1.本发明涉及复杂智能问答系统环境技术领域,是一种基于文本蕴含的多源答案校验方法。
背景技术:
2.在复杂智能问答系统环境中,为了保证答案的多样性,以确保正确答案会包含在答案集 合中,往往会存在多个不同种类的问答模块。这些问答模块往往相互独立,且各自的结构, 实现方法也并不一致。自动问答系统有望改变人类的信息获取方式,具有重要的理论和实际 应用价值。如何提高问答系统返回正确答案的能力是问答系统要解决的核心问题。
3.现有的问答系统实现,大多是基于深度学习方法,根据用户的提问以及系统中的实际问 答模块的原理,返回给用户最有可能的答案。由于这些方法只关心了答案的可能性,并没有 对得到的答案进行进一步的校验,例如:1)答案是否与问题相匹配,即答案的合理性。例如 问日期的问题,答案内容中应该包含有日期词。2)答案是否符合常识,即答案的合法性。例 如询问乒乓球比赛的比赛,答案如果类似于30:1,那就非常不合理。因此未来提高正确答案 的获得效果,非常有必要在现有方法的基础上,进一步对答案的正确性进行校验。
4.目前,面向问答系统的答案验证方法的研究还相对较少。现有提出的在阅读理解问答方 法返回最可能的答案的同时,返回答案所在句,通过进一步分析问题和答案所在句的关系, 来判断该问题是否得到了充分的回答。如果该问题已经被完整回答,则将答案返回给用户。 文献针对开放域问答系统,从多个阅读材料中获得的多个答案,提出利用答案之间的相互印 证关系,从中筛选出正确答案。这些方法都没有考虑答案与问题、问答对和上下文之间的关 系,无法提高正确答案的获取效果。针对阅读理解中选择题,首先根据问题和候选答案之间 的关系,得到候选答案的语义表示,再根据问题与阅读材料之间的关系,得到阅读材料的语 义表示,最后通过比较阅读材料和候选答案之间的关系,从多个候选答案中选择一个最可能 的答案。一方面由于一般的问答系统没有所谓的“候选答案”,因此无法直接使用。另一方 面,也没有考虑问答对与阅读材料之间的关系,效果有待提升。
5.1.目前的校验技术基本局限于基于阅读理解的问答系统。不能够处理其他类型的问答系 统(例如基于知识图谱或常见问题库的问答系统)。
6.2.目前的校验技术基本局限于训练语料,深度学习在训练语料规模不够大的情况下难以 学习到足够的语言信息,更难以学到问答对之间的逻辑关系。
7.3.基于深度学习的方法能够学到的全部信息都来自于训练集,并没有任何引入外部信息 的机制,导致了在处理分布和训练集不一致的测试集时,效果较差。
技术实现要素:
8.本发明为了能够对复杂问答系统提供答案校验服务,本发明充分利用知识图谱的
知识信 息,本发明提供了以下技术方案:
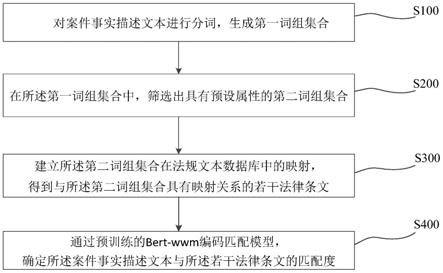
9.一种基于文本蕴含的多源答案校验方法,通过基于文本蕴含的答案校验模块,在整个问 答项目中处于下游位置,用来作为收尾,根据前期多意图识别以及问答模块,针对一个问题 输入得到多个不同来源的答案,通过答案校验模块对返回给用户具体回答进行筛选;
10.所述答案校验模块的输入为上游所有问答模块的输出,原始的问题以及被分类出的意图; 输出为部分经过筛选出的答案以及顺序,进行收尾统合,将不合格的答案进行筛选掉,并且 通过排序的方式给出用户最想看到的答案。
11.优选地,基于文本蕴含的答案校验模块基于文本蕴含识别任务,通过分析两个句子,包 括问题和其中一个回答之间的逻辑关系,判断文本蕴含性,进而确定问答的得分;
12.将每组的得分进行排序,加上问题意图对模块的加权,当询问运动员身高时,知识图谱 的可信度比文档问答要高,最终输出得分最高的那项。
13.优选地,以bert模型为基础的文本蕴含识别模型,作为计算两个句子之间蕴含性大小的 模型,所述模型的输入为两个句子,并通过特殊标记符号予以分割,得到的输出即为一串向 量序列,取其中的第一个标记,作为最终的输出。
14.优选地,选择描述问答对之间的文本蕴含关系的语料集,选择了qnli数据集作为构造 训练集的基础,给定一个问句,需要判断给定文本中是否包含该问句的正确答案,属于句子 对的文本二分类任务,需要一个中文的训练集,使用爬虫翻译为中文,构造出了需要的cqnli 语料集,并用作训练集。
15.本发明具有以下有益效果:
16.本发明是基于文本蕴含的多源答案校验技术。原生性地适合于任何的问答系统。本发明 使用的训练任务不是由单一的基于阅读理解的问答系统提出的不够完备的训练集所确定的。 而是使用了一种比较开发的通用文本理解任务,即文本蕴含识别任务。通过这样的方式,能 够很轻松地训练出能够校验所有问答系统的,训练集便于获取也足够完备的答案校验系统。 实际上,仅仅通过一个简单的问答文本蕴含训练集cqnli,的答案校验系统便能够将一个在 特定领域能够达到40%准确率的基于阅读理解的问答系统,提升到62%的准确率。
17.同时,本发明也注意到了,不同的问答系统原理上的不同,会导致在实际用户视角中, 其可信度有着一定的差别。所以本发明针对各类不同的提问意图,分别给出了不同的置信度。 通过这样的形式对于各种不同的问答系统进行整合。从而提高答案校验的效果。
附图说明
18.图1是常见的复杂智能问答系统;
19.图2是多源答案验证模块原理图;
20.图3是多源答案验证模块的算法流程;
21.图4是bert模型的使用方法;
22.图5是bert模型架构;
23.图6是bert模型中一个transformer结构的构成。
解)的问答模块,意即在相关领域的文档中,寻找最可能是答案的段落或句子或短语。faq 模块,即基于常见问题库的问答模块,意即在提前准备的常见问题库中,寻找最相似的问题, 并且输出由专家提前给出相关的答案。第三方问答模块,即一些比较专业的问答模块。例如 针对地点和路线提问的地图问答模块,保证了问答系统的时效性、可靠性,以及可拓展性。 为了能够对这样的复杂问答系统提供答案校验服务,本发明提出了多源答案校验方法。
40.基于文本蕴含的答案校验模块,在整个问答项目中处于下游位置,基本用来作为最后的 收尾。根据前期多意图识别以及后续多种问答模块,针对一个问题输入能够得到多个不同来 源的答案,那么返回给用户具体哪种回答就需要答案校验模块对回答进行筛选。
41.模块的整体思路如图2所示,答案校验模块的输入为上游所有具体问答模块的输出,原 始的问题以及其被分类出的意图。而输出为部分经过筛选出的答案,以及其顺序。也就是在 整个问答系统中用于最后的收尾统合,将不合格的答案进行筛选掉,并且通过排序的方式给 出用户最想看到的答案。
42.答案校验模块基于文本蕴含识别任务,通过分析两个句子(问题和其中一个回答)之间 的逻辑关系,判断其文本蕴含性,进而确定该问答对的得分。将每组的得分进行排序,再加 上问题意图对具体模块的加权(例如当询问运动员身高时,知识图谱的可信度就会比文档问 答要高),最终输出得分最高的那项。
43.其中,作为计算两个句子之间蕴含性大小的模型,即是以bert模型为基础的文本蕴含识 别模型。模型的输入为两个句子,并通过特殊标记符号予以分割。而得到的输出即为一串向 量序列。取其中的第一个标记,作为最终的输出。
44.分解来看,作为基础的bert,其内部结构即,其将一串输入序列,通过一共12层的双向 transformer结构网络,最终得到一串输出序列。由于网络是双向连接的,并且层数足够深, 模型能够学习到足够的语言学信息。将每个transformer展开,其内部结构可以看出,其内 部分为两层。第一层通过一个多头注意力层,并且与原始输入做一个残差连接和正则化。第 二层通过一个前向神经网络,并且与输入做一个残差连接并且通过正则化,得到输出。这样 的结构能够充分地捕捉到句子内部词与词之间的联系。
45.以上是模型部分。而有了合适的模型,还需要足够并且相关的语料进行训练。
46.为了选择能够更好地描述问答对之间的文本蕴含关系的语料集,选择了qnli数据集作为 构造训练集的基础。
47.qnli(question natural language inference),其前身是squad 1.0数据集,给定一 个问句,需要判断给定文本中是否包含该问句的正确答案。属于句子对的文本二分类任务。
48.由于的问答系统是基于中文环境的。所以需要一个中文的训练集。因此使用爬虫对其翻 译为中文,即构造出了需要的cqnli语料集。并将其用作训练集。
49.cqnli语料的数据形如下表1所示:
50.--------------------------------------------------------------
51.表1 cqnli数据集
[0052][0053]
最后,从用户的角度来说,在对路线进行提问时,地图类的问答模块往往相比其他的问 答模块更加可信,无论它回答内容如何。
[0054]
根据这点,提出了基于用户提问意图的问答模块置信度规则。根据用户在不同提问意图 情况下,对于每一个qa模块赋予不同的置信度。而最终每一个问答对的得分,即模型给出的 得分加上模块的置信度。该最终得分即作为对答案进行排序的依据。
[0055]
最终,对于单一问答对,先由模型给出一个基础得分,再加上一个模块的置信度得分。 最终的得分即作为用来筛选和排序的依据。
[0056]
具体实施例三:
[0057]
以一个完整的qa系统为例,用户输入的问题为:“今天北京的天气如何?”[0058]
就得到了这样一些回答,如下表2所示:
[0059]
表2各个qa模块对问题的回答
[0060][0061]
将其中的每一对问答对输入多源答案验证模型,就能得到每一个问答对的得分。结果如下 表3所示:
[0062]
表3多源答案校验模型对问答对的打分
[0063][0064]
接着查询对于“天气相关”类型的问题,各个模块的置信度得分为如下表4所示:
[0065]
表4多源答案校验模块对问答对类型的打分
[0066]
模块类型问题类型模块置信度dbqa天气相关0.6kbqa天气相关0.7faq天气相关0.7天气类api天气相关0.9
[0067]
将得分相加,即可得到各个问答对的最终得分,如下表5所示:
[0068]
表5多源答案校验模块最终得分
[0069]
模块类型问答对得分模块置信度最终得分dbqa0.90.61.5kbqa0.80.71.5faq0.70.71.4天气类api0.90.91.8
[0070] 可以看出,第三方天气类api给出的回答:“19~27℃小雨转阴,北风微风”,即最符合 这个问题的回答。
[0071]
基于文本蕴含的答案校验模型,不仅仅可以使用bert模型,还可以使用任何深度学习模 型,例如lstm、gpt等。
[0072]
模块置信度与问答对得分的融合方式,不仅仅可以使用简单相加相乘,还可以通过简单 训练的模型给出结果等。
[0073]
以上所述仅是一种基于文本蕴含的多源答案校验方法的优选实施方式,一种基于文本蕴 含的多源答案校验方法的保护范围并不仅局限于上述实施例,凡属于该思路下的技术方案均 属于本发明的保护范围。应当指出,对于本领域的技术人员来说,在不脱离本发明原理前提 下的若干改进和变化,这些改进和变化也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。