1.本发明涉及口译教学技术领域,更具体的说是涉及一种基于蚁群算法的英语口译教学辅助方法及系统。
背景技术:
2.翻译工作是我国对外交流和国际交往的桥梁和纽带,发展翻译事业也是我国对外改革开放的必然要求。为提高翻译人员素质、加强翻译人才队伍建设,进一步推广翻译专业资格考试是顺应国家经济发展的需要的。翻译专业人才在我国经济发展和社会进步中起着非常重要的作用,特别是在吸收引进外国的先进科技知识和加强国际交流与合作方面,翻译是桥梁和纽带。
3.口译教学的发展对于日后的翻译工作至关重要,对于口译过程中面临不同音色、不同发音习惯的人可能口译就会出现错误,目前口译教学单纯是通过教师经验去开展教学工作,对于教师的工作难度可想而知。
4.因此,如何提供一种能够针对不同发音习惯的口译教学辅助方法及系统是本领域技术人员亟需解决的问题。
技术实现要素:
5.有鉴于此,本发明提供了一种基于蚁群算法的英语口译教学辅助方法及系统,能够针对不同发音习惯,准确的匹配需要口译的语言。
6.为了实现上述目的,本发明提供如下技术方案:
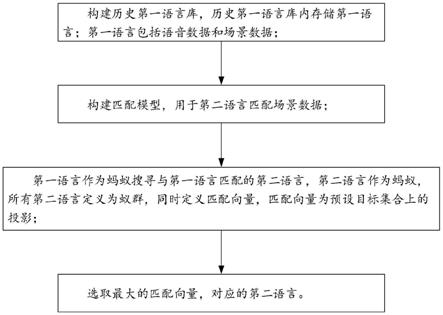
7.一种基于蚁群算法的英语口译教学辅助方法,具体步骤包括如下:
8.构建历史第一语言库,所述历史第一语言库内存储第一语言;所述第一语言包括语音数据和场景数据;
9.构建匹配模型,用于第二语言匹配场景数据;
10.所述第一语言作为目标源,所述第二语言作为蚂蚁,所有所述第二语言定义为蚁群,同时定义匹配向量,所述匹配向量为预设目标集合上的投影;
11.选取最大的匹配向量,对应的第二语言。
12.可选的,在一种基于蚁群算法的英语口译教学辅助方法中,构建匹配模型具体步骤如下:
13.提取语音数据中的语音特征参数,和场景数据中的场景特征参数;
14.根据所述场景特征参数与所述语音特征参数进行分类,并标记;
15.输入待匹配语音数据,对所述语音数据根据语法规则进行拆分;
16.根据拆分后的语音数据匹配对应的场景数据。
17.可选的,在一种基于蚁群算法的英语口译教学辅助方法中,所述第二语言均分配概率矩阵和匹配矩阵;所述概率矩阵用于描述所述第一语言与所述第二语言匹配的概率;所述匹配矩阵用于描述所述第二语言和所述第一语言匹配的初步结果。
18.可选的,在一种基于蚁群算法的英语口译教学辅助方法中,选取最大的匹配向量具体步骤如下:
19.循环迭代所述第二语言,当所述第二语言的语义与所述第一语言匹配作为候选语言;
20.所述候选语言根据所述场景数据更新所述概率矩阵,所述概率矩阵根据当前场景数据中出现的频次表征所述第一语言与所述第二语言匹配的概率;
21.根据所述概率矩阵更新匹配矩阵,并计算更新后的所述匹配矩阵的匹配向量,选取最大的匹配向量。
22.可选的,在一种基于蚁群算法的英语口译教学辅助方法中,所述匹配矩阵和概率矩阵表达式如下:
23.a=(a
ij
);
[0024][0025]
b=(b
ij
);
[0026]
其中,i表示第一语言的第i个元素;j表示第二语言第j个候选语言,b
ij
表示第j个候选语言出现次数与j个候选语言出现次数的比值。
[0027]
一种基于蚁群算法的英语口译教学辅助系统,包括:
[0028]
语言库模块,构建历史第一语言库,所述历史第一语言库内存储第一语言;所述第一语言包括语音数据和场景数据;
[0029]
匹配模块,构建匹配模型,用于第二语言匹配场景数据;
[0030]
搜寻模块,所述第一语言作为目标源,所述第二语言作为蚂蚁,所有所述第二语言定义为蚁群,同时定义匹配向量,所述匹配向量为预设目标集合上的投影;
[0031]
选择模块,选取最大的匹配向量,对应的第二语言。
[0032]
可选的,在一种基于蚁群算法的英语口译教学辅助系统中,匹配模块包括:
[0033]
提取特征单元,提取语音数据中的语音特征参数和场景数据中的场景特征参数;
[0034]
分类单元,根据所述场景特征参数与所述语音特征参数进行分类,并标记;
[0035]
拆分单元,输入待匹配语音数据,对所述语音数据根据语法规则进行拆分;
[0036]
匹配单元,根据拆分后的语音数据匹配对应的场景数据。
[0037]
可选的,在一种基于蚁群算法的英语口译教学辅助系统中,搜寻模块包括概率单元和匹配单元;
[0038]
所述概率单元生成描述所述第一语言与所述第二语言匹配的概率矩阵;所述匹配单元生成描述所述第二语言和所述第一语言匹配的初步结果对应的矩阵。
[0039]
可选的,在一种基于蚁群算法的英语口译教学辅助系统中,选择单元包括:
[0040]
候选单元,循环迭代所述第二语言,当所述第二语言的语义与所述第一语言匹配作为候选语言;
[0041]
更新单元,所述候选语言根据所述场景数据更新所述概率矩阵,所述概率矩阵根据当前场景数据中出现的频次表征所述第一语言与所述第二语言匹配的概率;
[0042]
匹配向量单元,根据所述概率矩阵更新匹配矩阵,并计算更新后的所述匹配矩阵的匹配向量,选取最大的匹配向量。
[0043]
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于蚁群算法的英语口译教学辅助方法及系统,先通过匹配模型得到语境,第一语言作为目标源,第二语言作为蚂蚁,根据匹配向量最大确定最优的第二语言,获取最大匹配向量时,不断更新匹配矩阵,并根据当前语境出现频次表征概率更新出现概率,保证最优的匹配结果,从而避免口译教学中因为不同的发音习惯,而出现翻译偏差的问题。
附图说明
[0044]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0045]
图1为本发明的方法流程图;
[0046]
图2为本发明的结构框图。
具体实施方式
[0047]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0048]
本发明实施例公开了一种基于蚁群算法的英语口译教学辅助方法及系统,先通过匹配模型得到语境,第一语言作为目标源,第二语言作为蚂蚁,根据匹配向量最大确定最优的第二语言,获取最大匹配向量时,不断更新匹配矩阵,并根据当前语境出现频次表征概率更新出现概率,保证最优的匹配结果,从而避免口译教学中因为不同的发音习惯,而出现翻译偏差的问题。
[0049]
本发明的实施例公开了一种基于蚁群算法的英语口译教学辅助方法,如图1所示,具体步骤包括如下:
[0050]
构建历史第一语言库,历史第一语言库内存储第一语言;第一语言包括语音数据和场景数据;
[0051]
构建匹配模型,用于第二语言匹配场景数据;
[0052]
第一语言作为蚂蚁搜寻与第一语言匹配的第二语言,第二语言作为蚂蚁,所有第二语言定义为蚁群,同时定义匹配向量,匹配向量为预设目标集合上的投影;
[0053]
选取最大的匹配向量,对应的第二语言。
[0054]
需要了解的是:通过构建匹配模型能够初步剔除部分不适于当前语境的语音数据,通过利用可能的匹配结果去寻找与待翻译的语言,根据匹配向量最大确定最优的第二语言,获取最大匹配向量时,不断更新匹配矩阵,并根据当前语境出现频次表征概率更新出现概率,保证最优的匹配结果。
[0055]
为了进一步优化上述技术方案,构建匹配模型具体步骤如下:
[0056]
提取语音数据中的语音特征参数,和场景数据中的场景特征参数;
[0057]
根据场景特征参数与语音特征参数进行分类,并标记;
[0058]
输入待匹配语音数据,对语音数据根据语法规则进行拆分;
[0059]
根据拆分后的语音数据匹配对应的场景数据。
[0060]
进一步,将待匹配的语音例如“苹果什么价格?”根据语法规则,进行拆分“苹果”、“价格”;应用场景为交易过程中。
[0061]
为了进一步优化上述技术方案,第二语言均分配概率矩阵和匹配矩阵;概率矩阵用于描述第一语言与第二语言匹配的概率;匹配矩阵用于描述第二语言和第一语言匹配的初步结果。
[0062]
为了进一步优化上述技术方案,选取最大的匹配向量具体步骤如下:
[0063]
循环迭代第二语言,当第二语言的语义与第一语言匹配作为候选语言;
[0064]
候选语言根据场景数据更新概率矩阵,概率矩阵根据当前场景数据中出现的频次表征第一语言与第二语言匹配的概率;
[0065]
根据概率矩阵更新匹配矩阵,并计算更新后的匹配矩阵的匹配向量,选取最大的匹配向量。
[0066]
为了进一步优化上述技术方案,匹配矩阵和概率矩阵表达式如下:
[0067]
a=(a
ij
);
[0068][0069]
b=(b
ij
);
[0070]
其中,i表示第一语言的第i个元素;j表示第二语言第j个候选语言,b
ij
表示第j个候选语言出现次数与j个候选语言出现次数的比值。
[0071]
本发明的另一实施例公开了一种基于蚁群算法的英语口译教学辅助系统,如图2所示,包括:
[0072]
语言库模块,构建历史第一语言库,历史第一语言库内存储第一语言;第一语言包括语音数据和场景数据;
[0073]
匹配模块,构建匹配模型,用于第二语言匹配场景数据;
[0074]
搜寻模块,第一语言作为蚂蚁搜寻与第一语言匹配的第二语言,第二语言作为蚂蚁,所有第二语言定义为蚁群,同时定义匹配向量,匹配向量为预设目标集合上的投影;
[0075]
选择模块,选取最大的匹配向量,对应的第二语言。
[0076]
为了进一步优化上述技术方案,匹配模块包括:
[0077]
提取特征单元,提取语音数据中的语音特征参数和场景数据中的场景特征参数;
[0078]
分类单元,根据场景特征参数与语音特征参数进行分类,并标记;
[0079]
拆分单元,输入待匹配语音数据,对语音数据根据语法规则进行拆分;
[0080]
匹配单元,根据拆分后的语音数据匹配对应的场景数据。
[0081]
为了进一步优化上述技术方案,搜寻模块包括概率单元和匹配单元;
[0082]
概率单元生成描述第一语言与第二语言匹配的概率矩阵;匹配单元生成描述第二语言和第一语言匹配的初步结果对应的矩阵。
[0083]
为了进一步优化上述技术方案,选择单元包括:
[0084]
候选单元,循环迭代第二语言,当第二语言的语义与第一语言匹配作为候选语言;
[0085]
更新单元,候选语言根据场景数据更新概率矩阵,概率矩阵根据当前场景数据中
出现的频次表征第一语言与第二语言匹配的概率;
[0086]
匹配向量单元,根据概率矩阵更新匹配矩阵,并计算更新后的匹配矩阵的匹配向量,选取最大的匹配向量。
[0087]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0088]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。