一种基于分布式的ip v6解析及存储控制方法
技术领域
1.本发明涉及ip位置归属查询及存储算法处理技术领域,特别涉及一种分布式场景下基于bloom和缓存容器的高性能ip v6归属地解析控制方法及存储结构。
背景技术:
2.ip地址(internet protocol address,网际协议地址)是ip协议提供的一种统一的地址格式,它为每一台主机分配一个逻辑地址,每个ip地址都有对应的归属地。ip v6(互联网协议第6版)是互联网工程任务组(ietf)设计的用于替代ipv4的下一代ip协议。
3.现有技术一般使用两种方式来实现归属地查询。一种是使用二分法查找算法来查找ip地址以获取ip地址对应的归属地信息,该方法需要构建一种树形数据结构,典型的是照段位转换为可比较的值,然后依据段位构建红黑树,然后需要将该树型数据结构同步在分布式检索节点的所有节点上,在分布式场景中每个节点同步相同的数据,造成内存占用大,数据一致性难以保障等问题;
4.还有一种是使用分段查询的方式,如将ip v6归属范围固定分为四段或八段,舍弃不在固定段位之内的做精度丢弃。又或者对不在完整段位的数据做补齐,如前三段固定,第四段范围为a到c,则补齐为xxxx:xxxx:xxxx:a、xxxx:xxxx:xxxx:b、xxxx:xxxx:xxxx:c,产生冗余数据。该方案存在数据冗余或精确度下降等问题。
技术实现要素:
5.本发明要解决的技术问题是克服现有技术的缺陷,提供一种基于分布式的ip v6解析及存储控制方法。
6.本发明提供了如下的技术方案:
7.本发明提供一种基于分布式的ip v6解析及存储控制方法,包括ip v6数据加载和ip v6归属地检索;ip v6数据加载包括:
8.s1.获取ip v6数据库并加载,通过定时任务将公开或私有的ip v6数据以文本的方式获取到本地;在加载开始的时候创建临时bloom,使用缓存容器自接口维护版本;而后逐行读取文本信息,并计算将ip v6区域信息转为node结构,将node添加到bloom和缓存容器中;
9.s2更新分布式节点持有的bloomfilter及缓存容器的key版本号,接s1完成后将计算出的临时bloom通过dubbo广播的方式推送到分布式检索节点上,覆盖节点上已有的bloom和版本号;
10.ip v6归属地检索包括:
11.s3格式化查询ip v6地址,在预置bloomfilter种查询前缀,在客户发生交易的时候通过交易触发设备采集客户入网ip,对ip经行格式化补齐,在检索节点内通过ip格式串截取及bloomfilter计算出匹配的ip格式化串和score;
12.s4依据判断出的ip v6前缀在缓存容器中查询ip v6地址对应的归属地,基于s3算
出的ip格式串和score查询缓存容器中的node结构数据,判断如果该node.e大于score则返回node的归属地,反之表示该解析不满足,重新进入到s3中迭代。
13.与现有技术相比,本发明的有益效果如下:
14.1、本方案使用分布式检索架构,满足高并发场景下使用;
15.2、本方案使用并共享数据结构,使用缓存容器内存数据库满足高性能要求,共享数据保障数据一致性,减少相同数据在不同节点上的同步风险;
16.3、本方案使用分布式检索检点本地持有bloom检索器,最大程度将迭代计算本地化,减少缓存容器远程访问次数,满足高性能计算场景;
17.4、本方案采用缓存容器的有序集合结构存储数据结构,数据结构紧密,不做数据冗余和精度损失处理,同时利用有序分值实现快速检索;
18.5、本方案使用版本号控制数据更新,实现快速切换,降低数据维护过程中对检索的影响;
19.6、本方案使用本地bloomfilter,在计算性能影响不大的情况下实现索引数据20倍以上的压缩。
附图说明
20.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
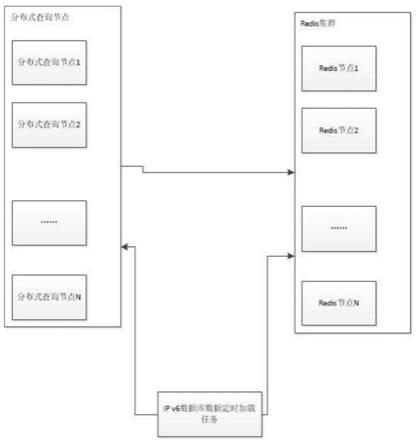
21.图1是本发明的ip v6数据加载及检索架构图;
22.图2是本发明的ip v6数据加载流程图;
23.图3是本发明的ip v6归属数据检索流程图;
24.图4是本发明的实施例示意图之一;
25.图5是本发明的实施例示意图之二;
26.图6是本发明的实施例示意图之三。
具体实施方式
27.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。其中附图中相同的标号全部指的是相同的部件。
28.实施例1
29.如图1-6,本发明提供一种基于分布式的ip v6解析及存储控制方法,包括ip v6数据加载和ip v6归属地检索;ip v6数据加载包括:
30.s1.获取ip v6数据库并加载,通过定时任务将公开或私有的ip v6数据以文本的方式获取到本地;在加载开始的时候创建临时bloom,使用缓存容器自接口维护版本;而后逐行读取文本信息,并计算将ip v6区域信息转为node结构,将node添加到bloom和缓存容器中;
31.s2更新分布式节点持有的bloomfilter及缓存容器的key版本号,接s1完成后将计算出的临时bloom通过dubbo广播的方式推送到分布式检索节点上,覆盖节点上已有的bloom和版本号;
32.ip v6归属地检索包括:
33.s3格式化查询ip v6地址,在预置bloomfilter种查询前缀,在客户发生交易的时候通过交易触发设备采集客户入网ip,对ip经行格式化补齐,在检索节点内通过ip格式串截取及bloomfilter计算出匹配的ip格式化串和score;
34.s4依据判断出的ip v6前缀在缓存容器中查询ip v6地址对应的归属地,基于s3算出的ip格式串和score查询缓存容器中的node结构数据,判断如果该node.e大于score则返回node的归属地,反之表示该解析不满足,重新进入到s3中迭代。
35.ip v6地址由网络运营商分配,通常会将一个区间段内的地址分配给一个城市。比如,将区间段a内的ip v6地址分配给广东省广州市;将区间段b内的ip v6地址分配给广东省深圳市。网络运营商会记录ip v6地址所在的区间段与城市之间的对应关系,然后生成ip归属地数据库。ip v6数据库格式如下表:
[0036][0037][0038]
如第二行2001:250:3000::/48就表示区段内的ip都属于中国广东省广州市。
[0039]
其中冒号分割为4位16进制的数字,不满的情况在前面可以补0;“::”表示中间有连续多个0,1《=n《32;“/48”表示掩码,指2进制的掩码位数。如上ip v6区域补充后:2001:0250:3000:0000:0000:0000:0000:0000;
[0040]
使用“/48”掩码标识范围为前48位ip值固定,后续位数可以任意变化:
[0041]
2001:0250:3000:0000:0000:0000:0000:0000;
[0042]
当用户使用上网设备上网时,网络运营商能够通过上网设备接入互联网所使用的ip地址从ip归属地数据库中查询到上网设备所在的地理位置,该地理位置即为ip归属地,
并将该ip归属地作为ip地址对应的登录地点。如ip v6“2001:250:3000::12:1:1”被解析到上述ip v6区域内,归属地址为:中国广东省广州市;
[0043]
进一步的,s1步骤中,通过定时任务将公开或私有的ip v6数据获取到本地。加载数据的流程如图4所示;
[0044]
格式化:
[0045]
ip v6格式化基于可配置的单位参数n,n为正整数,表示分段16进制的位数,用以控制检索次数。ip v6的格式话结构为:
[0046]
{
[0047]
s:起始点(long)
[0048]
,e:结束点(long)
[0049]
,p:前缀(string)
[0050]
,a:归属地(string)
[0051]
}
[0052]
如“2001:250:3000::/48”,按照n=2解析为:node(s=0,e=255,p=200102503000)。
[0053]
a》首先对ip v6做填充计算,转为“20010250300000000000000000000000”;使用掩码值m=48计算前缀截取位数,满足:
[0054]
p=substr(“20010250300000000000000000000000”,0,indexp)
[0055]
b》s是格式化的ip v6截取前缀后剩余部分获取掩码对n*4求余数位,补齐向右补齐n*4位的值。掩码对n*4求余数submask=mod(m,n*4),当submask=0则s=0;反之满足公式:s=long.parselong(substr(ip,indexp,indexp n),16)》》(n*4-submask))《《(size*4-submask)
[0056]
e是对s作为n*4二进制,高位submask不变,低位改为1的计算;
[0057]
bloom加载:
[0058]
bloom可以看做是对bit-map的扩展,它是通过k个hash函数将这个元素映射成一个位阵列中的k个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了;
[0059]
如果这些点有任何一个0,则被检索元素一定不在;如果都是1,则被检索元素很可能在。在数据加载开始初构建bloomfilter,该步骤将格式化的node的前缀p加载到bloom索引器中;
[0060]
缓存容器加载(如图5所示):
[0061]
缓存容器是一个key-value存储系统,是跨平台的非关系型数据库,缓存容器支持字符串(string)、哈希(hash)、列表(list)、集合(sets)和有序集合(sorted sets)等类型。在数据加载开始初提升缓存容器的key版本号,该步骤将格式化的node加载到缓存容器的有序集合结构中,使用缓存容器api:zadd${pad}_${version}_${p}${s}node;
[0062]
${pad}为缓存容器key常量前缀;
[0063]
${version}为数据加载开始初提升缓存容器的key版本号;
[0064]
${p}为node前缀值p;
[0065]
${s}为node起始值s;
[0066]
在s2更新分布式节点持有的bloomfilter及缓存容器的key版本号中,各个分布式ip v6归属地检索节点上持有bloom索引器和缓存容器的key版本号。结构如下:
[0067]
{b:bloom检索器
[0068]
,v:缓存容器的key版本号
[0069]
}
[0070]
该步骤是在ip v6数据库数据加载完成后,通过广播的方式将最新的bloomfilter和缓存容器的key版本号同步给各个分布式节点,并覆盖;
[0071]
在s3式化查询ip v6地址,在预置bloomfilter种查询前缀中,采用补齐的方式将查询ip v6地址格式化,如“2001:250:3000::1:1”格式化为“20010250300000000000000000010001”。
[0072]
在查询节点使用bloomfilter判断该ip的最大匹配索引,如过不在bloom中,则删除ip格式串最后n位并进一步判断,直到查找到或ip格式串长度不足,如图6所示,计算ip格式串向后获取n位,转为10进制分值score即可进入s4步骤查询;
[0073]
在s4依据判断出的ip v6前缀在缓存容器中查询ip v6地址对应的归属地中,具体包括以下:
[0074]
基于s3如返回的前缀格式串为空,则该表示该ip v6无法解析;反之则在缓存容器中检索,使用缓存容器api:
[0075]
zrevrangebyscore${pad}_${version}_${p}${score}0withscores limit 1
[0076]
${pad}为缓存容器key常量前缀;
[0077]
${version}为数据加载开始初提升缓存容器的key版本号;
[0078]
${p}为s3计算出的存在于bloom中的ip格式串前缀;
[0079]
${score}为s3计算出的存在于bloom中的ip格式串前缀的分值;
[0080]
缓存容器获取的结果为node结构数据,如进一步判断如果该node.e大于score则返回node的归属地,反之表示该解析不满足,重新进入到s3中迭代。
[0081]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。