差分抽取装置、方法以及程序
1.优先权基础申请等关联申请的引用
2.本技术以2020年11月4日提交的日本专利申请第2020-184610号为基础,主张优先权,其全部内容通过引用并入本文。
技术领域
3.本发明的实施方式涉及差分抽取装置、方法以及程序。
背景技术:
4.一般而言,用于通过搜索未登记于词典的未知词作为词典登记的候补,从而支援用户的词典登记作业的技术正在开发。作为这种技术,例如,已知有如下方式:从对文本进行词素解析而得到的结果抽取复合词,如果该复合词未登记于已构建词典,则视为未知词。
5.该方式通常不特别成为问题,但根据本发明人的研究,有时关于即使不登记也成为正确的标记的未知词也作为词典登记的候补而被抽取。在该情况下,会登记不需要登记的词。
技术实现要素:
6.本发明要解决的课题是提供能够防止未知词中的即使不登记也成为正确的标记的未知词的登记的差分抽取装置、方法以及程序。
7.实施方式的差分抽取装置具备文本获取部、发音串变换部、标记串变换部以及比较部。所述文本获取部获取记载有输入标记串的文本。所述发音串变换部将所述输入标记串变换为发音串。所述标记串变换部将所述发音串变换为输出标记串。所述比较部比较所述输入标记串和所述输出标记串而抽取差分。
8.根据上述结构的差分抽取装置,能够防止未知词中的即使不登记也成为正确的标记的未知词的登记。
附图说明
9.图1是例示第1实施方式的差分抽取装置的结构的框图。
10.图2是例示第1实施方式中的从发音串向标记串的变换的示意图。
11.图3是用于说明第1实施方式中的比较部的示意图。
12.图4是例示第1实施方式中的显示画面的示意图。
13.图5是用于说明第1实施方式中的动作的流程图。
14.图6是用于说明第1实施方式中的动作的示意图。
15.图7是例示第1实施方式中的日语的音节的示意图。
16.图8是例示第1实施方式中的发音状态声响得分矢量的示意图。
17.图9是例示第1实施方式的变形例的特征量变换部的框图。
18.图10是用于说明第1实施方式的变形例中的动作的流程图。
19.图11是例示第2实施方式的差分抽取装置的结构的框图。
20.图12是用于说明第2实施方式中的动作的流程图。
21.图13是用于说明第2实施方式中的单词推测部的示意图。
22.图14是例示第2实施方式中的显示画面的示意图。
23.图15是示出第2实施方式中的指示例的示意图。
24.图16是例示第3实施方式的差分抽取装置的结构的框图。
25.图17是用于说明第3实施方式中的动作的流程图。
26.图18是例示第3实施方式的显示画面的示意图。
27.图19是示出第3实施方式的单词登记部的登记例的示意图。
28.图20是示出第3实施方式的登记反映时的显示例的示意图。
29.图21是例示第3实施方式的显示画面以及登记画面的示意图。
30.图22是例示第4实施方式的差分抽取装置的硬件结构的框图。
31.符号说明
32.1:差分抽取装置;10:文本获取部;20:发音串变换部;21:词素解析部;22:读音附加处理部;30:标记串变换部;31:特征量变换部;31a:声音合成部;31b:声响特征量计算部;31c:声响得分计算部;32:变换部;33:存储部;34:语言模型;35:单词词典;40:比较部;50:单词推测部;60:单词种类判定部;61:未知词判定部;62:标记波动判定部;70:显示控制部;71:显示器;80:指示部;81:鼠标;90:单词登记部;101:文本读入按钮;101a:打开按钮;102:输入标记串显示画面;103:输出标记串显示画面;104、600~602:显示属性;400:光标;401:单词候补画面;402:单词候补;403:范围修正按钮;700:单词登记按钮;701、800:单词登记画面;702:标记输入框;703:发音登记框;704:词类登记框;705、802:登记按钮;801:有效显示。
具体实施方式
33.以下,参照附图,说明实施方式的装置、方法以及存储介质。在以下的说明中,以将差分抽取装置搭载于声音识别系统,用于抽取登记于声音识别用的单词词典的单词的情况举为例子而进行叙述。此外,为了容易知道用途,差分抽取装置也可以换称为单词抽取装置、单词抽取支援装置、词典登记装置或者词典登记支援装置等这样的任意的名称。
34.《第1实施方式》
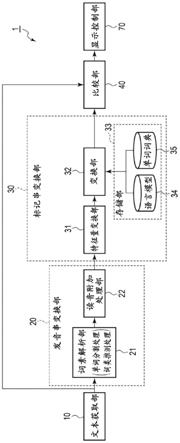
35.图1是例示第1实施方式的差分抽取装置的结构的框图。该差分抽取装置1具备文本获取部10、发音串变换部20、标记串变换部30、比较部40以及显示控制部70。
36.在此,文本获取部10获取记载有输入标记串的文本。获取到的文本被送出到发音串变换部20以及比较部40。例如,文本获取部10也可以根据操作者的操作,选择未图示的存储器内的文档文件并打开,从而从文档文件获取记载有输入标记串的文本。另外,例如,文本获取部10也可以根据由用户进行的键盘或者鼠标等的操作,获取通过键输入的文本或者从其它文档文件粘贴的文本。此外,文本获取部10也可以作为获取输入标记串的标记串获取部。
37.发音串变换部20将由文本获取部10获取到的输入标记串变换为发音串。例如,发音串变换部20解析该获取到的输入标记串,根据得到的解析结果将该输入标记串变换为发
音串。变换后的发音串被送出到标记串变换部30。这样的发音串变换部20例如也可以具备词素解析部21以及读音附加处理部22。发音串是表示输入标记串的读音的文本。例如,在输入标记串是“学習”(发音;gakushuu:意思;学习)的情况下,发音串成为
“ガクシュウ”
(gakushuu:学习)。
38.词素解析部21解析由文本获取部10获取到的输入标记串。例如,词素解析部21将输入标记串分割为单词,进行推测各单词的词类的词素解析。此外,在词素解析中所称的“单词”也可以换称为“词素”。即,词素解析包括将输入标记串分割为词素,推测各词素的词类的处理。词素解析部21也可以称为“输入标记串解析部”或者“解析部”。
39.读音附加处理部22根据词素解析的结果,对各单词附加读音而变换为发音串。读音附加处理部22例如也可以使用未图示的词素词典,对各单词附加读音。词素词典用于词素解析,是针对每个词素记述了词条(单词)、读音、词类以及变化形式等的词典。此外,不限于此,读音附加处理部22也可以使用后述单词词典35,对各单词附加读音。单词词典35是单词的标记、发音串(读音)以及词类相互关联起来存储的词典。
40.标记串变换部30将由发音串变换部20变换后的发音串变换为输出标记串。例如,标记串变换部30解析由发音串变换部20变换后的发音串,根据得到的解析结果,将该发音串变换为输出标记串。变换后的输出标记串被送出到比较部40。这样的标记串变换部30例如也可以具备特征量变换部31、变换部32以及存储部33。存储部33也可以具备语言模型34以及单词词典35。
41.在此,特征量变换部31将发音串变换为声响得分矢量。在此,特征量变换部31也可以执行(1)将发音串直接地变换为声响得分矢量的处理、(2)将发音串变换为声音信号,将该声音信号变换为声响得分矢量的处理中的任意处理。在第1实施方式中,将使用上述(1)的处理的情况举为例子而进行叙述。此外,在第1实施方式的变形例中叙述上述(2)的处理。
42.在此,声响得分矢量还被称为发音串特征量矢量,是如在变换部32中发音序列成为正解那样的特征矢量。此外,特征量变换部31也可以称为声响得分变换部。
43.变换部32使用语言模型34以及单词词典35,将声响得分矢量变换为输出标记串。详细而言,变换部32从声响得分矢量生成发音串,如图2所例示那样使用语言模型34以及单词词典35,将所生成的发音串变换为输出标记串。此外,变换部32也可以称为输出标记串变换部。
44.存储部33存储有声音识别用的语言模型34和单词词典35。
45.作为语言模型34,使用从与想要确认声音识别结果的声音识别引擎相同的统计信息制作出的模型。作为一个例子,作为语言模型,能够使用按照语言模型学习数据的一个单词的出现概率决定的n-gram语言模型(n是1以上的自然数)。作为语言模型,除了可以使用1-gram语言模型以外,还可以使用2-gram语言模型、3-gram语言模型、4-gram语言模型、5-gram语言模型
…
等其它语言模型。在图2中,作为语言模型34,使用将某个单词(第2词)的出现概率依赖于紧接着之前的已知的n-1单词(第1词)来决定的2-gram语言模型(n=2)。此外,也可以使用利用递归神经网络(rnn:recurrent neural networks)模型化的语言模型。另外,也可以使用加权有限状态传感器(wfst:weighted finite-state transducer)声音识别技术。
46.在单词词典35中,作为声音识别的对象的单词的标记、与标记对应的发音串、单词
的词类的信息被对应起来登记。例如如果是“評価”(hyooka:评价)这样的单词,则单词的标记是“評価”(hyooka:评价)这样的标记。例如如果是“評価”(hyooka:评价)这样的单词,则与标记对应的发音串是
“ヒョオカ”
(hyooka:评价)这样的发音串。
47.比较部40如图3所示比较由文本获取部10获取到的输入标记串和经由发音串变换部20以及标记串变换部30从该输入标记串得到的输出标记串,抽取差分。此外,“抽取差分”这样的用语也可以换称为“检测差分”或者“确定差分”等。比较部40将差分的抽取结果送出到显示控制部70。差分的抽取结果例如包括能够辨别地包含差分的输入标记串和能够辨别地包含差分的输出标记串。此外,不限于此,差分的抽取结果也可以包括确定输入标记串以及输出标记串与输入标记串以及输出标记串之中的差分的差分确定信息(例,差分的标记
“○○”
和位置(从文本开头起第xx个字符)等)。
48.显示控制部70使从比较部40送出的输入标记串、输出标记串以及比较结果等显示于显示器。详细而言,如图4所例示那样,显示控制部70使文本读入按钮101、输入标记串显示画面102以及输出标记串显示画面103显示于显示器71。文本读入按钮101是用于使文本获取部10获取文本的按钮。输入标记串显示画面102是配置有包含差分的输入标记串的画面。输出标记串显示画面103是配置有包含差分的输出标记串的画面。输入标记串显示画面102以及输出标记串显示画面103分别也可以称为输入标记串显示区域以及输出标记串显示区域。差分根据显示属性104从差分以外的标记串能够辨别地显示。在图4中,显示属性104表示实线的下划线。但是,作为显示属性104,不限于此,能够适当地使用能够辨别差分的有无的属性。例如,作为显示属性,也可以使用字符的颜色、字体的种类、大小,背景的颜色等各种显示属性。
49.接下来,使用前述附图、图5的流程图以及图6至图8的示意图,说明如以上那样构成的差分抽取装置的动作。此外,差分抽取装置的动作对应于差分抽取方法。
50.在步骤st10中,文本获取部10获取记载有输入标记串的文本。具体而言,例如,显示控制部70如图6所示使文本读入按钮101、输入标记串显示画面102以及输出标记串显示画面103显示于显示器71。此外,在文本获取前的情况下,与图6不同,输入标记串显示画面102是空栏。文本读入按钮101是用于通过用户的操作使文本获取部10执行使包括能够选择的文件的列表和打开按钮101a的文件选择画面101b显示于显示器71的处理的按钮。打开按钮101a是用于通过用户的操作使文本获取部10执行打开在列表中选择的文件,并且获取该打开的文件内的文本的处理的按钮。
51.在此,文本获取部10通过文本读入按钮101的操作使文件选择画面101b显示于显示器71。另外,文本获取部10通过用户的操作在列表中选择文件,通过打开按钮101a的操作从该所选择的文件获取记载有输入标记串的文本。获取到的文本显示于输入标记串显示画面102,并且被送出到发音串变换部20。
52.在步骤st20中,发音串变换部20解析在步骤st10中获取到的输入标记串,变换为发音串。详细而言,发音串变换部20解析输入标记串,根据得到的解析结果将输入标记串变换为发音串。这样的步骤st20由词素解析部21以及读音附加处理部22作为步骤st21~st22而执行。
53.在步骤st21中,词素解析部21对该获取到的输入标记串进行词素解析,进行词素的分割以及词类推测。详细而言,词素解析部21将输入标记串分割为单词,进行推测各单词
的词类的词素解析。例如,在获取到的标记串是“評価実験”(hyooka jikken:评价实验)的情况下,分为“評価”(hyooka:评价)和“実験”(jikken:实验),分别被推测为名词。
54.在步骤st22中,读音附加处理部22接收词素解析部21的结果,针对每个词素进行读音附加,将发音串供给到标记串变换部30。详细而言,读音附加处理部22根据词素解析的结果,对各单词附加读音而变换为发音串。例如,在从词素解析部21作为结果而示出“評価”(hyooka:评价)和“実験”(jikken:实验)的情况下,由读音附加处理部22对各自进行
“ヒョオカ”
(hyooka:评价)和
“ジッケン”
(jikken:实验)的读音附加。然后,将
“ヒョオカジッケン”
(hyooka jikken:评价实验)交给标记串变换部30。由此,包括步骤st21~st22的步骤st20结束。
55.在步骤st30中,标记串变换部30将在步骤st20中变换后的发音串作为输入而接收,解析发音串而变换为输出标记串,将输出标记串送出到比较部40。这样的步骤st20由特征量变换部31以及变换部32作为步骤st31~st33而执行。
56.在步骤st31中,特征量变换部31将在步骤st20中得到的发音串变换为声响得分矢量。具体而言,特征量变换部31从获取到的发音串生成发音串特征量矢量。发音串特征量矢量是如在后级的变换部32中发音序列成为正解那样的特征矢量。例如,在使用了dnn以及hmm的dnn-hmm声音识别引擎中,每隔一定的时间将声音区间切取为1帧。另外,针对切取的帧,使用dnn来计算发音序列的发音状态输出概率矢量(发音状态声响得分矢量)。此外,dnn是深度神经网络(深层neural network)的简称。hmm是隐马尔科夫模型(hidden markov model)的简称。
57.在此,说明发音状态声响得分矢量。在此,将发音的单位作为音节叙述。在日语的情况下,除了所谓的50音之外,还有浊音(
“ガ”
(ga)、
“ザ”
(za)等)、半浊音(
“パ”
(pa)等)、拗音(
“キャ”
(kya)、
“ジャ”
(ja)等)的音节。此外,拨音
“ン”
(n,m)和促音
“ッ”
(tt,kk,pp)也作为一个音节处置,长音
“ー”
用紧接着之前的母音进行置换而处置。在此,将日语的音节设为图7所例示的102个而进行说明。各发音通常用3个状态左右的hmm表达,但为了简化说明,将各发音设为一个状态而进行说明。该情况下的发音状态声响得分矢量是表示矢量的各要素的值对应的音节的似然度的102维的矢量。即,作为发音状态声响得分矢量,针对输入到特征量变换部31的发音串,针对每一个音节,从特征量变换部31输出一个102维的矢量。但是,不限于此,也可以用3个状态表达各发音,针对每一个音节使用306维的发音状态声响得分矢量。
58.作为向发音状态声响得分矢量的变换方法,将与变换对象的音节对应的要素(输出概率)设为1,将其它要素设为0即可。例如,在作为发音串而输入
“ヒョオカ”
(hyooka:评价)的情况下,如图8所例示那样,针对输入
“ヒョ”
(hyo),输出仅将与
“ヒョ”
(hyo)对应的要素设为1,将其它全部设为0的矢量即可。同样地,针对
“オ”
(o),输出仅将与
“オ”
(o)对应的要素设为1,将其它全部设为0的矢量即可。关于
“カ”
(ka)也相同。此外,该发音状态声响得分矢量列相对于
“ヒョ”
(hyo)、
“オ”
(o)、
“カ”
(ka)这样的发音串,似然度最高。因此,在将该发音状态声响得分矢量串供给到变换部32(例,dnn-hmm解码器)时,变换部32将声响得分矢量变换为发音串,将发音串变换为标记串。详细而言,如果与所输入的发音串相同的发音串处于单词词典35,则变换部32关于发音串输出与输入相同的发音串,关于标记串输出依赖于语言模型34而决定的标记串。
59.此外,发音状态声响得分矢量的制作方法不限于此,也可以不使用输出概率,而如对应状态的要素是10.0,其它要素是5.0等那样,使用任意的比来输出。另外,也可以构成为对发音状态声响得分矢量施加噪音,判别在更严格的条件下是否输出所期望的结果。另外,也可以在使用了混合高斯模型(gmm:gaussian mixture model)的hmm声音识别中,将把表示各发音串状态的gmm的多维的平均值作为要素的矢量等设为发音状态声响得分矢量。但是,在该情况下,在标记串变换执行时,使用gmm-hmm声音识别引擎用的语言模型和声响模型。
60.在步骤st32中,变换部32将在步骤st31中得到的发音状态声响得分矢量串变换为发音串。详细而言,以下,将发音状态声响得分矢量的各要素的值是表示对应的音节的似然度的102维的矢量的情况举为例子而进行说明。另外,将发音的单位作为音节而叙述。
61.变换部32根据发音状态声响得分矢量,推测对应的音节。日语的音节除了所谓的50音之外,还用浊音(
“ガ”
(ga)、
“ザ”
(za)等)、半浊音(
“パ”
(pa)等)、拗音(
“キャ”
(kya)、
“ジャ”
(ja)等)表达。此外,拨音
“ン”
(n,m)和促音
“ッ”
(tt,kk,pp)也作为一个音节处置,长音
“ー”
用紧接着之前的母音进行置换而处置。在此,将日语的音节设为图7所例示的102个而进行说明。此外,在本说明书中,用片假名表达音节,但不限于此,也可以用平假名表达音节。在发音状态声响得分矢量中,各要素的值表示各音节的似然度,所以被推测为对应的音节的似然度的值大的音节。例如,当在102维的发音状态声响得分矢量的要素中,仅与音节
“ヒョ”
(hyo)对应的要素的值是1,其它所有的要素的值是0的情况下,该发音状态声响得分矢量被变换为音节
“ヒョ”
(hyo)。此外,发音状态声响得分矢量的要素的值仅是0和1而进行了说明,但不限定于此。作为发音状态声响得分矢量,能够使用要素的值表示似然度的任意的矢量。即,这种发音状态声响矢量按照同样的次序,被推测为高的似然度的音节,变换为音节。这样,变换部32将发音状态声响得分矢量变换为音节,生成发音串。
62.在步骤st33中,变换部32一边参照存储部33内的语言模型34和单词词典35,一边将在步骤st32中得到的发音串变换为输出标记串。即,变换部32参照单词词典35,推测与发音串对应的标记的候补也就是说单词的候补。另外,变换部32使用语言模型34,一边考虑单词的前后的关联,一边从在单词词典35中推测出的单词候补选择如作为文章是适当的单词,生成标记串。
63.在此,使用前述图2,详细地说明步骤st33的动作的一个例子。在此,在单词词典35中,至少针对发音串
“ヒョオカ”
(hyooka)登记有标记“評価”(hyooka:评价),针对发音串
“ジッケン”
(jikken)登记有标记“実験”(jikken:实验)和“実権”(jikken:实权)。另外,将以下情况举为例子而进行叙述:使用用两个单词的出现概率表达的2-gram语言模型,在语言模型的学习数据中,针对发音串
“ヒョオカジッケン”
(hyooka jikken),比“評価実権”(hyooka jikken:评价实权),“評価実験”(hyooka jikken:评价实验)的组合更多地出现。
64.变换部32针对发音串
“ヒョオカジッケン”
(hyooka jikken),首先参照单词词典35。其结果,针对发音串
“ヒョオカ”
(hyooka)得到“評価”(hyooka:评价)这一个候补,针对
“ジッケン”
(jikken)得到“実験”(jikken:实验)和“実権”(jikken:实权)这两个候补。
65.接下来,变换部32使用语言模型34来决定
“ヒョオカ”
(hyooka)与
“ジッケン”
(jikken)的适当的组合。在是图2所例示的语言模型的情况下,相比“評価実権”(hyooka jikken:评价实权),“評価実験”(hyooka jikken:评价实验)的出现概率更高,所以针对发
音串
“ヒョオカジッケン”
(hyooka jikken),决定标记串“評価実験”(hyooka jikken:评价实验)。在该例子的情况下,所决定的标记串“評価実験”(hyooka jikken:评价实验)如图4所示与输入标记串“評価実験”(hyooka jikken:评价实验)相同,即使不登记到单词词典35,也是正确的标记。此外,不限于此,有时还如图3所示,所决定的标记串“新装学習”(shinsoo gakushuu:新装学习)与输入标记串“深層学習”(shinsoo gakushuu:深层学习)不同。在该情况下,在后级的比较部40抽取差分“深層”(shinsoo:深层)。
66.在这样的从发音串向标记串的变换中,能够针对输入发音串,使用利用了n-gram(n是1以上的自然数)的出现概率的维特比算法(viterbi algorithm)。此外,搜索算法不限定于维特比算法,也可以使用树栅格(tree trellis)搜索算法等其它算法。另外,变换部32将变换后的输出标记串供给到比较部40。由此,包括步骤st31~st33的步骤st30结束。
67.在步骤st40中,比较部40比较在步骤st10中获取到的输入标记串和在步骤st30中供给的输出标记串,抽取差分。例如如图3所示,利用发音串变换部20将由文本获取部10获取到的输入标记串变换为发音串,利用标记串变换部30变换为输出标记串。然后,当由比较部40进行比较时,“深層”(shinsoo:深层)作为差分而被抽取。
68.在步骤st70中,显示控制部70例如如图4所示使包括输入标记串的输入标记串显示画面102和包括输出标记串的输出标记串显示画面103显示于显示器71。另外,显示控制部70在输入标记串显示画面102和输出标记串显示画面103这两个画面,利用显示属性104将差分设为能够从其它标记辨别的状态来显示于显示器71。在该状态下,包含差分的标记能够适当地根据由用户进行的键盘或者鼠标等的操作,登记于单词词典35。另外,还能够在后述单词推测等的处理后,登记于单词词典35。
69.如上所述,根据第1实施方式,文本获取部获取记载有输入标记串的文本。发音串变换部将输入标记串变换为发音串。标记串变换部将发音串变换为输出标记串。比较部比较输入标记串和输出标记串,抽取差分。
70.利用这样的结构,输入标记串中包含的未知词中的在输出标记串中不成为正确的标记的未知词作为差分而被抽取。换言之,输入标记串中包含的未知词中的在输出标记串中成为正确的标记的未知词不被抽取为差分。因而,能够防止未知词中的即使不登记也成为正确的标记的未知词的登记。另外,即使从少量的输入标记串也能够抽取与输出标记串的差分。另外,比较输入标记串和从输入标记串经由发音串变换后的输出标记串,作为差分而抽取不成为正确的标记的部分,所以能够抽取对于声音识别有用的差分。另外,用户对抽取出的差分进行词典登记作业,所以能够防止标记波动等不需要的词的登记。另外,能够在制作单词词典时,将应登记到单词词典的单词易于理解地提示给用户。另外,用户进行词典登记作业,所以能够针对每个用户,根据标记串的领域对单词词典进行改良。
71.另外,根据第1实施方式,标记串变换部也可以具备特征量变换部、存储部以及变换部。特征量变换部也可以将发音串变换为声响得分矢量。存储部也可以存储声音识别用的语言模型和单词词典。变换部也可以从声响得分矢量生成发音串,使用语言模型以及单词词典将该生成的发音串变换为输出标记串。在该情况下,除了前述效果之外,由于使用声音识别用的语言模型和单词词典来得到输出标记串,所以还能够作为包含不处于单词词典的未知词的标记,抽取更适当的差分。
72.另外,根据第1实施方式,发音串变换部也可以具备词素解析部和读音附加处理
部。词素解析部也可以将输入标记串分割为单词,进行推测各单词的词类的词素解析。读音附加处理部也可以根据词素解析的结果,对各单词附加读音,变换为发音串。在该情况下,除了前述效果之外,例如,相比于变换为使用如重音、停顿那样的读音以外的信息的发音串的情况,能够容易地变换为发音串。
73.《第1实施方式的变形例》
74.第1实施方式的变形例是如下方式:特征量变换部31不执行将发音串直接地变换为声响得分矢量的处理,而执行在将发音串变换为声音信号之后变换为声响得分矢量的处理。
75.与其相伴地,特征量变换部31如图9所示具备声音合成部31a、声响特征量计算部31b以及声响得分计算部31c。
76.在此,声音合成部31a从由发音串变换部20变换后的发音串合成声音信号。合成后的声音信号被送出到声响特征量计算部31b。此外,“声音信号”还称为“声音波形信号”。例如,声音合成部31a依照所输入的发音串,生成声音波形信号。
77.声响特征量计算部31b根据由声音合成部31a合成后的声音信号来计算声响特征矢量。例如,声响特征量计算部31b以预定的帧单位根据声音信号计算表示谱的特征的声响特征矢量。计算出的声响特征矢量被送出到声响得分计算部31c。
78.声响得分计算部31c根据由声响特征量计算部31b计算出的声响特征矢量来计算声响得分矢量。例如,声响得分计算部31c根据声响特征矢量来推测各音节的似然度,计算发音状态声响得分矢量。计算出的声响得分矢量被送出到前述变换部32。
79.其它结构与第1实施方式相同。
80.接下来,使用图10的流程图,说明如以上那样构成的变形例的动作。在以下的说明中,叙述将发音串变换为声响得分矢量的步骤st31的动作。即,与前述同样地,执行步骤st10~st20的处理,在步骤st30中,开始步骤st31的处理。步骤st31包括步骤st31-1~st31-3。
81.在步骤st31-1中,声音合成部31a从由发音串变换部20变换后的发音串合成声音信号。在此,声音合成部31a能够使用能够从任意的发音串生成声音波形信号的各种公知的手法。例如,能够使用存储音节单位的波形数据,依照所输入的发音串选择及连接波形数据的手法。关于表示声音的音调的间距信息,既可以不变更地直接连接波形数据,也可以通过公知的技术推测自然的间距变化来修正波形数据的间距。另外,也可以不存储波形数据,而存储音节单位的谱参数序列,使用音源滤波器模型来合成声音信号。或者,也可以使用根据音节的序列来预测谱参数序列的dnn。在任意情况下,声音合成部31a都从发音串合成声音信号,将该声音信号送出到声响特征量计算部31b。
82.在步骤st31-2中,声响特征量计算部31b根据在步骤st31-1中合成后的声音信号来计算声响特征矢量。例如,在声响特征量计算部31b中,通过与在声音识别处理中使用的处理同样的处理,根据声音波形信号计算声响特征矢量序列。首先,声响特征量计算部31b对所输入的声音数据例如以帧长10ms且帧移5ms进行快速傅里叶变换,变换为谱。接下来,声响特征量计算部31b根据预定的带宽的规格来求出每个频域的功率谱的总和,变换为滤波器组特征矢量,作为声响特征矢量而送出到声响得分计算部31c。作为声响特征矢量,除此以外,能够使用梅尔频率倒谱系数(mfcc:mel frequency cepstral coefficients)等
各种声响特征矢量。
83.在步骤st31-3中,声响得分计算部31c根据在步骤st31-2中计算出的声响特征矢量计算声响得分矢量。例如,声响得分计算部31c将声响特征矢量作为输入,使用dnn来推测发音状态声响得分矢量,并进行输出。关于声响得分计算部31c的处理,也能够使用在声音识别中利用的各种公知的手法。也可以代替基于全结合的dnn,而使用卷积神经网络(cnn:convolutional neural network)、长短期存储(lstm:long short-term memory)等。在任意情况下,声响得分计算部31c都根据声响特征矢量计算声响得分矢量,将该声响得分矢量送出到变换部32。基于以上,包括步骤st31-1~st31-3的步骤st31结束。
84.以下,与前述同样地,执行步骤st32以后的处理。
85.如上所述,根据第1实施方式的变形例,特征量变换部具备声音合成部、声响特征量计算部以及声响得分计算部。声音合成部从发音串合成声音信号。声响特征量计算部根据声音信号计算声响特征矢量。声响得分计算部根据声响特征矢量计算声响得分矢量。
86.因而,利用在将发音串变换为声音信号之后变换为声响得分矢量的结构,除了第1实施方式的效果之外,还能够对使用声音识别用的语言模型和单词词典的变换部供给更合适的声响得分矢量。
87.进行补充,根据该变形例,输出的发音状态声响得分矢量与在实际的声音识别的处理中生成的矢量类似,从而能够生成更加接近声音识别结果的标记串。变形例的发音状态声响得分矢量不仅是与输入音节对应的要素,与和其类似的音节对应的要素也存在值变大的趋势,与前述仅将0和1作为要素的发音状态声响得分矢量(发音状态输出概率矢量)不同。即,在第1实施方式中叙述的发音状态声响得分矢量中,仅将与输入音节对应的要素的值设为1。相对于此,关于变形例中叙述的声响得分矢量,与输入音节对应的要素的值和与类似于输入音节的音节对应的要素的值分别变大,所以能够与在实际的声音识别的处理中生成的矢量类似。
88.《第2实施方式》
89.接下来,使用图11至图15,说明第2实施方式。第2实施方式与第1实施方式或者其变形例相比,对由比较部40抽取出的差分追加性地进行处理。例如,第2实施方式与仅抽取差分而显示的第1实施方式不同,将抽取出的差分变换为单词单位的差分而显示。另外,在第2实施方式中,修正所显示的单词候补的范围,所以能够期待单词抽取的质的提高。
90.图11是例示第2实施方式的差分抽取装置1的结构的框图,关于与前述构成要素同样的构成要素,附加相同的符号,省略其详细的说明,在此,主要叙述不同的部分。以下的各实施方式也同样地省略重复的说明。
91.该差分抽取装置1相比于图1所示的结构,还具备单词推测部50以及指示部80。
92.在此,单词推测部50根据基于词素解析部21的输入标记串的解析结果,推测输入标记串中的包含由比较部40抽取出的差分的单词候补的标记。在此,输入标记串的解析结果例如是基于词素解析部21的词素解析的结果。
93.与其相伴地,显示控制部70使包含由单词推测部50推测出的单词候补的输入标记串显示于显示器71。
94.指示部80指示显示于显示器71的输入标记串中的包含单词候补中的至少一部分的标记的范围。例如,指示部80也可以根据由用户进行的键盘或者鼠标(未图示)的操作,指
示标记的范围。此外,不限于此,指示部80也可以根据触摸面板等这样的其它输入设备的操作,指示标记的范围。
95.接下来,使用图12的流程图以及图13至图15的示意图,说明如以上那样构成的差分抽取装置的动作。
96.现在,与前述同样地,执行步骤st10~st40,抽取出输入标记串与输出标记串的差分。
97.在步骤st50中,单词推测部50根据输入标记串的解析结果,推测输入标记串中的包含差分的单词候补的标记。详细而言,单词推测部50抽取能够推测为将在比较部40中抽取出的差分的词的邻接的词素进行连结而构成单词的字符串,作为单词候补而输出。具体而言,单词推测部50如图13所例示那样,设为差分的词是“深層”(shinsoo:深层),确认是否与其前后的词合起来形成单词。在该情况下,在差分之前,存在词
“は”
(wa),在差分之后存在词“学習”(gakushuu:学习),所以有可能与后面的词形成单词。因而,在单词推测部50中,“深層学習”(shinsoo gakushuu:深层学习)被推测为单词候补。作为这样构成单词的字符串的判断,例如使用
“‘
名词-一般’的连结部分推测为单词”等规则。另外,在单词推测部50中,不限于使用了一个词素解析结果的规则,也可以进而利用根据大量的词素解析的结果,将高频度地邻接地出现的多个词素进行连结而推测为单词候补的其它规则。
98.在步骤st71中,显示控制部70如图14所例示那样,将由文本获取部10获取到的标记串配置于输入标记串显示画面102,将由标记串变换部30输出的标记串配置于输出标记串显示画面103而显示于显示器71。另外,在显示控制部70中,根据由比较部40抽取出的差分和由单词推测部50推测出的单词候补,利用显示属性104使包含差分的标记显示于显示器71。在该状态下,包含差分的标记能够适当地根据由用户进行的键盘或者鼠标等的操作登记于单词词典35。另外,还能够在接下来的步骤st80之后,登记于单词词典35。
99.在步骤st80中,指示部80使用光标400、单词候补画面401、单词候补402以及范围修正按钮403。在指示部80中,能够根据用户的操作,变更显示控制部70的显示属性104的范围来变更单词的范围。
100.具体而言,指示部80如图15所例示那样,当将光标400对准到输入标记串显示画面102的显示属性104之上时,单词候补画面401被打开,显示单词候补402(步骤st80-1)。
101.指示部80将光标400对准到单词候补402之上来选择候补,变更输入标记串显示画面102和输出标记串显示画面103的显示属性104的范围(步骤st80-2)。例如,指示部80将光标400对准到单词候补的标记
“ペンローズ”
(penroozu:彭罗斯)之上,从单词候补画面401之中的单词候补402之中选择
“ムーア
·
ペンローズ”
(muua penroozu:穆尔-彭罗斯)。由此,指示部80将显示属性104的范围从单词候补的标记
“ペンローズ”
(penroozu:彭罗斯)变更为包含该标记的全部的范围
“ムーア
·
ペンローズ”
(muua penroozu:穆尔-彭罗斯)。此外,不限于此,指示部80也可以将光标400对准到单词候补的标记
“ペンローズ”
(penroozu:彭罗斯)之上,从单词候补画面401之中的单词候补402之中选择
“ペン”
(pen:笔)或者
“ローズ”
(roozu:玫瑰)。由此,指示部80将显示属性104的范围从单词候补的标记
“ペンローズ”
(penroozu:彭罗斯)变更为包含该标记的一部分的范围
“ペン”
(pen:笔)或者
“ローズ”
(roozu:玫瑰)。
102.或者,指示部80选择范围修正按钮403,使用光标400来变更显示属性104的范围。
例如,指示部80选择范围修正按钮403,根据由用户进行的鼠标81的操作,使光标400移动,扩大
“ペンローズ”
(penroozu:彭罗斯)的范围,从而选择
“ムーア
·
ペンローズ”
(muua penroozu:穆尔-彭罗斯)的范围。不限于此,指示部80也可以选择范围修正按钮403,根据用户的鼠标81的操作,使光标400移动,将显示属性104的范围从单词候补的标记
“ペンローズ”
(penroozu:彭罗斯)缩小到包含该标记的一部分的范围
“ペン”
(pen:笔)或者
“ローズ”
(roozu:玫瑰)。
103.步骤st80-2或者st80-2a的结果,例如输入标记串显示画面102的显示属性104成为
“ムーア
·
ペンローズ”
(muua penroozu:穆尔-彭罗斯)(步骤st80-3),输出标记串显示画面103的显示属性104成为
“ムーア
·
penrose”(muua penrose:穆尔-彭罗斯)。另外,在输入标记串显示画面102的显示属性104的范围是
“ペン”
(pen:笔)或者
“ローズ”
(roozu:玫瑰)的情况下,输出标记串显示画面103的显示属性104的范围是“pen”或者“rose”。
104.如上所述,根据第2实施方式,解析部解析输入标记串。单词推测部根据输入标记串的解析结果,推测输入标记串中的包含差分的单词候补的标记。因而,利用能够推测包含差分的单词候补的标记的结构,除了第1实施方式的效果之外,即使在差分与和差分连结的名词的复合词是未知词的情况下,也能够将该未知词推测为单词候补。
105.另外,根据第2实施方式,显示控制部使包含单词候补的输入标记串显示于显示器。指示部指示所显示的输入标记串中的包含单词候补中的至少一部分的标记的范围。因而,利用能够修正推测出的单词候补的范围的结构,能够期待单词抽取的质的提高。
106.《第3实施方式》
107.接下来,使用图16至图21,说明第3实施方式。在第3实施方式中,针对在第2实施方式中推测出的单词候补判定单词种类,使用与单词种类相应的显示属性来显示单词候补。另外,第3实施方式也可以将所显示的单词候补登记于单词词典35,使登记的结果反映到显示。
108.图16是表示第3实施方式的差分抽取装置1的处理的框图。该差分抽取装置1除了具备图11所示的结构之外,还具备单词种类判定部60以及单词登记部90。单词种类判定部60也可以具备未知词判定部61以及标记波动判定部62。
109.在此,单词种类判定部60判定由单词推测部50推测出的单词候补的单词种类。例如,单词种类判定部60也可以利用未知词判定部61将由单词推测部50推测出的单词候补的单词种类判定为未知词。或者,例如,单词种类判定部60也可以利用标记波动判定部62将由单词推测部50推测出的单词候补的单词种类判定为标记波动。此外,不限于此,作为单词种类判定部60,能够对表示单词标记的各种种类进行使用。例如,单词种类判定部60能够推测固有名词、动词等各种种类。
110.如果由单词推测部50推测出的单词候补的标记未登记于单词词典35,则未知词判定部61将该单词候补的标记判定为未知词。
111.如果由单词推测部50推测出的单词候补的标记和与该单词候补的标记对应的输出标记串内的标记是相同的单词的不同标记,则标记波动判定部62将作为该不同标记的两个标记判定为标记波动。标记波动的判定例如能够根据两个标记是否处于不同标记词典内来执行。不同标记词典是记述有相同的单词的不同标记的词典。“不同标记词典”也可以称为“不同标记信息”或者“标记波动判定信息”。
112.此外,显示控制部70使用与由单词种类判定部60判定出的单词种类相应的显示属性,使单词候补的标记显示于显示器71。
113.单词登记部90将由指示部80指示的范围的标记登记于单词词典35。
114.接下来,使用图17的流程图以及图18至图21的示意图,说明如以上那样构成的差分抽取装置的动作。
115.现在,与前述同样地,执行步骤st10~st50,推测出包含差分的单词候补的标记。
116.在步骤st60中,单词种类判定部60并行地执行未知词判定部61和标记波动判定部62。在未知词判定部61中,进行如果在步骤st50中推测出的单词候补的标记未登记于单词词典35则判定为未知词的处理。例如,在根据输入标记串与输出标记串的差分而
“ペンローズ”
(penroozu:彭罗斯)的标记被推测为单词候补的情况下,单词候补的标记
“ペンローズ”
(penroozu:彭罗斯)不包含于单词词典35,所以被判定为未知词。
117.在标记波动判定部62中,进行如果在步骤st50中推测出的单词候补的标记和与单词候补的标记对应的输出标记串内的标记是相同的单词的不同标记则判定为标记波动的处理。例如,在输入标记串“所”(tokoro:地方,部分)和对应的输出标记串
“ところ”
(tokoro:部分,地方)的情况下,根据两者的差分,单词候补被推测为“所”(tokoro:地方,部分)。如果推测出的单词候补的标记“所”(tokoro:地方,部分)和对应的输出标记串内的标记
“ところ”
(tokoro:部分,地方)这两个处于不同标记词典内,则是相同的单词的不同标记,所以被判定为标记波动。
118.在步骤st72中,显示控制部70如图18所例示那样,根据推测为抽取出的差分的单词候补,进而根据单词种类,利用与单词种类相应的显示属性600~602使差分的标记显示于显示器71。在该例子中,
“ペンローズ”
(penroozu:彭罗斯)被判定为未知词,“所”(tokoro:地方,部分)被判定为标记波动,所以
“ペンローズ”
(penroozu:彭罗斯)用双划线的显示属性600显示,“所”(tokoro:地方,部分)用虚线的显示属性602显示,其它词用实线的显示属性601显示。在该例子中,显示属性601设为双划线的显示属性、虚线的显示属性602以及其它显示属性601,但不限于此,能够根据单词种类来使用任意的字符修饰。作为显示属性的变形例,能够适当地使用高亮的浓度、字符大小、字体、颜色、粗体字、斜体、在字符的前后配置预定记号(例,黑三角)等各种种类。
119.在步骤st72之后,适当地执行步骤st80。此外,如果没有用户的操作,则省略步骤st80。
120.在步骤st90中,单词登记部90如图19所例示那样使用单词候补画面401和单词登记画面701,执行单词的登记处理。单词候补画面401是包括单词候补402、范围修正按钮403以及单词登记按钮700的画面。单词登记画面701通过单词登记按钮700的操作显示,是包括标记输入框702、发音登记框703、词类登记框704以及登记按钮705的画面。例如,当与由用户进行的鼠标81的操作相应地,将光标400对准到显示属性601之上时,单词候补画面401被打开,当按压单词登记按钮700时,单词登记画面701被打开。在单词登记画面701,将针对显示属性601的范围的单词的标记、发音以及词类分别输入到标记输入框702、发音登记框703以及词类登记框704,当按压登记按钮705时,单词被登记到单词词典35。在该例子中,输入了标记输入框702、发音登记框703以及词类登记框704,但也可以在按压单词登记按钮700之后,自动地输入标记、读音、词类。
121.另外,单词登记部90也可以为了如图20所例示那样使登记的单词反映到显示画面,通过手动或者自动再次执行标记串变换部30、比较部40、单词推测部50、单词种类判定部60以及显示控制部70。在图20的下层,例示出更新后的输入标记串显示画面102和输出标记串显示画面103。在利用单词登记部90将“深層学習”(shinsoo gakushuu:深层学习)登记于单词词典35之后,执行这样的单词登记反映处理,从而在输出标记串显示画面103显示为“深層学習”(shinsoo gakushuu:深层学习)。因此,比较部40不进行差分抽取,显示属性601不被显示。
122.另外,单词登记部90也可以如图21所例示那样使得用于集中登记多个单词的单词登记画面800显示于显示器71。在此,单词登记画面800将由单词推测部50推测出的单词候补以及与由指示部80指示的范围的单词候补的差分对应的输入标记串显示画面102的输入标记串的单词作为应登记到单词词典35的多个单词而显示。在单词登记画面800内的有效显示801处,能够指定进行单词登记的单词。通过按压单词登记画面800内的登记按钮802,单词登记部90能够将在有效显示801处设为有效的单词集中登记于单词词典35。
123.此外,在图21中,有效显示801是复选框,但不限于此,能够使用各种显示方式。例如,也可以代替复选框而使用圆圈记号、叉记号、涂抹等各种显示方式。除此之外,在图21所示的例子中,标记输入框702、发音登记框703以及词类登记框704是自动输入,但也可以是用户手动输入。在任意情况下,通过向单词词典35的登记,步骤st90结束。
124.如上所述,根据第3实施方式,单词种类判定部60判定单词候补的单词种类。因而,除了第2实施方式的效果之外,还能够在登记单词候补之前,区分是否是需要单词候补的登记的单词种类。
125.另外,根据第3实施方式,显示控制部70也可以使用与单词种类相应的显示属性使单词候补的标记显示于显示器。在该情况下,能够在用户登记单词候补之前,支援是否需要单词候补的登记的判断。
126.另外,根据第3实施方式,单词登记部90也可以将所指示的范围的标记登记于单词词典。在该情况下,能够将由用户进行确认后的标记登记于单词词典。
127.另外,根据第3实施方式,也可以是如果单词候补的标记未登记于单词词典,则单词种类判定部60中的未知词判定部61将该单词候补的标记判定为未知词。在该情况下,能够准确地检测单词候补中的未登记于单词词典的未知词。
128.另外,根据第3实施方式,也可以是如果单词候补的标记和与该单词候补的标记对应的输出标记串内的标记是相同的单词的不同标记,则单词种类判定部60中的标记波动判定部62将作为该不同标记的两个标记判定为标记波动。在该情况下,能够检测单词候补中的无需新登记于单词词典的标记波动的单词。
129.《第4实施方式》
130.图22是例示第4实施方式的差分抽取装置的硬件结构的框图。第4实施方式是第1至第3实施方式的具体例,是通过计算机实现差分抽取装置1的方式。
131.该差分抽取装置1作为硬件而具备cpu(central processing unit,中央处理单元)2、ram(random access memory,随机存取存储器)3、程序存储器4、辅助存储装置5以及输入输出接口6。cpu2经由总线与ram3、程序存储器4、辅助存储装置5以及输入输出接口6进行通信。即,本实施方式的差分抽取装置1通过这样的硬件结构的计算机实现。
132.cpu2是通用处理器的一个例子。ram3作为工作存储器而在cpu2中使用。ram3包括sdram(synchronous dynamic random access memory,同步动态随机存取存储器)等易失性存储器。程序存储器4存储用于实现与各实施方式相应的各部分的程序。该程序例如也可以设为用于使计算机实现如下各功能的程序。[1]获取记载有输入标记串的文本的功能。[2]将输入标记串变换为发音串的功能。[3]将发音串变换为输出标记串的功能。[4]比较输入标记串和输出标记串而抽取差分的功能。另外,作为程序存储器4,例如使用rom(read-only memory,只读存储器)、辅助存储装置5的一部分或者其组合。辅助存储装置5非临时地存储数据。辅助存储装置5包括hdd(hard disc drive,硬盘驱动器)或者ssd(solid state drive,固态硬盘)等非易失性存储器。
[0133]
输入输出接口6是用于与其它设备连接的接口。输入输出接口6例如用于与键盘、鼠标81以及显示器71的连接。
[0134]
存储于程序存储器4的程序包括计算机可执行命令。程序(计算机可执行命令)当由作为处理电路的cpu2执行时,使计算机执行预定的处理。例如,程序当由cpu2执行时,使cpu2执行关于图1、图9、图11以及图16的各部分说明的一连串的处理。例如,程序中包含的计算机可执行命令当由cpu2执行时,使计算机执行差分抽取方法。差分抽取方法也可以包括与上述[1]~[4]的各功能对应的各步骤。另外,差分抽取方法也可以适当地包括图5、图10、图12以及图17所示的各步骤。
[0135]
程序可以在存储于计算机能够读取的存储介质的状态下提供给作为计算机的差分抽取装置1。在该情况下,例如,差分抽取装置1还具备从存储介质读出数据的驱动器(未图示),从存储介质获取程序。作为存储介质,例如能够适当地使用磁盘、光盘(cd-rom、cd-r、dvd-rom、dvd-r等)、光磁盘(mo等)、半导体存储器等。存储介质也可以称为非临时性的计算机能够读取的存储介质(non-transitory computer readable storage medium)。另外,也可以将程序保存于通信网络上的服务器,差分抽取装置1使用输入输出接口6从服务器下载程序。
[0136]
执行程序的处理电路不限于cpu2等通用硬件处理器,也可以使用asic(application specific integrated circuit,专用集成电路)等专用硬件处理器。处理电路(处理部)这样的词包括至少一个通用硬件处理器、至少一个专用硬件处理器或者至少一个通用硬件处理器与至少一个专用硬件处理器的组合。在图22所示的例子中,cpu2、ram3以及程序存储器4相当于处理电路。
[0137]
根据以上叙述的至少一个实施方式的装置、方法以及存储介质,获取记载有输入标记串的文本,将输入标记串变换为发音串,将发音串变换为输出标记串,比较输入标记串和输出标记串,抽取差分,从而能够防止未知词中的即使不登记也成为正确的标记的未知词的登记。
[0138]
此外,说明了本发明的几个实施方式,但这些实施方式是作为例子而提示的,未意图限定发明的范围。这些实施方式能够以其它各种方式被实施,能够在不脱离发明的要旨的范围进行各种省略、置换、变更。这些实施方式及其变形与包含于发明的范围、要旨同样地,包含于专利权利要求书所记载的发明及与其均等的范围。
[0139]
此外,能够将上述实施方式总结成以下的技术方案。
[0140]
(技术方案1)
[0141]
一种差分抽取装置,具备:
[0142]
文本获取部,获取记载有输入标记串的文本;
[0143]
发音串变换部,将所述输入标记串变换为发音串;
[0144]
标记串变换部,将所述发音串变换为输出标记串;以及
[0145]
比较部,比较所述输入标记串和所述输出标记串而抽取差分。
[0146]
(技术方案2)
[0147]
根据技术方案1所记载的差分抽取装置,其中,还具备:
[0148]
解析部,解析所述输入标记串;以及
[0149]
单词推测部,根据所述输入标记串的解析结果,推测所述输入标记串中的包含所述差分的单词候补的标记。
[0150]
(技术方案3)
[0151]
根据技术方案2所记载的差分抽取装置,其中,还具备:
[0152]
显示控制部,使包含所述单词候补的所述输入标记串显示于显示器;以及
[0153]
指示部,指示所述显示的所述输入标记串中的包含所述单词候补中的至少一部分的标记的范围。
[0154]
(技术方案4)
[0155]
根据技术方案2所记载的差分抽取装置,其中,
[0156]
所述差分抽取装置还具备单词种类判定部,该单词种类判定部判定所述单词候补的单词种类。
[0157]
(技术方案5)
[0158]
根据技术方案4所记载的差分抽取装置,其中,
[0159]
所述差分抽取装置还具备显示控制部,该显示控制部使包含所述单词候补的所述输入标记串显示于显示器,
[0160]
所述显示控制部使用与所述单词种类相应的显示属性使所述单词候补的标记显示于显示器。
[0161]
(技术方案6)
[0162]
根据技术方案3所记载的差分抽取装置,其中,
[0163]
所述差分抽取装置还具备单词登记部,该单词登记部将所指示的所述范围的标记登记于单词词典。
[0164]
(技术方案7)
[0165]
根据技术方案4所记载的差分抽取装置,其中,
[0166]
所述单词种类判定部具备未知词判定部,如果所述单词候补的标记未登记于单词词典,则该未知词判定部将该单词候补的标记判定为未知词。
[0167]
(技术方案8)
[0168]
根据技术方案4所记载的差分抽取装置,其中,
[0169]
所述单词种类判定部具备标记波动判定部,如果所述单词候补的标记和与该单词候补的标记对应的所述输出标记串内的标记是相同的单词的不同标记,则该标记波动判定部将作为该不同标记的两个标记判定为标记波动。
[0170]
(技术方案9)
[0171]
根据技术方案1所记载的差分抽取装置,其中,
[0172]
所述标记串变换部具备:
[0173]
特征量变换部,将所述发音串变换为声响得分矢量;
[0174]
存储部,存储有声音识别用的语言模型和单词词典;以及
[0175]
变换部,从所述声响得分矢量生成发音串,使用所述语言模型以及所述单词词典将该生成的发音串变换为所述输出标记串。
[0176]
(技术方案10)
[0177]
根据技术方案9所记载的差分抽取装置,其中,
[0178]
所述特征量变换部具备:
[0179]
声音合成部,从所述发音串合成声音信号;
[0180]
声响特征量计算部,根据所述声音信号计算声响特征矢量;以及
[0181]
声响得分计算部,根据所述声响特征矢量计算声响得分矢量。
[0182]
(技术方案11)
[0183]
根据技术方案1所记载的差分抽取装置,其中,
[0184]
所述发音串变换部具备:
[0185]
词素解析部,将所述输入标记串分割为单词,进行推测各单词的词类的词素解析;以及
[0186]
读音附加处理部,根据所述词素解析的结果,对所述各单词附加读音而变换为所述发音串。
[0187]
(技术方案12)
[0188]
一种差分抽取方法,具备:
[0189]
获取记载有输入标记串的文本;
[0190]
将所述输入标记串变换为发音串;
[0191]
将所述发音串变换为输出标记串;以及
[0192]
比较所述输入标记串和所述输出标记串而抽取差分。
[0193]
(技术方案13)
[0194]
一种存储介质,存储有用于使计算机实现如下功能的程序:
[0195]
获取记载有输入标记串的文本的功能;
[0196]
将所述输入标记串变换为发音串的功能;
[0197]
将所述发音串变换为输出标记串的功能;以及
[0198]
比较所述输入标记串和所述输出标记串而抽取差分的功能。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。