1.本发明涉及计算机视觉领域,特别涉及一种基于知识蒸馏的场景文本检测方法及装置。
背景技术:
2.近年来,由于广泛应用于机器阅读、移动翻译、车牌识别等实际场景,场景文本图像的研究一直是计算机视觉领域的研究热点。然而,场景文本的形状和风格多种多样,这使得它仍然是一项具有挑战性的任务。
3.作为识别与翻译的首要前提,场景文字检测旨在定位文本的位置,并给出文本的边界框。
4.近年来,任意形状的文本检测越来越受人们的关注。研究人员试图通过设计复杂的语义分割网络来处理形状各异的场景文本。但是这往往会导致庞大的计算时间与冗余的模型参数。最近的研究结果表明,轻量化的网络结构也可以胜任场景文本检测任务,这也表明当前网络在该任务上存在稀疏性和冗余性,但是并未给出具体的实现方式。
5.因此,需要一种基于知识蒸馏的场景文本检测方法及装置,能够在速度和准确度之间进行平衡,在不影响特征融合网络的情况下剪枝得到一个简化的prunednet网络,并通过知识蒸馏的方式提示该prunednet网络的检测性能。
技术实现要素:
6.(一)要解决的技术问题
7.为了解决现有技术的上述问题,本发明提供一种基于知识蒸馏的场景文本检测方法及装置,能够在速度和准确度之间进行平衡,在不影响特征融合网络的情况下剪枝得到一个简化的prunednet网络,并通过知识蒸馏的方式提示该prunednet网络的检测性能。
8.(二)技术方案
9.为了达到上述目的,本发明采用的一种技术方案为:
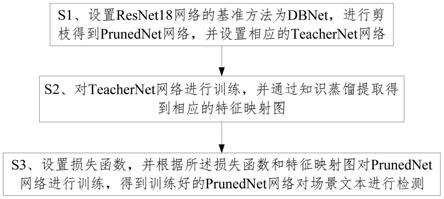
10.一种基于知识蒸馏的场景文本检测方法,包括步骤:
11.s1、设置resnet18网络的基准方法为dbnet,进行剪枝得到prunednet网络,并设置相应的teachernet网络;
12.s2、对teachernet网络进行训练,并通过知识蒸馏提取得到相应的特征映射图;
13.s3、设置损失函数,并根据所述损失函数和特征映射图对prunednet网络进行训练,得到训练好的prunednet网络对场景文本进行检测。
14.为了达到上述目的,本发明采用的另一种技术方案为:
15.一种基于知识蒸馏的场景文本检测装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现以下步骤:
16.s1、设置resnet18网络的基准方法为dbnet,进行剪枝得到prunednet网络,并设置相应的teachernet网络;
17.s2、对teachernet网络进行训练,并通过知识蒸馏提取得到相应的特征映射图;
18.s3、设置损失函数,并根据所述损失函数和特征映射图对prunednet网络进行训练,得到训练好的prunednet网络对场景文本进行检测。
19.(三)有益效果
20.本发明的有益效果在于:通过设置resnet18网络的基准方法为dbnet,进行剪枝得到prunednet网络,并设置相应的teachernet网络;对teachernet网络进行训练,并通过知识蒸馏提取得到相应的特征映射图;设置损失函数,并根据所述损失函数和特征映射图对prunednet网络进行训练,得到训练好的prunednet网络对场景文本进行检测,在速度和准确度之间进行平衡,在不影响特征融合网络的情况下剪枝得到一个简化的prunednet网络,更加敏捷高效,并通过知识蒸馏的方式提升该prunednet网络的检测性能,使得检测性能更加优异。
附图说明
21.图1为本发明实施例的基于知识蒸馏的场景文本检测方法流程图;
22.图2为本发明实施例的基于知识蒸馏的场景文本检测装置的整体结构示意图;
23.图3为msra-td500上不同方法的比较示意图;
24.图4为场景文本检测结果示意图。
25.【附图标记说明】
26.1:基于知识蒸馏的场景文本检测装置;
27.2:存储器;
28.3:处理器。
具体实施方式
29.为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
30.实施例一
31.请参照图1,一种基于知识蒸馏的场景文本检测方法,包括步骤:
32.s1、设置resnet18网络的基准方法为dbnet,进行剪枝得到prunednet网络,并设置相应的teachernet网络;
33.所述的剪枝得到prunednet网络得过程具体为:
34.获取resnet18网络每个残差块的第一个bn层;
35.获取每个bn层的缩放因子构成集合a={γ1,γ2,γ3,γ4…
γm};
36.通过剪枝比pr对所述集合a进行排序,取第k大的缩放因子γk,
37.遍历所有的bn层,若存在γi《γk,则删除上下层对应的卷积核,得到prunednet网络。
38.所述的设置相应的teachernet网络具体为:
39.设置相应的teachernet网络为resnet50网络。
40.s2、对teachernet网络进行训练,并通过知识蒸馏提取得到相应的特征映射图;
41.s3、设置损失函数,并根据所述损失函数和特征映射图对prunednet网络进行训
练,得到训练好的prunednet网络对场景文本进行检测。
42.步骤s3具体为:
43.设置特征映射图损失函数和概率损失函数,并根据所述特征映射图损失函数和概率损失函数对prunednet网络进行训练,得到训练好的prunednet网络对场景文本进行检测。
44.所述的特征映射图损失函数lf公式为:
[0045][0046]
其中,w,h,c表示特征映射图的宽、高以及通道数,y
i,j,k
表示teachernet网络中某点的特征值,x
i,j,k
表示prunednet网络中某点的特征值。
[0047]
所述的概率损失函数l
p
公式为:
[0048][0049]
其中,x表示prunednet网络的输出预测图,y表示teachernet网络的输出预测图。
[0050]
实施例二
[0051]
本实施例和实施例一的区别在于,本实施例将结合具体的应用场景,进一步说明本发明上述基于知识蒸馏的场景文本检测方法是如何实现的:
[0052]
1.1、基准方法
[0053]
设置resnet18网络的基准方法为dbnet。dbnet是一个参数小且易于实现的高效文本检测器,图像经过一个主干网络,提取出四种不同大小的特征映射图;接着,这些特征映射图经过自下而上的融合后被拼接在了一起;随后,网络从融合后的特征预测出概率图与阈值图,并通过可微二值化计算得到最后的目标预测图;最后,后处理算法根据二值图得到文本边界框。
[0054]
1.2、剪枝
[0055]
bn(batch normalization)层是网络中的一种数据归一化操作,旨在将输入数据拉回比较标准的正态分布,使得激活输入值落在非线性函数对输入比较敏感的区域。其中,bn层需要学习参数β,γ进行线性映射,若线性变换的缩放因子γ较小时,该层特征在后续的卷积等一系列操作的作用也会较小。因此,可根据γ的大小对网络的卷积核进行剪枝,可以得到简化的网络。
[0056]
对resnet18网络进行剪枝得到prunednet网络,过程具体为:
[0057]
(1)获取resnet18网络每个残差块的第一个bn层;
[0058]
(2)获取每个bn层的缩放因子构成集合a={γ1,γ2,γ3,γ4…
γm};
[0059]
(3)通过剪枝比pr对所述集合a进行排序,取第k大的缩放因子γk,
[0060]
(4)遍历所有的bn层,若存在γi《γk,则删除上下层对应的卷积核,得到prunednet网络。
[0061]
对黄色的bn模块进行计算后,精简上下两个卷积核的参数大小。可以看到,对于第一个卷积核,原参数大小为64
×
64
×3×
3,即输入特征映射图通道数为64,卷积核大小3
×
3,数量64个。经过裁剪后,该卷积核参数为64
×
32
×3×
3,即卷积核的数量由原来的64个减少为32个。对于第二个卷积核,原参数大小为64
×
128
×3×
3,代表有128个3
×
3大小的卷积核对通道数为64的特征映射图进行卷积。经过裁剪操作后,由于上一个卷积核的数量为32,仅输出通道数为32的特征映射图,于是改卷积核的参数变为32
×
128
×3×
3以适应32通道数的特征映射图。
[0062]
本文的剪枝方法保留了卷积残差块的输出通道,不影响后续的特征融合与知识蒸馏操作。它还可以扩展到其他领域,如语义分割、目标跟踪等。
[0063]
1.3、知识蒸馏
[0064]
知识蒸馏,就是从复杂网络中提取已学到的抽象知识,训练简化网络,使得简化网络达到复杂网络的性能。为了使两个网络达到相同的性能,需要在训练时设置一些损失函数来约束网络,使它们的特征表达趋于一致,设置相应的teachernet网络为resnet50网络。
[0065]
对teachernet网络进行训练,并通过知识蒸馏提取得到相应的特征映射图;
[0066]
设置特征映射图损失函数和概率损失函数,并根据所述特征映射图损失函数和概率损失函数对prunednet网络进行训练,得到训练好的prunednet网络对场景文本进行检测。
[0067]
具体地,从主干网络出来的四种特征映射图都各自经过1
×
1卷积进行维度统一,四种特征映射图在prunednet网络和teachernet网络里都有一一对应的关系。另外,由于融合后的特征映射图也存在对应关系。本发明利用这种对应关系,采用l2损失函数约束特征,将teachernet网络提取特征的知识蒸馏到prunednet网络当中,所述的特征映射图损失函数lf公式为:
[0068][0069]
其中,w,h,c表示特征映射图的宽、高以及通道数,y
i,j,k
表示teachernet网络中某点的特征值,x
i,j,k
表示prunednet网络中某点的特征值。
[0070]
对于预测图,常用的知识蒸馏方法是利用kl损失函数(kullback-leibler divergence loss)进行约束,使得prunednet网络对类别预测的概率分布趋近于teachernet网络的预测概率分布。然而对文字检测而言,对像素的分类属于二分类(文字与背景),仅需要一个0到1的浮点数即可以表示概率,不适用kl损失函数。本文采用骰子损失对预测的概率图与二值图进行概率约束,本发明采用骰子损失对预测的概率图与二值图进行概率约束,所述的概率损失函数l
p
公式为:
[0071][0072]
其中,x表示prunednet网络的输出预测图,y表示teachernet网络的输出预测图。在训练过程中,特征损失可以增强网络的特征表达能力,概率损失可以使网络灵活地预测像素点。结合剪枝,简化后的网络在去掉冗余参数后仍具有良好的性能。
[0073]
1.4、损失函数
[0074]
本发明方法继承了基准方法的三种损失函数,即:概率图损失、二值图损失和阈值图损失,对应的损失函数被定义为:ls、lb和l
t
。其中ls、lb使用二进制交叉熵(bce)损失,公式
如下:
[0075][0076]
其中,xi为预测值,yi为真实值。l
t
采用l1损失,公式如下:
[0077][0078]
结合知识蒸馏的监督损失,实验的总损失函数可表示为:
[0079][0080]
其中,α和β在实验中分别设置为1和10,表示低i个特征图的特征损失、表示概率图的概率损失、表示二值图的概率损失。
[0081]
2、实验
[0082]
为了评估本发明方法的性能,在公共基准数据集total-text上实现了本文的方法。将本文方法与现有的文本检测方法进行了比较,然后进行了消融研究,考察了剪枝率和知识蒸馏对文本检测结果的影响。
[0083]
2.1、数据集
[0084]
total-text是一个基于单词级别的英语弯曲文本数据集。它是第一个具有三个不同文本方向(水平、多向和曲线)的相对较大的场景文本数据集。它包含1255个训练图像和300个测试图像。
[0085]
2.2、实验细节
[0086]
对于所有的模型,首先,本发明训练dbnet的两个模型(resnet18和resnet50)。然后对resnet18的模型进行剪枝和微调。最后,利用简化后的模型进行蒸馏训练。在训练过程中,当模型单独训练时,批次大小被设置为16,而对于蒸馏训练,由于内存限制,批次大小被设置为8。在所有的训练中,训练轮数为1200,初始学习率为0.007,学习率呈指数级下降,下降率为0.9。输入大小为640
×
640,通过随机翻转、旋转和剪裁获得。
[0087]
在测试期间,本发明保持与基准相同的测试图像大小。虽然gpu显示了一点不同,但在没有任何加速技术的情况下,在单线程中使用单个2080ti gpu测试了实现速度。
[0088]
2.3、消融研究
[0089]
对数据集total-text进行消融研究,检测结果如图4显示,考察剪枝和知识蒸馏的有效性。
[0090]
表1为本文方法在不同剪枝率下与基准方法相比较的实验结果。随着剪枝率的增加,综合得分开始下降,但帧数增加。当剪枝比为0.1或0.2时,与基准方法相比,本文方法可以同时提高性能和速度。当剪枝率达到0.5时,本文方法在综合得分方面与基准方法相当,帧数提高了7。
[0091]
表1:不同剪枝率的结果
[0092][0093]
其中,“p”、“r”、“f”分别代表“准确率”、“漏检率”和“综合得分”。
[0094]
知识蒸馏的效果如表2所示,在对基准方法剪枝后,综合得分只有81.1%,比基准方法有所下降。但对模型进行微调后,综合得分达到82.7%,接近基准方法水平。然而,模型的综合得分达到83.0%,超过了基线。最后,在概率损失的监督下,模型的性能提高到83.3%,在综合得分方面实现了0.5%的增益。
[0095]
表2:不同损失函数下的实验结果
[0096][0097]
其中,pr:剪枝得到模型(剪枝比为0.1);ft:模型微调;f1:特征损失;p1:概率损失。
[0098]
2.4、参数大小
[0099]
在参数大小方面与dbnet、psenet、textsnake和craft进行了比较,这些方法都是基于分割的方法。它们都是来自互联网的源代码,其中一些是重新实现的代码。比较结果如表4所示,本发明方法的参数仅为dbnet的一半,为6.8m,是五种方法中参数最少的。
[0100][0101]
3、总结
[0102]
由图3可知,本发明提供的基于知识蒸馏的场景文本检测方法,在fps(帧率速度)和综合得分(分类问题的评判性能指标)之间进行了取得了平衡,该方法能够在速度与准确度之间取得平衡,能够获得敏捷、高效的检测网络,设计了知识蒸馏结构,该结构可以将复杂文本检测器的暗知识转移到简化网络中,从而得到优异的检测性能。
[0103]
本发明先通过剪枝算法,简化了网络参数,提高检测速度。此外,为了提高简化网络的检测性能,通过知识蒸馏,能够灵活高效的对任意形状文本进行检查,并在数据集上取得了与之相当的性能和最快的检测速度。
[0104]
实施例三
[0105]
请参照图2,一种基于知识蒸馏的场景文本检测装置1,包括存储器2、处理器3及存储在存储器2上并可在处理器3上运行的计算机程序,所述处理器3执行所述程序时实现实施例一中步骤。
[0106]
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
