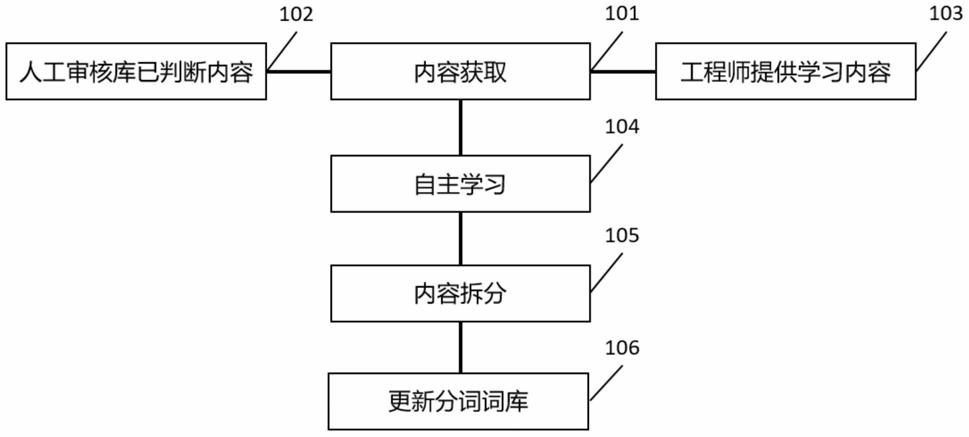
ai智能识别系统如图1所示,包括:
[0117]
内容获取模块101、人工审核库已判断内容模块102、工程师提供内容模块103、自助学习模块104、内容拆分模块105、更新分词词库模块106,
[0118]
内容获取模块101的数据输入端分别与人工审核库已判断内容模块102的数据输出端、工程师提供内容模块103的数据输出端相连,内容获取模块101的数据输出端与自主学习模块104的数据输入端相连,自主学习模块104的数据输出端与内容拆分模块105的数据输入端相连,内容拆分模块105的数据输出端与更新分词词库模块106的数据输入端相连。
[0119]
内容获取模块101:ai智能识别系统的学习内容来源于步骤102人工审核库已判断内容和步骤103工程师提供内容两大数据集;
[0120]
自助学习模块104:ai智能识别系统通过文字库自主学习文字内容,每一条文本内容均有唯一编号textid,给ai智能识别系统设定一个定期扫描素材库的任务,若有新增的素材,则对该素材进行分析;
[0121]
内容拆分模块105、更新分词词库模块106:将文本内容拆分成若干个分词,根据每一个分词查询分词词库,若词频数为0,则向分词词库插入该分词,若分词词频数大于0,则在该分词的词频数加1,拦截/通过数加1,并更新拦截率。
[0122]
ai智能识别系统在业务中的应用,如图2所示,包括以下步骤:
[0123]
步骤201:终端或平台用户编辑短信;
[0124]
步骤202:发送短信;
[0125]
步骤203:短信需经过ai智能识别系统的分析审核,然后根据识别结果执行步骤204、步骤206、步骤207中的任意一种;
[0126]
步骤204:短信内容无异常,执行步骤205;
[0127]
步骤205:可直接发送,并返回用户发送成功信息;
[0128]
步骤206:识别到疑似违规内容,执行步骤208;
[0129]
步骤207:识别到违规内容,则将该信息返回用户重新编辑,执行步骤201;
[0130]
步骤208:将疑似违规短信移至人工审核库进行人工审核,然后根据审核结果执行步骤209、步骤210中的任意一种;
[0131]
步骤209:人工审核未违规,则执行步骤205,同时将该短信返回人工审核库已判断内容模块102进行ai智能识别系统再学习;
[0132]
步骤210:人工审核确认违规,则将该信息返回用户重新编辑,同时将该短信返回人工审核库已判断内容模块102进行ai智能识别系统再学习。
[0133]
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不
脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
