1.本公开涉及图形处理,更具体地,涉及图形处理单元(graphics processing unit,gpu)的着色器(shader)可访问可配置分箱(binning)子系统。
背景技术:
2.一些gpu可能主要基于两种通用架构:即时模式渲染(immediate mode rendering,imr)或基于图块的延迟渲染(tile based deferred rendering,tbdr)之一。也可以使用这些架构的混合。tbdr的特征可以是根据它们的(x,y)屏幕空间位置将输入的图元(primitive)(例如,由(x,y)坐标对的三元组定义的三角形)排序到箱(bin)或tile(图块)中。一旦排序,处理可以通过向每个图块查询在图块的屏幕空间扩展中找到的覆盖的图元的列表来继续。基于imr的gpu也可能有一些形式的分箱,用于改善存储器访问的深度和颜色缓冲区所需的存储器访问的一般高速缓存局部性。
3.在分箱操作中可以使用专用的硬件分箱器单元(binner unit)。分箱器单元可以接收图元流,并基于图元的屏幕空间位置继续将图元排序到箱的集合中。虽然通过将工作限制在空间上邻近的像素来提高缓存局部性,从减少后期存储器流量的角度来看,这可能是一种有效的操作,但在非图形(即计算)操作期间,这可能是固定功能硬件的空闲部分。
4.更一般地,现代gpu可以包括可编程的、高度并行的计算引擎的集合和各种固定功能单元的集合,其中的一些可以包括:纹理地址生成和过滤;图元裁剪、剔除、视口变换;分箱;光栅化(rasterization)设置和光栅化;深度比较;混合(blending);和其他操作。gpu可以用于图形密集型操作和计算密集型工作负载。然而,在后一种情况下,大多数固定功能的硬件可能闲置,仅仅消耗泄漏的功率。
技术实现要素:
5.本公开的各种实施例包括gpu的分箱子系统,其可以包括:存储子系统;着色器核心,被配置为经由第一路径输出第一数据;选择器,被配置为经由第一路径接收第一数据以及经由第二路径从存储子系统接收第二数据、分箱器单元;以及控制逻辑单元,被配置为控制选择器,并使选择器将第一数据或第二数据中的至少一个传送到分箱器单元。分箱子系统可以包括从分箱器单元到着色器核心的返回路径。分箱器单元可以被配置为经由返回路径将分箱器输出数据传送到着色器核心。
6.本文公开的一些实施例包括gpu的分箱方法,其可以包括由着色器核心经由第一路径输出第一数据。该方法可以包括由选择器经由第一路径接收第一数据。该方法可以包括由选择器经由第二路径从存储子系统接收第二数据。该方法可以包括由控制逻辑单元控制选择器。该方法可以包括由控制逻辑单元使选择器将第一数据或第二数据中的至少一个传送到分箱器单元。该方法可以包括经由返回路径将分箱器输出数据传送到着色器核心。
附图说明
7.参考附图,根据以下详细描述,本公开的前述和附加特征和优点将变得更加明显,附图中:
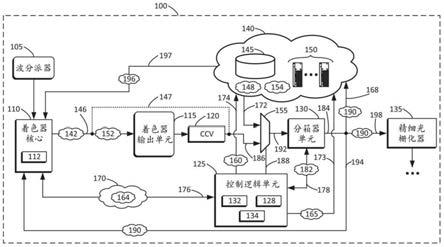
8.图1a示出了根据一些实施例的着色器可访问可配置分箱子系统的框图。
9.图1b示出了根据一些实施例的包括图1a的着色器可访问可配置分箱子系统的gpu。
10.图1c示出了根据一些实施例的包括具有图1a的着色器可访问可配置分箱子系统的gpu的移动个人计算机。
11.图1d示出了根据一些实施例的包括具有图1a的着色器可访问可配置分箱子系统的gpu的平板计算机。
12.图1e示出了根据一些实施例的包括具有图1a的着色器可访问可配置分箱子系统的gpu的智能电话。
13.图2是示出根据一些实施例的数据块的预固定求和(pre-fix sum)的曲线图。
14.图3是示出根据一些实施例的用于执行gpu基数排序(radix sort)算法的技术的流程图。
15.图4是示出根据一些实施例的用于执行gpu合并排序(merge sort)算法的技术的流程图。
16.图5是示出根据一些实施例的gpu的分箱技术的流程图。
具体实施方式
17.现在将详细参考本文公开的实施例,其示例在附图中示出。在下面的详细描述中,阐述了许多具体细节,以便能够彻底理解本发明构思。然而,应该理解,本领域普通技术人员可以在没有这些具体细节的情况下实践本发明构思。在其他情况下,没有详细描述公知的方法、过程、组件、电路和网络,以免不必要地模糊实施例的各个方面。
18.应当理解,尽管术语第一、第二等可以在本文中用于描述各种元件,但是这些元件不应该被这些术语所限制。这些术语仅用于区分一个元素和另一个元素。例如,第一设备可以被称为第二设备,并且类似地,第二设备可以被称为第一设备,而不脱离本发明构思的范围。
19.本文在描述本发明构思时使用的术语仅仅是为了描述特定的实施例,并且不是为了限制本发明构思。如在本发明构思的描述和所附权利要求中所使用的,单数形式“一”、“一个”和“该”旨在也包括复数形式,除非上下文清楚地另外指出。还应当理解,本文使用的术语“和/或”是指并包括一个或多个相关列出项目的任何和所有可能的组合。将进一步理解,当在本说明书中使用时,术语“包括”和/或“包含”指定所陈述的特征、整数、步骤、操作、元件和/或组件的存在,但是不排除一个或多个其他特征、整数、步骤、操作、元件、组件和/或其组合的存在或添加。附图的组件和特征不一定按比例绘制。
20.本文公开的一些实施例可以允许在计算算法期间重新调整分箱硬件的用途,并且使得分箱硬件对gpu的通用可编程部分可用,从而它可以参与各种计算算法,而不是简单地保持空闲。因此,泄漏和硅面积成本可以分摊,并且性能可以提高。
21.图1a示出了根据一些实施例的着色器可访问可配置分箱子系统100的框图。图1b
示出了根据一些实施例的包括图1a的着色器可访问可配置分箱子系统100的gpu 102。图1c示出了根据一些实施例的包括具有图1a的着色器可访问可配置分箱子系统100的gpu 102的移动个人计算机180a。图1d示出了根据一些实施例的包括具有图1a的着色器可访问可配置分箱子系统100的gpu 102的平板计算机180b。图1e示出了根据一些实施例的包括具有图1a的着色器可访问可配置分箱子系统100的gpu 102的智能电话180c。现在参考图1a至1e。
22.着色器可访问可配置分箱子系统100可以包括波分派器(wave dispatch)105、着色器核心110、着色器输出单元115、裁剪、剔除和视口(clipping,culling,and viewport,ccv)单元120、分箱器单元130、精细光栅化器135、存储子系统140、选择器155和/或控制逻辑单元125。例如,选择器155可以是多路复用器。存储子系统140可以包括易失性存储器(诸如系统存储器150)和/或非易失性存储器(诸如固态驱动器(solid-state drive,ssd)或其他物理存储介质145。应当理解,着色器可访问可配置分箱子系统100中可以包括其他组件。
23.可以从着色器核心110访问分箱器单元130。传统上,分箱器单元130可以具有固定功能操作,并且专用于服务所提供的图元流。在本文公开的一些实施例中,分箱器单元130可以连接到可编程着色器核心110和存储子系统140,使得分箱器单元130可以用作着色器核心110的协处理器,并且因此可以从着色器核心110接收任何数据作为输入。这种数据不必局限于(x,y)屏幕空间坐标对。
24.本文公开的一些实施例可以重新调整分箱硬件的用途,以用于计算工作负载和/或应用。例如,如下面进一步描述的,分箱器单元130可以用于基数排序和/或合并排序计算算法。几何工作可以由波分派块105提供给着色器核心110,并且着色器处理的结果可以被收集在着色器输出单元115中。该结果可以从着色器输出单元115传送到ccv单元120以用于变换。分箱器单元130可以对图元视口后变换(primitives post-viewport transformation)(即,在屏幕空间中)进行操作。在本文公开的一些实施例中,分箱器单元130还可以从来自存储子系统140或另一本地数据存储的单独数据流中读取。控制逻辑单元125可以经由链路174提供读取地址160,以用于从存储子系统140的读取访问。控制逻辑单元125可以经由链路173提供写入地址165,以用于对存储子系统140的写入访问。
25.分箱器单元130的一个或多个输入数据流可以从包括存储子系统140的一个或多个源到达。在一些实施例中,分箱器单元130可以受益于高速缓存层级。此外,分箱器单元130的输入可以从本地存储装置(诸如着色器核心110的寄存器文件112)或其他共享或私有本地存储装置到达。控制逻辑单元125中的地址生成逻辑128可以以直接存储器访问(direct memory access,dma)引擎方式运行,以直接为去往和/或来自分箱器单元130的输入和输出流生成地址序列(例如,160、165),或者与对着色器核心110的访问相结合。虽然着色器核心110可以具有主控制,但是控制逻辑单元125可以对分箱器单元130和选择器155提供更精细级别的控制。因此,分箱器单元130可以在其否则处于空闲时使用。控制逻辑单元125可以包括排序和仲裁逻辑134,排序和仲裁逻辑134用于与着色器核心110协作来控制分箱器单元130的使用。
26.控制逻辑单元125可以响应于着色器核心110,并且更具体地响应于一个或多个指令集架构(instruction set architecture,isa)级指令170,指令集架构级指令170可以提供用于加载一个或多个配置值164的装置,该一个或多个配置值164被维护在控制逻辑单元125中的寄存器132内,并且用于例如计算分箱器单元130数据流的读取和写入地址(例如,
160,165)。在一些实施例中,isa指令170可以类似于用于访问纹理的样本指令,用于图形和/或计算机程序。isa指令170可以用于设置和访问分箱结果190。与样本指令一样,isa指令170可以使着色器核心110能够直接访问分箱器单元130的固定功能逻辑,从而使用分箱器单元130推广该逻辑的使用。
27.可以添加isa指令170以使着色器核心110能够访问分箱器单元130。着色器核心110可以是可编程的,而分箱器单元130可以是固定功能硬件单元。固定功能硬件单元可以指这样一种硬件单元,尽管它是可配置的或模态的,并且因此响应于一组配置寄存器,但是它不必是可编程的。另一方面,着色器核心110可以是完全可编程的硬件单元。除了可能存在于一些架构中的图元流输入链路(primitive stream input link)(例如,186)之外,数据链路(例如,176、172)可以使得来自着色器核心110和/或存储子系统140的输入能够被路由到分箱器单元130。自分箱器单元130的输出路径(例如,184、194)可以使得分箱器单元130能够将分箱器输出数据190传送到着色器核心110。自分箱器单元130的另一输出路径(例如,184、168)可以使得分箱器单元130能够将分箱器输出数据190传送到存储子系统140。自分箱器单元130的又一输出路径(例如,184、198)可以使得分箱器单元130能够将分箱器输出数据190馈送到下游固定功能单元,诸如精细光栅化器(fine rasterizer)135。控制逻辑单元125可以通过经由链路178发送一个或多个控制信号182来直接控制分箱器单元130。控制逻辑单元125可以监督着色器核心110和分箱器单元130之间的排序交互。
28.控制逻辑单元125可以选择由分箱器单元130使用的用于将输入分配给箱(bin)的功能。控制逻辑单元125还可以负责处理分箱器单元130和着色器核心110之间的任何排序握手,以确保在读取数据之前完成操作,并且不会因为过早开始分箱器单元130的着色器核心110相关使用而破坏分箱器单元130的图形使用。此外,控制逻辑单元125可以确保分箱器单元130的图形使用不会干扰分箱器单元130的着色器核心110相关的使用。这些互锁(interlock)和保护措施的细节可以包括微架构方面。
29.着色器核心110可以经由路径197从存储子系统140接收存储数据196。控制逻辑单元125可以控制选择器155。选择器155可以是具有两个输入172和186的多路复用器。输入172可以直接来自存储子系统140。输入186可以直接来自ccv单元120。换句话说,选择器155可以经由链路172将数据从存储子系统140提供给分箱器单元130,和/或经由链路186将数据从ccv单元120提供给分箱器单元130。选择器155可以基于经由控制链路188从控制逻辑单元125接收的控制信号从输入172和186中进行选择。选择器155的输出192可以被提供给分箱器单元130。
30.此外,分箱器单元130可以是可配置的。例如,可以使用不同数量的排序输入键值(sorting input key),而不仅仅是图元的(x,y)坐标。作为控制逻辑单元125和分箱器单元130的操作的一部分,可以维护各种标识数据,诸如线程标识(id)或工作组元素,从而使得分箱器单元130的输出能够被适当地标记和/或标识,并且被正确地路由到目的地,无论是诸如存储子系统140的数据存储,还是直接到着色器核心110等。
31.编程模型可以包括提供作为更大算法的构建块的宏的集合。isa指令170可以对编译器可用。isa指令可以由一个或多个经调整的着色器核心(例如,110)使用,该一个或多个经调整的着色器核心可以提供合并排序、基数排序和/或由分箱器单元130扩充的其他操作,如下文进一步描述的。isa指令可以由驱动器打包和抽象化(abstracted),使得应用可
以调用功能,但不必能访问实现的细节。isa指令的一个或多个特性可能被隐藏,因此isa指令可以出现在早期的实现中,而不必被编入规范中。替代地,可以向应用提供更明确的指令。因此,编程模型可以类似于广义矩阵乘法(generalized matrix multiplication,gemm)包,它可以从应用中抽象出最底层的细节。
32.因此,isa指令170可以向着色器核心110提供对分箱器单元130的访问。附加的数据路径可以使得来自着色器核心110和存储子系统140的输入能够被路由到分箱器单元130。自分箱器单元130的新输出路径可以使得数据能够被返回到着色器核心110,和/或被写入到存储子系统140。控制逻辑单元125可以协调着色器核心110和分箱器单元130之间的排序交互。
33.在一些实施例中,着色器核心110可以被配置为经由路径146输出数据142。选择器155可以被配置为经由第一路径146经过着色器输出单元115和ccv 120接收数据142。替换地,选择器155可以被配置为经由路径147直接接收数据142。此外,选择器155可以被配置为经由路径172从存储子系统140接收数据148。控制逻辑单元125可以被配置为控制选择器155,并使选择器155将数据142和/或数据148传送到分箱器单元130。着色器核心110可以被配置为经由路径146输出一个或多个控制信号152。选择器155可以被配置为经由路径146接收一个或多个控制信号152,和/或经由路径172从存储子系统140接收一个或多个控制信号154。控制逻辑单元125可以被配置为使选择器155将一个或多个控制信号152和/或一个或多个控制信号154传送到分箱器单元130。分箱子系统100可以包括从分箱器单元130到着色器核心110的路径194。分箱器单元130可以被配置为经由路径194将分箱器输出数据190传送到着色器核心110。分箱子系统100可以包括从分箱器单元130到图形流水线的一个或多个后续阶段(例如,135)的路径198。分箱器单元130可以被配置为经由路径198将分箱器输出数据190传送到图形流水线的一个或多个后续阶段(例如,135)。分箱子系统100可以包括从分箱器单元130到存储子系统140的路径168。分箱器单元130可以被配置为经由路径168将分箱器输出数据190传送到存储子系统140。
34.在一些实施例中,着色器核心110可以被配置为控制控制逻辑单元125,并且控制逻辑单元125可以被配置为控制分箱器单元130。着色器核心110可以被配置为使用一个或多个isa指令170与控制逻辑单元125通信。一个或多个isa指令170可以提供用于将一个或多个配置值164加载到控制逻辑单元125的一个或多个寄存器132的装置。
35.控制逻辑单元125可以被配置为基于控制逻辑单元125的一个或多个寄存器132中的一个或多个配置值164来生成一个或多个读取地址160和/或一个或多个写入地址165。控制逻辑单元125可以被配置为使分箱器单元130基于一个或多个读取地址160从存储子系统140读取数据148。控制逻辑单元125可以被配置为使分箱器单元130基于一个或多个写入地址165将数据190写入存储子系统140。控制逻辑单元125可以包括地址生成逻辑128,并且可以被配置为使用地址生成逻辑128来控制对存储子系统140的访问。控制逻辑单元125可以包括排序和仲裁逻辑134,排序和仲裁逻辑134用于与着色器核心110协作来控制分箱器单元130的使用,从而减少计算数量并节省能量。
36.图2是示出根据一些实施例的数据块210相对于桶(bucket)205的预固定求和215的曲线图200。基数排序可以包括基于非比较的排序算法,这可以是一种有效的排序方法。可能需要一个或多个增强来将顺序基数排序算法实现为高效且高性能的并行gpu计算工作
负载。一个或多个增强可以包括:1)将输入数据集细分割成块以展示更大的并行性,和/或2)对数据块进行预排序以最大化与基数排序算法相关联的分散的局部性。例如,对32位整数进行每次4位排序的gpu基数排序算法可以包括如图3所示的以下步骤中的一个或多个。
37.图3是示出根据一些实施例的用于执行gpu基数排序算法的技术的流程图300。现在参考图1a、2和3。
38.在305,输入数据(例如,键值(key))可以被分割成大小相等、连续的固定大小的块210。可以设置块的大小,使得该块可以适合片上存储(例如,高速缓存、暂存(scratchpad)存储器等)。在310,每个数据块可以根据当前正在处理的连续位的数量(例如,四个)并行排序(例如,从最低有效的四位开始)。四位值等于0000的一些或所有键值可以排在第一位,然后是0001的键值,依此类推。此外,具有相同四位值的键值中的一些或所有键值可以按照它们最初出现的顺序出现。应当理解,可以使用不同数量的位,例如,两位值、五位值、六位值、八位值、16位值等。位数不必是2的幂。在315,对于每个数据块,可以创建直方图,其可以计数有多少个键值具有每个可能的四位值(例如,总共2^4=16个可能的桶)。315处的直方图创建可以与310并行执行。例如,在320,可以根据图2对每个块的直方图进行预固定求和。使用在320生成的预固定求和结果215,在325,每个块的键值可以被写入正确的输出位置。在330,可以对下一组位(例如,四位组)重复步骤305至325,直到所有组位都被处理。对于每次处理四位的32位键值,可以执行步骤305至325的总共八次迭代。每个连续迭代的输入可以是在前一次迭代的325产生的输出。
39.上述步骤310不需要在功能上是必需的。换句话说,排序仍然可以在没有步骤310的情况下工作,但是如果数据没有根据当前正在处理的四位键值进行排序(即,如果310被移除),则在325发生的写入可能更加分散,从而导致不太有效的排序性能。在310执行的预排序可以在325改善散点的局部性,并且可以导致更好的整体性能。因此,步骤310可以与gpu基数排序算法一起使用。
40.(图1a的)分箱器单元130可以用于评估上述算法中的步骤310和/或315。步骤310可以根据每个键值中连续的一组位对输入键值进行排序。诸如分箱器单元130的硬件分箱器可以将图元作为输入,并根据每个图元的(x,y)屏幕空间位置对它们进行排序。在该示例中,输入可以是图元,并且分箱功能可以将图元映射到它们在屏幕上出现的图块。类似地,在310,输入可以包括键值的块(例如,32位无符号整数),并且分箱功能可以包括当前正在处理的四位的值。就其输入和/或输出以及分箱功能而言,可以使分箱器单元130更加灵活和/或可配置。例如,分箱器单元130可以用于对键值块进行排序,正如可以在310执行的那样。此外,在一些增强中,分箱器单元130还可以跟踪有多少输入被映射到每个箱,这可以在315处执行。
41.替换地,在315创建的直方图可以使用软件产生(即,不使用分箱器单元130),但是这可能不那么有效。软件产生直方图的一种方式是让多个着色器核心110线程处理给定的块更新,并最终为该块产生一个直方图。这种方法可以包括原子存储器递增操作(increment operation),因为两个或更多线程可以尝试同时递增直方图的相同的箱和/或桶(bucket)。由于与导致串行化的原子操作相关联的依赖性,原子操作通常不能在现有的gpu上执行。
42.产生直方图的另一种方式(这避免了原子性)可以是每个线程产生其自己的局部
直方图,然后将这些直方图相加和/或组合和/或减少成一个最终直方图。尽管这种方法避免了原子性,但它可能引入附加地指令开销来执行每个线程直方图的缩减,并且还可能使用更多的存储器来容纳每个线程的直方图。此外,缩减本身可能依赖于处理块的线程之间的同步。尽管可能支持这种类型的同步,但它可能会导致性能和/或效率损失。让(图1a的)分箱器单元130执行基数排序算法的步骤310和315的功能,并将数据返回给着色器核心110(图1a的着色器核心110,例如,经由存储器或片上存储),可以避免与软件方法相关联的若干性能和/或效率问题。
43.图4是示出根据一些实施例的用于执行gpu合并排序算法的技术的流程图400。现在参考图1a和图4。
44.合并排序也可以用作排序算法。合并排序算法可以如下进行:
45.在405,输入数据(例如,键值)可以被分割成相等大小的、连续的、固定大小的块。可以设置块的大小,使得该块可以适合片上存储(例如,高速缓存、暂存存储器、图1a的存储子系统140等)。这可以与上面图3中描述的基数排序算法的步骤305相同。在410,每个数据块可以被并行排序。虽然类似于上面图3中描述的基数排序的步骤310,但是步骤410可以对块中的键值执行完全排序,而不仅仅是根据键值中当前组连续位进行排序。在415,可以并行合并经排序的数据块。分箱器单元130可以用于合并排序算法的步骤410。通过分箱器单元130的多次使用,每次对键值中不同的连续组位进行操作,每个块中的数据可以被完全排序(full sort)。410处的完全排序可以通过基数排序来完成,基数排序的每一遍使用分箱器单元130来完成。例如,每次四位处理32位键值可以导致分箱器单元130的八次连续使用,其中每次连续使用的输入可以是前一次的输出。应当理解,32位键值可以每次处理两位,每次处理五位,每次处理六位,每次处理八位等。每次处理的位数不必是2的幂。
46.另一个实施例可以包括许多图元的高质量透明性,这可以使用用于深度排序(随后是渲染和混合)的分箱器单元130来执行——优点在于排序操作可以作为流水线的一部分来完成,从而避免昂贵的数据移动或基于软件的中央处理器(central processing unit,cpu)侧排序算法。
47.上面呈现的排序算法可以是gpu计算工作负载中的分箱器单元130的一些用例。可以使分箱器单元130更加灵活和/或可配置,使得gpu计算算法可以使用分箱器单元130来使算法更快和/或更有效。例如,gpu可能变得更节能和/或更省电。
48.在计算工作负载期间,分箱器单元130不需要保持空闲,并且可以用于各种算法。这可以导致较少浪费的泄漏,并且还提供可以受益于分箱器单元130功能(例如,某些排序问题)的某些算法的更快执行。与基于软件的排序算法相比,分箱器辅助算法可以避免原子存储器访问的成本,原子存储器访问可能是能量密集型的,速度慢,并且延迟长。
49.图5是示出根据一些实施例的gpu的分箱技术的流程图500。在505,着色器核心可以经由第一路径输出第一数据。在510,选择器可以经由第一路径接收第一数据。在515,选择器可以经由第二路径从存储子系统接收第二数据。在520,控制逻辑单元可以控制选择器。在525,控制逻辑单元可以使选择器将第一数据和/或第二数据传送到分箱器单元。在530,分箱器单元可以经由第三路径将分箱器输出数据传送到着色器核心。在535,分箱器单元可以经由第四路径将分箱器输出数据传送到图形流水线的一个或多个后续阶段。在540,分箱器单元可以经由第五路径将分箱器输出数据传送到存储子系统。
50.应当理解,图3至图5的步骤不需要以所示的顺序执行,并且可以存在中间步骤。
51.结合本文公开的实施例描述的方法或算法的块或步骤以及功能可以直接实施在硬件、由处理器执行的软件模块或两者的组合中。模块可以包括硬件、软件、固件或其任意组合。如果以软件实现,功能可以作为一个或多个指令或代码存储在有形的、非暂时性的计算机可读介质上或通过其传送。软件模块可以驻留在随机存取存储器(random access memory,ram)、闪存、只读存储器(read only memory,rom)、电可编程rom(electrically programmable rom,eprom)、电可擦除可编程rom(electrically erasable programmable rom,eeprom)、寄存器、硬盘、可移动磁盘、cd rom或本领域已知的任何其他形式的存储介质中。
52.下面的讨论旨在提供一个或多个合适的机器的简要概括描述,在这些机器中可以实现本发明构思的某些方面。典型地,一个或多个机器包括系统总线,处理器、存储器(例如,ram、rom或其他状态保持介质)、存储设备、视频接口和输入/输出接口端口附接到该系统总线。一个或多个机器可以至少部分地通过来自传统输入设备(例如键盘、鼠标等)的输入来控制,以及通过从另一台机器接收的指令、与虚拟现实(virtual reality,vr)环境的交互、生物反馈或其他输入信号来控制。如本文所使用的,术语“机器”旨在广泛地包含单个机器、虚拟机或通信耦合的机器、虚拟机或一起操作的设备的系统。示例性机器包括计算设备(诸如个人计算机、工作站、服务器、便携式计算机、手持设备、电话、平板电脑等)以及运输设备(诸如私人或公共交通工具,例如汽车、火车、出租车等)。
53.一个和多个机器可以包括嵌入式控制器,诸如可编程或不可编程逻辑器件或阵列、asic、嵌入式计算机、卡等。一个或多个机器可以利用到一个或多个远程机器的一个或多个连接,诸如通过网络接口、调制解调器或其他通信耦合。机器可以通过物理和/或逻辑网络(诸如内联网、互联网、局域网、广域网等)互连。本领域技术人员将理解,网络通信可以利用各种有线和/或无线短程或远程载波和协议,包括射频(radio frequency,rf)、卫星、微波、电气和电子工程师协会(institute of electrical and electronics engineers,ieee)545.11、光、红外、电缆、激光等。
54.本公开的实施例可以通过参考或结合包括函数、过程、数据结构、应用程序等的相关数据来描述,相关数据当被机器访问时,导致机器执行任务或定义抽象数据类型或低级硬件上下文。相关数据可以存储在例如易失性和/或非易失性存储器(例如ram、rom等)或其他存储设备及其相关存储介质(包括硬盘、软盘、光存储器、磁带、闪存、记忆棒、数字视频盘、生物存储器等)中。相关数据可以以分组、串行数据、并行数据、传播信号等形式在传输环境(包括物理和/或逻辑网络)上递送,并且可以以压缩或加密格式使用。相关数据可以在分布式环境中使用,并存储在本地和/或远程以供机器访问。
55.已经参考图示的实施例描述和图示了本公开的原理,将会认识到,在不脱离这些原理的情况下,图示的实施例可以在布置和细节上进行修改,并且可以以任何期望的方式进行组合。尽管前面的讨论集中在特定的实施例上,但是也可以考虑其他配置。具体而言,即使在本文中使用了诸如“根据本发明构思的实施例”等表述,这些短语通常是指实施例的可能性,而不是旨在将本发明构思限制于特定的实施例配置。如本文所使用的,这些术语可以指可组合到其他实施例中的相同或不同的实施例。
56.本公开的实施例可以包括非暂时性机器可读介质,其包括可由一个或多个处理器
执行的指令,该指令包括用于执行本文描述的发明构思的元素的指令。
57.前述说明性实施例不应被解释为限制其发明构思。尽管已经描述了几个实施例,但是本领域技术人员将容易理解,在本质上不脱离本公开的新颖教导和优点的情况下,对这些实施例的许多修改是可能的。因此,所有这些修改都旨在包括在如权利要求所定义的本公开的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。