1.本发明涉及毫米波雷达点云与对象识别的技术领域,尤其是指一种基于毫米波雷达点云聚类和深度学习的行人识别方法。
背景技术:
2.常见的行人识别是基于计算机视觉的,但是视觉解决方案需要拍摄图片,因此存在用户隐私的安全问题,另外会受到光照条件的影响,在光线太弱等较差环境条件下无法获得清晰的图像,从而导致对象识别失败。因此不适合用在酒店、银行、私人住宅等隐私安全要求较高的地方。
3.近期,使用毫米波无线信号进行行人识别受到广泛关注。毫米波雷达对不同的光照和天气条件具有很好的鲁棒性,数据提取时不受人的额外特征例如衣服颜色的影响,此外,与视觉特征相比,人体的回波信号特征在长时间内更加稳定。但是低空间分辨率的雷达点云不能清晰地反映人体的几何信息,并且雷达点云的分布稀疏,对行人识别任务提出了挑战。
4.目前基于深度学习的毫米波雷达点云目标识别方法主要分为两大类,即基于点云的方法和基于图像处理的方法。
5.基于点云的方法是从点云处理的角度入手,直接利用原始点云进行识别,例如pointnet、srpnet、tcpcn等。pointnet只关注单帧特征提取;srpnet在预处理阶段并没有改变点云数据稀疏的情况,并且采用双向长短期记忆网络(bilstm)同时提取时空特征,导致模型的准确度和时间效率不佳;tcpcn只关注每一帧点云的局部特征,而且点云帧数过多,使得时间复杂度偏高,不利于准确提取时间特征。
6.第二类则是借鉴图像处理领域的方法,将毫米波雷达的3d点云数据映射为图像数据,然后利用深度学习进行行人识别,例如mmgaitnet,在不同通道上对帧内固定数量的点云使用resnet提取特征,最后融合所有局部特征进行识别。
7.虽然mmgaitnet可以通过增加设备数量或将点云中的点多次复制作为点云的填充点来提高点云密度,但这种方法不仅提高了成本,填充点也有可能是噪声点,干扰了模型的训练;而且模型从图像的角度处理点云数据,忽略了点云的全局特征与时间特征,特征学习也没有侧重点。
技术实现要素:
8.本发明的目的在于克服现有技术的缺点与不足,提出了一种基于毫米波雷达点云聚类和深度学习的行人识别方法,采用基于聚类的多帧合并配合重采样的方法进行稀疏点云数据的预处理,提高点云密度,降低时间复杂度;使用pointnet 网络结构提取每帧点云的全局空间特征并使用注意力模块为不同的特征加权;使用堆叠的lstm提取时间特征,提高了行人识别的准确率以及计算效率。
9.为实现上述目的,本发明所提供的技术方案为:基于毫米波雷达点云聚类和深度
学习的行人识别方法,包括以下步骤:
10.1)对毫米波雷达采集的原始点云数据进行点云聚类的预处理,提高每帧点云数量;
11.2)使用预处理的点云数据训练由空间特征提取模块、注意力模块、时间特征提取模块组成的深度学习网络模型,直到模型收敛,再输入待测数据,得到行人识别的结果;其中,使用pointnet 网络作为空间特征提取模块,批次提取每帧点云的空间特征;使用注意力模块衡量每一帧提取到的空间特征并对空间特征向量加权;使用两个堆叠的长短期记忆网络(lstm)作为时间特征提取模块,提取点云的时间特征。
12.进一步,所述步骤1)包括以下步骤:
13.1.1)使用多帧合并算法,按照固定时间段,将毫米波雷达采集到的同一时间段内的多帧点云合并为一帧,保留采集到的所有点数,算法表示为:
[0014][0015]
其中,f
p
表示合并后每帧的点数,p
total
表示采集到的点的总数,f表示固定的帧数,即固定帧数后,按照时间间隔,依次按照式(1)分配点数,减少帧数,降低时间复杂度,提高点云密度;
[0016]
1.2)使用层次凝聚聚类算法即hac算法对合并后的帧内点云进行上采样,每一步都将合并的簇的质心加入点云中,作为新点:
[0017]
p(m,n)=αap(a,n) αbp(b,n) βp(a,b) γ|p(a,n)-p(b,n)|
ꢀꢀꢀ
(2)
[0018]
其中,p(,)表示邻近度函数,m是由簇a和b合并形成的新簇,n是a、b以外的原簇,αa、αb、β、γ均表示权重,0<αa<1,0<αb<1,0<β<1,0<γ<1,hac算法的每一步都根据簇邻近度合并最接近的两个簇,迭代运行,直到达到终止条件;
[0019]
1.3)对上采样的点云进行k均值聚类下采样,k是定义的每帧点云被采样的固定点数,也是pointnet 网络的固定输入点数。
[0020]
进一步,在步骤2)中,空间特征提取模块使用pointnet 网络结构,首先提取每帧点云的局部特征以捕获小区域中的重要结构,然后将局部特征进一步分组为大的单元以提取更高级别的特征,重复上述过程,直到计算出整个点云数据的全局特征。
[0021]
进一步,在步骤2)中,注意力模块使用1个多层感知机(mlp)来衡量每一帧提取的特征,通过学习pointnet 网络的输出特征向量来生成权重,其提取得到的权重与空间特征提取模块输出的特征向量相乘,强调有意义的特征,提高模型的鲁棒性,使用softmax函数为激活函数,加权后的特征向量作为时间特征提取模块的输入。
[0022]
进一步,在步骤2)中,时间特征提取模块采用两个堆叠的lstm层,每个lstm层表示为:
[0023][0024][0025][0026]
[0027][0028]
其中,f
t
是遗忘门,i
t
是输入门,o
t
是输出门,c
t
是控制门,c
t-1
是前一个时间步的控制门,s
t
是时间步长,是隐藏状态,j只有两个取值1或2,是前一个时间步的隐藏状态,uf、vf、ui、vi、uo、vo、uc、vc是对应门的权重矩阵,bf、bi、bo、bc是模型偏差,σ是sigmoid激活函数,符号ο表示哈达玛积;
[0029]
为了正则化,在lstm层后增加两个全连接层和一个dropout层。
[0030]
进一步,在步骤2)中,将预处理后的点云数据按照8:1:1的比例分为训练集、验证集和测试集,使用训练集和验证集对深度学习网络模型进行训练并验证,模型使用交叉熵损失函数作为分类损失函数lc:
[0031][0032]
其中,m和n是输出所属的类别,k是类别总数,r是样本总数,x
ma
是样本a的类别为m的标签,x
na
是样本a的类别n的标签;
[0033]
为了约束特征变换矩阵接近正交矩阵,使用softmax函数训练损失函数时增加一项正则化损失函数lr:
[0034]
lr=||i-hh
t
||2ꢀꢀꢀ
(9)
[0035]
其中,i是单位矩阵,h是特征变换矩阵;
[0036]
由式(8)和式(9)得到损失函数l:
[0037]
l=lc αlrꢀꢀꢀ
(10)
[0038]
其中,α表示权重,0<α<1;
[0039]
获取训练误差后,网络模型沿梯度方向传播,更新网络模型参数,迭代训练,直到网络模型收敛;而在测试时,输入测试集,即可得到行人识别的结果。
[0040]
本发明与现有技术相比,具有如下优点与有益效果:
[0041]
1、本发明使用毫米波雷达采集点云数据,保证了用户的隐私安全也避免了外部环境的影响。
[0042]
2、本发明使用基于点云聚类的帧合并和重采样方法进行预处理,解决了雷达点云稀疏的问题并且降低了时间复杂度。
[0043]
3、本发明学习每帧点云的全局时空特征并加入注意力机制,在损失函数中加入正则,提高了模型的鲁棒性和对象识别的准确度,降低了模型的时间损耗。
附图说明
[0044]
图1是实施例中毫米波雷达点云数据预处理流程图。
[0045]
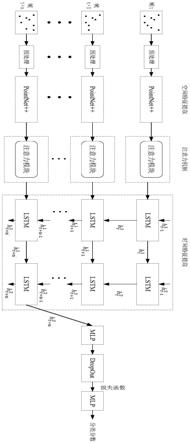
图2是实施例中深度学习网络模型的结构示意图。
具体实施方式
[0046]
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
[0047]
参见图1和图2所示,本实施例公开了一种基于毫米波雷达点云聚类和深度学习的
行人识别方法,其具体情况如下:
[0048]
1)对毫米波雷达采集的原始点云数据进行点云聚类的预处理,提高每帧点云数量,包括以下步骤:
[0049]
1.1)使用多帧合并算法,在点上应用时间衰减,按照固定时间段将毫米波雷达采集到的多帧点云合并为一帧,保留原始帧的所有点数,算法表示为:
[0050][0051]
其中,f
p
表示合并后每帧的点数,p
total
表示采集到的点的总数,f表示固定的帧数,即固定帧数后,按照时间间隔,依次按照式(1)分配点数,重新排列帧内的点云,以此类推,实现多帧合并,减少帧数的同时降低时间复杂度,提高点云密度。
[0052]
1.2)使用层次凝聚聚类算法(hac算法)对合并后的帧内点云进行上采样,将训练样本中的每个点都当做一个聚类,计算每两个聚类之间的距离,将距离最近或最相似的两个聚类进行合并,并把每个簇的质心都作为一个新点添加到点云中,防止生成单粒子簇,迭代运行hac直到一帧中达到预定义的点数:
[0053]
p(m,n)=αap(a,n) αbp(b,n) βp(a,b) γ|p(a,n)-p(b,n)|
ꢀꢀꢀ
(2)
[0054]
其中,p(,)表示邻近度函数,m是由簇a和b合并形成的新簇,n是a、b以外的原簇,αa、αb、β、γ均表示权重,0<αa<1,0<αb<1,0<β<1,0<γ<1,hac算法的每一步都根据簇邻近度合并最接近的两个簇,迭代运行,直到达到终止条件;
[0055]
1.3)对上采样的点云进行k均值聚类下采样,k是定义的每帧点云被采样的固定点数,也是pointnet 网络的固定输入点数。
[0056]
2)将预处理后的点云数据按照8:1:1的比例分为训练集、验证集和测试集,使用训练集和验证集对由空间特征提取模块、注意力模块、时间特征提取模块组成的深度学习网络模型进行训练并验证,模型使用交叉熵损失函数作为分类损失函数lc:
[0057][0058]
其中,m和n是输出所属的类别,k是类别总数,r是样本总数,x
ma
是样本a的类别为m的标签,x
na
是样本a的类别n的标签;
[0059]
为了约束特征变换矩阵接近正交矩阵,使用softmax函数训练损失函数时增加一项正则化损失函数lr:
[0060]
lr=||i-hh
t
||2ꢀꢀꢀ
(9)
[0061]
其中,i是单位矩阵,h是特征变换矩阵;
[0062]
由式(8)和式(9)得到损失函数l:
[0063]
l=lc αlrꢀꢀꢀ
(10)
[0064]
其中,α表示权重,0<α<1;
[0065]
获取训练误差后,网络模型沿梯度方向传播,更新网络模型参数,迭代训练,直到网络模型收敛;而在测试时,输入测试集,即可得到行人识别的结果。
[0066]
其中,使用pointnet 网络作为空间特征提取模块,批次提取每帧点云的空间特征,以q
×
p
×
3的点云作为输入(q表示批量大小,p表示点数),使用两个集合抽象层来模拟cnn的卷积层,每个抽象层包括一个采样层、一个分组层和一个pointnet层;采样层输入预
处理后的每帧点云数据,输出一组定义了局部区域质心的点,分组层根据质心算则其“相邻”点来构建局部区域的集合,pointnet层将局部区域编码为特征向量,pointnet层后接一个全连接层输出每帧点云的全局特征向量。
[0067]
使用注意力模块衡量每一帧提取到的空间特征并对空间特征向量加权,注意力模块使用1个多层感知机(mlp)来衡量每一帧提取的特征,通过学习pointnet 网络的输出特征向量来生成权重,其提取得到的权重与空间特征提取模块输出的特征向量相乘,强调有意义的特征,提高模型的鲁棒性,使用softmax函数为激活函数,加权后的特征向量作为时间特征提取模块的输入。
[0068]
使用两个堆叠的长短期记忆网络(lstm)作为时间特征提取模块,提取点云的时间特征,即时间特征提取模块包括两个堆叠的lstm层,每个lstm层可表示为:
[0069][0070][0071][0072][0073][0074]
其中,f
t
是遗忘门,i
t
是输入门,o
t
是输出门,c
t
是控制门,c
t-1
是前一个时间步的控制门,s
t
是时间步长,是隐藏状态,j只有两个取值1或2,是前一个时间步的隐藏状态,uf、vf、ui、vi、uo、vo、uc、vc是对应门的权重矩阵,bf、bi、bo、bc是模型偏差,σ是sigmoid激活函数,符号ο表示哈达玛积。
[0075]
为了正则化,在lstm层后增加两个全连接层和一个dropout层。
[0076]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
