1.本发明涉及图像语义分割技术领域,尤其涉及一种基于多通道深度加权聚合的图像语义分割算法及系统。
背景技术:
2.近年来,随着深度学习技术的不断发展,图像语义分割技术也随之发展到一个新的阶段,涌现出各种语义分割算法。这其中图像语义分割算法是一种重要的智能感知技术,其任务是为每个像素分配语义标签,将图像中不同物体的像素区域分隔开,并对每一块区域的类别进行标注。传统的语义分割算法有很多缺陷,如:推理速度慢、语义分割精度低、无法在智能移动机器人上实时运行等。
3.对于大多数语义分割算法,如何保持算法的速度与精度之间的均衡仍是一个关键问题。在传统语义分割算法中,一些方法通过限制图像大小,或者通过修剪网络的冗余通道来降低网络的计算复杂度,以此提高算法推理速度,但这些语义分割算法的分割精度较低;也有一些方法利用u形结构在高分辨率特征图上操作,提高分割精度,但这会大幅增加计算复杂度,使得算法推理速度过慢。显然,上述传统语义分割算法都不能很好的平衡精度与速度之间的关系。
4.考虑到当前大部分语义分割算法学习能力有限,导致算法整体性能无法得到较大的提升,为此有研究者提出从提高语义分割算法的学习能力上来改进的思路。其中神经进化方法最为显著,如神经进化的卷积神经网络convgp(convolutional genetic programming)、生成式对抗网络egan(evolutionary generative adversarial networks)、自动编码器evoae(evolutionary autoencoder)、长短期记忆网络codeepneat(convolution deep neuro evolution of augmenting topologies)、深度强化学习wann(weight agnostic neural network)等典型模型,这些模型能极大的提高算法的学习能力,但在推理速度上仍然受到很大的限制,无法根本解决算法速度与精度之间的平衡问题。
5.也有研究者提出了一些改进措施:如bisenet语义分割算法利用双分支结构结合空间信息在保证一定速度的同时,尽可能提高算法的分割精度,取得了一定的效果。但双分支结构中分支之间的相互独立性限制了算法的学习能力,使算法无法更好的学习图像的全局语义特征,使得分割精度的提升非常有限。
6.dfanet语义分割算法利用多分支结构并使各分支之间进行信息交互提取图像语义特征,在保证了算法的推理速度前提下,一定程度上提高了算法的分割精度。但该多分支结构均相同,因此只能提取一种语义信息,无法更好的获取全局语义和上下文信息特征,使得算法的分割精度受到限制。
7.综上,虽然目前已有众多基于深度学习的语义分割算法,但这些算法几乎都无法保证图像分割精度与推理速度之间的均衡。为此本发明提出一种全新的语义分割网络框架,实现图像语义分割算法分割精度与推理速度之间的权衡。
技术实现要素:
8.针对现有技术中存在的技术问题,本发明的目的在于提供一种基于多通道深度加权聚合的图像语义分割算法及系统,能够解决传统图像语义分割算法无法实现分割精度与速度之间权衡的问题,具有更强的鲁棒性。
9.本发明提供的基于多通道深度加权聚合的图像语义分割算法,包括以下步骤:
10.s1,通过低级语义通道、辅助语义通道以及高级语义通道分别提取图像中具有明确类别信息的语义特征、介于低级语义和高级语义的过渡语义特征以及图像中上下文逻辑关系的语义特征;
11.s2,将步骤s1得到的三种不同的语义特征通过加权聚合进行融合得到图像的全局语义信息;
12.s3,将步骤s1中各语义通道输出的语义特征与步骤s2中的全局语义信息共同计算损失函数进行训练。
13.优选地,步骤s1中:采用浅层卷积结构网络构建低级语义通道,用于提取低级语义信息;
14.采用深度可分离卷积结构网络构建辅助语义通道,并将辅助语义通道得到的过渡语义信息反馈至高级语义通道;
15.采用深层卷积结构网络构建高级语义通道,用于提取高级语义信息。
16.优选地,浅层卷积结构网络提取低级语义信息的过程包括:
17.ls(i
h*w
)=s3(s2(s1(i
h*w
)))
18.其中,ls(x)为低级语义信息提取过程,i
h*w
为输入图像矩阵,s为卷积步长。
19.优选地,可分离卷积结构网络包括三个串联的辅助模块及位于尾部的注意力机制模块,各模块将提取到的不同层次辅助语义信息传递到高级语义通道;
20.辅助语义通道提取过渡语义信息的过程包括:
21.as(k
m*n
)=atten(aux(aux(aux(k
m*n
))))
22.其中,as(x)为过渡语义信息提取过程,km*n为输入辅助语义通道的特征矩阵,aux(x)为辅助模块,atten(x)为注意力机制模块;
23.辅助语义通道各阶段输出的辅助语义信息包括:
24.aux1(k
m*n
)=aux(k
m*n
)
25.aux2(k
m*n
)=aux(aux1(k
m*n
))
26.aux3(k
m*n
)=aux(aux2(k
m*n
))
27.aux1'(k
m*n
)=up(as(k
m*n
),4)
28.其中,up(x,k)为注意力机制模块向高级语义通道的上采样,x为输入,k为上采样倍数,选取数值为4。
29.优选地,高级语义通道包括启动模块、特征聚合模块以及语义嵌套模块,其提取高级语义信息的过程包括:
30.通过启动模块和特征聚合模块与辅助语义通道提供的辅助语义信息融合,提取图像深层语义信息,然后利用语义嵌套模块将辅助语义通道与高级语义通道的深层语义信息整合,得到高级语义信息。
31.优选地,所述启动模块包括卷积和最大池化两种不同的下采样方式,两种输出结
果连接后卷积输出;所述特征聚合模块包括两个特征聚合子模块,利用深度卷积加深特征层数,所述特征聚合模块的聚合过程包括:
32.fgb(k
′
m*n
,s1,s
′1)=fg(fg(k
′
m*n
,s1),s
′1)
33.其中,fgb(x)为特征聚合模块推理过程,fg(x,s1)表示特征聚合子模块的推理过程,k
′
m*n
为输入特征矩阵,步长s1=2,s1=1;
34.辅助语义通道中三个辅助模块的特征聚合模块的推理过程包括:
35.fgb1(k
m*n
)=fgb(st(k
m*n
) aux1(k
m*n
) aux1'(k
m*n
),s1,s
′1)
36.fgb2(k
m*n
)=fgb(fgb1(k
m*n
) aux2(k
m*n
),s1,s
′1)
37.fgb3(k
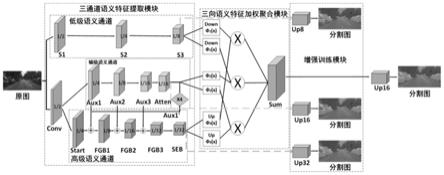
m*n
)=fgb(fgb2(k
m*n
) aux3(k
m*n
),s1,s
′1)
38.所述语义嵌套模块采用全局平均池化和跳跃连接结构,将高级语义通道和辅助语义通道提供的辅助语义信息进行深度融合;
39.高级语义通道语义信息提取的过程包括:
40.as(k
m*n
)=seb(fgb3(k
m*n
))
41.其中,as(x)为高级语义通道语义信息提取过程,seb(x)为语义嵌套模块的推理过程。
42.优选地,步骤s2中语义特征的融合包括加权聚合以及三类语义特征的融合,
43.加权聚合包括:更新低级语义通道、辅助语义通道以及高级语义通道分别得到语义特征的加权权重ε1、ε2和ε3,权重的更新由三类语义特征在验证集中测得的miou={miou1,miou2,miou3}自适应决定,采用各通道的网络权重在验证集上求得miou,再由miou值根据如下公式更新三类语义特征的加权权重,包括:
[0044][0045][0046][0047]
三类语义特征加权过程包括:
[0048][0049]
其中,up为一个放大倍数为2的上采样,up(x)表示所述上采样过程,conv为卷积操作,sigmoid(x)的计算包括:
[0050][0051]
优选地,三类语义特征的融合包括将两两语义通道得到的加权结果相乘后再进行
步长为1的3*3卷积,三类语义特征中的两两聚合过程包括:
[0052][0053]
其中,sa1(x)、sa2(x)和sa3(x)分别为三类语义特征两两聚合过程;
[0054]
三类语义通道得到的三向语义特征的复合过程包括:
[0055]
msa(x)=sa1(x) sa2(x) sa3(x)
[0056]
其中,msa(x)为三向语义特征的复合过程。
[0057]
优选地,步骤s3中,将各通道输出语义特征进行上采样与图像的全局语义信息共同计算损失进行随机梯度下降学习,损失函数包括权值的计算、损失函数的计算以及综合训练机制中损失函数的确定,其中权值的计算包括:
[0058][0059]
其中,α为权值,n为类别数;
[0060]
损失函数的计算包括:
[0061]
ced(x,y)=cel(x,y) α*d l(x,y)
[0062]
其中,x为预测数据,y为真实数据,cel(x,y)为cross-entropy损失函数,dl(x,y)为dice loss损失函数;
[0063]
综合训练机制中损失函数的确定包括:
[0064][0065]
其中,t为真实标签,p
re
为全局语义信息输出标签,a1、a2和a3分别为低级语义通道、辅助语义通道和高级语义通道的输出标签。
[0066]
本发明还提供了一种图像语义分割系统,采用上述基于多通道深度加权聚合的图像语义分割算法,包括:三通道语义表征模型、三类语义加权聚合模块以及增强训练模块;
[0067]
所述三通道语义表征模型包括低级语义通道、辅助语义通道以及高级语义通道;所述辅助语义通道包括辅助模块及注意力机制模块,所述高级语义通道包括启动模块、特征聚合模块以及语义嵌套模块。
[0068]
本发明针对传统图像语义分割算法无法实现分割精度与速度之间权衡的问题,提供了一种基于多通道深度加权聚合网络(muti-channel deep weighted aggregation net,mcdwa net,简称mcdwa_net)新的高精度实时图像语义分割算法。
[0069]
首先通过三通道语义表征模型引入多通道思想,主要包括:低级语义通道、辅助语义通道和高级语义通道三种不同的语义通道,分别用于提取三类互补的语义信息。低级语义通道输出图像中具有明确类别信息的语义特征;辅助语义通道提取介于低级语义和高级语义的过渡信息,并实现对高级语义通道的多层反馈,确保高级语义通道提取的快速性和准确性;高级语义通道获取图像中上下文逻辑关系的语义特征。
[0070]
其次通过三类语义特征加权聚合模块可将三通道输出的互补语义特征加权后进行深度融合,输出全局语义特征,从而大幅提高网络的分割精度。
[0071]
最后,增强训练模块通过改善两种损失函数的缺陷,并将其融合,从而加强训练阶
段的特征表示,强化和改善训练的速度。
[0072]
本发明中的图像语义分割算法与传统语义分割算法相比,对场景的分割精度更高,推理速度更快,对各种复杂环境的适应性更强,具有更好的实用价值。
附图说明
[0073]
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
[0074]
图1为本发明基于多通道深度加权聚合的图像语义分割算法的逻辑框架图;
[0075]
图2为低级语义通道网络结构示意图;
[0076]
图3为辅助语义通道网络结构示意图;
[0077]
图4为高级语义通道网络结构示意图;
[0078]
图5为启动模块网络结构示意图;
[0079]
图6为特征聚合子模块网络结构示意图;
[0080]
图7为语义嵌套模块网络结构示意图;
[0081]
图8为三类语义特征加权聚合模块示意图;
[0082]
图9为增强训练模块示意图;
[0083]
图10为实施例1中模型训练损失值变化曲线图;
[0084]
图11为实施例1中模型训练miou值变化曲线图;
[0085]
图12为消融实验效果图;
[0086]
图13为实施例1中六种语义分割算法实际分割效果图;
[0087]
图14为实施例2中模型训练损失值变化曲线图;
[0088]
图15为实施例2中模型训练miou值变化曲线图;
[0089]
图16为实施例2中六种语义分割算法在分割效果图。
具体实施方式
[0090]
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
[0091]
在本公开使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本公开。在本公开和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
[0092]
应当理解,尽管在本公开可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本公开范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,如在此所使用的词语“如果”可以被解释成为“在
……
时”或“当
……
时”或“响应于确定”。
[0093]
参见图1,本发明提供的基于多通道深度加权聚合的图像语义分割算法,主体步骤包括:1)利用浅层卷积网络结构构建低级语义通道,用于提取图像中具有明确类别信息的语义特征,2)利用深度可分离卷积构建较深层的辅助语义通道,用于提取介于低级语义和高级语义的过渡信息,并实现对高级语义通道的多层反馈,3)利用深层卷积结构构建高级语义通道,获取图像中上下文逻辑关系的语义特征。
[0094]
然后设计一种三类语义特征加权聚合模块,该模块可将三通道输出的互补语义特征加权后进行深度融合,输出全局语义特征,从而大幅提高网络的分割精度;
[0095]
最后引入增强训练机制,加强训练阶段的特征表示,强化和改善训练速度。
[0096]
相比于传统的语义分割算法具有更强的鲁棒性,且能够实现图像语义分割速度与精度之间的权衡。
[0097]
本发明提出的基于多通道深度加权聚合的图像语义分割算法,与传统语义分割算法相比,引入多通道思想,设计一种三通道语义表征模型用于提取图像中三类不同的语义信息,该模型能够最大程度提取图像中各类语义信息,并将语义信息提取任务分配在三个通道中完成,大大降低算法推理时间,提高算法运行速度;为了使三类局部语义信息能够更好的融合在一起,本发明提供了三类语义特征加权聚合模块,使三类语义信息加权后进行两两融合,最后再将其全部融合在一起,从而融合成全局语义信息;此外,为了提高算法训练速度,通过增强训练模块能够更快的训练出算法的模型。
[0098]
本发明采用了如下的技术方案及实现步骤:
[0099]
三通道语义特征分别为低级语义通道、辅助语义通道和高级语义通道。
[0100]
低级语义通道负责提取图像中具有明确类别信息的语义特征,此类语义信息只有在高分辨率特征图中才能完整展现。因此,本发明通过浅层结构卷积网络提取低级类别语义信息,如图2所示。该种简单的浅层结构卷积网络不仅能够提取高分辨率特征图,而且还能大大减少推理时间。
[0101]
设输入图像矩阵为ih*w,通道数为3,则低级语义信息的提取可表达为表1中s1-s3的过程。
[0102]
表1中,h和w分别为输入图像的高和宽,conv表示卷积操作,k为卷积核大小,cout为输出图像通道数,s为卷积步长。
[0103]
表1低级语义通道语义信息提取过程
[0104][0105]
设函数ls(x)为低级语义通道信息提取过程,则该低级语义信息提取过程如式(1)所示:
[0106]
ls(i
h*w
)=s3(s2(s1(i
h*w
)))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0107]
由表1可知,低级语义通道最终会输出h/8*w/8*64的低级语义特征ls(i
h*w
),其能
更好的表达图像中具有明确类别信息的语义特征。
[0108]
辅助语义通道负责提取图像中介于低级语义和高级语义的过渡语义信息,并将其提供给高级语义通道,辅助高级语义通道提取图像上下文信息,从而起到辅助作用。
[0109]
本发明采用深度可分离卷积(dsc),设计了一种既能提高运行速度又能提取更深层特征信息的辅助模块(aux),将三个辅助模块(aux)串联,并在尾部添加一种全连接结构的注意力机制模块(atten),以此保留最大的感受野,输出更完整的辅助特征信息;最后将各阶段提取的辅助语义特征传递给高级语义模块,构建辅助通道,其网络结构示意图如图3所示。
[0110]
如图3中,aux模块由三层深度可分离卷积(dsc)结果和一层步长为2的3*3卷积结果结合后输出,atten模块先将输入变为n*1000*1*1(n为类别数)的矩阵结构,再对其进行步长为1的1*1卷积,最后再恢复成原来的输入形状并与输入进行合并后输出。
[0111]
设输入辅助语义通道的特征矩阵为km*n,aux模块用aux(x)函数表示,atten模块用atten(x)表示,用as(x)表示辅助语义通道信息提取过程,则辅助语义通道信息提取过程可表达为如下过程:
[0112]
as(k
m*n
)=atten(aux(aux(aux(k
m*n
))))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0113]
进一步,由图3可看出辅助语义通道最终输出h/16*w/16*64的过渡语义特征as(k
m*n
)。
[0114]
基于上述分析,设上采样操作为up(x,k)(其中,x为输入,k为上采样倍数,此处k=4),辅助语义通道各阶段输出的辅助语义信息可表达为:
[0115]
aux1(k
m*n
)=aux(k
m*n
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0116]
aux2(k
m*n
)=aux(aux1(k
m*n
))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0117]
aux3(k
m*n
)=aux(aux2(k
m*n
))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0118]
aux1'(k
m*n
)=up(as(k
m*n
),4)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0119]
综上可看出,辅助语义通道将各阶段输出的不同层次辅助语义信息反馈给高级语义通道,使高级语义通道更精准的提取图像中上下文逻辑关系,加快提取速度和精度。
[0120]
高级语义通道负责获取图像中上下文逻辑关系的语义特征。高级语义通道通过启动模块(start)和特征聚合模块(cgb)与辅助语义通道提供的辅助语义信息融合,实现对图像深层语义信息的提取,最后利用语义嵌套模块(seb)将辅助语义通道与高级语义通道的深层语义信息整合,完成高级语义通道的信息提取过程,其网络结构示意图如图4所示。
[0121]
启动模块(start):高级语义通道中,以启动模块作为第一阶段,如图5所示,其使用了卷积和最大池化两种不同的下采样方式,再将它们的输出结果连接再卷积输出,以此增强特征表达能力。设函数st(x)为启动模块的推理过程。
[0122]
特征聚合模块(fgb):在启动模块之后是特征聚合模块,特征聚合模块由两个特征聚合子模块组成,特征聚合子模块网络结构示意图,如图6所示。利用深度卷积加深特征层数,提取更深层语义信息,更有效地聚合语义特征,输出更深层特征。
[0123]
假设采用fg(x,s1)表示特征聚合子模块推理过程,fgb(x)表示特征聚合模块推理过程,则聚合过程如公式(7)所示:
[0124]
fgb(k'
m*n
,s1,s
′1)=fg(fg(k'
m*n
,s1),s
′1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0125]
其中,k'
m*n
为输入特征矩阵,步长s1=2,s
′1=1。
[0126]
进一步结合公式(3)、(4)、(5)、(6)和(7),可将fgb1、fgb2、fgb3推理过程表达如下:
[0127]
fgb1(k
m*n
)=fgb(st(k
m*n
) aux1(k
m*n
) aux1'(k
m*n
),s1,s
′1)
ꢀꢀꢀꢀꢀꢀ
(8)
[0128]
fgb2(k
m*n
)=fgb(fgb1(k
m*n
) aux2(k
m*n
),s1,s
′1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0129]
fgb3(k
m*n
)=fgb(fgb2(k
m*n
) aux3(k
m*n
),s1,s
′1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0130]
语义嵌套模块(seb):在高级语义通道最后阶段是一个语义嵌套模块,该模块使用了全局平均池化和跳跃连接结构,将高级语义通道和辅助语义通道提供的辅助语义信息进行深度融合,从而更有效的嵌入全局上下文信息,如图7所示。设seb(x)表示该模块的推理过程,as(x)为高级语义通道语义信息提取过程,则结合公式(10)可将as(x)推理过程表达如下:
[0131]
as(k
m*n
)=seb(fgb3(k
m*n
))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0132]
综上,可由高级语义通道提取h/32*w/32*128的高级语义特征as(k
m*n
)。
[0133]
上述三类语义信息均为图像的局部语义特征,具有互补性,为此需要将三者进行融合得到图像的全局语义信息,本发明通过采用特征加权聚合方法实现三类语义融合。
[0134]
具体融合原理如图8所示,当输入h*w*3的图像时,先通过三类语义通道提取语义特征,之后加权聚合过程如下:
[0135]
加权聚合原理分析
[0136]
设三类语义特征加权权重分别为ε1、ε2和ε3,其初值均设为1,运行中权重的改变由三类语义特征在验证集中测得的miou={miou1,miou2,miou3}自适应决定,具体更新规则为采用当前各通道的网络权重在验证集上求得miou,再由miou值根据如下公式(14)~(16)更新ε1、ε2和ε3。
[0137][0138][0139][0140]
如图8中down是一个步长为2的3*3卷积,up是一个放大倍数为2的上采样,设up(x)表示该上采样过程,则三类语义特征加权过程如下:
[0141][0142]
式中,
[0143]
[0144]
三类语义特征聚合
[0145]
如图8中表示将两种结果相乘后再进行步长为1的3*3卷积,设该卷积过程用conv1(x)表示,三类语义特征两两聚合过程分别用sa1(x)、sa2(x)和sa3(x)表示,最后复合过程用msa(x)表示,由公式(15)可得:
[0146][0147]
三向语义特征最后的复合过程可表达如下:
[0148]
msa(x)=sa1(x) sa2(x) sa3(x)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(18)
[0149]
综上,公式(15)~公式(18)完成了三类语义特征加权聚合的推理过程。
[0150]
为进一步提高训练速度和训练效果,本发明设计了一种新的增强训练模块,可增强训练阶段特征表示。如图9所示,在训练mcdwa_net网络时,将各通道输出特征进行上采样与网络最终输出结果共同计算损失进行随机梯度下降学习。
[0151]
传统语义分割中,一般采用cross-entropy损失函数进行梯度下降学习,如式(19)所示:
[0152][0153]
其中,p为真实数据,q为预测数据,c为类别数。
[0154]
然而cross-entropy损失函数在语义分割时,权重的更新会受到误差的影响。例如图像中前景像素远小于背景像素,式(19)中pi=0部分会占据主导,则会使训练出的模型偏向背景。
[0155]
为此,引入另一种损失函数dice loss如式(20)所示:
[0156][0157]
式(20)中,x为预测数据,y为真实数据。一般情况下使用dice loss损失函数会对反向传播不利,使训练过程不稳定,因此该损失函数应用并不多。
[0158]
然而通过实验发现,dice loss损失函数有一个特点即当图像中前景像素与背景像素数量不均衡时,该函数能恰好弥补cross-entropy损失函数的缺陷,消除偏差影响。为此,本发明将二者相结合,设计了一种基于cross-entropy与dice loss的联合损失函数,简称cedice损失函数。
[0159]
设x为预测数据,y为真实数据,n为类别数,α为权值,则公式如下:
[0160][0161]
则cedice损失函数可表达如下:
[0162]
ced(x,y)=cel(x,y) α*dl(x,y)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(22)
[0163]
cel(x,y)为cross-entropy交叉熵损失函数,dl(x,y)为dice loss铰链损失函数;由式(21)和式(22)可知,当语义分割中分割类别数为1时,相当于一个二分类,此时无需用到dice loss损失函数,因此,只有cross-entropy损失函数起作用;当语义分割类别数目越
大时,图像中会存在前景像素远小于背景像素,即图像中前景像素与背景像素数量不均衡的情况,此时加入dice loss损失函数的权值越大,会极大的降低像素不均衡的影响。
[0164]
综上,将本发明的综合训练机制中的损失函数替换为cedice损失函数,则最终的损失函数可设为:
[0165][0166]
式(23)中,t为真实标签,pre为mcdwa_net网络输出标签,a1、a2和a3分别为低级语义通道、辅助语义通道和高级语义通道的输出标签。
[0167]
以下针对不同的应用环境对本发明中的技术方案展开说明,本发明中仿真实验平台的硬件环境为intel core i7-10750 cpu,@2.6ghz,x6 cores,16gb ram,实验的运行环境为pytorch1.6.0。
[0168]
实施例1
[0169]
本实施例中主要进行cityscapes街景数据集实验。
[0170]
在仿真实验中,首先采用cityscapes街景数据集进行验证。该数据集共有18类街景和1类背景(总类别数为19),采用数据集中3475张图片及其标签进行训练、验证和测试。其中训练集、验证集和测试集图片数量分别为2975张、300张、200张。之后,制作了实验室走廊的实际场景数据集,该数据集共有7个走廊场景类和1个背景类(总类别数为8),共350张图片及其标签,300张用于训练模型,30张用于验证模型,20张用于测试模型。为充分表明本发明算法的有效性,分别与bisenet、bisenetv2、dfanet、deeplab v3和shufflenet v2算法进行了对比和分析。
[0171]
1)模型训练
[0172]
在用cityscapes街景数据集训练mcdwa_net模型时,设置训练批量batch_size为4,类别数为num_classes为19,迭代次数为epoches为500,学习策略采用随机梯度下降(sgd)算法,并设其动量为0.9,初始学习率设为0.05,权重衰减率为0.0001。
[0173]
在训练模型时,采用本发明提出的增强训练模块将各通道提取的三类语义特征应用公式(23)计算损失函数,并采用随机梯度下降法进行训练学习,训练过程中损失值变化如图10所示。
[0174]
2)模型性能评价指标
[0175]
首先引入平均交并比(mean intersection over union,miou)对模型的准确性进行评估,miou评估的是模型分割物体的精度,miou值越高则表示物体分割效果越好。计算方法如式(23)所示:
[0176][0177]
式中,k为类别数,fti表示第i个类别中预测错误且预测为真的样本数,ffi表示第i个类别中预测错误且预测为假的样本数,tti表示第i个类别中预测正确的样本数。
[0178]
本发明算法在cityscapes街景数据集上训练过程miou值变化如图11所示。
[0179]
3)模型消融实验
[0180]
在cityscapes街景数据集上完成消融实验,验证网络模型中各模块的有效性,并
利用cityscapes街景验证集进行算法评估。
[0181]
表2和图12是mcdwa_net在cityscapes街景数据集上的实验结果。表2中前三行表示仅使用一个通道时的分割精度和运算复杂度,低级语义通道无法获取图像的上下文逻辑关系特征,辅助语义通道仅能提取过渡语义信息,高级语义通道包含图像的上下文逻辑关系语义特征,但没有明确的类别信息,因此,这三种语义通道都无法获取图像完整的语义信息,必须将三类语义信息进行相融才能表达图像的完整语义信息,而融合方法结果也起到了至关重要的作用,如表2第4行的直接相加融合效果明显比第五行的语义特征加权融合效果差很多。但也可看出无论何种融合方法,融合后分割效果均明显优于各通道的分割效果,说明三个通道提取的语义信息具有局部性和互补性。
[0182]
此外,模型训练的方法也影响着模型的分割效果,用普通的训练方法比本发明的增强训练方法训练出的模型分割精度低0.6%。因此,一定程度上来说,本发明设计的增强训练方法也能提高训练模型的分割精度。综上,将三类互补的语义信息加权聚合后,图像的语义分割效果更好,分割精度更高,上下文信息表达更加明确。
[0183]
表2 mcdwa_net在cityscapes街景数据集上的消融实验
[0184][0185][0186]
4)模型性能对比实验
[0187]
将bisenet、bisenetv2、dfanet、deeplab v3和shufflenet v2算法在cityscapes街景数据集上训练出相应模型,采用传统训练策略进行训练。
[0188]
表3 mcdwa_net算法与先进算法在cityscapes街景数据集上的性能比较
[0189][0190]
表3展现了mcdwa_net和5种相对最新的语义分割算法性能指标对比结果。由表3可明显看出本发明所提的mcdwa_net算法分割精度高于其他5种算法,但其运算复杂度比bisenet、bisenetv2、dfanet算法更复杂,因此其推理速度稍慢于这三种算法,在算法精度和推理速度上均优于deeplab v3和shufflenet v2算法。
[0191]
上述6种算法具体分割效果如图13所示。由表3和图13可知,本发明中的算法虽然
小幅降低了推理速度,但大幅提升了分割精度,其miou最高可达80.4%,推理速度为16ms/帧。因此,综合性能更优、性价比更高,具有更好的实际应用价值。
[0192]
实施例2
[0193]
本实施例中主要进行实验室走廊场景数据集实验,实验室走廊场景数据集是自设场景建立的数据集。本实施例中的重要目的是验证本发明设计的增强训练模块的训练效果,在用实验室走廊场景数据集训练mcdwa_net模型时,设置训练批量batch_size为4,类别数为num_classes为8,迭代次数为epoches为500,学习策略采用随机梯度下降(sgd)算法,并设其动量为0.9,初始学习率设为0.05,权重衰减率为0.0001。
[0194]
利用本发明所提出的增强训练模块的cedice loss损失函数与单独使用cross entropy损失函数和dice loss损失函数训练结果最对比,验证本发明算法的优越性。训练过程损失值变化过程如图14所示,miou值变化过程如图15所示。此外,表4展现了各种损失函数的训练效果。
[0195]
表4三种损失函数训练效果比较
[0196][0197]
结合图14和表4可知,本发明设计的cedice loss损失函数在训练过程中循环训练90次即可让损失值降低90%以上,而cross entropy损失函数在训练过程中需要循环139次才能使损失值降低90%,dice loss损失函数在训练过程中需要循环141次才能使损失值降低90%,由此可见本发明所设计的损失函数能够更好的降低训练时的损失值。
[0198]
结合图15和表4可知,在实验室走廊场景数据集训练过程中,本发明中的增强训练模块使用cedice loss损失函数能够使模型miou最高达到95%,且仅需要循环训练9次即可使模型的miou提升90%,而cross entropy损失函数与dice loss损失函数能够使模型精度最高达到94.2%和82%,它们分别需要循环训练22次和298次才能使模型的miou提升90%,由此可见,本发明所设计的训练算法能够更快的使语义分割网络模型提升至更高精度,强于其他损失函数的单独应用。
[0199]
同时,本发明也将bisenet、bisenetv2、dfanet、deeplab v3和shufflenet v2算法在实验室走廊场景数据集上训练出相应模型,并与本发明算法性能进行比较,6种算法在实验室走廊场景数据集上的性能如表5所示,其对实验室走廊场景的分割效果如图16所示。
[0200]
表5 mcdwa_net算法与先进算法在实验室走廊场景数据集上的性能比较
[0201]
[0202]
表5中展现了本发明所提mcdwa_net算法虽然推理速度相对较慢,但其分割精度大幅提高,这几类算法具体分割效果如图16所示,本发明所提算法对图像的分割效果明显优于其他算法的分割效果。
[0203]
此外,本发明所提算法在分割精度上具有显著的提升,大大高于其他5种算法,且其运算复杂度相对较低,推理速度相对较快,再根据图15可看出(左图为较简单场景,右图为较复杂场景),在左图简单场景中本发明算法的优越性并不十分明显,但在右图复杂场景中,可显著看出其他5种算法对场景的语义分割均有缺陷,由于它们不能完整的提取图像的全局语义信息,从而导致分割效果相对欠佳。因此,在对实验室走廊场景的实验中,本发明所提算法的综合性能更优,分割精度更高,运行速度较快,从而进一步表明本发明算法在实际场景中的优越性。
[0204]
最后应说明的是:虽然本说明书包含许多具体实施细节,但是这些不应被解释为限制任何发明的范围或所要求保护的范围,而是主要用于描述特定发明的具体实施例的特征。本说明书内在多个实施例中描述的某些特征也可以在单个实施例中被组合实施。另一方面,在单个实施例中描述的各种特征也可以在多个实施例中分开实施或以任何合适的子组合来实施。此外,虽然特征可以如上所述在某些组合中起作用并且甚至最初如此要求保护,但是来自所要求保护的组合中的一个或多个特征在一些情况下可以从该组合中去除,并且所要求保护的组合可以指向子组合或子组合的变型。
[0205]
类似地,虽然在附图中以特定顺序描绘了操作,但是这不应被理解为要求这些操作以所示的特定顺序执行或顺次执行、或者要求所有例示的操作被执行,以实现期望的结果。在某些情况下,多任务和并行处理可能是有利的。此外,上述实施例中的各种系统模块和组件的分离不应被理解为在所有实施例中均需要这样的分离,并且应当理解,所描述的程序组件和系统通常可以一起集成在单个软件产品中,或者封装成多个软件产品。
[0206]
由此,主题的特定实施例已被描述。其他实施例在所附权利要求书的范围以内。在某些情况下,权利要求书中记载的动作可以以不同的顺序执行并且仍实现期望的结果。此外,附图中描绘的处理并非必需所示的特定顺序或顺次顺序,以实现期望的结果。在某些实现中,多任务和并行处理可能是有利的。
[0207]
以上所述仅为本公开的较佳实施例而已,并不用以限制本公开,凡在本公开的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本公开保护的范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。