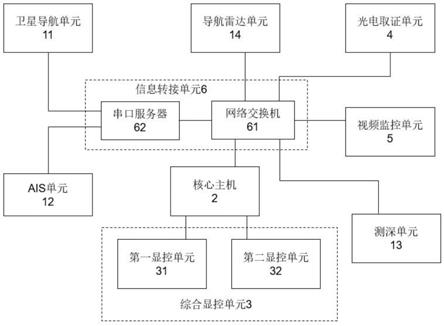
1.本发明涉及视频分析领域中的个体序列情绪识别问题,尤其是涉及一种融合表情和姿态的多流神经网络对个体序列情绪分类的视频分析方法。
背景技术:
2.情绪识别旨在使计算机拥有能够感知和分析人类的情绪和意图的能力,从而在娱乐、医疗、教育、公共安全等领域发挥作用。情绪的表达方式不是孤立存在的,其中,面部表情和身体姿态的组合视觉渠道被认为是判断人类行为线索的重要渠道。面部表情可以最直观地反映出人们的情绪状态和心理活动,是表达情绪的重要方式,然而真实环境中的无关因素会对面部情绪的识别产生很大影响;身体姿态的活动性比面部复杂,表达的情绪不如面部表情直观,但是在情感表达中同样具有诊断性。
3.视频大量存在于现实生活之中,如无人机视频监控,网络共享视频,3d视频等。通过对视频中人们的情绪分析有助于动态的了解视频中的人们的情感及情绪的变化,有着广阔的应用前景。例如在机场、地铁、公园等人流量大的场所进行情绪监测可以帮助识别潜在威胁,及时处理突发事件。
4.传统的基于表情和姿态个体情绪识别方法主要是人工构建和提取特征,特征维数过大,计算复杂,处理海量真实场景的视频数据十分困难。深度学习(deep learning)是一个近几年备受关注的研究领域,在机器学习中起着重要的作用。深度学习通过建立、模拟人脑的分层结构来实现对外部输入的数据进行从低级到高级的特征提取,从而能够解释外部数据。深度学习强调网络结构的深度,通常有多个隐藏层,以用来突出特征学习的重要性。与人工规则构造特征的浅层结构相比,深度学习利用大量的数据来学习特征,更能够描述数据特有的丰富的特征信息。我们还可以通过学习一种深层非线性网络,实现复杂模型的逼近,表征输入数据分布式表示。
技术实现要素:
5.本发明的目的是提供一种视频序列中个体情绪识别的方法,将深度学习与视频个体情绪相结合,充分发挥深度学习自我学习的优势,有效融合面部表情和身体姿态表达的情绪信息,可以解决目前浅层学习的参数难以调整,需要人工选取特征,公共空间个体情绪识别准确率不高的问题。
6.为了方便说明,首先引入如下概念:
7.个体序列情绪分类:对于视频序列中个体的情绪进行分析,将每个个体划分到正确的情绪类别之中。根据实际需求不同,可定义不同的个体情绪类别。
8.卷积神经网络(cnn):受视觉神经机制的启发而设计的,是为识别二维形状而设计的一种多层感知器,这种网络结构对平移、比例缩放、倾斜或者其他形式的变形具有高度不变性。
9.多任务卷积神经网络(mtcnn):主要采用三个级联的网络,采用候选框加分类器的
思想,进行快速高效的人脸检测。
10.深度可分离卷积神经网络(xception):为了更加有效地利用模型参数,深度学习领域发展出了深度可分离卷积(depthwise separable convolution),将传统的卷积操作分成了两步;网络中残差连接模块还能加快收敛过程。
11.深度三维卷积神经网络(c3d):利用沿时间轴共享权值的3d卷积核代替传统的2d卷积核,简单高效地学习时空特征,并且可以同时对外观和运动进行建模。
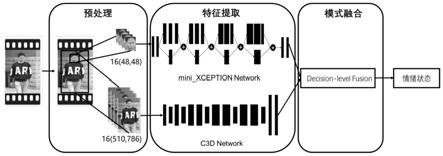
12.多模态个体序列情绪识别网络:通过多个并行的子神经网络提取个体序列表情和姿态的特征,然后将多个子神经网络进行加权融合形成多流神经网络。
13.数据集:公共空间个体情绪数据集scu-fabe。
14.本发明具体采用如下技术方案:
15.提出了一种融合表情和姿态的个体情绪识别方法,该方法的主要特征在于:
16.a.将视频序列处理成表情序列和姿态序列以提取不同特征;
17.b.采用针对性的神经网络分别提取表情和姿态的特征;
18.c.采用加权的方法融合b中的表情和姿态特征以预测个体情绪;
19.该方法主要包括以下步骤:
20.a.将视频数据集分为训练集和测试集,并贴上定义好的几个情绪类别标签;对视频序列进行预处理,其中通过人脸检测等视频分析技术获取人脸序列,完整个体序列为姿态序列;
21.b.采用2通道(表情通道,姿态通道)多模态个体序列情绪识别网络分别提取表情和姿态的特征,其中表情通道处理分辨率为48
×
48的人脸序列,姿态通道处理分辨率为510
×
786的身体序列;加权融合表情和姿态特征进行个体的视频序列情绪分类;
22.c.将训练集的表情序列和姿态序列分别输入多模态个体序列情绪识别网络的两个通道,完成整个网络的训练,最后融合,保存生成的网络与网络参数模型,以用于预测;
23.d.利用多模态个体序列情绪识别网络和步骤c中生成的网络参数模型,将待识别的视频的表情序列和姿态序列分别输入,融合两通道的分类结果来预测该视频的个体情绪类别。
24.优选地,在步骤a中的情绪类别标签包括消极、中性、积极。
25.优选地,在步骤a中数据预处理包括:采用多任务卷积神经网络(mtcnn)对每一个个体序列进行面部检测得到表情序列;对表情序列和姿态序列进行尺寸处理,其中表情序列图片分辨率为48
×
48,姿态序列图片分辨率为510
×
786。
26.优选地,在步骤b中采用深度可分离卷积神经网络(mini xception)为表情通道的基础网络,采用深度三维卷积神经网络(c3d)作为姿态通道的基础网络,对两通道网络采用7:3的权重融合得到多模态个体序列情绪识别网络。
27.优选地,在步骤c中训练时采用10%自动对比度和逆时针旋转5度的方法进行训练数据的扩充。
28.优选地,在步骤d中预测时对视频序列的表情序列和姿态序列分别分类处理,然后对两个通道的分类结果采用7:3的权重融合得到最终的个体情绪类别预测结果。
29.本发明的有益效果是:
30.(1)充分发挥深度学习的自我学习优势,机器自动学习良好的特征。当输入视频时
能够快速准确地提取特征,并行抽取多种特征,加权融合分类,避免了人工提取特征的局限性,适应能力更强。
31.(2)利用多模态个体序列情绪识别网络的结构特征,对网络进行训练,预测,最后对结果进行融合,可以大大的减少训练所需时间,增加工作效率。
32.(3)结合多流深度学习网络,有效融合多种特征(表情,姿态等),使分类结果更加准确、可靠。
33.(4)将深度学习与视频个体情绪分类相结合,解决传统方法在公共空间情绪识别中准确率不高,泛化能力差等问题,提高研究价值。
附图说明
34.图1为本发明的融合表情和姿态的个体情绪识别方法的流程图;
35.图2为多模态个体序列情绪识别网络的组成图;
36.图3为本发明方法在测试集上表情通道、姿态通道、两通道按7:3的权重融合的分类结果混淆矩阵。
具体实施方式
37.下面通过实例对本发明作进一步的详细说明,有必要指出的是,以下的实施例只用于对本发明做进一步的说明,不能理解为对本发明保护范围的限制,所属领域技术熟悉人员根据上述发明内容,对本发明做出一些非本质的改进和调整进行具体实施,应仍属于本发明的保护范围。
38.图1中,融合表情和姿态的个体情绪识别方法,具体包括以下步骤:
39.(1)将视频序列数据集分为消极,中性,积极三个不同的个体情绪类别,将分好等级的数据集按5:5的比例分为训练集、测试集,并制作数据标签。
40.(2)分别将上述步骤(1)中各数据集的视频序列进行人脸检测处理获取人脸序列,完整个体序列为姿态序列,并进行尺寸统一处理。
41.(3)利用不同的网络通道处理人脸序列和姿态序列,本方法具体使用表情通道处理分辨率为48
×
48的人脸序列,姿态通道处理分辨率为510
×
786的姿态序列,最后采用7:3的权重融合两个通道得到本方法的多模态个体序列情绪识别网络。
42.(4)训练:其中采用mini xception作为表情通道的基础网络,c3d作为姿态通道的基础网络,对两通道网络加权融合得到多模态个体序列情绪识别网络,然后从上述步骤(2)处理过的训练集中取1/10的数据对多模态个体序列情绪识别网络微调,验证输入数据是否有效,如果无效则重新生成输入数据。接着利用步骤(2)中训练集对多模态个体序列情绪识别网络进行训练。最后得到训练完成的网络的参数模型,用于预测网络。
43.(5)多模态个体情绪识别网络加载步骤(4)中得到的网络参数模型。
44.(6)将上述步骤(2)的测试集视频的人脸序列和姿态序列分别输入预测网络的两个通道。
45.(7)将两个通道得到的结果采用7:3的权重融合得到预测结果。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。