1.本发明属于多传感器数据融合技术领域,特别涉及一种多尺度异源特征自适应融合的三维目标检测方法,可应用于机器人导航、三维建模、自动驾驶与虚拟现实。
背景技术:
2.激光雷达和相机是智能车和机器人上最常见的传感器,对两者获取的点云和图像数据的处理决定了智能终端的智能化程度。然而,每个传感器既有自身优势,也纯在天然缺陷,点云包含精确的空间距离信息,但是数据很稀疏,缺乏颜色信息,受雨雾天气的影响大;图像具有高分辨率像素和丰富的纹理,但是无法获取物体之间的精确距离。因此,两者的优势互补,能够更好的帮助智能终端感知外部环境。因此,点云和图像的融合在智能化设备领域得到了充分的利用。
3.三维目标的检测是一种对三维空间目标进行三维检测的任务,其作为众多领域的重要应用,近年来受到了广泛的关注。随着神经网络的不断发展,基于深度学习的融合点云和图像数据的三维目标检测方法已成为了学界的研究热点,例如,vora s等人发表的名称为“pointpainting:sequential fusion for 3d object detection”(cvpr2020)的论文中,使用图像语义分割后的信息辅助进行点云的三维目标检测,能够充分利用目标的语义信息,获得了很好的检测性能,然而,由于图像语义分割的结果将直接影响三维检测结果,鲁棒性差;史少帅等人发表的名称为“pv-rcnn:point-voxel feature set abstraction for 3d object detection”(cvpr2020)的论文中,使用体素特征融合点特征的方法,平衡了两种方法之间关于计算量大和空间特征信息丢失带来的问题,然而,此方法依旧存在单传感器对低分辨率目标的检测低的问题。
4.为了避免单一特征带来不足,引入了异源特征融合。异源特征融合就是将不同表征形式的特征进行融合,实质上就是通过组合不同特征带来的优势来提高三维目标检测的精度,例如申请公布号为cn111209840a的专利申请文献公开了一种基于多传感器数据融合的3d目标检测方法,其实现步骤为:1)分别利用两个神经网络对点云和图像进行逐点和逐像素的特征提取,在点云的前景点上进行区域建议。2)利用传感器的标定矩阵实现两种异质传感器数据的逐点关联,实现最大程度上的关联。3)最后利用一个神经网络对每一个区域的联合特征表示进行自适应的融合,并根据融合后的区域特征直接进行进一步得精细化调整。本发明虽然通过神经网络自适应地融合两类传感器数据特征,克服了点云数据稀疏和图像数据没有深度信息等不足,但是没有改变基于点的特征提取带来的大计算量和图像特征提取阶段与任务弱相关的问题。
技术实现要素:
5.本发明的目的在于克服上述现有技术存在的缺陷,提出一种基于多尺度异源特征自适应融合的三维目标检测方法,以提高检测精度。
6.为实现上述目的,本发明的技术方案包括如下:
7.(1)从公开数据集中获取包括训练样本集e1和测试样本集e2,每个样本包括lidar点云、rgb图像和三维目标的标注信息;
8.(2)构建包括异源特征融合模块和关键点权重估计模块的异源特征融合网络,其中,异源特征融合模块用于不同模态数据的多尺度特征融合,权重估计模块用于特征融合后关键点的权重估计;
9.(3)构建由异源特征编码模块、异源特征融合网络、三维候选框估计模块和输出层依次连接构成的三维目标检测模型t,其中:
10.所述异源特征编码模块,包括顺次连接的三维体素特征编码模块、图像特征编码模块,该体素特征编码模块用于多尺度体素空间特征的提取,该图像特征编码模块用于多尺度图像语义特征的提取;
11.所述三维候选框估计模块用于对三维目标的姿态信息进行粗估计,该姿态信息包括三维目标外接立方体的空间坐标、尺度和旋转角;
12.所述输出层用于对融合特征后关键点的池化及三维目标框的精确回归;
13.(4)利用训练样本集e1,采用梯度下降法对三维目标检测模型t进行训练,得到训练好的目标检测模型t
*
;
14.(5)将测试样本集e2输入到训练好的目标检测模型t
*
进行前向传播,得到三维目标检测结果。
15.本发明与现有的技术相比,具有以下优点:
16.第一,本发明将点云的体素特征、图像的语义特征和点特征经过多尺度的级联方式进行了融合,充分利用了体素特征的规则化空间位置信息、图像特征的语义信息和点特征的精细化空间结构信息,提升了三维目标的检测性能和检测精度。
17.第二,本发明由于使用端到端训练的网络结构,充分耦合了不同特征编码网络的网络结构,有效地提高了不同特征融合的协同性。
附图说明
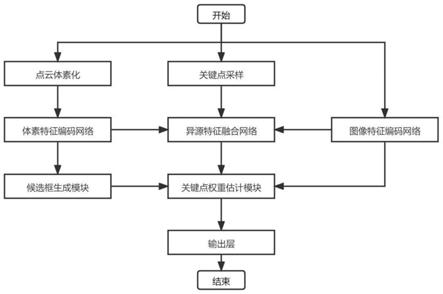
18.图1是本发明的实现流程图;
19.图2是本发明中构建的特征融合层结构图;
20.图3是本发明中构建的异源特征融合网络模型图;
21.图4是本发明中构建的关键点权重估计网络模型图;
22.图5是用本发明对点云数据进行三维目标检测的仿真结果图。
具体实施方式
23.以下结合附图对本发明的实施例和效果作进一步的详细说明。
24.参照图1,本实例的实现步骤包括如下:
25.步骤1:建立训练样本集和测试样本集;
26.从公开数据集kitti中获取包括7481个样本的训练样本集e1和包括7518个样本的测试样本集e2,每个样本包括lidar点云、rgb图像和三维目标的标注信息;
27.步骤2:预处理样本中的点云数据,得到体素集合v和关键点集合p。
28.2.1)设置点云筛选范围长(0,70)米、宽(-40,40)米、高(-1,3)米,将符合筛选范围
的点云提取出来,得到点云集合p
raw
,大小为s*3,s表示p
raw
中点云的个数;
29.2.2)设置体素长0.05米、宽0.05米、高0.01米,将点云集合p
raw
按照体素大小划分,并将划分后的每个体素内包含的点云进行平均池化,得到体素集合v,v的大小为1600
×
1600
×
80
×
3;
30.2.3)采用随机采样法从点云集合p
raw
中随机采样n个关键点,构成关键点集合p,p的大小为n
×
3。
31.步骤3:构建三维体素特征编码模块,将步骤2得到的体素集合v作为体素特征编码模块的输入,得到体素特征图集合v1。
32.3.1)建立6个三维稀疏卷积层,其中:
33.第1、第2个三维稀疏卷积层的卷积核大小均为3
×3×
3,卷积核个数均为16,步长均为(1,1,1);
34.第3、第4、第5个三维稀疏卷积层的卷积核大小均3
×3×
3,步长均为(2,2,2),积核个数分别为32、64、64;
35.第6三维稀疏卷积层的卷积核大小为3
×1×
1,卷积核个数为128,步长(2,1,1);
36.3.2)建立6个归一化层,其输入通道数分别为16、16、32、64、64、128;
37.3.3)建立6个relu激活层,其表达式为x表示输入,f(x)表示输出;
38.3.4)将以上所述6个三维稀疏卷积层、6个归一化层、6个relu激活层进行连接构成三维体素特征编码模块,其连接关系为:
39.第1三维稀疏卷积层-》第1归一化层-》第1个relu激活层-》第2三维稀疏卷积层-》第2归一化层-》第2relu激活层-》第3三维稀疏卷积层-》第3归一化层-》第3relu激活层-》第4三维稀疏卷积层-》第4归一化层-》第4relu激活层-》第5三维稀疏卷积层-》第5归一化层-》第5relu激活层-》第6三维稀疏卷积-》第6归一化层-》第6relu激活层;
40.3.5)将步骤2.2)得到的体素集合v作为三维体素特征编码模块的输入,把第2、第3、第4、第5、第6relu激活层的输出结果保存,构成体素特征图集合3、第4、第5、第6relu激活层的输出结果保存,构成体素特征图集合表示第a体素特征图。
41.步骤4:构建三维候选框估计模块,将步骤3得到体素特征图集合v1作为三维候选框估计模块的输入,得到三维候选框集合b
rpn
并计算三维候选框估计损失值l
rpn
。
42.4.1)建立4个卷积层,其中:
43.第1卷积层的卷积核大小为3,卷积核个数为256,步长为2;
44.第2、第3、第4个卷积层的卷积核大小为3,卷积核个数为256,步长为1;
45.4.2)建立4个归一化层,其输入通道数分别为128、256、256、256;
46.4.3)建立4个relu激活层,其表达式为x表示输入,f(x)表示输出;
47.4.4)建立2个全连接层,其输出通道数分别为18和42;
48.4.5)将上述4个卷积层、4个归一化层、4个relu激活层和2个全连接层进行如下连
接,构成三维候选框估计模块:
49.第1卷积层、第1归一化层、第1relu激活层、第2卷积层、第2归一化层、第2relu激活层、第3卷积层、第3归一化层、第3relu激活层、第4卷积层、第4归一化层、第4relu激活层依次级联,并将第1全连接层和第2全连接层分别与第4relu激活层连接;
50.4.6)将步骤3.5)得到体素特征图集合v1中的中的第5体素特征图作为三维候选框估计模块的输入,输出m个包含类别置信度和姿态信息的三维候选框,构成三维候选框集合合表示第m个三维候选框的信息;
51.4.7)计算三维候选框估计损失值l
rpn
:
52.4.7.1)采用交叉熵损失函数计算第m个三维候选框的类别损失值
[0053][0054]
其中,表示第m个三维候选框的类别概率值,ym表示第m个三维候选框的真实类别值;
[0055]
4.7.2)采用smooth-l1损失函数计算三维候选框的总损失值l
rpn
:
[0056][0057]
其中,m表示b
rpn
中三维候选框的个数,表示第m个三维候选框的预测偏移量,表示第m个三维候选框相对于真实目标框的偏移量,β表示权重超参数。
[0058]
步骤5:构建图像特征编码模块,将样本中的图像作为图像特征编码模块的输入,得到图像特征图集合f1。
[0059]
5.1)设置输入卷积层,其卷积核大小为7,卷积个数为64,步长为2,填充大小3;
[0060]
5.2)设置归一化层,其输入通道数为64;
[0061]
5.3)设置relu激活层,其表达式为x表示输入,f(x)表示输出;
[0062]
5.4)设置最大池化层,其卷积核大小为3,步长为2;
[0063]
5.5)设置4个残差模块,这4个残差模块的输出通道数分别为256、512、1024、2048;
[0064]
5.6)将上述输入卷积层、归一化层、relu激活层、最大池化层和4个残差模块依次级连构成图像特征编码模块,其连接关系为:
[0065]
输入卷积层-》归一化层-》relu激活层-》最大池化层-》第1残差模块-》第2残差模块-》第3残差模块-》第4残差模块;
[0066]
5.7)将样本中的图像作为图像特征编码模块的输入,把第1、第2、第3、第4残差块的输出结果保存,构成图像特征图集合表示第c体素特征图。
[0067]
步骤6:构建异源特征融合模块,将步骤3得到体素特征图集合v1、步骤5得到图像特征图集合f1和步骤2得到关键点集合p作为异源特征融合模块的输入,得到特征融合后的关键点集合p1。
[0068]
6.1)建立特征映射层,表达式为其中,r表示从样本标注信息中获取的点云空间到图像空间的转换矩阵,p
×
r表示关键点集合p经过r转换以后在图像空间中的二维坐标,表示第c个图像特征图,pc(p)表示关键点集合p中所有关键点在图像特征图集合f1的第c图像特征图中相应坐标位置的特征向量集合;
[0069]
6.2)建立第一特征融合层;
[0070]
设置输出通道分别为64、128、256的三个全连接层、输出通道分别为19、259、192的三个拼接层和输出为p1(p)的特征映射层,将这三个全连接层、三个拼接层和一个特征映射层进行连接构成第一特征融合层,其连接关系为:
[0071]
将特征映射层、第一特征拼接层、第一全连接层依次级连,将第二特征拼接层、第二全连接层依次连接,第一全连接层和第二全连接层分别和第三特征拼接层连接,将第三特征拼接层、第三全连接层依次连接,如图2所示;
[0072]
6.3)建立第二特征融合层,
[0073]
设置输出通道分别为256、512、512的三个全连接层、输出通道分别为288、
[0074]
768、768的三个拼接层和输出为p2(p)的特征映射层,将这三个全连接层、三个拼接层和一个特征映射层按照与第一特征融合层相同的连接关系构成第二特征融合层,如图2所示;
[0075]
6.4)建立第三特征融合层;
[0076]
设置输出通道分别为512、1024、1024的三个全连接层、输出通道分别为578、
[0077]
1536、1536的三个拼接层和输出为p3(p)的特征映射层,将这三个全连接层、三个拼接层和一个特征映射层按照与第一特征融合层相同的连接关系构成第三特征融合层,如图2所示;
[0078]
6.5)建立第四特征融合层;
[0079]
设置输出通道分别为1024、2048、2048的三个全连接层、输出通道分别为1088、3092、3092的三个拼接层和输出为p4(p)的特征映射层,将这三个全连接层、三个拼接层和一个特征映射层按照与第一特征融合层相同的连接关系构成第四特征融合层,如图2所示;
[0080]
6.6)将第一特征融合层、第二特征融合层、第三特征融合层、第四特征融合层依次级连构成异源特征融合模块,如图3所示;
[0081]
6.7)将步骤3.5)得到体素特征图集合v1、步骤5.7)得到图像特征图集合f1和步骤2.3)得到关键点集合p作为异源特征融合模块的输入,结果为2048个融合了图像特征、体素特征和关键点特征的关键点,构成特征融合后的关键点集合
[0082]
步骤7:构建关键点权重估计模块,将步骤5得到的图像特征图和步骤6得到的特征融合后的关键点集合p1作为关键点权重估计模块的输入,得到特征融合后的前景关键点集合p2并计算其二分类损失值l
seg
。
[0083]
7.1)建立两个卷积层,其卷积核大小均为1,卷积核个数均为2;
[0084]
7.2)建立两个反卷积层,其中:
[0085]
第1反卷积层的卷积核大小为32,卷积核个数为2,步长为16;
[0086]
第2反卷积层的卷积核大小为64,卷积核个数为2,步长为32;
[0087]
7.3)建立两个全连接层,其输出通道数均为2;
[0088]
7.4)建立一个特征拼接层,其输出通道数为2;
[0089]
7.5)建立一个softmax层,其表达式为其中u表示输入,g(u)表示输出;
[0090]
7.6)将上述两个卷积层、两个反卷积层、两个全连接层、一个特征拼接层和softmax层进行如下连接,构成关键点权重估计模块:
[0091]
将第1全连接层、第1反卷积层、第1卷积层依次级连,1卷积层和第2全连接层分别与第1特征拼接层连接,将第1特征拼接层、第2反卷积层、第2卷积层、softmax层依次级连,如图4所示;
[0092]
7.7)将步骤5.7)得到的图像特征图集合f1中的第2特征图和第4特征图作为关键点权重估计模块的输入,对图像中的像素进了二分类,得到二值图f;
[0093]
7.8)根据转换矩阵r,计算关键点集合p中所有关键点在f中相应坐标位置的分类结果其中,表示p中第n个关键点的分类结果,取p中结果值为1的关键点成为前景关键点,构成前景关键点集合其中,表示第w个前景关键点;
[0094]
7.9)计算p
front
和p1的交集,得到特征融合后的前景关键点集合:其中,表示第w个特征融合后的前景关键点;
[0095]
7.10)采用交叉熵损失函数计算关键点集合p的二分类损失值:其中,n表示关键点集合p中关键点个数,表示像素的类别预测概率值,yn表示像素的真实类别值。
[0096]
步骤8:构建输出层,将步骤4得到三维候选框集合b
rpn
和步骤7得到特征融合后的前景关键点集合p2作为输出层的输入,得到最终预测的三维目标框集合b
out
并计算其预测损失值l
rcnn
。
[0097]
8.1)建立2个卷积层,其中:
[0098]
第1卷积层的卷积核大小为1,卷积核个数为1024,步长为1;
[0099]
第2卷积层的卷积核大小为1,卷积核个数为512,步长为2;
[0100]
8.2)建立最大池化层,其卷积核大小为216*1,步长为1;
[0101]
8.3)建立2个全连接层,其输出通道数分别为1和7;
[0102]
8.4)将上述第一卷积层、第二卷积层、最大池化层依次级联,且第一全连接层和第二全连接层分别与最大池化层连接,构成输出层;
[0103]
8.5)将步骤4.6)得到三维候选框集合b
rpn
和步骤7.8)得到特征融合后的前景关键点集合p2作为输出层的输入,输出k个包含类别信息和姿态信息的三维目标框,构成三维目标框集合其中表示第k个预测的三维目标框;
[0104]
8.6)计算三维目标框预测损失值l
rcnn
:
[0105]
8.6.1)采用交叉熵损失函数计算第k个预测的三维目标框的类别损失值
[0106][0107]
其中,表示第k个预测的三维目标框的类别概率值,yk表示第k个预测的三维目标框的真实类别值;
[0108]
8.6.2)采用smooth-l1损失函数计算预测的三维目标框的总损失值l
rcnn
:
[0109][0110]
其中,k表示b
out
中预测得到的三维目标框的个数,表示第k个预测的三维目标框偏移量,表示第k个预测的三维目标框相对于真实的三维目标框的偏移量。
[0111]
步骤9:构建基于多尺度异源特征自适应融合的三维目标检测模型t,利用梯度下降法对其进行训练得到训练好的三维目标检测模型。
[0112]
9.1)设置初始化迭代次数为i,最大迭代次数为i,i≥100,第i次迭代的三维目标检测模型为ti,ti的权值参数为ωi,并令i=1,ti=t;
[0113]
9.2)将训练样本集e1输入到基于多尺度异源特征自适应融合的三维目标检测模型t中;
[0114]
9.3)使用步骤4)得到的损失值l
rpn
、步骤7)得到的损失值l
rcnn
和步骤8)得到的损失值l
rcnn
,采用加权求和的方式计算第i次迭代的三维目标检测模型的总损失值li:
[0115][0116]
其中,表示l
rpn
的权重超参数,γ表示l
seg
的权重超参数;
[0117]
9.4)根据总损失值li,采用反向传播的方法,更新网络参数ωi,得到第i次的目标
[0118]
检测模型ti,ωi的更新公式如下:
[0119][0120]
其中,ω
*
表示ωi的更新结果,η表示l的学习率,表示求导操作;
[0121]
9.5)判断i≥i是否成立,若是,则得到训练好的三维目标检测模型t
*
,否则,令i=i 1,返回9.2)。
[0122]
步骤10:将测试集e2输入到训练好的模型t
*
,得到最终的三维目标检测结果,计算检测精度。
[0123]
下面结合仿真实验,对本发明的技术效果作进一步的描述。
[0124]
1.仿真条件:
[0125]
仿真实验使用的硬件平台为nvidia rtx2080*2,12g ram;软件平台为python3.8,操作系统为ubuntu 18.04。
[0126]
仿真实验中用到的数据集为kitti数据集,该数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合制作的汽车传感器数据,单帧点云数为60000多,图像大小为1243
×
375,包含3类目标,分别为汽车、非机动车和行人,仿真实验中选取7518个样本作为测试样本。
[0127]
2.仿真内容:
[0128]
分别使用现有pv-rcnn网络模型和本发明基于多尺度异源特征自适应融合的三维目标检测方法对kiti数据集进行三维目标检测,结果如图5,其中:
[0129]
图5(a)为使用现有pv-rcnn网络模型的检测结果;
[0130]
图5(b)为使用本发明方法的检测结果。
[0131]
对比图5(a)和图5(b)的检测结果图可以看出,相比于pv-rcnn网络模型的检测结果,本发明方法对于非机动车、行人和远景车辆等低分辨率物体具有更好的检测效果,表明本发明的方法具有更好的检测精度。
[0132]
利用各类别精度ap和平均精度map这两个评价指标对检测结果进行评价,当交并比阈值为0.5和样例难度为中等时,得到每类目标的检测精度ap和平均检测精度map,结果如表1。
[0133]
表1 交并比阈值为0.5时各类别检测精度比较
[0134]
评价指标汽车非机动车行人map本发明88.5362.7365.8972.38pv-rcnn80.4162.7125.7256.28
[0135]
从表1的实验结果中可以看出,相对于现有技术,本发明对每类目标的检测精度有明显的提高,且本发明相对于pv-rcnn方法,平均检测精度map提高了16.10%。
[0136]
综上,本发明基于多尺度异源特征自适应融合的三维目标检测方法,有效融合了各种数据特征的优势,获得了较好的三维检测效果。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。