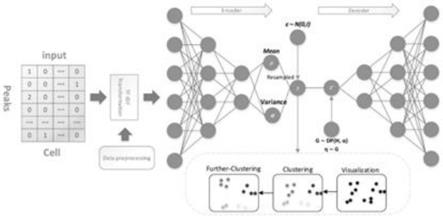
技术特征:
1.一种提高单细胞深度聚类算法精度的方法,其特征在于:包括以下步骤:(1)数据处理包括异常细胞和异常基因表达的过滤以及归一化,并进行tf-idf转换;(2)将步骤(1)处理后的数据输入变分自编码器,对步骤(1)得到的数据进行训练变分自编码器包括两个神经网络:编码器神经网络和解码器神经网络,以及两个变量:观测变量x和潜变量z;变分自编码器的公式如下:变分自编码器的公式如下:表示变分自编码器在参数λ和参数设置好的情况下输出的x是多少;代表了重构误差,其中q
λ
(z|x)表示编码器的输出,表示解码器的输出,x表示观测变量,z表示隐藏变量,λ和分别表示编码器神经网络和解码器神经网络的训练参数;kl(q
λ
(z|x)||p(z))代表了近似后验分布和先验分布之间的kl散度,其中q
λ
(z|x)代表近似后验分布,其中x表示观测变量,z表示隐藏变量,λ表示编码器神经网络的训练参数,p(z)表示先验分布,z~n(0,1);然后结合变分自编码器和贝叶斯高斯混合模型,推断出聚类的个数,贝叶斯高斯混合模型是高斯混合模型的拓展,接着根据方程高斯混合模型是m分量高斯密度的加权和,其中x是一个d维向量,w
i
,i=1,...,m表示权重,g(x|μ
i
,σ
i
),i=1,...m表示高斯分量密度;本步骤利用了具有狄利克雷分布的有限混合模型和一个具有狄利克雷过程的无限混合模型,在狄利克雷过程混合模型中,dp被用作层次贝叶斯规范中的非参数先验:g|{α,g0}~dp(α,g0),η
n
|g~g,x
n
|η
n
~p(x
n
|η
ns
),其中,g0表示基本测度,α表示基本测度的离散程度,g表示从基本测度中采样出来的分布,η
n
|g是服从g的分布,其中η
n
显示出聚类效应,x
n
表示产生的数据,其可以根据参数的不同值进行区分;由该模型生成的数据可以根据不同的参数值进行分区;dp混合是一种灵活的混合模型,其中组分的数量(即分区中的细胞数量)是随机的,并随着新数据的观察而扩展,利用kolmogorov一致性定理,通过式上中的有限维分布来定义dp;将dp更具体地描述为一种断棍结构,两个随机变量的无限集合,公式如下:v
i
~beta(1,α),i={1,2,...},v
i
是由beta(1,α)分布中独立采样得出的随机变量,采样结果决定了每一部分的大小,且与棍子的剩余部分成比例;且与棍子的剩余部分成比例;v={v1,v2,...,v
∞
},
其中,是断棍表达式的形式,π(v
i
)是其对应的采样的权重,v
j
代表前一次采样的权重,v={v1,v2,...,v
∞
}表示无限次的采样的权重集合p(d
i
|v)=mult(π(v)),其中,mult(π(v))表示以π(v)为参数的多项式分布,p(d
i
|v)表示从多项式分布中采样得到的概率p(d)=p(d
i
|v),其中,把多项式分布p(d
i
|v)表示成p(d),其中d是一个分类变量,其概率是离散的p(x|z)=ber(x|μ
x
),联合概率如下:p(x
,
z,d)=p(x|z)p(z|d)p(d),训练变分自编码器以达到最大化观测数据的似然函数:它被转换为最大化证据的下界(elbo):elbo(x)=e
q(z,d|x)
[logp(x|z)]-d
kl
(q(z,d|x)||p(z,d)),g|{α,g0}~dp(α,g0),η
n
|g~g,x
n
|η
n
~p(x
n
|η
ns
),正则化项是一个kl散度,它将潜变量z正则化为贝叶斯高斯混合模型流形,q(z,c|x)和p(x|z)分别是编码器和解码器,分别用两个神经网络建模,将步骤(1)处理后的数据输入编码器神经网络,对数据进行降维;(3)将步骤(2)降维后的数据进行第一次聚类分析,本步骤采用k-means聚类算法,直接使用从模型推断出来的聚类个数k;(4)进行第二次聚类第二次聚类基于第一次聚类预测的伪标签,采用leiden聚类算法,本步骤中,对第二次聚类的预测结果和第一次聚类得到的伪标签进行评分,即ari:ari是调整兰德系数,ri是兰德系数,expected(ri)是兰德系数的期望值,max(ri)表示兰德系数的最大值;两个簇的结果通过ari评分进行比较,设置γ的取值范围作为比较范围,得分高的结果作为γ参数选择的依据,这样可以从复杂网络的角度对聚类模型进行约束,进一步提高其性能。2.根据权利要求1所述的一种提高单细胞深度聚类算法精度的方法,其特征在于:所述步骤(1)中数据过滤方式为:对scatac-seq计数矩阵进行了筛选,只保留了至少100个细胞和至少0.01倍于表达细胞数的基因,然后,计算差异性分数,所有细胞差异性特征进行排名,在排名结束后,选择排名前30000的基因进行分析;然后对原始的scatac-seq计数矩阵进行tf-idf转换。
3.根据权利要求1所述的一种提高单细胞深度聚类算法精度的方法,其特征在于:所述步骤(2)中编码器神经网络设置成6层的深度神经网络,维数分别是数据本身维度,3000维,1500维,840维,420维和潜在空间的固定维度10维,再通过解码器神经网络将数据维度还原到其自身的维度,其中的激活函数主要使用了relu函数,批次大小设置为30,优化器采用了adam优化器。4.根据权利要求1所述的一种提高单细胞深度聚类算法精度的方法,其特征在于:所述步骤(3)第一次聚类分析时,时间复杂度:o(tknm),其中,t为迭代次数,k为簇的数目,n为样本点数,m为样本点维度;空间复杂度:o(m(n k)),其中,k为簇的数目,m为样本点维度,n为样本点数。
技术总结
本发明提供了一种提高单细胞深度聚类算法精度的方法,该方法包括四个步骤,分别为数据处理,包括异常细胞和异常基因表达的过滤以及归一化,并进行TF-IDF转换;将处理后的数据输入变分自编码器,对得到的数据进行训练,进行降维;将降维后的数据进行第一次聚类分析,本步骤采用k-means聚类算法,直接使用从模型推断出来的聚类个数k;最后进行第二次聚类。本发明相对于以往的方法如SCALE,scVI和Cicero等方法,提高了聚类的准确性;且不需要人为地设置聚类个数,这样就避免了人为设置的聚类个数与数据本身细胞类型个数不符所造成的偏差,避免了对下游分析的影响;本发明具有一个二次聚类功能,相对于自身可以进一步提升聚类的准确性。确性。确性。
技术研发人员:李凤 段宏宇 李涵 褚鑫 孟凡杰 孙振省
受保护的技术使用者:曲阜师范大学
技术研发日:2022.02.23
技术公布日:2022/5/10
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。