1.本发明涉及食品科学和人工智能领域,具体涉及一种改进模糊线性特征提取的红枣品种分类方法,应用于红枣品种分类。
背景技术:
2.我国是红枣的主要生产国和消费国。红枣营养价值极其丰富,其中包括糖、脂肪、有机酸、氨基酸、维生素、类黄酮和多种微量元素。随着中国人民生活水平的提高,人们越来越重视健康。同时红枣具有很高的营养价值,是集食用、药用、保健等功能于一体的干果,具有广阔的市场前景。众所周知,不同红枣的化学成分是不同的,甚至同一种红枣也可能含有不同的化学成分。人工鉴定红枣品种是一种常用的方法。工作人员可以根据红枣的颜色、味道、形状来鉴别红枣的品种。但该方法对识别人员要求较高,容易产生判断误差。此外,有些红枣的口味和形状非常相似。普通消费者很难对市场上的红枣进行准确的识别和分类。因此,有必要设计一种简单、快速、有效的红枣品种鉴定方法。
3.与传统方法相比,近红外光谱被认为是一种方便、快速、准确的检测方法技术。近红外区域主要分为两个区域:近红外短波(780-1100nm)和近红外长波(1100-2526nm)。近红外光谱属于分子振动光谱的倍频和主频吸收光谱。它主要发生在分子振动向基态跃迁到高能级时,由于分子振动共振,它具有很强的穿透能力。近红外光主要是含氢基团x-h(x=c,n,o)振动的倍频和组合频率吸收,它包含了大多数类型有机化合物的组成和分子结构信息。由于不同有机物含有不同基团,不同基团具有不同的能级,不同基团和同基团在不同的物理化学环境中对近红外光的吸收波长有明显差异,因此,近红外光谱可以作为获取信息的有效载体。
4.目前,许多模式识别算法已经应用到红枣的研究中,如pca lda、ulda、olda、nlda等。它们可用于光谱数据的特征提取。经典lda的目标是通过同时最小化类内距离和最大化类间距离来找到最优变换,从而达到最大的分辨,最优变换可以通过应用散射矩阵的特征分解来计算。但是在实际的应用中,往往会出现样本数量少于样本维数的现象,这样便会导致小样本问题。虽然改进的线性判别分析和改进的零空间线性判别分析可以处理这样的问题,但是仍然无法描述样本类信息多样性问题。因此,本发明在这两种特征提取的算法的基础上加入模糊集理论,提出一种改进模糊线性特征提取的红枣品种分类方法。
技术实现要素:
5.针对红枣样品数据小样本问题以及样本类信息多样性问题,研究设计了一种改进模糊线性特征提取的红枣品种分类方法。在使用基于模糊算法的改进的线性判别分析的特征提取算法时,解决了采集的红枣样品数据的小样本问题以及样本类信息多样性问题。同时,本发明还具有检测简便,分类准确率高以及绿色无污染的优点。
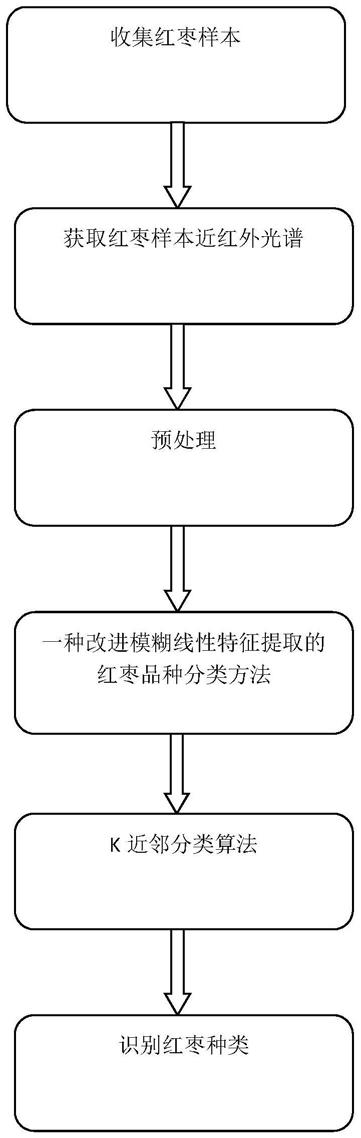
6.一种改进模糊线性特征提取的红枣品种分类方法,其步骤如下:
7.步骤一、提取红枣样品的近红外光谱数据;
8.步骤二、对获得的初始红枣近红外光谱数据进行预处理;
9.步骤三、对红枣近红外光谱数据进行降维处理。利用主成分分析(pca)将步骤二中预处理后的红枣近红外光谱数据进行压缩;
10.步骤四、利用一种改进模糊线性特征提取的红枣品种分类方法从经过预处理过的红枣近红外光谱数据中提取红枣品种的鉴别信息;
11.步骤五、使用分类器对红枣品种进行分类。
12.进行步骤一时为了获取红枣样品的近红外光数据,使用nir-m-r2便携式光谱仪采集红枣样品的近红外光谱数据。同时不仅要保证温度为25℃左右,湿度为50%左右的条件,而且采集红枣的近红外光谱数据前,开启光谱仪持续1小时,达到预热效果,这样保证了实验数据的准确性。最终每个红枣样品采集光谱的波长范围为900nm-1700nm,采集的红枣光谱数据维度为228;
13.进行步骤二即对红枣近红外光谱数据进行预处理,具体使用的是savitzky-golay fir平滑滤波器对收集的原始的红枣近红外光谱数据进行预处理。
14.进行步骤四即从降维后的红枣近红外光谱数据中提取红枣品种的鉴别信息,其具体过程如下:
15.(1)给定一个样品矩阵m为样本维数,n为样本数量,s
ft
,s
fb
,s
fw
分别为该训练样本集的模糊总体散射矩阵,模糊类间散射矩阵,模糊类内散射矩阵:
[0016][0017][0018][0019]
c为类别数,n是样本数据的数量,η为权重指数,u
ij
为数据点的模糊隶属度值,di是第i(i=1,2,
…
,n)个样本,所有样本的均值是vj表示第j(j=1,2,
…
,c)类样本在样本集中的均值;
[0020][0021]
初始模糊隶属度,为第i类的初始类中心值。
[0022]
(2)构造矩阵h
ft
,使其满足
[0023][0024][0025]
[0026][0027][0028][0029][0030][0031]
(3)定义矩阵b=(exp(s
fw
))-1
exp(s
fb
),其中exp(s
fw
)即使用exp函数:求矩阵中每个元素的e指数;
[0032]
(4)将矩阵b以b=uvu
t
进行特征值分解,u为b矩阵的特征向量,v为由特征向量对应的特征值组成的对角阵;
[0033]
(5)将u矩阵的前q列组成最终的特征投影矩阵w2,即w2=uq,其中q=c-1,w2为模糊改进的线性判别分析特征投影矩阵;
[0034]
(6)对矩阵h
ft
进行奇异值分解,h
ft
=g∑s
t
,其中g和s都为正交矩阵,g=[g
1 g2],t为矩阵h
ft
的秩;
[0035]
(7)构造矩阵(7)构造矩阵为矩阵g1的转置矩阵;
[0036]
(8)对矩阵进行特征分解.其中δw为非零特征值,矩阵w为特征值为零对应的特征向量,r为矩阵零空间的维数,w1为特征值非零对应的特征向量;
[0037]
(9)定义矩阵w3=g1w,w3为模糊改进的零空间线性判别分析特征投影矩阵。
[0038]
步骤五即对不同的红枣样品进行分类鉴别,应用k近邻分类算法(knn)将步骤四中蕴含红枣样本品种鉴别信息的测试样本分类,以实现对四种红枣的快速识别和分类。
[0039]
本发明的有益效果为:
[0040]
本发明是一种改进模糊线性特征提取的红枣品种分类方法,不仅克服了线性判别分析存在的小样本问题,还解决了样本类信息多样性问题。这项发明既可以用于对红枣品种的分类鉴别,还可以对其它食品的近红外光谱特征信息的提取以及分类。
附图说明
[0041]
图1是本发明的总体流程图;
[0042]
图2是原始的红枣近红外光谱图;
[0043]
图3是经过预处理后的红枣近红外光谱图;
[0044]
图4是经过基于改进模糊线性特征提取算法后得到的样本数据图;
[0045]
图5是经过基于改进模糊零空间线性特征提取算法后得到的样本数据图;
[0046]
图6是初始模糊隶属度图。
具体实施方式
[0047]
下面结合附图对本发明作进一步说明。
[0048]
如图1所示,本发明的具体操作步骤如下;
[0049]
步骤一、获得红枣样本的近红外光谱数据:收集山西,陕西,河南,河北四种产地的红枣,每种产地的红枣的样本数为60,一共240个红枣样本。所有红枣样本必须要保证大小一致均匀且还要保证其表面的整洁以及平整。在整个实验的过程中,还要保证实验室温度湿度等外界环境的恒定。光谱数据采集的具体步骤包括:第一,采集红枣近红外光谱数据前,开启便携式近红外光谱仪持续1小时,达到预热效果,以此保证实验数据的准确性;第二,每个红枣样品采集光谱的波长范围为900nm-1700nm,分辨率为10nm;第三,使用nir-m-r2便携式光谱仪采集红枣样品的近红外光谱数据,得到的红枣光谱数据维数为228。同时,为了以后实验的便利,每个红枣样本分别采集3次数据,取其平均值作为后续模型建立的实验数据。图2为原始的240个红枣样品的近红外光谱图。
[0050]
步骤二、对收集到的原始的红枣样品的近红外光谱进行预处理:本发明使用savitzky-golay fir平滑滤波器对收集的原始的红枣近红外光谱数据进行预处理,预处理后的光谱图如图3所示。
[0051]
步骤三、对红枣样本近红外光谱数据进行降维处理。利用主成分分析(pca)将预处理后的红枣近红外光谱数据进行压缩。
[0052]
将步骤二中的光谱用主成分分析计算特征值和特征向量,将特征值从大到小排列,取前9个最大特征值(分别为:52.1045,20.6989,0.4016,0.3003,0.0872,0.0338,0.0220,0.0047,0.0026)对应的9个特征向量,将240个红枣样本的近红外光谱数据投影到这9个特征向量上,从而将近红外光谱从228维压缩到9维。再将经过预处理后的红枣样本数据随机分配到两个样本集(训练集和测试集)中,在模糊改进的线性判别分析算法中,选取35个样本组成训练集,剩余25个样本则构成测试集;在模糊改进的零空间线性判别分析算法中,选取36个样本组成训练集,剩余24个样本则构成测试集。
[0053]
步骤四、采用特征提取算法对红枣光谱数据进行特征提取:利用改进模糊线性判别分析的特征提取算法从经过降维后的红枣近红外光谱数据中提取红枣品种的鉴别信息,得到包含鉴别信息的训练样本和测试样本,其中使用模糊改进的线性判别分析算法和模糊改进的零空间线性判别分析算法得到测试样本数据分别如图4,图5所示。
[0054]
进行步骤四即对降维后的红枣样品的分类鉴别信息进行提取,其具体过程如下:
[0055]
(1)给定一个样品矩阵样本维数m=228,样本数量n为240,s
ft
,s
fb
,s
fw
分别为该训练样本集的模糊总体散射矩阵、模糊类间散射矩阵、模糊类内散射矩阵:
[0056][0057][0058]
[0059]
类别数c为4,权重指数η为1.5,u
ij
为数据点的模糊隶属度值,如图6所示,di是第i(i=1,2,
…
,n)个样本,所有样本的均值是vj表示第j(j=1,2,
…
,c)类样本在样本集中的均值;
[0060][0061]
初始模糊隶属度,为第i类的初始类中心值。
[0062]
计算可得初始聚类中心:
[0063][0064]
(2)构造矩阵h
ft
,使其满足
[0065][0066][0067][0068][0069][0070][0071][0072][0073]
(3)定义矩阵b=(exp(s
fw
))-1
exp(s
fb
),其中exp(s
fw
)即使用exp函数:求矩阵中每个元素的e指数;
[0074]
计算得模糊类间散射矩阵、模糊类内散射矩阵、矩阵b分别为:
[0075][0076]
[0077][0078]
(4)将矩阵b以b=uvu
t
的形式进行特征值分解,u为b矩阵的特征向量,v为由特征向量对应的特征值组成的对角阵;
[0079]
计算得:
[0080][0081][0082]
(5)将u矩阵的前q列组成最终的特征投影矩阵w2,即w2=uq,其中q=c-1=3,w2为模糊改进的线性判别分析特征投影矩阵;
[0083]
计算可得模糊改进的线性判别分析特征投影矩阵分别为:
[0084][0085]
(6)对矩阵h
ft
进行奇异值分解,h
ft
=g∑s
t
,其中g和s都为正交矩阵,g=[g
1 g2],t为矩阵h
ft
的秩为115;
[0086]
计算得:
[0087][0088][0089][0090]
(7)构造矩阵(7)构造矩阵为矩阵g1的转置矩阵;
[0091]
计算可得模糊类内散射矩阵和构造的分别为:
[0092]
[0093][0094]
(8)对矩阵进行特征分解,其中δw为非零特征值,矩阵w为特征值为零对应的特征向量,r为矩阵零空间的维数,w1为非零特征值对应的特征向量;
[0095]
计算得矩阵w为:
[0096][0097]
(9)定义矩阵w3=g1w,w3为模糊改进的零空间线性判别分析特征投影矩阵。
[0098]
计算可得模糊改进的线性判别分析特征投影矩阵为:
[0099][0100]
步骤五、识别红枣样本的种类:应用k近邻分类算法(knn)将步骤四中蕴含红枣样本品种鉴别信息(本发明使用模糊隶属度作为鉴别信息)的测试样本分类,以实现对四种红枣的快速识别和分类。
[0101]
实验结果:当设置k近邻分类算法(knn)中的k值为6时,基于改进模糊线性特征提取算法的待测的红枣样本(测试集的红枣样本数量为100)的分类准确率达到95%,当设置k近邻分类算法(knn)中的k值为2时,基于改进模糊零空间线性判别分析算法的待测的红枣样本(测试集的红枣样本数量为96)的分类准确率达到93%。
[0102]
上文所列出的一系列的详细说明仅仅是针对本发明的可行性实施方式的具体说明,它们并非用以限制本发明的保护范围,凡未脱离本发明技术所创的等效方式或变更均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。