1.本发明涉及用于通过所谓的模糊测试来对程序代码进行测试的方法。本发明尤其涉及用于选择用来对特定的程序代码进行模糊测试的模糊测试方法的措施。
背景技术:
2.一种用于探测在计算机系统上执行的可以以软件或硬件实现的程序代码中的错误的常规方法在于:借助于模糊测试过程有关程序执行错误或者系统崩溃来检查该计算机系统。在此,为该计算机系统生成所谓的模糊测试输入,用这些输入来执行待测试的程序代码并且监控该程序代码的算法的功能。监控程序代码的执行包括:查明算法的运行是否导致程序执行错误、也就是说例如系统崩溃或意外的执行停止。
3.在执行程序期间,监控程序流的内部行为,尤其是关于通过程序代码执行的程序流路径来监控程序流的内部行为。用不同的输入来重复该过程,以便获得关于该程序代码针对各种输入的行为的信息。程序代码监控的目标在于:将这些输入生成得使得实现对程序流路径的尽可能大的覆盖,也就是说在这些输入的重复变化期间经历数目尽可能多的程序流路径。
4.如果在执行程序代码期间发生错误或意外行为,则这被模糊测试工具识别出,并且报告相对应的信息,这些信息说明了是哪个模糊测试输入导致了错误。
技术实现要素:
5.按照本发明,规定了一种按照权利要求1所述的用于选择用来执行模糊测试的模糊测试方法的计算机实现的方法以及一种按照并列权利要求所述的用于训练基于数据的模糊测试选择模型来选择模糊测试方法的方法以及一种按照并列权利要求所述的相对应的装置。
6.其它的设计方案在从属权利要求中说明。
7.按照第一方面,规定了一种用于选择用来执行对预先给定的程序代码的模糊测试的模糊测试方法的计算机实现的方法,该方法具有如下步骤:
‑ꢀ
提供程序代码指标,所述程序代码指标表征待测试的程序代码;
‑ꢀ
将所述程序代码指标应用于基于数据的模糊测试选择模型,用来为多种模糊测试方法确定被分配给所述模糊测试方法的性能指标,其中所述基于数据的模糊选择模型被训练来针对所述模糊测试方法中的每种模糊测试方法来输出性能指标;
‑ꢀ
选择与所分配的性能指标相对应的一种或多种模糊测试方法;
‑ꢀ
根据所选择的所述一种或多种模糊测试方法来执行模糊测试。
8.按照另一方面,规定了一种用于训练基于数据的模糊测试选择模型的方法,该方法具有如下步骤:
‑ꢀ
从预先给定的程序代码集中提供程序代码;
‑ꢀ
根据预先给定的模糊测试方法,执行对所述程序代码的模糊测试过程;
‑ꢀ
为每个程序代码的每个被执行的模糊测试过程确定性能指标;
‑ꢀ
为所述程序代码中的每个程序代码确定一组一个或多个程序代码指标,使得形成训练数据集,所述训练数据集分别针对模糊测试方法和用所述模糊测试方法来测试的程序代码将一组所述一个或多个程序代码指标分配给相对应的性能指标;
‑ꢀ
基于所述训练数据集来创建所述基于数据的模糊测试选择模型,使得给一组一个或多个程序代码指标分配性能指标。
9.公知多种模糊测试方法,这些模糊测试方法基本上可以细分为源代码模糊测试类和协议模糊测试类。源代码模糊测试用于查找程序代码中的错误,其中试图就不符合期望的程序流而言对程序代码中的尽可能多的程序流路径进行测试。在协议模糊测试的情况下,监控程序代码的通信,其方式是使通信消息延迟、对通信消息进行拦截、篡改等等,以便引发不符合期望的系统行为。在此,模糊测试软件用作待测试系统的两个子单元之间的中间人(man-in-the-middle)单元。
10.对于源代码模糊测试来说,目前公知在不同的模糊测试软件工具中实现的模糊测试方法。这种模糊测试软件工具的示例是american fuzzing lop、libfuzz或honggfuzz。
11.此外,模糊测试过程可以用不同的种子文件作为输入来开始,这些种子文件显著影响模糊测试的过程。模糊测试主要基于随机性,使得所选择的种子文件以及在测试期间的随机选择使模糊测试方法之间的比较变得困难。
12.因而,对于模糊测试软件工具的比较来说,应该使用相同的种子文件。
13.种子文件代表最小数量的有效输入。基于相同输入的程序应该提供相同的种子文件。这尤其适用于像png、jpg、pdaf、avi、mp3、gif那样的媒体格式,但是也适用于像pdf、elf、xml、sql等等那样的其它数据结构。
14.模糊测试软件工具也应该针对所使用的相同输入类型的种子文件使用相同的字典(dictionary)。字典包括针对特定输入、诸如错误注入模式(fault injection patterns)等等的规范集,而且尤其包含以字符、符号、词语、二元值字符串等等为形式的条目,这些条目通常是针对待测试软件的输入值的组成部分。不仅存在例如用于pdf、elf、xml或sql解析器的通用字典,而且存在只用于一个软件的单独的字典。字典作为辅助工具用于模糊器,以便生成如下输入,这些输入引起在待测试软件中的更长的执行路径。
15.因此,通过所使用的模糊测试软件工具、种子文件和字典来表征模糊测试方法。根据其可区分模糊测试方法的其它方面包括模糊测试参数,如可用内存的限制、每个测试用例的超时设置、模糊测试工具的模式或启发式选择、语法的使用,等等。附加标准可涉及模糊测试的测试时间、在其上运行模糊测试软件工具的数据处理平台及其配置。
16.现在,上述方法的思路在于提供一种模糊测试选择模型,该模糊测试选择模型能够实现:以基于统计特征来表征程序代码的程序代码指标为基础,选择并且配置适合于模糊测试的模糊测试方法。
17.为此,这些程序代码指标例如可包括如下指标中的一个或多个:代码行数、圈复杂度、程序流路径的平均数量、单次执行时间、加载时间、程序代码大小、潜在危险函数调用(例如memcpy)次数、内存访问次数,等等。
18.借助于基于数据的模糊测试选择模型,得到不同模糊测试方法的性能指标,这些性能指标通过该模糊测试选择模型来被分类。根据性能指标,可以确定这些模糊测试方法
中的一个或多种,用于对所提供的程序代码进行模糊测试。这种性能指标可以包括或取决于:程序流路径的覆盖率(coverage),尤其是功能覆盖率、程序行覆盖率或路径覆盖率;所执行的程序流路径的数目;找到的不同错误的数目;和平均模糊测试执行时间。
19.这样,尤其可以选择获得了该性能指标的最高值的模糊测试方法,用于进行模糊测试。
20.基于数据的模糊测试选择模型可以是分类模型并且例如借助于神经网络来被设计。替选地,模糊测试选择模型也可以被提供作为线性回归或查找表(分配函数),该线性回归或该查找表说明了在过去哪种模糊测试方法最好。
21.对模糊测试选择模型的训练可以基于数据地进行。为此,例如在程序代码集中提供程序代码,这些程序代码可包括代码片段、代码示例或者真实软件。这些程序代码应该分别配备至少一个人为或已知的真实错误(cve:通用漏洞披露(common vulnerabilities and exposures)),当相对应的程序流路径被执行时,该真实错误导致程序中断。
22.对用于训练模糊测试选择模型的程序代码集的选择可以固定地预先给定,或者该程序代码集可以根据所要评估的性能指标基于强化学习方法来被选择。为了进行训练,创建训练数据集,其中首先为该程序代码集的程序代码确定程序代码指标。
23.如果在对模糊测试选择模型的训练期间所观察到的性能指标(例如覆盖率)不再发生变化(或者变化得太少)而且接着针对下一次模糊测试运行使程序(例如超时)轻微适配以便(希望)使性能指标最大化,则可以应用强化学习。
24.此外,借助于所提供的模糊测试方法中的每种模糊测试方法,对所提供的程序代码集的程序代码中的每个程序代码进行测试。在相同的条件下进行测试,也就是说假设工作能力相同的数据处理装置和相同的测试时长。然后,关于性能指标中的一个或多个来评估测试结果。
25.现在,基于数据的模糊测试选择模型可以被训练,尤其是被训练作为分类模型,其中程序代码指标被映射到输出向量上,该输出向量针对这些模糊测试方法中的每种模糊测试方法都预先给定相对应的性能指标。
附图说明
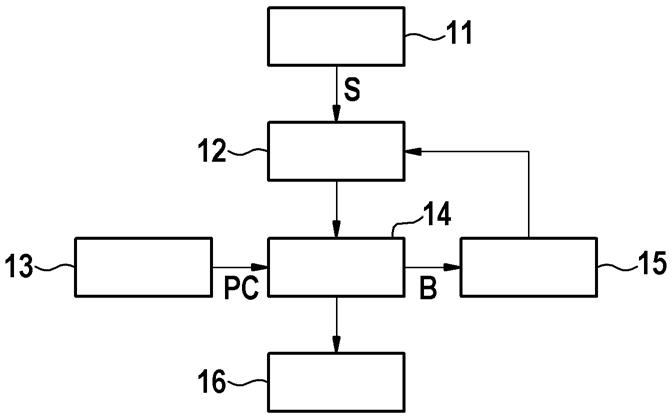
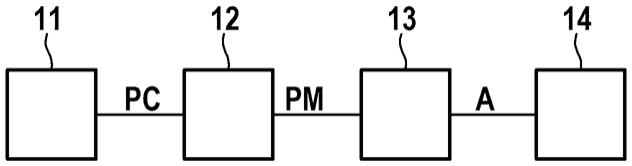
26.随后,依据随附的附图更详细地阐述实施方式。其中:图1示出了阐明用来选择用于测试程序代码的模糊测试方法的系统的框图;图2示出了阐明用来选择用于对预先给定的程序代码的模糊测试的模糊测试方法的方法的流程图;图3示出了阐明用于训练模糊测试选择模型的系统的功能的框图;以及图4示出了阐明用于训练模糊测试选择模型以在图3的系统中使用的方法的流程图。
具体实施方式
27.图1示出了阐明用来选择用于对预先给定的程序代码的模糊测试的一种或多种模糊测试方法的功能的框图。随后,依据图2的流程图更详细地描述该功能。该系统的方法和功能性在数据处理装置中被提供。
28.在步骤s1中,提供程序代码pc。程序代码pc可对应于代码片段、代码示例或者真实软件,该真实软件应该借助于模糊测试来被测试。程序代码pc可以由程序代码存储器11以可调用的方式提供。为了执行模糊测试,需要程序代码可编译、可解读并且可执行。
29.在步骤s2中,在分析块12中根据预先给定的程序代码来确定程序代码指标pm。程序代码指标pm可包括如下指标中的一个或多个:圈复杂度、指令路径长度(总程序路径长度的机器代码指令的数目)、代码行数、程序执行时间、程序加载时间和程序大小(以字节为单位)。程序代码指标pm被选择为使得这些程序代码指标表征预先给定的程序代码,而且尤其应该能通过对所提供的程序代码的少量的、尤其是一次程序执行来被确定。
30.圈复杂度,也称为mccabe指标,用于确定软件模块(功能、程序或者一般来说一段源代码)的复杂度。该圈复杂度被限定为在程序代码的控制流图上的线性无关的路径数目,并且借此被限定为为了实现该控制流图的完整分支覆盖所需的测试用例的最小数目的上限。
31.在步骤s3中,在模糊测试选择模型块13中将程序代码指标pm输送给经训练的基于数据的模糊测试选择模型,以便获得针对在该模糊测试选择模型中被考虑的模糊测试方法的分类结果。
32.模糊测试选择模型对应于基于数据的分类模型,该基于数据的分类模型被训练来针对多种被考虑的模糊测试方法分别根据程序代码指标例如以输出向量a的形式来输出性能指标。性能指标分别说明:相对应的模糊测试方法适合于对预先给定的程序代码进行测试的程度。该性能指标例如可具有在0与1之间的值域。
33.在步骤s4中,根据输出向量,可以在选择块14中选择模糊测试方法中的具有最高性能指标的一种或多种模糊测试方法,以便用与模糊测试方法相对应的模糊测试过程来对预先给定的程序代码相对应地进行测试。
34.在步骤s5中,使用所选择的模糊测试方法来执行模糊测试。因此,根据模糊测试选择模型的结果,在执行块中在程序代码上应用所选择的一种或多种模糊测试方法。
35.模糊测试方法的区别主要在于所使用的模糊测试软件工具和最初提供的种子文件,这些种子文件为模糊测试提供初始输入。用于所选择的模糊测试方法的其它参数是所使用的字典、处理能力、测试时间、最少程序执行次数和模糊测试软件工具的可能的配置。
36.在图3中,示出了阐明用于训练基于数据的模糊测试选择模型的功能的框图。该功能参考图4的流程图更详细地被阐述。其中所描述的方法可以在常规的数据处理装置上被执行。
37.为了训练模糊测试选择模型,使用训练数据集,这些训练数据集分别将一个或多个程序代码指标映射到输出向量上。输出向量根据模糊测试方法来对程序代码指标进行分类。为此,输出向量的每个元素都可以被分配给不同的模糊测试方法,而且可具有相对应的值,该值对应于性能指标。该值表示相对应的模糊测试方法对通过程序代码指标所表征的程序代码类型的适合性。
38.在该方法开始时,在步骤s11中,在程序代码存储器21中提供具有多个不同的程序代码示例bsp的程序代码集(基准套件(benchmark suite))。程序代码集可以被提供作为固定套件(fixed suite),诸如“the darpa cgc binaries”、“lava test suite”、“google fuzzer suite”、“nist software assurance metrics and tool evaluation (samate)”、“fedata”;被提供作为可进化套件(evolvable suite),诸如在klees g.等人的“evaluating fuzz testing”,in proceedings of the 2018 acm sigsac conference on computer and communications security, ccs
ꢀ’
18,第2123-2138页,new york, ny, usa, 2018. acm中所公开的那样;和/或被提供作为标记套件(labeled suite),这些标记套件提供用于区分错误类型的程序代码集并且这些标记套件例如利用google fuzzer suite和nist samate project来被提供。
39.在步骤s12中,在分析块22中相对应地分析程序代码示例bsp,以便分别确定程序代码指标pm。
40.此外,在步骤s13中,借助于在模糊测试块23中执行的一系列所选择的模糊测试方法,借助于与所提供的模糊测试方法相对应的模糊测试过程来对这些程序代码示例bsp进行测试。
41.在步骤s14中,在评估块24中确定性能指标,作为测试结果。性能指标可包括如下指标中的一个或多个或者取决于如下指标中的一个或多个:测试覆盖率(coverage)、所执行的程序流路径的数目、错误识别率(例如所识别出的错误的数目)和平均模糊测试执行时间。性能指标可以考虑这些指标中的一个或多个并且将这些指标中的一个或多个分配给相对应的数值。然后,根据性能指标来创建向量,该向量的元素针对相对应的模糊测试方法中的每种模糊测试方法来说明所属的性能指标。
42.现在,借助于适合的机器学习方法,可以在步骤s15中在模型训练块25中利用训练数据集来创建/训练基于数据的模糊测试选择模型,这些训练数据集将被分配给程序代码集的程序代码示例的程序代码指标分配给相对应的向量。例如,这些机器学习方法可包括高斯过程模型或者神经网络,作为模糊测试选择模型。
43.设计模糊测试选择模型的其它可能性在于统计学习方法以及强化学习。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。