1.本发明是有关于一种人工智能模型训练系统及人工智能模型训练方法,且特别是有关于一种有效率地强化同义字词学习的人工智能模型训练系统及人工智能模型训练方法。
背景技术:
2.一个好的机器学习模型必需要能够做到一定程度的泛化(generalization)。也就是说,即使某些字词并未经过特别训练,机器学习模型也能够将这些未经训练的字词辨识出来。然而,要训练出一个高度泛化的机器学习模型并不容易。因此,如何提供一个训练方法来有效地训练出高度泛化的机器学习模型是本领域技术人员应致力的目标。
技术实现要素:
3.有鉴于此,本发明提供一种人工智能模型训练系统及人工智能模型训练方法,能够有效率地强化同义字词的学习。
4.本发明提出一种人工智能模型训练系统,包括人工智能模型及处理器耦接到人工智能模型。处理器将多个同义字从第一训练资料移除以获得第二训练资料,并根据第二训练资料来训练人工智能模型。处理器将根据同义字扩展第一测试资料以获得第二测试资料,并在测试操作中根据第二测试资料来测试人工智能模型。当对应关键字词的测试结果产生错误时,处理器根据关键字词及第二训练资料获得第三训练资料,并根据第三训练资料来训练人工智能模型。
5.本发明提出一种人工智能模型训练方法,适用于人工智能模型训练系统。人工智能模型训练系统包括人工智能模型及处理器耦接到人工智能模型。人工智能模型训练方法包括藉由处理器将多个同义字从第一训练资料移除以获得第二训练资料,并根据第二训练资料来训练人工智能模型。人工智能模型训练方法还包括藉由处理器将根据同义字扩展第一测试资料以获得第二测试资料,并在测试操作中根据第二测试资料来测试人工智能模型。人工智能模型训练方法还包括当对应关键字词的测试结果产生错误时,藉由处理器根据关键字词及第二训练资料获得第三训练资料,并根据第三训练资料来训练人工智能模型。
6.基于上述,本发明的人工智能模型训练系统及人工智能模型训练方法会从第一训练资料移除同义字以获得第二训练资料并根据第二训练资料来训练人工智能模型。接着,第一测试资料会根据同义字扩展成第二测试资料且第二测试资料会用于测试人工智能模型。当对应一个关键字词(即,无法被泛化处理的字词)的测试结果产生错误时,第三训练资料会根据关键字词及第二训练资料来获得且人工智能模型会再次根据第三训练资料来训练。
附图说明
7.图1为根据本发明一实施例的人工智能模型训练系统的方块图。
8.图2为根据本发明一实施例的人工智能模型训练方法的流程图。
9.图3为根据本发明一实施例的分析流程的流程图。
10.其中:
11.100:人工智能模型训练系统;
12.110:人工智能模型;
13.120:处理器;
14.210:预处理流程;
15.211:第一训练资料;
16.212:第二训练资料;
17.213:同义字;
18.220:训练流程;
19.221:训练操作;
20.222:已训练模型;
21.230:测试流程;
22.231:第一测试资料;
23.232:测试操作;
24.233:测试结果;
25.240:分析流程;
26.241:分析操作;
27.242:分析结果;
28.243:第三训练资料;
29.244:训练资料调整操作;
30.s301~s305:分析流程的步骤。
具体实施方式
31.在本发明一实施例的语意模型中,使用者问题中重要的单词可被称作实体(entity),而使用者的目的可被称作意图(intention)。举例来说,在问句「where is the repair center in tokyo」中,语意模型可理解语意并进而将信息简化成意图「find repair center」及实体「tokyo」,并根据解析出的意图及实体到系统后端资料库寻找对应的答案提供给使用者。由于相同的意图可能会发生在不同的实体上,因此语意模型必需要有能力学习并辨认不同实体。
32.表1为使用者询问的句子及其意图的范例。
33.表1
34.句子意图higreetinghellogreetinghi theregreeting
where is the repair center in tokyofind repair centeri want to find a repair center in taipei cityfind repair centeri want to go to the acer repair centerfind repair centerwhy my wifi is not workingtroubleshootingi am not able to use my wifitroubleshootingmy wifi doesn’t worktroubleshootinglaunch the system backupuse applicationuse the system backupuse applicationplease open the acer recoveryuse application
35.表1列举了使用者问句及对应意图的范例。句子中的「tokyo」、「taipei」、「wifi」、「system backup」、「acer recovery」则为实体。
36.在一实施例的语意模型中,「wifi」可通过人工替换成「wi-fi」或「wireless」等同义字,然而这会大幅提升人力成本。在另一实施例的语意模型中,可利用同义字词应用程序界面(application program interface,api)来替换句子中的同义字来增加语意模型对句子的意图及/或实体中的同义字的识别能力。
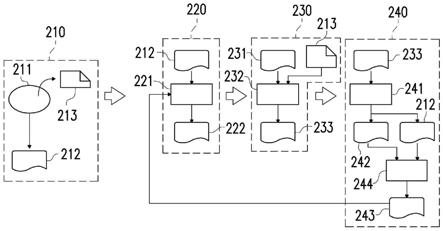
37.图1为根据本发明一实施例的人工智能模型训练系统的方块图。
38.请参照图1,本发明一实施例的人工智能模型训练系统100包括人工智能模型110及处理器120。处理器120耦接到人工智能模型110。人工智能模型训练系统100例如是服务器、个人电脑、笔记本电脑、智能型手机、平板电脑或其他类似电子装置。处理器120例如是中央处理单元(central processing unit,cpu)或其他类似装置。在一实施例中,人工智能模型110可为聊天机器人模型,用于接收使用者问题并作出相关的回应。处理器120可对人工智能模型110进行训练、测试及分析等操作。
39.在一实施例中,处理器120将多个同义字从第一训练资料移除以获得第二训练资料,并根据第二训练资料来训练人工智能模型110。处理器120将根据同义字扩展第一测试资料以获得第二测试资料,并在测试操作中根据第二测试资料来测试人工智能模型110。当对应关键字词的测试结果产生错误时,处理器120根据关键字词及第二训练资料获得第三训练资料,并根据第三训练资料来训练人工智能模型110。
40.图2为根据本发明一实施例的人工智能模型训练方法的流程图。
41.请同时参照图1及图2,本发明一实施例的人工智能模型训练方法包括预处理流程210、训练流程220、测试流程230及分析流程240。
42.在预处理流程210中,处理器120可将多个同义字213从第一训练资料211中移除,而产生不具有同义字213的第二训练资料212。由于第二训练资料212不包括同义字213,因此可大幅增加人工智能模型110的训练速度。
43.在训练流程220中,第二训练资料212会被输入人工智能模型110中进行训练操作221以产生已训练模型222。
44.在测试流程230中,处理器120可根据同义字213来扩展第一测试资料231以获得扩展后测试资料(或称为第二测试资料),并用扩展后测试资料对人工智能模型110进行测试操作232以产生测试结果233。测试操作232的细节会在下文中详细说明。
45.在分析流程240中,处理器120会对测试结果233进行分析操作241以产生分析结果
242。当分析结果242记录测试结果233的错误时,处理器120会根据产生错误的关键字词及第二训练资料212进行训练资料调整操作244来获得第三训练资料243。训练资料调整操作244的细节会在下文中详细说明。
46.在一实施例中,测试操作232可包括第一测试及第二测试。在第一测试中,人工智能模型110可接收句子以进行测试操作并产生对应句子的意图及实体,且处理器120判断意图及实体是否与对应句子的预定意图及预定实体相同。若判断出的意图及实体符合人工标注的正确答案则第一测试成功。在第二测试中,人工智能模型110通过意图及实体到资料库中搜寻对应句子的答案(或称为第一答案)。若人工智能模型110通过意图及实体到资料库中正确地搜寻对应句子的第一答案则第二测试成功。
47.图3为根据本发明一实施例的分析流程的流程图。
48.图3,在步骤s301中,读取测试结果。
49.在步骤s302中,从测试结果判断错误类型。
50.在步骤s303中,判断测试结果是否发生第一类错误或第二类错误。第一类错误及第二类错误会在下文中详细说明。
51.若测试结果没发生第一类错误或第二类错误,则在步骤s305中,产生分析结果。
52.若测试结果发生第一类错误或第二类错误,在步骤s304中,根据产生错误的关键字词产生重新训练资料(或称为第三训练资料)。
53.在步骤s305中,产生分析结果。
54.在一实施例中,当第一测试失败且第二测试失败则处理器120判断发生第一类错误。第一类错误又可称为缺同义字的错误,代表人工智能模型110无法识别预先定义好的字词且这个字词不在同义字集中,也无法用预测出的意图及实体到资料库找出答案。当第一类错误发生时,处理器120可根据句子中的关键字词搜寻同义字词资料库(例如,同义字词应用程序界面)以获得对应关键字词的多个同义字词,并根据同义字词替换该句子中的关键字词以获得第三训练资料。举例来说,当人工智能模型110无法识别「why my wi-fi is not working」时,处理器120可搜寻「wi-fi」的同义字「wifi」并以「wifi」替换问句中的「wi-fi」以将「why my wifi is not working」加入第三训练资料中。
55.当第一测试成功且第二测试失败则判断发生第二类错误。第二类错误又可称为缺答案的错误,代表人工智能模型110可以识别预先定义好的字词但这个字词不在同义字集里面,由于这组同义字词没有与资料库中的答案关联,因此人工智能模型也无法用识别出的字词到资料库找出答案。当第二类错误发生时,处理器120可根据句子中的关键字词搜寻同义字词资料库以获得对应关键字词的多个同义字词,并将同义字词关联到资料库中对应关键字词的答案(或称为第二答案)。举例来说,当人工智能模型110成功识别出「why my wi-fi is not working」但「wi-fi」并不在同义字集里面时,处理器120可通过同义字词资料库将「wi-fi」对应的答案与「wifi」对应的答案关联,以将系统后端资料库的答案补充完整。
56.综上所述,本发明的人工智能模型训练系统及人工智能模型训练方法会从第一训练资料移除同义字以获得第二训练资料并根据第二训练资料来训练人工智能模型。接着,第一测试资料会根据同义字扩展成第二测试资料且第二测试资料会用于测试人工智能模型。当对应一个关键字词(即,无法被泛化处理的字词)的测试结果产生错误时,第三训练资
料会根据关键字词及第二训练资料来获得且人工智能模型会再次根据第三训练资料来训练。
57.虽然本发明已以实施例揭露如上,然其并非用以限定本发明,任何所属技术领域中普通技术人员,在不脱离本发明的精神和范围内,当可作些许的更动与润饰,故本发明的保护范围当视权利要求书所界定者为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。