1.本发明涉及数据挖掘的技术领域,尤其涉及一种考虑典型因素综合能源系统用能行为数据挖掘方法及装置。
背景技术:
2.随着大数据时代的到来,在智能电网的背景下,电网信息采集系统和客户服务信息系统中积累了大量的用电数据,隐藏了大量的用电信息。而工业负荷作为用电大户,如何有序高效,节能环保用电意义重大。因此,未来的智能电网应在确保用电安全可靠的同时,为不同用户提供更高质量、更有针对性的服务和科学建议。因此,分析用户和供电企业用电量的增长规律和特征具有重要意义。
3.用电信息采集系统中积累的海量用户历史负荷数据,包含了用户的用电行为和习惯。它不仅可以提高负荷预测的准确性和调度管理水平,还可以为电价设定、经济调度和需求响应提供支持。随着新一轮电力体制改革,用电量大、用电稳定的工商业用户将直接参与双边交易、电力现货市场和需求侧响应,承担清洁能源配额,将对发电调度方案、电网运行方式、电网调峰能力、新能源消纳等产生重大影响。
4.目前对能源使用行为的分析方法有很多,如使用时长算法、根据社区特征分析能源使用异常、使用模糊聚类算法研究电力客户的行为模式等。但目前使用能量的用户行为数据难以定量估计,用户行为数据的挖掘精度有待进一步提高。为了进一步提高数据挖掘的准确性,本文提出了一种考虑典型因素的综合能源系统能耗行为数据挖掘方法。
技术实现要素:
5.电力改革下,售电端的开放使得电力公司、消费者和整个电力市场获得不同用户的用电行为变得非常重要,不同生活习惯和背景的用户有不同的用电行为。从电力公司的角度来看,对用户行为的分析可以帮助电力零售商制定更高效、更令人满意的营销和需求方案,有助于积累大量客户。对于居民用电用户,通过与电力公司的互动,可以更好地了解他们的消费模式,甚至可以调整和优化他们的用电习惯,在电包激励下削峰填谷,降低家庭用电成本也有助于电网的整体稳定性。
6.单用户负荷模式提取是研究用户分类的基础,有助于实现需求响应,使电力供应商实现基于负荷模式和消费类别的有效能源控制、灵活定价和需求管理,使电力用户了解他们的负载模式,并应对波动的价格,从而减少电费。从日负荷曲线聚类中提取负荷模式有两个挑战,一是降维减少信息丢失,二是提高日负荷曲线聚类的性能。
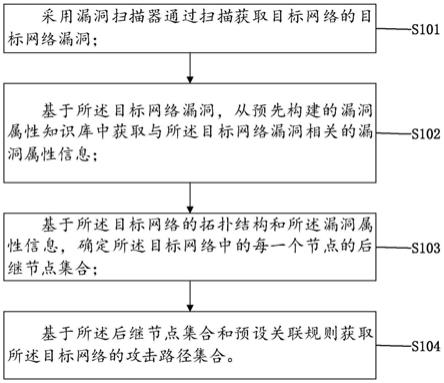
7.为实现上述目的,本发明提供如下技术方案:
8.一种考虑典型因素综合能源系统用能行为数据挖掘方法,所述方法按照以下步骤进行,
9.通过k-means算法获取行为数据的负载特征曲线;
10.对所述负载特征曲线上的不良数据进行修正,得到用电修正曲线;
11.采用标准化处理对所述修正曲线进行统一量化,得到用电数据的归一化值;
12.将所述用电量数据归一化值形成用户用电行为特征序列;
13.根据协方差计算所述特征序列中相邻周期的数值关系之间的相关性,得到相关性数值关系;
14.根据所述相关性数值关系,提取特征指标,以实现数据挖掘。
15.优选的,所述不良数据包括在数据采集系统和其他外部因素的影响下,数据丢失或损坏;所述不良数据会影响负荷分析的准确性。
16.优选的,所述通过k-means算法获取行为数据的负载特征曲线包括,采用k-means算法对每个用户的日负荷曲线进行聚类,其中,用户工作日、周末和节假日负荷曲线各用户之间差异较大,用户工作日、周末和节假日进行单独聚类。
17.优选的,所述不良数据进行修正包括,不良数据修正方程为:
[0018][0019]
式(1)中,td是要修改的曲线,tc是特性曲线,p、q分别是td、tc 上的点,t(n)为负载特征曲线,q(n)是用电修正曲线,n是用户曲线的一个点。
[0020]
优选的,所述采用标准化处理对所述修正曲线进行统一量化,变换过程表示为:
[0021]g*
=q(n)х(g’ g
min
)/g
max
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0022]
式(2)中,g
*
表示用电数据的归一化值,g’表示用户在选定时段内的用电量,g
min
表示用户在选定时段内的最小用电量,以及g
max
表示用电行为的最大值,q(n)是用电修正曲线。
[0023]
优选的,所述用户用电行为特征序列,其数值关系可表示为:
[0024]em
={ed,d=1,2,...,m}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0025]
式(3)中,em表示第m个计量周期的用户用电行为特征序列,m代表周期数,m为周期天数,ed为周期负荷最大值,d为特征天数。
[0026]
优选的,所述特征序列中相邻周期的数值关系之间的相关性,相关性数值关系表示为:
[0027][0028]
式(4)中,e(em)表示异常用电数据的最大筛选系数,n为周期总数,xj表示异常用电数据的实时判别向量元素。
[0029]
优选的,采用卡方检验过程对特征序列的干扰数据进行筛选,可表示为:
[0030][0031]
式(5)中,β为卡方检验结果,该结果越大表明实际值与理论值偏差越大;m为第m个计量周期;n为周期总数;am表示用电量数据缺失值的标准计算项系数。
[0032]
优选的,所述提取特征指标,包括用户用电行为特征提取的过程可以表示为:
[0033]
α=p
m-1
(p
m 1-p
m-1
)2ꢀꢀꢀꢀ
(6)
[0034]
式(6)中,p
m-1
代表上一期用户用电行为数据集,p
m 1
代表下一期用户用电行为数据
集。
[0035]
优选的,所述p
m 1
和p
m-1
为em经用卡方检验过程剔除干扰数据后的用户用电行为特征序列。
[0036]
一种考虑典型因素综合能源系统用能行为数据挖掘装置,所述挖掘装置包括:
[0037]
修正单元,用于通过k-means算法获取行为数据的负载特征曲线,对所述负载特征曲线上的不良数据进行修正,得到用电修正曲线,并采用标准化处理对所述修正曲线进行统一量化,得到用电数据的归一化值;
[0038]
相关性确定单元,用于将所述用电量数据归一化值形成用户用电行为特征序列,根据协方差计算所述特征序列中相邻周期的数值关系之间的相关性,得到相关性数值关系;
[0039]
数据挖掘单元,用于根据所述相关性数值关系,提取特征指标,以实现数据挖掘。
[0040]
本发明的技术效果和优点:
[0041]
为了避免典型因素的干扰,提高数据挖掘的准确性,本发明提出了一种考虑典型因素综合能源系统用能行为数据挖掘方法及装置。
[0042]
1、采用k-means算法对损坏的数据进行修正,并对数据中部分受干扰的数据进行挖掘和边缘化;
[0043]
2、处理后的用户用电行为数据中存在一些干扰数据,为了避免典型因素的影响,采用标准化处理方法对行为数据进行量化,可以准确提取用户的用电行为特征。
[0044]
综上所述,为了避免典型因素的干扰,提高数据挖掘的准确性,本文提出了一种综合能源系统能耗行为的数据挖掘方法,采用k-means算法对损坏的数据进行修正,处理后的用户用电行为数据中存在一些干扰数据,为了避免典型因素的影响,有效提取用电数据,采用标准化处理方法对行为数据进行量化,提高了数据挖掘的准确性。同时,本发明的提取精度与长短时算法(传统方法)和模糊聚类算法(传统方法)进行比较,本发明所提出的方法具有明显的。
[0045]
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书中所指出的结构来实现和获得。
具体实施方式
[0046]
下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0047]
电力改革下,售电端的开放使得电力公司、消费者和整个电力市场获得不同用户的用电行为变得非常重要,不同生活习惯和背景的用户有不同的用电行为。从电力公司的角度来看,对用户行为的分析可以帮助电力零售商制定更高效、更令人满意的营销和需求方案,有助于积累大量客户。对于居民用电用户,通过与电力公司的互动,可以更好地了解他们的消费模式,甚至可以调整和优化他们的用电习惯,在电包激励下削峰填谷,降低家庭用电成本也有助于电网的整体稳定性。
[0048]
单用户负荷模式提取是研究用户分类的基础,有助于实现需求响应,使电力供应商实现基于负荷模式和消费类别的有效能源控制、灵活定价和需求管理,使电力用户了解他们的负载模式,并应对波动的价格,从而减少电费。从日负荷曲线聚类中提取负荷模式有两个挑战,一是降维减少信息丢失,二是提高日负荷曲线聚类的性能。由于数据采集系统和其他外部因素的影响,数据经常丢失或损坏。这些不良数据的存在会影响负荷分析的准确性,必须予以排除和修复。
[0049]
为解决现有技术的不足,本发明公开了一种考虑典型因素的综合能源系统用能行为数据挖掘方法,其中,所述方法包括:通过k-means算法获取行为数据的负载特征曲线;对所述负载特征曲线上的不良数据进行修正,得到用电修正曲线;采用标准化处理对所述修正曲线进行统一量化,得到用电数据的归一化值;所述用电量数据归一化值根据计量周期形成的用户用电行为特征序列;根据协方差计算所述特征序列中相邻周期的数值关系之间的相关性,得到相关性数值关系;根据所述相关性数值关系,提取特征指标。
[0050]
传统的数据挖掘方法,如使用时长算法、根据社区特征分析能源使用异常、使用模糊聚类算法研究电力客户的行为模式等,容易受到自然等典型因素的影响,数据挖掘的精度不理想。未解决上述问题,本发明提出一种考虑典型因素综合能源系统能耗行为数据挖掘方法及装置,k-means算法用于对损坏的数据进行校正,并对数据中部分受干扰的数据进行挖掘和边缘化,因此,采用标准化的处理方法对数据进行量化,过滤后,可以准确提取用户的用电行为特征,本发明方法能够有效地提取出正确的行为数据,且准确率高于传统方法。
[0051]
其中,一种考虑典型因素综合能源系统用能行为数据挖掘装置,所述挖掘装置包括:
[0052]
修正单元,用于通过k-means算法获取行为数据的负载特征曲线,对所述负载特征曲线上的不良数据进行修正,得到用电修正曲线,并采用标准化处理对所述修正曲线进行统一量化,得到用电数据的归一化值;
[0053]
相关性确定单元,用于将所述用电量数据归一化值形成用户用电行为特征序列,根据协方差计算所述特征序列中相邻周期的数值关系之间的相关性,得到相关性数值关系;
[0054]
数据挖掘单元,用于根据所述相关性数值关系,提取特征指标,以实现数据挖掘。
[0055]
一种考虑典型因素综合能源系统用能行为数据挖掘方法,所述方法包括以下步骤:通过k-means算法获取行为数据的负载特征曲线;对所述负载特征曲线上的不良数据进行修正,得到用电修正曲线;采用标准化处理对所述修正曲线进行统一量化,得到用电数据的归一化值;将所述用电量数据归一化值形成用户用电行为特征序列;根据协方差计算所述特征序列中相邻周期的数值关系之间的相关性,得到相关性数值关系;根据所述相关性数值关系,提取特征指标,以实现数据挖掘。
[0056]
进一步地,负荷数据的横向相似性,采用k-means算法对每个用户的日负荷曲线进行聚类(用户工作日、周末和节假日负荷曲线由于各用户之间差异较大,在用户工作日、周末和节假日中需要单独聚类),通过k-means 算法获取聚类中心即负载特征曲线,对不良数据进行识别和处理。坏数据修正方程为:不良数据修正方程为:
[0057][0058]
等式(1)中,td是要修改的曲线;tc是特性曲线;p、q分别是td、 tc上的点;t(n)为负载特征曲线;q是用电修正曲线;n是用户曲线的一个点。
[0059]
用户用电行为数据经过挖掘和边缘化处理后,存在一些干扰数据。因此,采用标准化处理对行为数据进行统一量化,变换过程可以表示为:
[0060]
g*=q(n)х(g’ g
min
)/g
max
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0061]
式(2)中,g
*
表示用电数据的归一化值,g’表示用户在该时段内的用电量,g
min
表示用户在该时段内的最小用电量,以及g
max
表示用电行为的最大值。
[0062]
进一步地,在相同变换行为数据的维度后,利用类内部差分矩阵对变换后的分离状态进行处理。
[0063]
鉴于数量级的不同用户可能具有相同的负载曲线模式,因此需要对数据进行归一化,将用户用电量数据归一化后,将数据作为特征序列处理,其数值关系可表示为:
[0064]em
={ed,d=1,2,...,m}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0065]
式(3)中,em表示第m个计量周期的用户用电行为特征序列,m代表周期数、m为周期天数、ed为周期负荷最大值、d为特征天数。
[0066]
进一步地,对应于相邻周期内形成的数值关系,利用协方差计算相邻周期变量之间的相关性,所述相关性数值关系表示为:
[0067][0068]
式(4)中,e(em)表示异常用电数据的最大筛选系数,n为周期总数,xj表示异常用电数据的实时判别向量元素。
[0069]
进一步地,采用卡方检验过程对特征序列的干扰数据进行筛选,可表示为:
[0070][0071]
式(5)中,β为卡方检验结果,该结果越大表明实际值与理论值偏差越大;m为第m个计量周期;n为周期总数;am表示用电量数据缺失值的标准计算项系数。
[0072]
进一步地,em是含有干扰数据的用户用电行为特征序列,因为还有干扰数据,对于提取用电行为特征并进行用电行为预测而言会造成影响导致用户用电特征提取不准确,因此需要剔除干扰数据,利用原交底材料中的卡方检验方法剔除干扰数据,从而是em变为pm,再根据pm进行特征提取。
[0073]
进一步地,为提高特征提取指标的准确性,采用卡方检验过程对干扰数据进行筛选,过滤后,用户用电行为特征提取的过程可以表示为:
[0074]
α=p
m-1
(p
m 1-p
m-1
)2ꢀꢀꢀꢀꢀ
(6)
[0075]
式(6)中,p
m-1
代表上一期用户用电行为数据集,p
m 1
代表下一期用户用电行为数据集。在上述数值处理下,扣除趋势变化剧烈的特征数据后,最终完成特征智能提取方法研究。
[0076]
进一步地,所述p
m 1
和p
m-1
为em经用卡方检验过程剔除干扰数据后的用户用电行为
特征序列。
[0077]
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对本发明的技术方案进行以下详细说明,但不能理解为对本发明可实施范围的限定。
[0078]
目前对能源使用行为的分析方法有很多,如使用时长算法、根据社区特征分析能源使用异常、使用模糊聚类算法研究电力客户的行为模式等。但目前使用能量的用户行为数据难以定量估计,用户行为数据的挖掘精度有待进一步提高。为了避免典型因素的干扰,提高数据挖掘的准确性,本发明提出了一种综合能源系统能耗行为的数据挖掘方法。采用k-means算法对损坏的数据进行修正,处理后的用户用电行为数据中存在一些干扰数据。为了避免典型因素的影响,有效提取用电数据,采用标准化处理方法对行为数据进行量化。
[0079]
本实施例使用的三个多元数据集是全年的用电量、用气量和气候数据,以 24:00日数据的形式呈现。其中,用电数据包括设施、风机、制冷、采暖、室内照明和室内设备用电负荷数据6个变量。燃气和天气数据包含四个变量,前者为设施、供暖、室内设备和热水器的天然气使用数据,后者为气候数据的温度、露点温度和风速。收集整理20组用户用电数据为处理对象,以实际日用电数据为处理对象,编制用户用电数据如表1所示。
[0080]
表1综合用户用电量数据
[0081][0082]
以表1中的数据为标准值,将该方法的提取精度与长短时算法(传统方法1)和模糊聚类算法(传统方法2)进行比较。在本实施例准备的基础上,在对相同的行为特征进行标定提取后,定义了三种提取精度的数值关系的方法如下:
[0083]
[0084]
式(6)中,k为精度数值,相当于把各种提取方法的结果作了归一化处理以方便不同方法之间的比较,处理结果越接近1表明特征提取越准确; n(o)表示数据处理对象,ωo表示指标数据集,w表示行为特征参数。三种方法对应的提取精度对比如表2所示。
[0085]
表2.提取精度结果的三种方法
[0086][0087]
精度值越接近1,表示智能提取方法的精度越高。如表2所示,传统方法1的精密度为0.22~0.28,均值约为0.26;传统方法2的精度为0.34~0.47,均值约为0.42;本发明方法的精度为0.82~0.96,均值约为0.86;三种方法进行比较,其中传统方法1的精密度最差,本发明方法的精密度明显高于两种传统方法。因此从表2中,可以明确的出。与两种传统方法相比,本发明所提出的方法具有最好的精度。
[0088]
综上所述,本发明提出一种考虑典型因素的综合能源系统能耗行为数据挖掘方法,通过k-means算法用于对损坏的数据进行校正,并对数据中部分受干扰的数据进行挖掘和边缘化,因此,采用标准化的处理方法对数据进行量化,过滤后,可以准确提取用户的用电行为特征。结合本实施例的实验结果表明,本发明方法能够有效地提取出正确的行为数据,且准确率高于传统方法。
[0089]
后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。