技术特征:
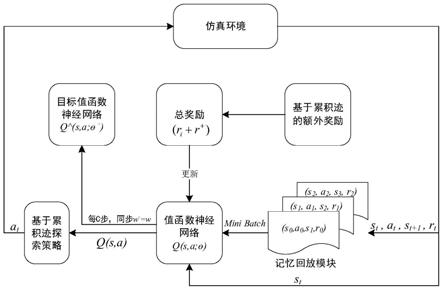
1.基于累积迹强化学习的多机器人协同搜索方法,其特征在于,包括以下步骤:步骤1:根据任务确定多目标各时刻对应的状态和动作;步骤2:初始化神经网络和目标神经网络,将神经网络与目标神经网络的神经元参数设为相同;设定奖励因子、折扣系数以及各动作对应的奖惩量;步骤3:根据当前时刻的状态s
t
选择动作a
t
;执行动作a
t
,确定对应的奖惩量r
t
以及下一时刻的状态s
t 1
,获得包括当前状态s
t
、选择的动作a
t
、奖惩量r
t
以及下一时刻状态的状态s
t 1
的状态动作对数据(s
t
,a
t
,r
t
,s
t 1
),并将状态动作对(s
t
,a
t
)的访问次数加1;重复执行步骤3直至获得特定数量的状态动作对数据;步骤4:从获得的特定数量的状态动作对数据中选择设定个数n的状态动作对数据;针对选定的每个动作状态对数据,基于预设的奖励因子以及各状态动作对的访问次数计算该状态动作对的额外奖励;基于获得的额外奖励、所述折扣系数以及状态动作对数据中的奖惩量计算目标神经网络的输出量;计算目标神经网络的输出量与神经网络的输出量之间的误差,并根据随机梯度下降更新神经网络的神经元参数;设定步数后将神经网络与目标神经网络的神经元参数设为相同;步骤5:返回步骤3直至神经网络收敛,结束训练得到神经网络策略模型;步骤6:根据神经网络策略模型得到多机器人协同搜索策略,生成多机器人目标协同搜索方法。2.根据权利要求1所述的基于累积迹强化学习的多机器人协同搜索方法,其特征在于,根据当前时刻的状态选择动作的具体方法如下:产生随机数,将产生的随机数与预设阈值比较;若随机数小于预设阈值,则计算动作集中除去当前时刻的状态下使神经网络值最大时选择的动作以外的其它动作的选择概率,确定选择概率最大的动作并选择该动作;若所述随机数大于等于预设阈值,则选择当前时刻的状态下使神经网络值最大时选择的动作,表达式如下:其中表示当前时刻的状态s
t
下使神经网络值最大时选择的动作a,θ为目标神经网络的神经元参数,a为动作集。3.根据权利要求2所述的基于累积迹强化学习的多机器人协同搜索方法,其特征在于,动作a
j
的选择概率的计算方法如下:其中prob(a
j
)表示选择动作a
j
的选择概率;t表示温度大小,count(s,a
j
)表示状态动作对(s,a
j
)的访问次数,也就是在状态s下选择动作a
j
的次数,count(s,a
k
)表示状态动作对(s,a
k
)的访问次数,也就是在状态s下选择动作a
k
的次数,k为动作的索引,其取值范围为动作集a中所有的动作数目。4.根据权利要求3所述的基于累积迹强化学习的多机器人协同搜索方法,其特征在于,产生的随机数范围为0到1,所述预设阈值为0.5。
5.根据权利要求1所述的基于累积迹强化学习的多机器人协同搜索方法,其特征在于,基于选择的设定个数n个的动作状态对,针对每个动作状态对数据,基于预设的奖励因子以及各状态动作对的访问次数计算该状态动作对的额外奖励的具体方法包括:其中r
为额外奖励,β为奖励因子,i=1,2
…
n,count(s
i
,a
i
)表示状态动作对(s
i
,a
i
)的访问次数。6.根据权利要求1所述的基于累积迹强化学习的多机器人协同搜索方法,其特征在于,基于获得的额外奖励、所述折扣系数以及状态动作对中的奖惩量计算目标神经网络的输出量y
i
的方法如下:若状态动作对(s
i
,a
i
)是选择的最后一个状态动作对,则将该状态动作对应的奖惩量r
i
作为目标神经网络的输出量y
i
;表达式为:y
i
=r
i
;若状态动作对不是选择的最后一个状态动作对,则按照以下公式计算目标神经网络的输出量y
i
:其中i=1,2
…
n,r
为额外奖励,β为奖励因子,γ为折扣系数,表示在状态s
i 1
下评估目标神经网络输出的各个动作所对应的q值中最大的那个q值;θ-表示目标神经网络的神经元参数,a为动作集。7.根据权利要求1所述的基于累积迹强化学习的多机器人协同搜索方法,其特征在于,计算目标神经网络的输出量与神经网络的输出量之间的误差error的公式如下:其中i=1,2
…
n,y
i
为目标神经网络在状态动作对(s
i
,a
i
)下的输出,q(s
i
,a
i
;θ)为神经网络在状态动作对(s
i
,a
i
)下的输出。
技术总结
本发明提出了一种基于累积迹强化学习的多机器人协同搜索方法,对智能体访问过的状态动作对进行记录,累积每个动作状态对的访问次数,引入玻尔兹曼分布方法,设计基于累积迹的探索方式,另外本发明通过加入基于累积迹的额外奖励的方式,来引导智能体进行探索。本发明通过加入基于累积迹的额外奖励的方式,来引导智能体进行探索,是以强化学习算法作为主体算法,在强化学习算法基础上进行改进,能够和任意强化学习算法进行结合,提高了强化学习的学习效率,实现多机器人在复杂环境下高效地协同探索。探索。探索。
技术研发人员:徐志雄 陈希亮 洪志理
受保护的技术使用者:中国人民解放军陆军工程大学
技术研发日:2020.11.13
技术公布日:2022/5/16
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。