连接单芯片系统与存储器芯片的加速器芯片
1.相关申请案
2.本技术案要求2019年9月17日提交且名称为“连接单芯片系统与存储器芯片的加速器芯片(accelerator chip connecting a system on a chip and a memory chip)”的美国专利申请案第16/573,795号的优先权,所述申请案的全部公开内容在此以引用的方式并入本文中。
技术领域
3.本文所公开的至少一些实施例涉及一种连接单芯片系统(soc)与存储器芯片的加速器芯片,例如人工智能(ai)加速器芯片。本文所公开的至少一些实施例涉及一种具有向量处理器的加速器芯片(例如,ai加速器芯片)。本文所公开的至少一些实施例涉及使用存储器阶层和存储器芯片串来形成存储器。
背景技术:
4.ai加速器为被配置成使ai应用的计算加速的一类微处理器或计算机系统,所述ai应用包括例如人工神经网络、机器视觉和机器学习的ai应用。ai加速器可为硬连线的以改进数据密集型或传感器驱动型任务的数据处理。ai加速器可包括一或多个核心,且针对低精度算术和存储器内计算可为有线的。ai加速器可存在于多种装置中,例如智能电话、平板计算机和任何类型的计算机(尤其具有传感器和数据密集型任务(例如图形和光学处理)的计算机)。而且,ai加速器可包括向量处理器或阵列处理器以改进数值模拟和ai应用中使用的其它类型的任务的执行。
5.soc为将计算机组件集成在单个芯片中的集成电路(ic)。soc中常见的计算机组件包括中央处理单元(cpu)、存储器、输入/输出端口和辅助存储装置。soc的所有组件可位于单个衬底或微芯片上,且一些芯片可小于25美分硬币。soc可包括各种信号处理功能,且可包括特殊处理器或共处理器,例如图形处理单元(gpu)。通过紧密集成,soc与具有等效功能性的常规多芯片系统相比消耗的功率可少得多。此情形使得soc有益于移动计算装置的集成(例如在智能电话和平板计算机中)。而且,soc可适用于嵌入式系统和物联网中(尤其当智能装置较小时)。
6.存储器(例如主存储器)为存储在计算机或计算装置中立即使用的信息的计算机硬件。存储器通常以比计算机存储装置更高的速度操作。计算机存储装置提供用于存取信息的较慢速度,但也可提供较高容量和更佳数据可靠性。随机存取存储器(ram)为可具有高操作速度的一类存储器。
7.通常,存储器由可定址的半导体存储器单元或胞元构成。存储器ic和其存储器单元可至少部分地由基于硅的金属氧化物半导体场效晶体管(mosfet)实施。
8.存在两种主要类型的存储器,易失性和非易失性存储器。非易失性存储器可包括快闪存储器(其还可用作存储装置)以及rom、prom、eprom和eeprom(其可用于存储固件)。另一类型的非易失性存储器为非易失性随机存取存储器(nvram)。易失性存储器可包括主存
储器技术,例如动态随机存取存储器(dram),和通常使用静态随机存取存储器(sram)实施的高速缓存存储器。
9.计算系统的存储器可为阶层式的。在计算机架构中常常被称作存储器阶层,存储器阶层可基于例如响应时间、复杂度、容量、持久性和存储器带宽的某些因素将计算机存储器分成阶层。这些因素可相关且可常常为进一步强调存储器阶层的有用性的取舍。
10.一般来说,存储器阶层影响计算机系统中的性能。使存储器带宽和速度优先于其它因素可能需要考虑存储器阶层的限制,例如响应时间、复杂度、容量和持久性。为了管理此优先化,可并入不同类型的存储器芯片以平衡更快的芯片与更可靠或具有成本效益的芯片等。各种芯片中的每一者可被视为存储器阶层的部分。并且,例如为了减少较快芯片上的延时,存储器芯片组合中的其它芯片可通过填充缓冲器且随后发信以启动芯片之间的数据传送来作出响应。
11.存储器阶层可由具有不同类型的存储器单元或胞元的芯片构成。举例来说,存储器单元可为dram单元。dram为将数据的每一位存储在一存储器胞元中的一类随机存取半导体存储器,所述存储器胞元通常包括电容器和mosfet。所述电容器可被充电或放电,其表示位的两个值,例如“0”和“1”。在dram中,电容器上的电荷会泄漏,因此dram需要外部存储器刷新电路,所述外部存储器刷新电路通过恢复每电容器的原始电荷来周期性地重写电容器中的数据。dram被视为易失性存储器,这是因为其在电力被去除时快速地失去其数据。此不同于快闪存储器和其它类型的非易失性存储器,例如nvram,其中数据存储更持久。
12.一种类型的nvram为3d xpoint存储器。在3d xpoint存储器的情况下,存储器单元结合可堆叠交叉栅格数据存取阵列而基于体电阻的改变来存储位。3d xpoint存储器可比dram更具成本效益,但比快闪存储器的成本效益更低。而且,3d xpoint为非易失性存储器和随机存取存储器。
13.快闪存储器为另一类型的非易失性存储器。快闪存储器的优点为其可被电抹除和重新编程。快闪存储器被视为具有两个主要类型:nand型快闪存储器和nor型快闪存储器,所述存储器以可实施快闪存储器的存储器单元的nand和nor逻辑门命名。快闪存储器单元或胞元展现类似于对应门的特性的内部特性。nand型快闪存储器包括nand门。nor型快闪存储器包括nor门。nand型快闪存储器可在可小于整个装置的块中写入和读取。nor型快闪存储器准许将单个位组写入到被抹除位置或独立地读取。因为nand型快闪存储器的优点,此类存储器常常用于存储卡、usb快闪驱动器和固态驱动机。然而,一般来说,使用快闪存储器的主要取舍为相较于例如dram和nvram的其它类型的存储器,其仅能够在特定块中进行相对较小数目个写入循环。
附图说明
14.本发明将从下方给出的具体实施方式和本发明的各种实施例的随附图式而得到更充分地理解。
15.图1说明根据本发明的一些实施例的实例系统,其包括连接soc与存储器芯片的加速器芯片(例如,ai加速器芯片)。
16.图2到3说明包括图1中所描绘的加速器芯片以及分离的存储器的实例系统。
17.图4说明包括连接soc与加速器芯片(例如,ai加速器芯片)的存储器芯片的实例相
关系统。
18.图5到7说明包括图4中所描绘的存储器芯片以及分离的存储器的实例系统。
19.图8说明根据本发明的一些实施例的实例计算装置的实例部分布置。
20.图9说明根据本发明的一些实施例的实例计算装置的另一实例部分布置。
21.图10和11说明可用于图2到3和5到7中所描绘的分离的存储器中的实例存储器芯片串。
具体实施方式
22.本文所公开的至少一些实施例涉及连接soc与存储器芯片(例如,dram)的加速器芯片(例如,ai加速器芯片)。换句话说,本文所公开的至少一些实施例涉及经由加速器芯片(例如,ai加速器芯片)将存储器芯片连接到soc。加速器芯片可与soc直接通信。加速器芯片获得来自soc的请求且使用存储器芯片来存储中间结果。此类实施例的实例参见图1到3中所描绘的加速器芯片102、第一存储器芯片104和soc 106。此外,参见图8到9中所展示的soc 806和专用组件807,所述专用组件可包括加速器芯片102、第一存储器芯片104和soc 106。在装置800和900的一些实施例中,专用组件807可包括第一存储器芯片104和加速器芯片102。
23.连接存储器芯片与soc的加速器芯片可具有两个分离的引脚集合;一个集合用于经由布线直接连接到存储器芯片(例如,参见图1到3中所展示的引脚集合114和布线124),且另一集合用于经由布线直接连接到soc(例如,参见图1到2中所展示的引脚集合116和布线126)。加速器芯片位于soc与存储器芯片之间通常可为soc,或更确切地说在一些实施例中为包括于soc中的图形处理单元(gpu)(例如,参见图1到3中所展示的gpu108)提供专用计算(例如ai计算)的加速。在一些实施例中,可经由加速器芯片连接soc中的gpu与存储器芯片。在一些实施例中,存储器芯片可包括一引脚集合,且可经由所述引脚集合和布线(例如,参见引脚集合115和布线124)直接连接到加速器芯片。此外,soc可包括一引脚集合,且可经由所述引脚集合和布线直接连接到加速器芯片。在一些实施例中,soc中的gpu可包括一引脚集合,且可经由所述引脚集合和布线(例如,参见引脚集合117和布线126)直接连接到加速器芯片。
24.在一些实施例(未描绘)中,连接存储器芯片与soc的加速器芯片可为soc的部分,且可任选地为soc中的gpu或soc中除gpu以外的专用装置(例如ai加速器装置)。当soc包括专用装置时,所述专用装置可包括被配置成特定用于专用计算的专用集成电路(asic)或现场可编程门阵列(fpga),其中所述专用装置被特定硬连线以用于专用计算(例如ai计算)的加速。
25.出于本发明的目的,应理解,本文所描述的加速器芯片中的任一者可为或包括或为专用加速器芯片的部分。专用加速器芯片的实例可包括人工智能(ai)加速器芯片、虚拟现实加速器芯片、增强现实加速器芯片、图形加速器芯片、机器学习加速器芯片或可提供低延时或高带宽存储器存取的任何其它类型的asic或fpga。举例来说,本文所描述的加速器芯片中的任一者可为或包括或为ai加速器芯片的部分。
26.加速器芯片可为自身被设计成用于ai应用的硬件加速的微处理器芯片或soc,所述ai应用包括人工神经网络、机器视觉和机器学习。在一些实施例中,加速器芯片被配置成
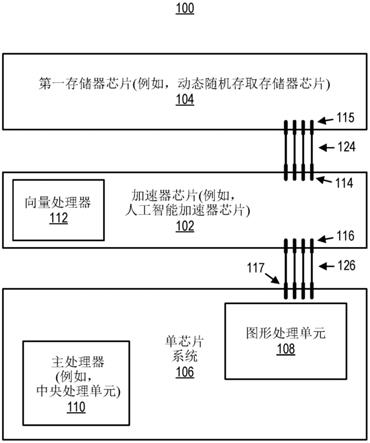
执行向量和矩阵的数值运算(例如,参见图1中所展示的向量处理器112,其可被配置成执行向量和矩阵的数值运算)。加速器芯片可为或包括asic或fpga。在加速器芯片的asic实施例的情况下,加速器芯片可被特定硬连线以用于专用计算(例如ai计算)的加速。在一些其它实施例中,加速器芯片可为超越未经修改fpga或gpu的被修改以用于专用计算的加速的经修改fpga或gpu。在一些其它实施例中,加速器芯片可为未经修改fpga或gpu。
27.为清楚起见,当描述整个系统的多个存储器芯片时,直接连接到加速器芯片的存储器芯片(例如,参见第一存储器芯片104)在本文中也被称为专用存储器芯片。专用存储器芯片不一定被特定硬连线以用于专用计算(例如,ai计算)。专用存储器芯片中的每一者可为dram芯片或nvram芯片。并且,专用存储器芯片中的每一者可直接连接到加速器芯片,且可具有在专用存储器芯片通过soc或加速器芯片配置之后通过加速器特定用于专用计算的加速的存储器单元。
28.在一些实施例中,soc可包括主处理器(例如,cpu)。举例来说,参见图1到3中所展示的主处理器110。在这些实施例中,soc中的gpu可运行用于专用任务和计算(例如,ai任务和计算)的指令,且主处理器可运行用于非专用任务和计算(例如,非ai任务和计算)的指令。并且,在这些实施例中,加速器可提供特定用于gpu的专用任务和计算的加速。soc还可包括其自身的用于将soc的组件彼此连接(例如连接主处理器与gpu)的总线。而且,soc的总线可被配置成将soc连接到soc外部的总线,使得soc的组件可与soc外部的芯片和装置(例如分离的存储器芯片)耦合。
29.gpu的非专用计算和任务(例如,非ai计算和任务)或不使用加速器芯片的此类计算和任务(其可为并非由主处理器执行的常规任务)可使用分离的存储器,例如分离的存储器芯片(其可为专用存储器)。并且,所述存储器可由dram、nvram、快闪存储器或其任何组合实施。举例来说,分离的存储器或存储器芯片可经由soc外部的总线连接到soc和主处理器(例如,参见图2中描绘的存储器204和总线202)。在这些实施例中,分离的存储器或存储器芯片可具有特定用于主处理器的存储器单元。而且,分离的存储器或存储器芯片可经由soc外部的总线连接到soc和gpu(例如,参见图2到3中所描绘的第二存储器芯片204和总线202)。在这些实施例中,分离的存储器或存储器芯片可具有用于主处理器或gpu的存储器单元。
30.应理解,出于本发明的目的,专用存储器芯片和分离的存储器芯片可各自由存储器芯片组,例如存储器芯片串(例如,参见图10和11中所展示的存储器芯片串)替代。举例来说,分离的存储器芯片可由至少包括nvram芯片和所述nvram芯片下游的快闪存储器芯片的存储器芯片串替代。而且,分离的存储器芯片可由至少两个存储器芯片替代,其中芯片中的一个用于主处理器(例如,cpu),且另一芯片用于gpu以用作用于非ai计算和/或任务的存储器。
31.另外,本文所公开的至少一些实施例涉及具有向量处理器(例如,参见图1到3中所展示的向量处理器112)的加速器芯片(例如,ai加速器芯片)。并且,本文所公开的至少一些实施例涉及使用存储器阶层和存储器芯片串来形成存储器(例如,参见图10和11)。
32.出于本发明的目的,应理解,本文所描述的加速器芯片中的任一者可为或包括或为专用加速器芯片的部分。专用加速器芯片的实例可包括ai加速器芯片、虚拟现实加速器芯片、增强现实加速器芯片、图形加速器芯片、机器学习加速器芯片或可提供低延时或高带
宽存储器存取的任何其它类型的asic或fpga。
33.图1说明根据本发明的一些实施例的实例系统100,其包括连接第一存储器芯片104与soc 106的加速器芯片102(例如,ai加速器芯片)。如所展示,soc 106包括gpu 108以及主处理器110。主处理器110可为或包括cpu。并且,加速器芯片102包括向量处理器112。
34.在系统100中,加速器芯片102包括第一引脚集合114和第二引脚集合116。第一引脚集合114被配置成经由布线124连接到第一存储器芯片104。第二引脚集合116被配置成经由布线126连接到soc 106。如所展示,第一存储器芯片104包括经由布线124将存储器芯片连接到加速器芯片102的对应引脚集合115。soc 106的gpu 108包括经由布线126将soc连接到加速器芯片102的对应引脚集合117。
35.加速器芯片102被配置成执行并加速用于soc 106的专用计算(例如,ai计算)。加速器芯片102还被配置成使用第一存储器芯片104作为用于专用计算的存储器。专用计算的加速可由向量处理器112执行。加速器芯片102中的向量处理器112可被配置成执行用于soc 106的向量和矩阵的数值运算。加速器芯片102可包括asic,所述asic包括向量处理器112且被特定硬连线以经由向量处理器112使专用计算(例如,ai计算)加速。替代地,加速器芯片102可包括fpga,所述fpga包括向量处理器112且被特定硬连线以经由向量处理器112使专用计算加速。在一些实施例中,加速器芯片102可包括gpu,所述gpu包括向量处理器112且被特定硬连线以经由向量处理器112使专用计算加速。在这些实施例中,gpu可被特定修改以经由向量处理器112使专用计算加速。
36.如所展示,soc 106包括gpu 108。并且,加速器芯片102可被配置成执行并加速用于gpu 108的专用计算(例如,ai计算)。举例来说,向量处理器112可被配置成执行用于gpu 108的向量和矩阵的数值运算。而且,gpu 108可被配置成执行专用任务和计算(例如,ai任务和计算)。
37.而且,如所展示,soc 106包括被配置成执行非ai任务和计算的主处理器110。
38.在一些实施例中,存储器芯片104为dram芯片。在这些实例中,第一引脚集合114可被配置成经由布线124连接到dram芯片。而且,加速器芯片102可被配置成使用dram芯片中的dram胞元作为用于专用计算(例如,ai计算)的存储器。在一些其它实施例中,存储器芯片104为nvram芯片。在这些实施例中,第一引脚集合114可被配置成经由布线124连接到nvram芯片。而且,加速器芯片102可被配置成使用nvram芯片中的nvram胞元作为用于专用计算的存储器。此外,nvram芯片可为或包括3d xpoint存储器芯片。在这些实例中,第一引脚集合114可被配置成经由布线124连接到3d xpoint存储器芯片,且加速器芯片102可被配置成使用3d xpoint存储器芯片中的3d xpoint存储器胞元作为用于专用计算的存储器。
39.在一些实施例中,系统100包括加速器芯片102,所述加速器芯片102经由布线连接到第一存储器芯片104,且第一存储器芯片104可为专用存储器芯片。系统100还包括soc 106,所述soc 106包括gpu 108(其可被配置成执行ai任务)和主处理器110(其可被配置成执行非ai任务且将ai任务委派到gpu 108)。在这些实施例中,gpu 108包括被配置成经由布线126连接到加速器芯片102的引脚集合117,且加速器芯片102被配置成执行并加速用于gpu 108的ai任务的ai计算。
40.在这些实施例中,加速器芯片102可包括向量处理器112,所述向量处理器112被配置成执行用于gpu 108的向量和矩阵的数值运算。并且,加速器芯片102包括asic,所述asic
包括向量处理器112且被特定硬连线以经由向量处理器112使ai计算加速。或者,加速器芯片102包括fpga,所述fpga包括向量处理器112且被特定硬连线以经由向量处理器112使ai计算加速。或者,加速器芯片102包括gpu,所述gpu包括向量处理器112且被特定硬连线以经由向量处理器112使ai计算加速。
41.系统100还包括存储器芯片104,并且加速器芯片102可经由布线124连接到存储器芯片104且被配置成执行并加速ai任务的ai计算。存储器芯片104可为或包括具有dram胞元的dram芯片,且dram胞元可由加速器芯片102配置以存储用于使ai计算加速的数据。或者,存储器芯片104可为或包括具有nvram胞元的nvram芯片,且nvram胞元可由加速器芯片102配置以存储用于使ai计算加速的数据。nvram芯片可包括3d xpoint存储器胞元,且所述3d xpoint存储器胞元可由加速器芯片102配置以存储用于使ai计算加速的数据。
42.图2到3分别说明实例系统200和300,每一系统包括图1中描绘的加速器芯片102以及分离的存储器(例如,nvram)。
43.图2中,总线202连接系统100(包括加速器芯片102)与存储器204。在一些实施例中可为nvram的存储器204为与系统100的第一存储器芯片104的存储器分离的存储器。并且,在一些实施例中,存储器204可为主存储器。
44.在系统200中,系统100的soc 106经由总线202与存储器204连接。并且,作为系统200的部分的系统100包括加速器芯片102、第一存储器芯片104和soc 106。系统100的这些部分经由总线202连接到存储器204。而且,图2中所展示,包括于soc106中的存储器控制器206控制系统100的soc 106对存储器204的数据存取。举例来说,存储器控制器206控制gpu 108和/或主处理器110对存储器204的数据存取。在一些实施例中,存储器控制器206可控制对系统200中的所有存储器的数据存取(例如,对第一存储器芯片104和存储器204的数据存取)。并且,存储器控制器206可通信耦合到第一存储器芯片104和/或存储器204。
45.存储器204为与系统100的第一存储器芯片104所提供的存储器分离的存储器,且其可经由存储器控制器206和总线202而用作用于soc 106的gpu 108和主处理器110的存储器。而且,存储器204可用作用于gpu 108和主处理器110的不由加速器芯片102执行的非专用任务或专用任务(例如非ai任务或ai任务)的存储器。此类任务的数据可经由存储器控制器206和总线202从存储器204存取和传达到存储器204。
46.在一些实施例中,存储器204为装置的主存储器,所述装置例如托管系统200的装置。举例来说,在系统200的情况下,存储器204可为图8中所展示的主存储器808。
47.在图3中,总线202连接系统100(包括加速器芯片102)与存储器204。而且,在系统300中,总线202将加速器芯片102连接到soc 106以及将加速器芯片102连接到存储器204。还展示,在系统300中,总线202代替了加速器芯片的第二引脚集合116以及soc 106和gpu 108的布线126和引脚集合117。类似于系统200,系统300中的加速器芯片102连接系统100的第一存储器芯片104与soc 106;然而,所述连接是经由第一引脚集合114和总线202。
48.而且,类似于系统200,在系统300中,存储器204为与系统100的第一存储器芯片104的存储器分离的存储器。在系统300中,系统100的soc 106经由总线202与存储器204连接。并且,在系统300中,作为系统300的部分的系统100包括加速器芯片102、第一存储器芯片104和soc 106。系统100的这些部分经由系统300中的总线202连接到存储器204。而且,类似地,如图3中所展示,包括于soc 106中的存储器控制器206控制系统100的soc 106对存储
器204的数据存取。在一些实施例中,存储器控制器206可控制对系统300中的所有存储器的数据存取(例如,对第一存储器芯片104和存储器204的数据存取)。并且,存储器控制器可连接到第一存储器芯片104和/或存储器204。并且,存储器控制器206可通信耦合到第一存储器芯片104和/或存储器204。
49.而且,在系统300中,存储器204(其可为nvram为一些实施例)为与系统100的第一存储器芯片104所提供的存储器分离的存储器,且其可经由存储器控制器206和总线202而用作用于soc 106的gpu 108和主处理器110的存储器。此外,在一些实施例和情形中,加速器芯片102可经由总线202使用存储器204。并且,存储器204可用作用于gpu 108和主处理器110的不由加速器芯片102执行的非专用任务或专用任务(例如非ai任务或ai任务)的存储器。此类任务的数据可经由存储器控制器206和/或总线202从存储器204存取和传达到存储器204。
50.在一些实施例中,存储器204为装置的主存储器,所述装置例如托管系统300的装置。举例来说,在系统300的情况下,存储器204可为图9中所展示的主存储器808。
51.图4说明实例系统400,其在一定程度上涉及系统100。系统400包括连接加速器芯片404(例如,ai加速器芯片)与soc 406的第一存储器芯片402。如所展示,soc 406包括gpu 408以及主处理器110。主处理器110可为或包括系统400中的cpu。并且,加速器芯片404包括向量处理器412。
52.在系统400中,存储器芯片402包括第一引脚集合414和第二引脚集合416。第一引脚集合414被配置成经由布线424连接到加速器芯片404。第二引脚集合416被配置成经由布线426连接到soc 406。如所展示,加速器芯片404包括经由布线424将第一存储器芯片402连接到加速器芯片的对应引脚集合415。soc 406的gpu 408包括经由布线426将soc连接到第一存储器芯片402的对应引脚集合417。
53.第一存储器芯片402包括第一多个存储器胞元,所述第一多个存储器胞元被配置成存储且提供经由第二引脚集合416从soc 406接收到的计算输入数据(例如,ai计算输入数据),以由加速器芯片404用作计算输入(例如,ai计算输入)。计算输入数据经由第一引脚集合414从第一多个存储器胞元存取且从第一存储器芯片402传输,以由加速器芯片404接收和使用。第一多个存储器胞元可包括dram胞元和/或nvram胞元。在具有nvram胞元的实例中,nvram胞元可为或包括3d xpoint存储器胞元。
54.第一存储器芯片402还包括第二多个存储器胞元,所述第二多个存储器胞元被配置成存储且提供经由第一引脚集合414从加速器芯片404接收到的计算输出数据(例如,ai计算输出数据),以由soc 406检索或由加速器芯片404重新用作计算输入(例如,ai计算输入)。计算输出数据可经由第一引脚集合414从第二多个存储器胞元存取且从第一存储器芯片402传输,以由加速器芯片404接收和使用。而且,计算输出数据可经由第二引脚集合416从第二多个存储器胞元存取且从soc 406或soc中的gpu 408传输,以由soc或soc中的gpu接收和使用。第二多个存储器胞元可包括dram胞元和/或nvram胞元。在具有nvram胞元的实例中,nvram胞元可为或包括3d xpoint存储器胞元。
55.第一存储器芯片402还包括第三多个存储器胞元,所述第三多个存储器胞元被配置成存储经由引脚集合416从soc 406接收到的与非ai任务有关的非ai数据,以由soc406检索以用于非ai任务。非ai数据可经由第二引脚集合416从第三多个存储器胞元存取且从第
一存储器芯片402传输,以由soc 406、soc中的gpu 408或soc中的主处理器110接收和使用。第三多个存储器胞元可包括dram胞元和/或nvram胞元。在具有nvram胞元的实例中,nvram胞元可为或包括3d xpoint存储器胞元。
56.加速器芯片404被配置成执行并加速用于soc 406的专用计算(例如,ai计算)。加速器芯片404还被配置成使用第一存储器芯片402作为用于专用计算的存储器。专用计算的加速可由向量处理器412执行。加速器芯片404中的向量处理器412可被配置成执行用于soc 406的向量和矩阵的数值运算。举例来说,向量处理器412可被配置成使用第一和第二多个存储器胞元作为存储器来执行用于soc 406的向量和矩阵的数值运算。
57.加速器芯片404可包括asic,所述asic包括向量处理器412且被特定硬连线以经由向量处理器412使专用计算(例如,ai计算)加速。替代地,加速器芯片404可包括fpga,所述fpga包括向量处理器412且被特定硬连线以经由向量处理器412使专用计算加速。在一些实施例中,加速器芯片404可包括gpu,所述gpu包括向量处理器412且被特定硬连线以经由向量处理器412使专用计算加速。在这些实施例中,gpu可被特定修改以经由向量处理器412使专用计算加速。
58.如所展示,soc 406包括gpu 408。并且,加速器芯片402可被配置成执行并加速用于gpu 408的专用计算。举例来说,向量处理器412可被配置成执行用于gpu 408的向量和矩阵的数值运算。而且,gpu 408可被配置成执行专用任务和计算。而且,如所展示,soc 406包括被配置成执行非ai任务和计算的主处理器110。
59.在一些实施例中,系统400包括存储器芯片402、加速器芯片404和soc 406,且存储器芯片402至少包括被配置成经由布线424连接到加速器芯片404的第一引脚集合414和被配置成经由布线426连接到soc 406的第二引脚集合416。并且,存储器芯片402可包括:第一多个存储器胞元,其被配置成存储且提供经由引脚集合416从soc 406接收到的ai计算输入数据,以由加速器芯片404用作ai计算输入;以及第二多个存储器胞元,其被配置成存储且提供经由另一引脚集合414从加速器芯片404接收到的ai计算输出数据,以由soc 406检索或由加速器芯片404重新用作ai计算输入。并且,存储器芯片402可包括用于非ai计算的存储器的第三多个胞元。
60.而且,soc 406包括gpu 408,且加速器芯片404可被配置成使用第一和第二多个存储器胞元作为存储器来执行并加速用于gpu 408的ai计算。并且,加速器芯片404包括向量处理器412,所述向量处理器412可被配置成使用第一和第二多个存储器胞元作为存储器来执行用于soc 406的向量和矩阵的数值运算。
61.而且,在系统400中,存储器芯片402中的第一多个存储器胞元可被配置成存储且提供经由引脚集合416从soc 406接收到的ai计算输入数据,以由加速器芯片404(例如,ai加速器芯片)用作ai计算输入。并且,存储器芯片402中的第二多个存储器胞元可被配置成存储且提供经由另一引脚集合414从加速器芯片404接收到的ai计算输出数据,以由soc 406检索或由加速器芯片404重新用作ai计算输入。并且,存储器芯片402中的第三多个存储器胞元可被配置成存储经由引脚集合416从soc 406接收到的与非ai任务有关的非ai数据,以由soc 406检索以用于非ai任务。
62.存储器芯片402中的第一、第二和第三多个存储器胞元各自可包括dram胞元和/或nvram胞元,且nvram胞元可包括3d xpoint存储器胞元。
63.图5到7分别说明实例系统500、600和700,每一系统包括图4中描绘的存储器芯片402以及分离的存储器。
64.在图5中,总线202连接系统400(包括存储器芯片402和加速器芯片404)与存储器204。存储器204(例如,nvram)为与系统400的第一存储器芯片402的存储器分离的存储器。并且,存储器204可为主存储器。
65.在系统500中,系统400的soc 406经由总线202与存储器204连接。并且,作为系统500的部分的系统400包括第一存储器芯片402、加速器芯片404和soc 406。系统400的这些部分经由总线202连接到存储器204。而且,图5中所展示,包括于soc406中的存储器控制器206控制系统400的soc 406对存储器204的数据存取。举例来说,存储器控制器206控制gpu 408和/或主处理器110对存储器204的数据存取。在一些实施例中,存储器控制器206可控制对系统500中的所有存储器的数据存取(例如,对第一存储器芯片402和存储器204的数据存取)。并且,存储器控制器206可通信耦合到第一存储器芯片402和/或存储器204。
66.存储器204为与系统400的第一存储器芯片402所提供的存储器分离的存储器,且其可经由存储器控制器206和总线202而用作用于soc 406的gpu 408和主处理器110的存储器。而且,存储器204可用作用于gpu 408和主处理器110的不由加速器芯片404执行的非专用任务或专用任务(例如非ai任务或ai任务)的存储器。此类任务的数据可经由存储器控制器206和总线202从存储器204存取和传达到存储器204。
67.在一些实施例中,存储器204为装置的主存储器,所述装置例如托管系统500的装置。举例来说,在系统500的情况下,存储器204可为图8中所展示的主存储器808。
68.在图6中,类似于在图5中,总线202连接系统400(包括存储器芯片402和加速器芯片404)与存储器204。系统600相对于系统500和700来说独特的是,第一存储器芯片402包括分别经由布线614和616将第一存储器芯片402直接连接到加速器芯片404和soc 406两者的单一引脚集合602。如所展示,在系统600中,加速器芯片404包括经由布线614将加速器芯片404直接连接到第一存储器芯片402的单一引脚集合604。此外,在系统600中,soc的gpu包括经由布线606将soc 406直接连接到第一存储器芯片402的引脚集合606。
69.在系统600中,系统400的soc 406经由总线202与存储器204连接。并且,作为系统600的部分的系统400包括第一存储器芯片402、加速器芯片404和soc 406。系统400的这些部分经由总线202连接到存储器204(例如,加速器芯片404和第一存储器芯片402经由soc 406和总线202间接连接到存储器204,且soc 406经由总线202直接连接到存储器204)。而且,图6中所展示,包括于soc 406中的存储器控制器206控制系统400的soc 406对存储器204的数据存取。举例来说,存储器控制器206控制gpu 408和/或主处理器110对存储器204的数据存取。在一些实施例中,存储器控制器206可控制对系统600中的所有存储器的数据存取(例如,对第一存储器芯片402和存储器204的数据存取)。并且,存储器控制器206可通信耦合到第一存储器芯片402和/或存储器204。
70.存储器204为与系统400的第一存储器芯片402所提供的存储器分离的存储器(例如,nvram),且其可经由存储器控制器206和总线202而用作用于soc 406的gpu408和主处理器110的存储器。而且,存储器204可用作用于gpu 408和主处理器110的不由加速器芯片404执行的非专用任务或专用任务(例如非ai任务或ai任务)的存储器。此类任务的数据可经由存储器控制器206和总线202从存储器204存取和传达到存储器204。
71.在一些实施例中,存储器204为装置的主存储器,所述装置例如托管系统600的装置。举例来说,在系统600的情况下,存储器204可为图8中所展示的主存储器808。
72.在图7中,总线202连接系统400(包括存储器芯片402和加速器芯片404)与存储器204。而且,在系统700中,总线202将第一存储器芯片402连接到soc 406以及将第一存储器芯片402连接到存储器204。还展示,在系统700中,总线202代替了第一存储器芯片402的第二引脚集合416以及soc 406和gpu 408的布线426和引脚集合417。类似于系统500和600,系统700中的第一存储器芯片402连接系统400的加速器芯片404与soc 406;然而,所述连接是经由第一引脚集合414和总线202。
73.而且,类似于系统500和600,在系统700中,存储器204为与系统400的第一存储器芯片402的存储器分离的存储器。在系统700中,系统400的soc 406经由总线202与存储器204连接。并且,在系统700中,作为系统700的部分的系统400包括第一存储器芯片402、加速器芯片404和soc 406。系统400的这些部分经由系统700中的总线202连接到存储器204。而且,类似地,如图7中所展示,包括于soc 406中的存储器控制器206控制系统400的soc 406对存储器204的数据存取。在一些实施例中,存储器控制器206可控制对系统700中的所有存储器的数据存取(例如,对第一存储器芯片402和存储器204的数据存取)。并且,存储器控制器206可通信耦合到第一存储器芯片402和/或存储器204。
74.而且,在系统700中,存储器204为与系统400的第一存储器芯片402所提供的存储器分离的存储器(例如,nvram),且其可经由存储器控制器206和总线202而用作用于soc 406的gpu 408和主处理器110的存储器。此外,在一些实施例和情形中,加速器芯片404可经由第一存储器芯片402和总线202来使用存储器204。在这些实例中,第一存储器芯片402可包括用于加速器芯片404和存储器204的高速缓存存储器。并且,存储器204可用作用于gpu 408和主处理器110的不由加速器芯片404执行的非专用任务或专用任务(例如非ai任务或ai任务)的存储器。此类任务的数据可经由存储器控制器206和/或总线202从存储器204存取和传达到存储器204。
75.在一些实施例中,存储器204为装置的主存储器,所述装置例如托管系统700的装置。举例来说,在系统700的情况下,存储器204可为图9中所展示的主存储器808。
76.本文所公开的加速器芯片的实施例(例如,参见图1到3和4到7中分别所展示的加速器芯片102和加速器芯片404)可为微处理器芯片或soc或其类似者。加速器芯片的实施例可被设计成用于ai应用的硬件加速,所述ai应用包括人工神经网络、机器视觉和机器学习。在一些实施例中,加速器芯片(例如,ai加速器芯片)可被配置成执行向量和矩阵的数值运算。在这些实施例中,加速器芯片可包括用以执行向量和矩阵的数值运算的向量处理器(例如,参见图1到3和4到7中分别所展示的向量处理器112和412,其可被配置成执行向量和矩阵的数值运算)。
77.本文所公开的加速器芯片的实施例可为或包括asic或fpga。在加速器芯片的asic实施例的情况下,加速器芯片被特定硬连线以用于专用计算(例如ai计算)的加速。在一些其它实施例中,加速器芯片可为超越未经修改fpga或gpu的被修改以用于专用计算(例如ai计算)的加速的经修改fpga或gpu。在一些其它实施例中,加速器芯片可为未经修改fpga或gpu。
78.本文所描述的asic可包括被定制成用于特定用途或应用,例如用于专用计算(例
如ai计算)的加速的ic。这不同于通常由cpu或另一类型的通用处理器(例如通常用于处理图形的gpu)实施的通用用途。
79.本文所描述的fpga可包括于在制造ic和fpga之后被设计和/或配置的ic中;因此,ic和fpga为现场可编程的。fpga配置可使用硬件描述语言(hdl)来加以指定。类似地,asic配置可使用hdl加以指定。
80.本文所描述的gpu可包括被配置成快速操纵和改变存储器以使帧缓冲器中的图像的产生和更新加速以输出到显示装置的ic。并且,本文所描述的系统可包括连接到gpu的显示装置和连接到显示装置和gpu的帧缓冲器。本文所描述的gpu可为嵌入式系统、移动装置、个人计算机、工作站或游戏控制台或连接到显示装置并使用显示装置的任何装置的部分。
81.本文所描述的微处理器芯片的实施例各自为至少并有中央处理单元的功能性的一或多个集成电路。每一微处理器芯片可为多用途的,且至少包括时钟和寄存器,其通过接受二进制数据作为输入且根据存储于连接到微处理器芯片的存储器中的指令使用寄存器和时钟来处理所述数据而实施芯片。在处理数据之后,微处理器芯片可提供输入和指令的结果作为输出。并且,所述输出可提供到连接到微处理器芯片的存储器。
82.本文所描述的soc的实施例各自为集成计算机或其它电子系统的组件的一或多个集成电路。在一些实施例中,soc为单一ic。在其它实施例中,soc可包括分离且被连接的集成电路。在一些实施例中,soc可包括其自身的cpu、存储器、输入/输出端口、辅助存储装置或其任何组合。这一或多个部分可在本文所描述的soc中的单一衬底或微处理器芯片上。在一些实施例中,soc小于25美分硬币、5美分硬币或10美分硬币。soc的一些实施例可为移动装置(例如智能电话或平板计算机)、嵌入式系统或物联网中的装置的部分。一般来说,soc不同于具有基于母板的架构的系统,所述基于母板的架构基于功能划分组件且经由中央介接电路板连接所述组件。
83.为清楚起见,当描述整个系统的多个存储器芯片时,本文所描述的直接连接到加速器芯片(例如,ai加速器芯片)的存储器芯片的实施例,例如参见图1到3中所展示的第一存储器芯片104或图4到7中展示的第一存储器芯片402,在本文中也被称为专用存储器芯片。本文所描述的专用存储器芯片不一定被特定硬连线以用于专用计算(例如ai计算)。专用存储器芯片中的每一者可为dram芯片或nvram芯片,或与dram芯片或nvram芯片具有类似功能性的存储器装置。并且,专用存储器芯片中的每一者可直接连接到加速器芯片(例如,ai加速器芯片)(例如参见图1到3中所展示的加速器芯片102和图4到7中所展示的加速器芯片404),且可具有在专用存储器芯片通过加速器芯片或分离的soc或处理器(例如,参见图1到3和4到7中分别所展示的soc 106和406)配置之后通过加速器芯片特定用于专用计算(例如ai计算)的加速的存储器单元或胞元。
84.本文所描述的dram芯片可包括将数据的每一位存储在具有电容器和晶体管(例如mosfet)的存储器胞元或单元中的随机存取存储器。本文所描述的dram芯片可采用ic芯片的形式,且包括数十亿个dram存储器单元或胞元。在每一单元或胞元中,电容器可充电或放电。此可提供用于表示位的两个值的两个状态。电容器上的电荷可从电容器缓慢泄漏,因此需要周期性地重写电容器中的数据的外部存储器刷新电路来维持电容器和存储器单元的状态。dram也为易失性存储器且不为非易失性存储器,例如快闪存储器或nvram,因为其在电力被去除时快速地失去其数据。dram芯片的益处为其可用于需要低成本和高容量计算机
存储器的数字电子装置中。dram还有益于用作主存储器或特定用于gpu的存储器。
85.本文所描述的nvram芯片可包括非易失性的随机存取存储器,这是与dram的主要区别特征。本文所描述的实施例中可使用的nvram单元或胞元的实例可包括3dxpoint单元或胞元。在3d xpoint单元或胞元中,位存储是基于与可堆叠交叉栅格数据存取阵列结合的体电阻的改变。
86.本文所描述的soc的实施例可包括主处理器(例如cpu或包括cpu的主处理器)。举例来说,参见图1到3中所描绘的soc 106和图4到7中所描绘的soc 406以及图1到7中所展示的主处理器110。在这些实施例中,soc中的gpu(例如,参见图1到3中所展示的gpu 108和图4到7中所展示的gpu 408)可运行用于专用任务和计算(例如ai任务和计算)的指令,且主处理器可运行用于非专用任务和计算(例如非ai任务和计算)的指令。并且,在这些实施例中,连接到soc的加速器芯片(例如,参见图1到7中所展示的加速器芯片中的任一者)可提供特定用于gpu的专用任务和计算(例如ai任务和计算)的加速。本文所描述的soc的实施例中的每一者可包括其自身的用于将soc的组件彼此连接(例如连接主处理器与gpu)的总线。而且,soc的总线可被配置成将soc连接到soc外部的总线,使得soc的组件可与soc外部的芯片和装置耦合,所述芯片和装置例如分离的存储器或存储器芯片(例如,参见图2到3和5到7中所描绘的存储器204以及图8到9中所描绘的主存储器808)。
87.gpu的非专用计算和任务(例如,非ai计算和任务)或不使用加速器芯片的专用计算和任务(例如,ai计算和任务)(其可为并非由主处理器执行的常规任务)可使用分离的存储器,例如分离的存储器芯片(其可为专用存储器),且所述存储器可由dram、nvram、快闪存储器或其任何组合实施。举例来说,参见图2到3和5到7中所描绘的存储器204以及图8到9中所描绘的主存储器808。分离的存储器或存储器芯片可经由soc外部的总线连接到soc和主处理器(例如,cpu)(例如,参见图2到3和5到7中所描绘的存储器204以及图8到9中所描绘的主存储器808;且参见图2到3和5到7中所描绘的总线202以及图8到9中所描绘的总线804)。在这些实施例中,分离的存储器或存储器芯片可具有特定用于主处理器的存储器单元。而且,分离的存储器或存储器芯片可经由soc外部的总线连接到soc和gpu。在这些实施例中,分离的存储器或存储器芯片可具有用于主处理器或gpu的存储器单元或胞元。
88.应理解,出于本发明的目的,本文所描述的专用存储器或存储器芯片(例如,参见图1到3中所展示的第一存储器芯片104或图4到7中所展示的第一存储器芯片402)和本文所描述的分离的存储器或存储器芯片(例如,参见图2到3和5到7中所描绘的存储器204以及图8到9中所描绘的主存储器808)可各自由存储器芯片组,例如存储器芯片串(例如,参见图10和11中所展示的存储器芯片串)替代。举例来说,分离的存储器或存储器芯片可由至少包括nvram芯片和所述nvram芯片下游的快闪存储器芯片的存储器芯片串替代。而且,分离的存储器芯片可由至少两个存储器芯片替代,其中芯片中的一个用于主处理器(例如,cpu),且另一芯片用于gpu以用作用于非ai计算和/或任务的存储器。
89.本文所描述的存储器芯片的实施例可为主存储器的部分,和/或可为存储在计算机中立即使用或由本文所描述的处理器中的任一者(例如,本文所描述的任一soc或加速器芯片)立即使用的信息的计算机硬件。本文所描述的存储器芯片可以比计算机存储装置更高的速度操作。计算机存储装置提供用于存取信息的较慢速度,但也可提供较高容量和更佳数据可靠性。本文所描述的存储器芯片可包括ram,其为可具有高操作速度的一类存储
806可包括一或多个专用处理装置,例如gpu、asic、fpga、数字信号处理器(dsp)、网络处理器、存储器中处理器(pim)或其类似者。soc 806可包括一或多个处理器,其具有复杂指令集计算(cisc)微处理器、精简指令集计算(risc)微处理器、超长指令字(vliw)微处理器,或实施其它指令集的处理器,或实施指令集的组合的处理器。soc 806的处理器可被配置成执行用于执行本文中所论述的操作和步骤的指令。soc 806可进一步包括例如网络接口810的网络接口装置以经由例如网络802的一或多个通信网络通信。
96.数据存储系统812可包括机器可读存储媒体(也被称为计算机可读媒体),其上存储有体现本文中所描述的方法或功能中的任何一或多者的一或多个指令集或软件。指令在其通过计算机系统执行期间也可完全或至少部分地驻存在主存储器808内和/或soc 806的处理器中的一或多者内,主存储器808和soc 806的一或多个处理器506还构成机器可读存储媒体。
97.虽然存储器、处理器和数据存储部分在实例实施例中展示成各自为单个部分,但每一部分应被视为包括可存储指令且执行其相应操作的单个部分或多个部分。术语“机器可读存储媒体”也应被视为包括能够存储或编码指令集以供机器执行且使机器执行本发明的方法中的任何一或多者的任何媒体。术语“机器可读存储媒体”将相应地被视为包括但不限于固态存储器、光学媒体和磁性媒体。
98.图9说明根据本发明的一些实施例的实例计算装置900的另一实例部分布置。计算装置900的实例部分布置可包括图3中所展示的系统300以及图7中所展示的系统700。在计算装置900中,可为ai组件的专用组件(例如,参见图9中的专用组件807)可包括如图3和7中分别所布置和展示的第一存储器芯片104或402和加速器芯片102或404以及如图3和7中分别所配置和展示的soc 106或406。在计算装置900中,布线将专用组件的组件直接彼此连接(例如,参见图3和7中分别所展示的布线124和424)。然而,在计算装置900中,布线不将专用组件直接连接到soc。替代地,在计算装置900中,一或多个总线将专用组件连接到soc(例如,参见如图9中所配置和展示的总线804以及如图3和7中所配置和展示的总线202)。
99.如图8和图9所展示,装置800和900具有多个类似组件。计算装置900可经由如图9中所展示的计算机网络802通信耦合到其它计算装置。类似地,如图9中所展示,计算装置900至少包括总线804(其可为一或多个总线,例如存储器总线与周边装置总线的组合)、soc 806(其可为或包括soc 106或406)、专用组件807(其可为加速器芯片102和第一存储器芯片104或第一存储器芯片402和加速器芯片404)和主存储器808(其可为或包括存储器204)以及网络接口810和数据存储系统812。类似地,总线804通信耦合soc 806、主存储器808、网络接口810和数据存储系统812。并且,总线804可包括总线202和/或点对点存储器连接,例如布线126、426或616。
100.如所提及,本文所公开的至少一些实施例涉及使用存储器阶层和存储器芯片串来形成存储器。
101.图10和11分别说明实例存储器芯片串1000和1100,其可用于图2到3和5到7中所描绘的分离的存储器(即,存储器204)中。
102.在图10中,存储器芯片串1000包括第一存储器芯片1002和第二存储器芯片1004。第一存储器芯片1002直接连线到第二存储器芯片1004(例如,参见布线1022)且被配置成与第二存储器芯片直接交互。存储器芯片串1000中的每一芯片可包括用于连接到所述串中的
上游芯片和/或下游芯片的一或多个引脚集合(例如,参见引脚集合1012和1014)。在一些实施例中,存储器芯片串1000中的每一芯片可包括密封于ic封装内的单个ic。
103.如图10中所展示,引脚集合1012为第一存储器芯片1002的部分,且经由布线1022和引脚集合1014将第一存储器芯片1002连接到第二存储器芯片1004,所述引脚集合1014为第二存储器芯片1004的部分。布线1022连接两个引脚集合1012和1014。
104.在一些实施例中,第二存储器芯片1004可具有串1000中的芯片的最低存储器带宽。在这些和其它实施例中,第一存储器芯片1002可具有串1000中的芯片的最高存储器带宽。在一些实施例中,第一存储器芯片1002为或包括dram芯片。在一些实施例中,第一存储器芯片1002为或包括nvram芯片。在一些实施例中,第二存储器芯片1004为或包括dram芯片。在一些实施例中,第二存储器芯片1004为或包括nvram芯片。并且,在一些实施例中,第二存储器芯片1004为或包括快闪存储器芯片。
105.在图11中,存储器芯片串1100包括第一存储器芯片1102、第二存储器芯片1104和第三存储器芯片1106。第一存储器芯片1102直接连线到第二存储器芯片1104(例如,参见布线1122)且被配置成与第二存储器芯片直接交互。第二存储器芯片1104直接连线到第三存储器芯片1106(例如,参见布线1124)且被配置成与第三存储器芯片直接交互。以此方式,第一存储器芯片1102和第三存储器芯片1106经由第二存储器芯片1104而间接地彼此交互。
106.存储器芯片串1100中的每一芯片可包括用于连接到所述串中的上游芯片和/或下游芯片的一或多个引脚集合(例如,参见引脚集合1112、1114、1116和1118)。在一些实施例中,存储器芯片串1100中的每一芯片可包括密封于ic封装内的单个ic。
107.如图11中所展示,引脚集合1112为第一存储器芯片1102的部分,且经由布线1122和引脚集合1114将第一存储器芯片1102连接到第二存储器芯片1104,所述引脚集合1114为第二存储器芯片1104的部分。布线1122连接两个引脚集合1112和1114。而且,引脚集合1116为第二存储器芯片1104的部分,且经由布线1124和引脚集合1118将第二存储器芯片1104连接到第三存储器芯片1106,所述引脚集合1118为第三存储器芯片1106的部分。布线1124连接两个引脚集合1116和1118。
108.在一些实施例中,第三存储器芯片1106可具有串1100中的芯片的最低存储器带宽。在这些和其它实施例中,第一存储器芯片1102可具有串1100中的芯片的最高存储器带宽。而且,在这些和其它实施例中,第二存储器芯片1104可具有串1100中的芯片的第二高存储器带宽。在一些实施例中,第一存储器芯片1102为或包括dram芯片。在一些实施例中,第一存储器芯片1102为或包括nvram芯片。在一些实施例中,第二存储器芯片1104为或包括dram芯片。在一些实施例中,第二存储器芯片1104为或包括nvram芯片。在一些实施例中,第二存储器芯片1104为或包括快闪存储器芯片。在一些实施例中,第三存储器芯片1106为或包括nvram芯片。并且,在一些实施例中,第三存储器芯片1106为或包括快闪存储器芯片。
109.在具有一或多个dram芯片的实施例中,dram芯片可包括用于命令和地址解码的逻辑电路以及dram的存储器单元的阵列。而且,本文中所描述的dram芯片可包括用于传入和/或传出数据的高速缓存存储器或缓冲存储器。在一些实施例中,实施高速缓存存储器或缓冲存储器的存储器单元可不同于托管高速缓存存储器或缓冲存储器的芯片上的dram单元。举例来说,在dram芯片上实施高速缓存存储器或缓冲存储器的存储器单元可为sram的存储器单元。
110.在具有一或多个nvram芯片的实施例中,nvram芯片可包括用于命令和地址解码的逻辑电路以及nvram的存储器单元(例如,3d xpoint存储器的单元)的阵列。而且,本文中所描述的nvram芯片可包括用于传入和/或传出数据的高速缓存存储器或缓冲存储器。在一些实施例中,实施高速缓存存储器或缓冲存储器的存储器单元可不同于托管高速缓存存储器或缓冲存储器的芯片上的nvram单元。举例来说,在nvram芯片上实施高速缓存存储器或缓冲存储器的存储器单元可为sram的存储器单元。
111.在一些实施例中,nvram芯片可包括非易失性存储器胞元的交叉点阵列。非易失性存储器的交叉点阵列可结合可堆叠交叉栅格数据存取阵列而基于体电阻的改变来执行位存储。另外,与许多基于快闪存储器的存储器相比,交叉点非易失性存储器可执行原地写入操作,其中可在先前未抹除非易失性存储器胞元的情况下编程所述非易失性存储器胞元。
112.如本文中所提及,nvram芯片可为或包括交叉点存储装置和存储器装置(例如,3dxpoint存储器)。交叉点存储器装置使用无晶体管存储器元件,所述无晶体管存储器元件中的每一者具有堆叠在一起作为列的存储器胞元和选择器。存储器元件列经由两个垂直导线分层连接,其中一个分层在存储器元件列上方且另一分层在存储器元件列下方。可在两个层中的每一者上的一条导线的交叉点处独立地选择每一存储器元件。交叉点存储器装置为较快且非易失性的,并且可用作用于处理和存储的统一存储器池。
113.在具有一或多个快闪存储器芯片的实施例中,快闪存储器芯片可包括用于命令和地址解码的逻辑电路以及快闪存储器的存储器单元(例如,nand型快闪存储器的单元)的阵列。而且,本文中所描述的快闪存储器芯片可包括用于传入和/或传出数据的高速缓存存储器或缓冲存储器。在一些实施例中,实施高速缓存存储器或缓冲存储器的存储器单元可不同于托管高速缓存存储器或缓冲存储器的芯片上的快闪存储器单元。举例来说,在快闪存储器芯片上实施高速缓存存储器或缓冲存储器的存储器单元可为sram的存储器单元。
114.而且,举例来说,存储器芯片串的实施例可包括dram到dram到nvram、或dram到nvram到nvram、或dram到快闪存储器到快闪存储器;然而,dram到nvram到快闪存储器可提供将存储器芯片串灵活设置为多层存储器的更有效解决方案。
115.而且,出于本发明的目的,应理解,dram、nvram、3d xpoint存储器和快闪存储器为用于个别存储器单元的技术,且用于本文所描述的存储器芯片中的任一者的存储器芯片可包括用于命令和地址解码的逻辑电路以及dram、nvram、3d xpoint存储器或快闪存储器的存储器单元的阵列。举例来说,本文中所描述的dram芯片包括用于命令和地址解码的逻辑电路以及dram的存储器单元的阵列。举例来说,本文中所描述的nvram芯片包括用于命令和地址解码的逻辑电路以及nvram的存储器单元的阵列。举例来说,本文中所描述的快闪存储器芯片包括用于命令和地址解码的逻辑电路以及快闪存储器的存储器单元的阵列。
116.而且,用于本文中所描述的存储器芯片中的任一者的存储器芯片可包括用于传入和/或传出数据的高速缓存存储器或缓冲存储器。在一些实施例中,实施高速缓存存储器或缓冲存储器的存储器单元可不同于托管高速缓存存储器或缓冲存储器的芯片上的单元。举例来说,实施高速缓存存储器或缓冲存储器的存储器单元可为sram的存储器单元。
117.在前述说明书中,本发明的实施例已参考其特定实例实施例加以描述。将显而易见的是,可在不脱离如以下权利要求书中所阐述的本发明的实施例的更广泛精神和范围的情况下对其进行各种修改。因此,应在说明性意义上而非限制性意义上看待说明书和图式。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。