一种考虑时钟约束的超大规模异构fpga布局方法
技术领域
1.本发明涉及一种考虑时钟约束的超大规模异构fpga布局方法,属于fpga物理设计自动化技术领域。
背景技术:
2.现场可编程门阵列(fpga)是一种可重新编程以实现用户定制的逻辑器件。fpga作为一种集成电路,具有风险低、设计灵活性高的优点。与asic相比,fpga可以以较低的成本迅速进入市场,并适用于高端控制应用。fpga是半导体行业发展最快的领域之一,已成为学术界和工业界的研究热点。
3.为满足新兴的电路设计需求,fpga在架构上实现了创新演进。为了提高电路的集成度,现代fpga的逻辑块呈现出大规模和异构的特性。clb架构也变得更加复杂,它由多个ble组成,ble是由luts和ffs组成的逻辑单元。现代fpga中还嵌入了大量异构块,包括ram、dsp和其他ip。
4.此外,现代fpga通常会引进复杂的时钟架构来实现更高的性能需求。由于现代fpga的类asic的时钟架构有着严格的时钟约束,满足所有时钟约束成为一个严峻的挑战。传统的fpga布局算法很少考虑时钟的合法性,这往往会导致时序收敛和功耗不理想。因此,有必要在布局阶段考虑异构和时钟约束。
5.经典的fpga设计流程由hdl源代码的逻辑综合开始,经过物理设计(包括工艺映射、逻辑打包、布线布局等流程)后,最终生成比特流。物理设计是一个复杂的优化过程,直接影响了电路性能、面积、可靠性、功率和制造产量。随着芯片迈入百万门时代,fpga的结构复杂性和芯片规模不断扩大,这无疑给物理设计带来了巨大的挑战。
6.布局是物理设计中最重要、最耗时的优化步骤之一,它与后续的布线操作有着紧密的联系,可以显著影响fpga设计的效率和质量。随着集成电路的不断发展,fpga呈现出超大规模、异构性的特征,这给布局技术的提升带来严峻的考验。
技术实现要素:
7.本发明的目的是提供一种考虑时钟约束的超大规模异构fpga布局方法,以解决现有技术中fpga布局结果不佳的问题。
8.为实现上述目的,本发明采用的技术方案为:
9.一种考虑时钟约束的超大规模异构fpga布局方法,包括以下步骤:
10.步骤s1,根据给定的fpga网表和架构,采用连接感知和类型平衡的聚类方法来构建层级结构;
11.步骤s2,在每个层级中,采用混合惩罚增广拉格朗日方法将异构和时钟感知布局建模为一系列无约束优化子问题,并使用adam优化器求解每个无约束优化子问题;
12.步骤s3,解聚类后重复步骤s2直至最后一个层级;
13.步骤s4,执行基于匹配的时钟感知的ip块合法化来合法化dsp和ram;
14.步骤s5,采用多阶段封装策略得到hclb级网表;
15.步骤s6,执行时钟驱动的hclb级全局布局进一步提高布局质量;
16.步骤s7,采用基于历史的clb合法化方法来确保布局合法性。
17.所述步骤s1中两个模块/聚类bi和bj的聚类分数s
ctc
(bi,bj)定义为
[0018][0019]
其中η1和η2是两个常数,内部连接项w
int
、外部连接项w
ext
和类型平衡项w
bal
的具体定义如下:
[0020][0021][0022][0023]
其中n
ext
是包含bi或bj但没有两者的网络数量,而n
bal
是bi和bj中的lut和ff数量之差。
[0024]
所述步骤s2中需解约束优化问题
[0025][0026]
其中t={ff,lut,dsp,ram}是模块类型的集合,是近似于半周线长(hpwl)的平滑线长函数,f(x,y)是时钟围栏区域cost函数
[0027]
f(xi,yi)=fh(xi) fv(yi)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0028]
其中fh(xi)和fv(yi)分别给出了水平和垂直围栏区域cost,而fh(xi)定义为:
[0029][0030]
其中x
il
和x
ir
分别是模块i的围栏区域的左右边界坐标,我们可以类似地获得竖直方向cost函数fv(yi)。是计算bin b中类型为t∈t的模块的总面积的平滑密度函数,而是bin b中类型为t∈t的模块的最大允许面积。将式(5)转为无约束优化问题
[0031][0032]
其中λc是围栏区域函数的罚参数,λ
t
是类型t的模块密度函数的罚参数,是类型t的模块在bin b的拉格朗日乘子,ω
t
是类型t的模块的光滑因子参数;
[0033]
并使用如下方法来解该问题
[0034][0035]
上式中,o
t
是模块类型t的溢出率,用于衡量模块分布的均匀性。ω0和ω1是两个常数,并且ω
t
将随着模块的分散而减少(即随o
t
减少而减小)。
[0036]
所述步骤s5中多阶段封装分为如下步骤:
[0037]
(1)基于2引脚线网的lut-ff配对。一个个检查所有2引脚网络,如果一个lut只扇出到一个ff并且它们彼此距离很近,我们将它们配对在一起。
[0038]
(2)基于多引脚网络的lut-ff配对。此阶段提出了一种基于匹配的方法,以在多引脚网络中形成具有强连接性的lut-ff对。我们首先将每一个lut或ff作为一个顶点,一一检查多引脚网络。如果多引脚网络e中一个lutbi和一个ffbj之间的曼哈顿距离小于fpga的两个单元,那么bi和bj之间存在边,边权重设为其中|e|是网络连接到的模块数。在遍历所有多引脚网络后,构建了一个加权图。通过解决最大加权匹配问题,可以进一步形成一些lut-ff对,以减少外部线网的线长。
[0039]
(3)时钟感知ble封装。将一个lut-ff对、单个lut或单个ff均视为一个ble,然后,使用基于最佳选择聚类的时钟感知ble打包算法,以形成对hclb封装友好的ble。合并两个bles bi和bj的亲和度函数定义为:
[0040][0041]
其中e
i,j
是连接bi和bj的网络的集合,|e|是网络e中的模块数量,dist(bi,bj)是bi和bj之间的距离,而k1是定义的参数。我们凭经验设置k1=0.0001,因此dist(bi,bj)只是为了避免亲和度相等。
[0042]
(4)亲和感知hclb封装。应用最佳选择聚类来封装连接在相同线网上的hclb。合并两个hclbbi和bj的亲和度函数定义为:
[0043][0044]
其中area(bi)表示bi的面积,此步骤需确保每个hclb最多包含四个bles,这四个bles共享相同的clk和sr信号,并且最多有两个不同的ce信号。此外,还禁止长距离hclb合并。
[0045]
(5)距离驱动的hclb封装。将两个hclb之间的曼哈顿距离作为亲和度,并应用最佳选择聚类来封装hclb。
[0046]
(6)hclb封装后处理。如果hclb的数量仍然超过目标hclb站点容量,将进行此步骤,以进一步减少最终的hclb数量。首先构造一个加权图,其中一个顶点代表一个hclb,一条边代表一个合法的hclb合并。两个hclb之间的边权重是包含它们的网络数量。通过迭代执行基于最大加权匹配的hclb打包并逐渐放宽最大距离约束,直到满足hclb站点容量约束。
[0047]
所述步骤s7中,通过对迭代增加各溢出站点的cost与溢出半列的时钟cost,并将对应模块移除重新放置在cost最小的位置上,每经过一定的周期数增加一次搜索半径,最终将所有模块放置到合法位置。
[0048]
有益效果:本发明提供的一种考虑时钟约束的超大规模异构fpga布局方法能够有效提高考虑时钟约束的超大规模异构fpga的布局质量,减少布线线长,特别是对于设计规模较大,时钟数量较多时,能显著提高布局质量,进而改善fpga性能。
附图说明
[0049]
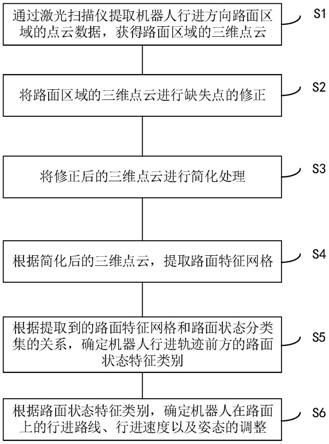
图1为本发明的一种考虑时钟约束的超大规模异构fpga布局方法的流程图;
[0050]
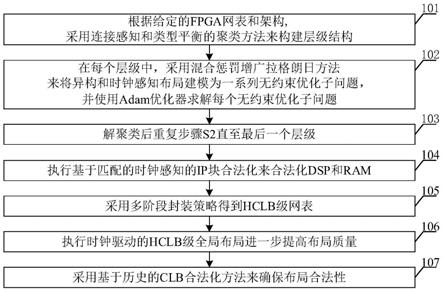
图2为本发明的基于历史的合法化算法。
具体实施方式
[0051]
下面结合附图对发明的技术方案进行详细说明。
[0052]
本发明提供一种考虑时钟约束的超大规模异构fpga布局方法,该方法首先根据给定网表与架构进行基于连接感知与类型平衡的聚类,然后使用考虑异构和时钟感知的混合惩罚增广拉格朗日方法与基于adam的优化器进行多级模块放置,再进行ip合法化与多阶段封装,最后进行clb级全局布局与clb合法化。如图1所示,该方法包括以下步骤:
[0053]
101,根据给定的fpga网表和架构,采用连接感知和类型平衡的聚类方法来构建层级结构;
[0054]
102,在每个层级中,采用混合惩罚增广拉格朗日方法将异构和时钟感知布局建模为一系列无约束优化子问题,并使用adam优化器求解每个无约束优化子问题;
[0055]
103,解聚类后重复步骤s2直至最后一个层级;
[0056]
104,执行基于匹配的时钟感知的ip块合法化来合法化dsp和ram;
[0057]
105,采用多阶段封装策略得到hclb级网表;
[0058]
106,执行时钟驱动的hclb级全局布局进一步提高布局质量;
[0059]
107,采用基于历史的clb合法化方法来确保布局合法性。
[0060]
101中两个模块/聚类bi和bj的聚类分数s
ctc
(bi,bj)定义为
[0061][0062]
其中η1和η2是两个常数,内部连接项w
int
、外部连接项w
ext
和类型平衡项w
bal
的具体定义如下:
[0063][0064][0065][0066]
其中n
ext
是包含bi或bj但没有两者的网络数量,而n
bal
是bi和bj中的lut和ff数量之差。
[0067]
102中需解约束优化问题
[0068][0069]
其中t={ff,lut,dsp,ram}是模块类型的集合,是近似于半周线长(hpwl)的平滑线长函数,f(x,y)是时钟围栏区域cost函数
[0070]
f(xi,yi)=fh(xi) fv(yi)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0071]
其中fh(xi)和fv(yi)分别给出了水平和垂直围栏区域cost,而fh(xi)定义为:
[0072][0073]
其中x
il
和x
ir
分别是模块i的围栏区域的左右边界坐标,我们可以类似地获得竖直方向cost函数fv(yi)。是计算bin b中类型为t∈t的模块的总面积的平滑密度函数,而是bin b中类型为t∈t的模块的最大允许面积。通过将式(5)转为无约束优化问题
[0074][0075]
并使用如下方法来解该问题
[0076][0077]
上式中,o
t
是模块类型t的溢出率,用于衡量模块分布的均匀性。ω0和ω1是两个常
数,并且ω
t
将随着模块的分散而减少(即随o
t
减少而减小)。
[0078]
105中多阶段封装分为如下步骤:
[0079]
(1)基于2引脚线网的lut-ff配对。一个个检查所有2引脚网络,如果一个lut只扇出到一个ff并且它们彼此距离很近,我们将它们配对在一起。
[0080]
(2)基于多引脚网络的lut-ff配对。此阶段提出了一种基于匹配的方法,以在多引脚网络中形成具有强连接性的lut-ff对。我们首先将每一个lut或ff作为一个顶点,一一检查多引脚网络。如果多引脚网络e中一个lutbi和一个ffbj之间的曼哈顿距离小于fpga的两个单元,那么bi和bj之间存在边,边权重设为其中|e|是网络连接到的模块数。在遍历所有多引脚网络后,构建了一个加权图。通过解决最大加权匹配问题,可以进一步形成一些lut-ff对,以减少外部线网的线长。
[0081]
(3)时钟感知ble封装。将一个lut-ff对、单个lut或单个ff均视为一个ble,然后,使用基于最佳选择聚类的时钟感知ble打包算法,以形成对hclb封装友好的ble。合并两个bles bi和bj的亲和度函数定义为:
[0082][0083]
其中e
i,j
是连接bi和bj的网络的集合,|e|是网络e中的模块数量,dist(bi,bj)是bi和bj之间的距离,而k1是定义的参数。我们凭经验设置k1=0.0001,因此dist(bi,bj)只是为了避免亲和度相等。
[0084]
(4)亲和感知hclb封装。应用最佳选择聚类来封装连接在相同线网上的hclb。合并两个hclbbi和bj的亲和度函数定义为:
[0085][0086]
此步骤需确保每个hclb最多包含四个bles,这四个bles共享相同的clk和sr信号,并且最多有两个不同的ce信号。此外,还禁止长距离hclb合并。
[0087]
(5)距离驱动的hclb封装。将两个hclb之间的曼哈顿距离作为亲和度,并应用最佳选择聚类来封装hclb。
[0088]
(6)hclb封装后处理。如果hclb的数量仍然超过目标hclb站点容量,将进行此步骤,以进一步减少最终的hclb数量。首先构造一个加权图,其中一个顶点代表一个hclb,一条边代表一个合法的hclb合并。两个hclb之间的边权重是包含它们的网络数量。通过迭代执行基于最大加权匹配的hclb打包并逐渐放宽最大距离约束,直到满足hclb站点容量约束。
[0089]
107中,通过对迭代增加各溢出站点的cost与溢出半列的时钟cost,并进行移除重放,最终将所有模块放置到合法位置。具体步骤如图2所示,其中b为整个fpga中所有hclb的集合,s为clb站点的集合(即slices);hc为半列的集合;clkb为连接到模块b的所有线网的集合,clk
hc
为连接到半列hc的所有线网的集合,clb为模块b所有候选位置的集合,为模块b的初始位置,第1行初始化未放置的块ub、当前迭代次
数iter和搜索半径sr。在第3-8行,我们每100次迭代扩展sr并更新模块的候选位置。第6行的函数不仅确定初始位置在距离sr内的候选位置,还符合clkb对应的时钟栅栏区域。因此,我们可以保证每个时钟区域最多包含24个时钟线网。在第10行,函数getmincostpos(clb)从clb中选择总cost最小的位置。将模块b放置到站点s的总cost定义如下:
[0090]
cost(b,s)=η3cost
wl
(b,s) η4costd(b,s) η5cost
lr
(s) η6cost
cr
(b,s)
ꢀꢀꢀꢀ
(12)
[0091]
其中cost
wl
(b,s)是计算放置模块b到站点s的hpwl,costd(b,s)是计算初始位置与站点s之间的曼哈顿距离,cost
lr
(s)是逻辑资源成本,cost
cr
(b,s)是时钟资源成本,η3、η4、η5和η6是权重。
[0092]
站点s的逻辑资源cost定义为:
[0093]
cost
lr
(s)=hs·
psꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0094]
其中hs和ps分别代表使用站点s的历史和当前罚值。它们的具体定义如下:
[0095]hs
=hs (usg
s-caps)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
[0096][0097]
其中η7是一个常数,usgs是站点s中的模块数量,容量caps设置为2,因为每个站点最多可以包含两个hclb。hs与站点s的违规历史有关。如果s在之前的迭代中频繁违规,hs将快速增加以阻止我们将模块分配给站点s,从而为选择较少的块保留站点s的逻辑资源。
[0098]
由于我们已经确保每个候选站点cl∈clb都位于相应的时钟围栏区域内,因此我们只需要进一步考虑半列约束。因此,我们定义时钟资源cost如下:
[0099][0100]
其中hcs是站点s所属的半列。此外,在半列hc中加入时钟线网c的cost定义如下:
[0101][0102]
其中oc是时钟c的序数,根据时钟c在半列hc内连接模块的数量,将所有时钟降序排列得到。是hc内与序数oc的时钟相连的模块数量,而n
11
是序数为11的对应值。对于c∈clk
hc
的情况,如果|clk
hc
|≤12,则设置为0,因为在hc上添加c不需要占用额外的时钟资源;否则,我们将倾向于将在hc内连接模块较少的时钟移出hc。对于|clk
hc
|<12表示有足够的时钟资源将c加到hc上,因此被设置为1;如果|clk
hc
|≥12,我们将设置为∞,因为没有额外的时钟资源让c添加到hc上。
[0103]
在图2第13-18行,我们更新cost
lr
(s)并收集违反每个站点逻辑资源的模块。在图2第16行,函数rmblkinsite(s)收集并移除放置在站点s中的模块。在图2第19-26行,我们更
新并收集每个半列中违反半列约束的模块。在图2第24行,函数rmblkwithclockv(hico)收集并移除连接到序数o>11时钟的连接到的模块。
[0104]
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。