多流存储器系统和在多流存储器系统中处理输入流的方法
1.本技术要求于2020年11月20日提交的第63/116,685号美国申请和于2020年12月9日提交的第17/117,008号美国申请的优先权和权益,所述美国申请的公开通过引用全部包含于此。
技术领域
2.本发明的方面涉及存储器装置的领域。
背景技术:
3.固态驱动器/固态盘(ssd)是使用集成电路(ic)组件作为存储器来持久地存储数据的固态存储装置。ssd技术通常利用与传统块输入/输出(i/o)硬盘驱动器(hdd)兼容的电子接口,从而在许多常见应用中提供容易的替换。
4.被称为“多流ssd(multi-stream ssd)”的构思提供具有接口的操作系统和应用,具有接口的操作系统和应用分别存储具有不同属性的数据。这些单独的数据存储被称为“流”。流可用于指示不同的数据写入何时彼此相关联或具有相似的寿命。也就是说,一组单独的数据写入可以是集体流的一部分,并且每个流通过由操作系统或对应的应用分配的流id来标识。因此,具有类似特性或属性的不同的数据可各自被分配唯一的流id,使得与该流id对应的数据可被写入ssd中的相同块。
5.当前,一些ssd允许装置侧处理(诸如,ssd内的数据的压缩或加密)。在ssd中处理数据可提供许多益处(诸如,以可对应用透明的方式减少主机侧处理时间和cpu(中央处理单元)/存储器消耗)。
6.现有技术的ssd以相同的方式处理全部的传入(incoming)数据(诸如,具有不同流id的数据)。例如,无论源或流id如何,全部的传入数据都可被压缩和/或加密。然而,通常,并非全部的数据都需要被压缩或加密。例如,由于元数据开销,对已经压缩的数据进行压缩可能导致大于原始数据大小,并且由数据处理产生的临时数据可能不需要被加密。
7.此外,压缩要求和加密要求可因应用而异。例如,一些应用可受益于高压缩比,而其它应用可受益于高压缩速度。然而,这些效果通常不可被同时实现,因为例如高压缩算法具有慢压缩速度。此外,不同的应用可需要不同的加密强度(诸如,rsa(rivest-shamir-adleman)或aes(高级加密标准))。因此,在ssd处以相同的方式处理全部的传入流可引入低效率和不期望的结果。
8.在本背景技术部分中公开的以上信息仅用于增强发明的背景的理解,因此该信息可包含不形成本领域普通技术人员已知的现有技术的信息。
技术实现要素:
9.本公开的实施例的方面涉及能够基于传入数据的流id进行ssd内数据处理引擎选择的多流存储器系统。在一些实施例中,多流存储器系统通过在数据流无法受益于压缩时绕过压缩引擎和/或通过在数据流无法受益于加密时绕过加密引擎来提高性能并且降低功
耗。
10.根据本发明的实施例,提供了一种多流存储器系统,所述多流存储器系统包括:装置内数据处理器,包括第一数据处理引擎和第二数据处理引擎;控制器处理器;以及处理器存储器,结合到控制器处理器,其中,处理器存储器上存储有指令,所述指令在由控制器处理器执行时使控制器处理器执行:识别输入流的流id,基于流分配表,将第一数据处理引擎识别为与所述流id相关联,以及将第一数据处理引擎应用于输入流,以生成处理后的数据。
11.在一些实施例中,其中,流分配表将包括所述流id的多个流id映射到包括第一数据处理引擎和第二数据处理引擎的多个数据处理引擎。
12.在一些实施例中,第一数据处理引擎被配置为执行与第二数据处理引擎不同的操作。
13.在一些实施例中,第一数据处理引擎执行压缩、加密、去重、搜索和图形处理中的至少一种。
14.在一些实施例中,所述指令还使控制器处理器执行:基于流分配表,将第二数据处理引擎识别为不与所述流id相关联;并且响应于识别第二数据处理引擎,针对处理后的数据绕过第二数据处理引擎。
15.在一些实施例中,所述指令还使控制器处理器执行:基于流分配表,将第二数据处理引擎识别为与所述流id相关联;并且响应于识别第二数据处理引擎,将第二数据处理引擎应用于处理后的数据。
16.在一些实施例中,装置内数据处理器在所述多流存储器系统的固态驱动器(ssd)内部并与所述多流存储器系统的固态驱动器(ssd)集成,所述多流存储器系统的固态驱动器(ssd)包括所述处理器存储器和所述控制器处理器。
17.在一些实施例中,流分配表将包括所述流id的多个流id映射到所述多流存储器系统的一个或多个存储器装置内的多个物理地址。
18.在一些实施例中,所述指令还使控制器处理器执行:基于流分配表,识别与流id相关联的物理地址;以及将处理后的数据存储在所述多流存储器系统的存储器装置内的物理地址处。
19.在一些实施例中,所述指令还使控制器处理器执行:生成与处理后的数据相关联的元数据,所述元数据指示将第一数据处理引擎应用于输入流;以及将所述元数据与处理后的数据一起存储在所述多流存储器系统的存储器装置内的所述物理地址处。
20.在一些实施例中,应用第一数据处理引擎和第二数据处理引擎中的识别的一个的步骤包括:由第一压缩引擎对输入流进行压缩,以生成压缩后的数据,并且其中,所述指令还使控制器处理器执行:监测压缩后的数据的压缩比;确定压缩比低于阈值,并且响应于确定,针对输入流的剩余部分绕过第一数据处理引擎和第二数据处理引擎中的识别的一个。
21.在一些实施例中,所述指令还使控制器处理器执行:向主机提供流分配表,主机是输入流的源。
22.根据本发明的实施例,提供了一种多流存储器系统,所述多流存储器系统包括:装置内数据处理器,包括数据处理引擎;控制器处理器;以及处理器存储器,结合到控制器处理器,其中,处理器存储器上存储有指令,所述指令在由控制器处理器执行时使控制器处理器执行:识别第一输入流的第一流id,识别第二输入流的第二流id,基于流分配表,确定第
一流id与数据处理引擎相关联,将数据处理引擎应用于第一输入流,以及针对第二输入流绕过数据处理引擎。
23.在一些实施例中,所述指令还使控制器处理器执行:基于流分配表,确定第二流id不与数据处理引擎相关联。
24.在一些实施例中,流分配表将包括第一流id和第二流id的多个流id映射到所述多流存储器系统的一个或多个存储器装置内的多个物理地址。
25.在一些实施例中,所述指令还使控制器处理器执行:基于流分配表,识别与第二流id相关联的物理地址;以及将第二输入流存储在所述多流存储器系统的存储器装置内的所述物理地址处。
26.根据本发明的实施例,提供了一种在多流存储器系统中处理输入流的方法,所述方法包括:识别输入流的流id;基于流分配表,将装置内数据处理器的第一数据处理引擎识别为与所述流id相关联,装置内数据处理器包括第二数据处理引擎;以及将第一数据处理引擎应用于输入流,以生成处理后的数据。
27.在一些实施例中,流分配表将包括所述流id的多个流id映射到包括第一数据处理引擎和第二数据处理引擎的多个数据处理引擎。
28.在一些实施例中,所述方法还包括:基于流分配表,将第二数据处理引擎识别为不与所述流id相关联;并且响应于识别第二数据处理引擎,针对处理后的数据绕过第二数据处理引擎。
29.在一些实施例中,所述方法还包括:从主机接收输入流,其中,主机将输入流与所述流id相关联。
附图说明
30.参照说明书、权利要求书和附图,将领会和理解本发明的这些和其它方面,其中:
31.图1是示出根据本公开的一些实施例的具有ssd内数据处理的多流存储器系统的框图。
32.图2是根据本公开的一些实施例的多流存储器系统针对特定流绕过ssd内的装置内数据处理引擎并同时针对其它流执行装置内数据处理的示例。
33.图3是示出根据本公开的一些实施例的利用中间件数据处理的多流存储器系统的框图。
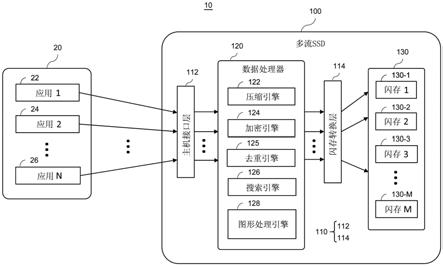
34.图4是示出根据本公开的一些示例实施例的在多流存储器系统中处理输入流的方法的流程图。
具体实施方式
35.通过参照下面的实施例的具体实施方式和附图,可更容易地理解发明构思的特征和实现发明构思的特征的方法。在下文中,将参照附图更详细地描述示例实施例,其中,相同的附图标记始终表示相同的元件。然而,本发明可以以各种不同的形式来实现,并且不应被解释为仅限于在此示出的实施例。相反,这些实施例作为示例被提供,使得本公开将是彻底和完整的,并且将向本领域技术人员充分传达本发明的方面和特征。因此,对于本领域普通技术人员而言为了完全理解本发明的方面和特征不是必需的处理、元件和技术可不被描
述。除非另外说明,否则贯穿附图和书面描述,相同的附图标记表示相同的元件,因此,它们的描述将不被重复。在附图中,为了清楚,可夸大元件、层和区域的相对大小。
36.除非另有定义,否则在此使用的全部术语(包括技术术语和科学术语)具有与本发明所属领域的普通技术人员通常理解的含义相同的含义。还将理解,除非在此明确地如此定义,否则术语(诸如,在通用词典中定义的术语)应被解释为具有与相关领域和/或本说明书中的上下文含义一致的含义,并且应不被解释为理想化或过于形式化的含义。
37.在现有技术的存储栈中,来自不同应用的主机数据在发送到固态驱动器(ssd)之前被混合。如果ssd压缩或加密引擎被启用,则全部的数据在现有技术的ssd内被压缩或加密。如果已知数据集具有低压缩比或者不需要被加密,则压缩/加密引擎可通过管理命令而被关闭。然而,由于在现有技术的ssd中仅存在一个数据流,因此,即使其它应用可受益于ssd处的压缩/加密处理,关闭压缩/加密引擎也会影响来自那些其它应用的数据。
38.因此,本公开的方面提供一种多流(multi-stream)存储器系统(例如,多流闪存驱动器),多流存储器系统包括压缩引擎和/或加密引擎,并且能够针对无法受益于压缩和/或加密的数据流选择性地绕过(bypass)压缩引擎和/或加密引擎。在一些实施例中,多流存储器系统能够基于应用需求选择适当的数据处理引擎(例如,压缩引擎或加密引擎)。在一些实施例中,多流存储器系统基于其流id选择性地对流进行压缩和/或加密,流id可由主机或多流存储器系统分配。根据一些实施例,多流存储器系统的控制器可基于对应的数据流的压缩比和/或压缩速度而自动地确定是否应对数据流进行压缩。
39.图1是示出根据本公开的一些实施例的具有ssd内(in-ssd)数据处理的多流存储器系统的框图。图2是根据本公开的一些实施例的多流存储器系统针对特定流绕过ssd内的装置内数据处理引擎并同时针对其它流执行装置内(in-device)数据处理的示例。图3是示出根据本公开的一些实施例的利用中间件(middleware(例如,mid-ware))数据处理的多流存储器系统的框图。
40.参照图1,在一些实施例中,多流存储器系统10包括与主机20(例如,包括多个应用(即,应用1 22、应用2 24至应用n 26(其中,n是大于1的整数))进行数据通信的具有装置内数据处理的多流ssd(例如,多流闪存驱动器)100。多流ssd 100包括ssd控制器110、装置内数据处理器120和非易失性存储器130,装置内数据处理器120在多流ssd 100内部并与多流ssd 100集成,非易失性存储器130包括多个存储器装置(例如,闪存1 130-1、闪存2 130-2至闪存m 130-m)(其中,m是大于1的整数)。在一些示例中,存储器装置130可以是闪存装置(例如,nand闪存装置)。
41.ssd控制器110通过多个流1至n(其中,n是大于1的整数)促进主机20与ssd 100之间的数据的传送。在一些实施例中,ssd控制器110包括主机接口层112和闪存转换层(ftl)114。主机接口层112从主机20获取应用i/o请求,将i/o请求转换为ssd内部读取/写入事务(transaction),并且将它们调度到ftl 114。闪存转换层(ftl)114充当主机20的基于扇区(sector-based)的文件系统与ssd 100的存储器装置130之间的转换层。主机接口层112和ftl 114可以以软件和/或硬件来实现。ftl 114向主机侧上的操作系统和文件系统提供对存储器装置130的访问,并且确保它们表现(或呈现)为一个块存储装置。在一些示例中,ftl 114通过将主机的逻辑地址映射到逻辑到物理(logical to physical,ltop)表中的闪存的物理地址来向闪存装置130提供逻辑块接口而隐藏闪存的复杂性。
42.数据处理器120充当ssd 100内的嵌入式计算机,并且对传入和传出(outgoing)的数据流执行装置内数据处理(诸如,压缩/解压缩、加密/解密、搜索操作和/或图形处理)。数据处理器120将处理移动到靠近存储数据的位置,因此减少了移动数据的需要,这在时间和能量方面可以是代价高的操作。例如,当运行搜索时,通常,存储装置上的大量数据将必须被移动到主机,并且在主机上被搜索。然而,用装置内数据处理器120,可将查询(inquiry)发送到ssd 100自身,使数据处理器120执行搜索,并且简单地返回结果。如图1中所示,数据处理器120可包括一个或多个压缩引擎122、一个或多个加密引擎124、一个或多个去重(deduplication)引擎125、一个或多个搜索引擎126和/或一个或多个图形处理引擎128。然而,本发明的实施例不限于此,并且任何合适的引擎可被包含在数据处理器120内。在一些示例中,一个或多个压缩引擎122可执行brotli压缩、gzip压缩、libdeflate压缩、lzfse压缩和zstd压缩中的至少一种,并且一个或多个加密引擎124可执行chacha20-ietf加密、aes-256-gcm加密、aes-256-cfb加密、aes-256-ctr加密和camellia-256-cfb加密中的至少一种。
43.根据一些实施例,ssd控制器110基于流的流id选择性地将数据处理应用于它们。在多流ssd中,每个输入/输出流可由唯一流id标识,流id可(例如,由主机)被编码在i/o命令中。ssd控制器110可基于流分配表为给定流id启用或禁用特定数据处理引擎,流分配表将每个流id映射到ssd 100要采取的一个或多个动作。动作可例如包括数据布置(data placement)、压缩、加密、搜索和图形处理。在一些实施例中,流分配表被编码在ssd 100的固件中,并且可用于主机20。因此,在主机20处运行的每个应用可确定适当的流id以用于其预期目的。
44.以下表1示出支持8个流的多流ssd 100中的流分配表的示例。
45.表1:
[0046][0047]
如表1中所示,每个流id可与ssd 100处的特定物理地址相关联。例如,每个流id可与闪存装置130中的不同闪存装置相关联。然而,本公开的实施例不限于此,并且两个或更多个流id可与ssd 100内的单个物理地址或存储器装置130相关联。另外,每个流id可与一个或多个数据处理引擎相关联,或者不与任何数据处理引擎相关联。例如,在表1中,流id 1至流id 3与压缩引擎1至压缩引擎3相关联,流id 7与压缩引擎1和加密引擎2两者相关联,流id 8不与任何装置内处理引擎相关联。
[0048]
在一些实施例中,当数据流到达ssd 100时,ssd控制器110(例如,主机接口层112)检查传入数据的流id,并且基于流分配表,确定将数据引导(direct)到什么引擎,并且如果
没有为流id指定引擎,则完全绕过数据处理器120(即,不应用数据处理器120中的任何引擎)。表1的示例中的流id 8的绕过压缩引擎和加密引擎也在图2中被可视化。
[0049]
在一些实施例中,在应用适当的数据处理引擎之后,ssd控制器110用适当的引擎id标记处理后的数据的每个单元,并且继续将数据存储在存储器装置130中的对应位置中,这是基于流分配表中指示的对应数据布置。在一些示例中,一旦数据的单元被数据处理器120处理(例如,被压缩和/或加密),ftl 114就将对应的一个或多个引擎id记录在处理后的数据的元数据中,并且将其与处理后的数据一起存储在对应的(一个或多个)存储器装置中。在一些示例中,数据的单元可以是适合ftl中的映射条目大小(例如,4kb)的逻辑页或一组页。
[0050]
当主机20发送对存储的数据的读取请求时,ssd控制器110(例如,ftl 114)基于存储的数据的元数据确定对存储的数据执行过什么操作,并且引导数据处理器120执行相反操作。例如,当数据处理器120在写入操作期间对特定流数据进行压缩/加密时,ssd控制器110在数据被主机20读回时自动指示数据处理器120对数据进行解压缩/解密。
[0051]
流分配表的知识(knowledge)允许主机20的应用在对主机20和/或ssd 100有益时选择适当的ssd内处理,并且在这样的操作对主机20或ssd 100赋予很少益处或没有益处时绕过(例如,不应用)ssd内数据处理。作为示例,在表1和图2的情况下,当来自应用8(图2中示出)的数据具有低压缩比,使得ssd 100不能受益于对来自应用8的数据进行压缩时,应用可选择使用流id 8,这绕过(例如,不应用)数据处理器120的压缩引擎,从而提高多流ssd 100的性能(例如,增大带宽)。
[0052]
如表1中所示,在一些示例中,数据处理器120可包括不同类型的压缩引擎(例如,deflate(rfc-1951)、zlib(rfc-1950)、gzip(rfc-1952)等)和/或不同类型的加密引擎(例如,rsa、aes等),数据流可被路由到最适合数据流的压缩/加密需求的压缩/加密引擎。
[0053]
根据一些实施例,ssd控制器110能够为给定流选择适当的流id。例如,ssd控制器110可(例如,实时地)监测经历压缩的流的压缩比,并且当流的压缩比小于阈值时,ssd控制器110可通过改变其流id(改变为例如绕过流id)来重新引导流绕过压缩引擎。用于绕过目的的该流id改变可在内部执行和临时地执行,并且可不被传送到主机20。根据一些示例,ssd控制器110可监测正在被存储的数据,并且如果需要则绕过去重。
[0054]
虽然图1示出数据处理器120在ssd 100内部并与ssd 100集成的实施例,但是本公开的实施例不限于此。例如,图3示出数据处理器120-1驻留在ssd 100-1外部的中间件系统200处的实施例。中间件系统200可驻留在云中,或者在主机操作系统与在其上运行的应用之间。在这样的示例中,数据处理器120-1可与图1的实施例的数据处理器120相同或基本相同,并且中间件系统200可包括类似于图1的实施例的主机接口层112的应用接口层112-1,应用接口层112-1处理来自主机应用的i/o请求。在一些实施例中,中间件控制器210处理以上关于图1和图2描述的输入流(例如,执行流id检测处理),并且能够绕过以上关于图1和图2描述的一个或多个数据处理引擎。中间件系统200保持处理后的数据的流id,因此多流ssd 100-1的主机接口层112可基于流id来识别/分开i/o流,并且允许流被存储在存储器装置130内的它们的对应位置处。
[0055]
如上所述,本公开对从中间件系统200接收的处理后的数据执行基于流id的布置。
[0056]
图4是示出根据本公开的一些示例实施例的在多流存储器系统中处理输入流的方
法300的流程图。
[0057]
在一些实施例中,在(例如,从将输入流与流id相关联的主机)接收到输入流时,ssd 100识别输入流的流id(s302)。然后,ssd 100基于流分配表,将装置内数据处理器120的多个数据处理引擎之中的第一数据处理引擎识别为与流id相关联(s304)。流分配表可将包括识别的流id的多个流id映射到多个数据处理引擎。然后,ssd 100将第一数据处理引擎应用于输入流,以生成可被存储在ssd 100内的处理后的数据(s306)。在一些实施例中,多个数据处理引擎包括不与流id相关联的第二数据处理引擎。这里,ssd 100基于流分配表,将第二数据处理引擎识别为不与流id相关联,并且针对处理后的数据绕过(例如,不应用)第二数据处理引擎。在一些实施例中,第一数据处理引擎被配置为执行与第二数据处理引擎的操作不同的操作。
[0058]
将理解,由多流ssd 100或中间件系统200和ssd 100-1执行的以上描述的操作仅是示例操作,并且由这些装置执行的操作可包括在此未明确描述的各种操作。
[0059]
由多流ssd的组成组件(例如,ssd控制器110、数据处理器120等)执行的操作可由“处理电路”或“处理器”(例如,控制器处理器)执行,“处理电路”或“处理器”可包括用于处理数据或数字信号的硬件、固件和软件的任何组合。处理电路硬件可包括例如专用集成电路(asic)、通用或专用中央处理器(cpu)、数字信号处理器(dsp)、图形处理器(gpu)和可编程逻辑器件(诸如,现场可编程门阵列(fpga))。在处理电路中,如在此使用的,每个功能由被配置(例如,硬连线)为执行该功能的硬件执行,或者由被配置为执行存储在非暂时性存储介质中的指令的更通用硬件(诸如,cpu)执行。处理电路可被制造在单个印刷线路板(pwb)上,或者分布在若干互连的pwb上。处理电路可包含其它处理电路,例如,处理电路可包括在pwb上互连的两个处理电路fpga和cpu。
[0060]
将理解,尽管在此可使用“第一”、“第二”、“第三”等的术语来描述各种元件、组件、区域、层和/或部分,但是这些元件、组件、区域、层和/或部分不应被这些术语限制。这些术语用于将一个元件、组件、区域、层或部分与另一元件、组件、区域、层或部分区分开。因此,在不脱离发明构思的范围的情况下,在此讨论的第一元件、第一组件、第一区域、第一层或第一部分能够被称为第二元件、第二组件、第二区域、第二层或第二部分。
[0061]
在此使用的术语用于描述特定实施例的目的,并且不意在限制发明构思。如在此使用的,除非上下文另外清楚地指示,否则单数形式也意在也包括复数形式。还将理解,术语“包括”和/或“包含”在本说明书中使用时,说明存在叙述的特征、整体、步骤、操作、元件和/或组件,但不排除存在或添加一个或多个其它特征、整体、步骤、操作、元件、组件和/或它们的组。如在此使用的,术语“和/或”包括相关所列项中的一个或多个的任何和全部组合。此外,在描述发明构思的实施例时“可”的使用表示“发明构思的一个或多个实施例”。此外,术语“示例性”意在表示示例或说明。
[0062]
将理解,当元件、层、区域或组件被称为“在”另一元件、层、区域或组件“上”、“连接到”或“结合到”另一元件、层、区域或组件时,该元件、层、区域或组件可直接在另一元件、层、区域或组件上、直接连接到或直接结合到另一元件、层、区域或组件,或者可存在一个或多个中间元件、层、区域或组件。另外,还将理解,当元件或层被称为“在”两个元件或层“之间”时,该元件或层可以是两个元件或层之间的唯一元件或层,或者也可存在一个或多个中间元件或层。
[0063]
如在此使用的,术语“使用”、“正在使用”以及“被使用”可分别被认为与术语“利用”、“正在利用”以及“被利用”同义。
[0064]
出于本公开的目的,“x、y和z中的至少一个”和“从由x、y和z组成的组选择的至少一个”可被解释为仅x、仅y、仅z,或x、y和z中的两个或更多个的任何组合(诸如,以xyz、xyy、yz和zz为例)。
[0065]
此外,在描述发明构思的实施例时“可”的使用表示“发明构思的一个或多个实施例”。此外,术语“示例性”意在表示示例或说明。
[0066]
当特定实施例可被不同地实现时,可以以描述的次序不同地执行特定的处理次序。例如,两个连续描述的处理可被基本上同时执行或者以与描述的次序相反的次序被执行。
[0067]
虽然已经具体参照本发明的说明性实施例详细描述了本发明,但在此描述的实施例并不意在将本发明的范围详尽或限制到所公开的确切形式。本发明所涉及的领域和技术的技术人员将理解,在不意图脱离如所附权利要求及其等同物所阐述的本发明的原理、精神和范围的情况下,描述的结构以及装配和操作的方法的改变和变化可被实践。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。