1.本发明属于车载语音技术服务技术领域,具体涉及一种智能网联汽车助手对话和形象管理系统和方法。
背景技术:
2.语音助手已经逐渐成为智能网联汽车的标配,语音交互已经成为车内人机交互的重要方式,用户通过语音控制车内硬件、软件是智能网联汽车最基础的功能。一方面用户对车载语音助手的专业知识覆盖能力的要求越来越高,另一方面用户希望通过直观的、更形象生动的形式获取关于汽车问题的知识。对于问答型对话如何将对话输出结果与形象展示有机结合,成为了提升智能网联汽车使用体验的关键。
3.现有技术方法缺点:1.大部分智能网联汽车助手均采用抽象的几何动图作为语音助手与用户交互反馈的补充,几何形象无法准确反映对话结果中所要表现的含义;2.语音交互逐渐由抽象到拟人化转变,几何形象动作状态的情感化设计体验相对较差,几何形象无法准确表达对话输出结果中的情感状态。
技术实现要素:
4.针对现有技术的上述不足,本发明要解决的技术问题是提供一种智能网联汽车助手对话和形象管理系统和方法,避免智能网联汽车助手语音回复内容与形象动作联动性不足的问题,取得智能网联汽车助手的形象动作兼具情感性、专业性的效果。
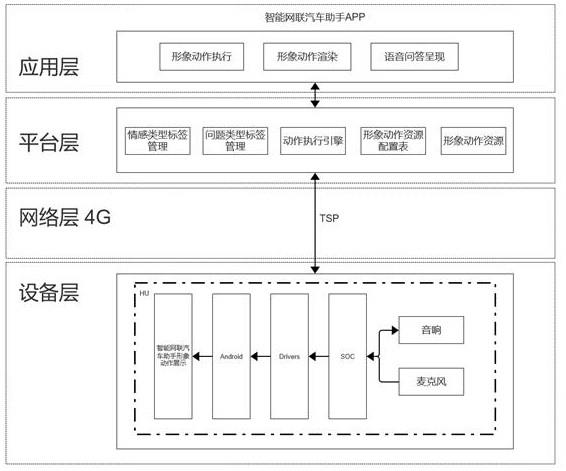
5.为解决上述技术问题,本发明采用如下技术方案:智能网联汽车助手对话和形象管理系统,包括车载主机终端和云端,车载主机终端接收来自云端的动作指令从而完成智能网联汽车助手形象动作执行,所述云端用于为所述智能网联汽车助手形象动作配置情感类型标签、问题类型标签以及相应的动作类型标签,并在所述动作类型标签下配置相应的形象动作资源;所述车载主机终端包括设备层和应用层,所述应用层为车载主机内所搭载的智能网联汽车助手app,用于形象动作执行、形象动作渲染和语音问答呈现;所述设备层用于智能网联汽车助手形象动作展示;所述云端包括nlu模块、dm模块、nlg模块、云端动作执行引擎;所述应用层与云端通信连接,所述设备层与云端通过tsp实现通信连接。
6.进一步完善上述技术方案,所述设备层包括麦克风,所述麦克风将语音转换为文本,并通过tsp将文本上传至云端的nlu模块;所述应用层还包括tts模块,用于朗读所述nlg模块生成的系统语言。
7.进一步地,所述nlu模块用于对文本进行预处理及词法分析、句法分析、语义分析和情感倾向分析,并映射用户对话行为,获得对话内容的情感类型标签和问题类型标签从而初步确定形象动作标签的类型;所述dm模块用于维护和更新对话的状态,对用户所提出的问题进行分类,并基于当前的对话状态选择接下来合适的动作;所述nlg模块用于生成系
统语言;所述云端动作执行引擎根据dm模块的处理结果,在nlu模块所给定的形象动作标签类型中指定相应的形象动作作为反馈结果,以实现将动作与语音问答回复相匹配。
8.进一步地,所述tts模块进行朗读系统语言与所述设备层进行智能网联汽车助手形象动作展示为同步进行。
9.进一步地,所述tts模块的输出结果为言语波形,并通过设备层的扬声器进行播放,以实现朗读nlg模块生成的系统语言。
10.进一步地,在nlu模块中,所述情感类型标签包括:积极、中性和消极;所述问题类型标签包括:车控类、应用控制类;在dm模块中对用户所提出的问题进行分类,类型包括:闲聊型、问答型和多轮对话型。
11.本发明还涉及智能网联汽车助手对话和形象管理方法,采用上述的智能网联汽车助手对话和形象管理系统,具体包括以下步骤:s1:asr-nlp-tts的车载主机终端用户认证信息管理,采用token认证,验证token成功后返回资源数据到车载主机终端;s2:asr过程,车载主机终端的麦克风将接收到的语音转换成文本,并将文本通过tsp发送给云端;s3:nlu过程,云端的nlu模块对文本进行处理,初步确定智能网联汽车助手形象动作标签的类型;s4:对话管理过程,云端的dm模块维护和更新对话的状态,包含所有可能会影响到接下来决策的信息,并对问题进行分类,然后基于当前的对话状态,选择接下来合适的动作;s5:tts过程,tts模块收到nlg模块下发的系统语言文本后,对文本进行语言学分析,将语言学描述转化成言语波形并通过设备层的扬声器进行播放;s6:形象动作执行,云端动作执行引擎实现将动作与语音问答回复相匹配后,下发对应的动作指令给车载主机终端的动作渲染sdk,动作渲染sdk根据所收到的动作指令查找云端对应的可执行文件路径,获取云端对应的形象动作资源并在渲染引擎中执行;s7:形象动作渲染,在智能网联汽车助手app中初始化渲染引擎并最终完成动作执行。
12.进一步完善上述技术方案,所述步骤s1中,用户通过用户名和密码发送请求,在完成服务器中的程序验证后返回一个签名的token给车载主机终端储存,所述签名的token每次用于发送请求。
13.进一步地,所述步骤s3中,nlu模块对文本进行预处理、词法分析、句法分析、语义分析和情感倾向分析,在情感倾向分析中采用支持向量机,解决小样本、非线性及高维识别。
14.进一步地,所述步骤s7中,在车载主机终端的智能网联汽车助手app中初始化渲染引擎,在需要显示的形象动作的xml布局文件里添加视图并设置好大小,初始化视图,调用渲染sdk接口加载资源展示形象动作并确定要显示的模式,调用渲染sdk接口绑定生命周期,加载资源文件,资源加载成功后执行动作,执行动作完成后调用渲染sdk接口释放资源完成视图销毁。
15.相比现有技术,本发明具有如下有益效果:
1、本发明的智能网联汽车助手对话和形象管理系统,提供了一种将nlu、dm和动作执行引擎相结合的技术,解决了智能网联汽车助手语音回复内容与形象动作联动的问题,让形象动作兼具情感性与专业性,提供给车载主机终端良好的动画反馈,满足用户对情感化、形象化3d形象车载语音助手的需求。
16.2、本发明的智能网联汽车助手对话和形象管理方法,在nlu过程增加情感分析与问题类型分析,分析结果与dm模块处理结果融合。当dm模块处理结果为闲聊情感化回复时,云端动作执行引擎将执行相应情感类型的拟人化形象动作,结合输出的情感化tts语音,以达到声情并茂的效果;当dm模块处理结果为问答型回复时,云端动作执行引擎执行问题类型对应的拟人化形象动作,结合汽车专业问答知识的回复,能够更加形象地阐释相应的汽车专业知识。
附图说明
17.图1为实施例的智能网联汽车助手对话和形象管理系统的结构框图;图2为实施例的智能网联汽车助手对话和形象管理方法的逻辑框图;图3为实施例的智能网联汽车助手对话和形象管理系统中车载主机终端实现智能网联汽车助手形象动作的执行流程图;图4为图3中“调用接口执行动作”渲染流程图。
具体实施方式
18.下面结合附图对本发明的具体实施方式作进一步的详细说明。
19.请参见图1,具体实施例的智能网联汽车助手对话和形象管理系统,包括车载主机终端和云端,车载主机终端接收来自云端的动作指令从而完成智能网联汽车助手形象动作执行,所述云端用于为所述智能网联汽车助手形象动作配置情感类型标签、问题类型标签以及相应的动作类型标签,并在所述动作类型标签下配置相应的形象动作资源;所述车载主机终端包括设备层和应用层,所述应用层为车载主机内所搭载的智能网联汽车助手app,用于形象动作执行、形象动作渲染和语音问答呈现;所述设备层用于智能网联汽车助手形象动作展示;所述云端包括nlu(natural language understanding,自然语言理解)模块、dm(dialog management,对话管理)模块、nlg(natural language generation,自然语言生成)模块、云端动作执行引擎;所述应用层与云端通信连接,所述设备层与云端通过tsp(telematics service provider,汽车远程服务提供商)实现通信连接。
20.实施例的智能网联汽车助手对话和形象管理系统提供了一种将nlu、dm和动作执行引擎相结合的技术,解决了智能网联汽车助手语音回复内容与形象动作联动的问题,让形象动作兼具情感性与专业性,提供给车载主机终端良好的动画反馈,满足用户对情感化、形象化3d形象车载语音助手的需求。
21.请继续参见图1和图2,所述设备层包括麦克风,所述麦克风将语音转换为文本,并通过tsp将文本上传至云端的nlu模块;所述应用层还包括tts(text to speech,从文本到语音)模块,用于朗读所述nlg模块生成的系统语言。
22.所述nlu模块用于对文本进行预处理及词法分析、句法分析、语义分析和情感倾向分析,并映射用户对话行为,获得对话内容的情感类型标签和问题类型标签从而初步确定形象动作标签的类型;所述dm模块用于维护和更新对话的状态,对用户所提出的问题进行分类,并基于当前的对话状态选择接下来合适的动作;所述nlg模块用于生成系统语言;所述云端动作执行引擎根据dm模块的处理结果,在nlu模块所给定的形象动作标签类型中指定相应的形象动作作为反馈结果,以实现将动作与语音问答回复相匹配。
23.实施时nlu模块映射用户对话行为后,如果该行为需要系统和用户交互,那么dm模块选择执行该行为,nlg模块被触发,从而生成系统语言。
24.其中,所述tts模块进行朗读系统语言与所述设备层进行智能网联汽车助手形象动作展示为同步进行。
25.其中,所述tts模块的输出结果为言语波形,并通过设备层的扬声器进行播放,以实现朗读nlg模块生成的系统语言。
26.其中,在nlu模块中,所述情感类型标签包括:积极、中性和消极;所述问题类型标签包括:车控类、应用控制类;在dm模块中对用户所提出的问题进行分类,类型包括:闲聊型、问答型和多轮对话型。
27.本发明还提供智能网联汽车助手对话和形象管理方法,采用上述的智能网联汽车助手对话和形象管理系统,具体包括以下步骤:s1:asr-nlp-tts的车载主机终端用户认证信息管理,采用token认证,验证token成功后返回资源数据到车载主机终端;s2:asr(automatic speech recognition,自动语音识别技术)过程,车载主机终端的麦克风将接收到的语音转换成文本,并将文本通过tsp发送给云端;s3:nlu过程,云端的nlu模块对文本进行处理,初步确定智能网联汽车助手形象动作标签的类型;s4:对话管理过程,云端的dm模块维护和更新对话的状态,包含所有可能会影响到接下来决策的信息,并对问题进行分类,然后基于当前的对话状态,选择接下来合适的动作;s5:tts过程,tts模块收到nlg模块下发的系统语言文本后,对文本进行语言学分析,将语言学描述转化成言语波形并通过设备层的扬声器进行播放;s6:形象动作执行,云端动作执行引擎实现将动作与语音问答回复相匹配后,下发对应的动作指令给车载主机终端的动作渲染sdk(software development kit,软件开发工具包),动作渲染sdk根据所收到的动作指令查找云端对应的可执行文件路径,获取云端对应的形象动作资源并在渲染引擎中执行;s7:形象动作渲染,在智能网联汽车助手app中初始化渲染引擎并最终完成动作执行。
28.本发明所提供的智能网联汽车助手对话和形象管理方法,在nlu过程增加情感分析与问题类型分析,分析结果与dm模块处理结果融合。当dm模块处理结果为闲聊情感化回复时,云端动作执行引擎将执行相应情感类型的拟人化形象动作,结合输出的情感化tts语音,以达到声情并茂的效果;当dm模块处理结果为问答型回复时,云端动作执行引擎执行问题类型对应的拟人化形象动作,结合汽车专业问答知识的回复,能够更加形象地阐释相应
的汽车专业知识。
29.实施时,nlp(natural language processing,自然语言处理)过程包括nlu过程和nlg过程。
30.在asr过程中,车载主机终端的麦克风对语音进行信号处理,按帧(毫秒级)拆分,并对拆分出的小段波形按照人耳特征变成多维向量信息,将这些帧信息识别成状态,再将状态组合形成音素,最后将音素组成字词并串连成句,从而实现将语音转换成文字。
31.在tts过程中,对输入的系统语言文本进行语言学分析,逐句进行词汇的、语法的和语义的分析,以确定句子的低层结构和每个字的音素的组成,把处理好的文本所对应的单字或短语从语音合成库中提取,把语言学描述转化成言语波形,通过车载主机终端的扬声器(音响)播放。
32.且步骤s5中的tts模块进行最终的播放应与步骤s7中的智能网联汽车助手app进行形象动作执行为同步进行,从而达到声情并茂的效果。
33.其中,所述步骤s1中,用户通过用户名和密码发送请求,在完成服务器中的程序验证后返回一个签名的token给车载主机终端储存,所述签名的token每次用于发送请求。
34.其中,所述步骤s3中,nlu模块对文本进行预处理、词法分析、句法分析、语义分析和情感倾向分析,在情感倾向分析中采用支持向量机,首先通过asr过程后得到的文本,nlu模块按照非线性变换将输入空间映射到一个高维特征空间,然后根据核函数在这个新空间中求取最优线性分类平面,解决小样本、非线性及高维识别。此技术为现有技术,故不作详细说明。
35.其中,所述步骤s7中,在车载主机终端的智能网联汽车助手app中初始化渲染引擎,在需要显示的形象动作的xml布局文件里添加视图并设置好大小,初始化视图,调用渲染sdk接口加载资源展示形象动作并确定要显示的模式,所述模式可以是仅显示头部,也可以是显示半身或者全身;然后调用渲染sdk接口绑定生命周期,加载资源文件,资源加载成功后执行动作,执行动作完成后调用渲染sdk接口释放资源完成视图销毁。
36.最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。