1.本发明涉及互联网技术领域,特别涉及一种低资源婴儿哭声检测方法。
背景技术:
2.婴儿哭声检测技术在教育、智能家居、婴幼产品领域具有十分丰富的应用场景。一直以来,由于传统婴儿哭声检测算法计算复杂度高的限制,识别性能比较稳健的算法通常都需要200mips以上的计算能力才能够实现,因此产业界大量算力只有几十mips的芯片上无法搭载高性能的婴儿哭声检测算法,造成这项技术无法在更加广泛的应用场景中推广应用。
技术实现要素:
3.本发明的主要目的是提出一种低资源婴儿哭声检测方法,旨在在保证识别性能的同时,大幅度降低婴儿哭声识别算法对硬件系统资源的要求。
4.为实现上述目的,本发明提出的低资源婴儿哭声检测方法,包括如下步骤:
5.使用1mixture的monophone单音子模型(状态数为209)进行初步匹配和筛选;
6.对单音子模型的viterbi匹配得分进行排序,选择得分最高的n个结果对应的音素模型进行进一步的精细匹配;
7.使用3mixture的triphone三音子模型(状态数为358)进行精细匹配和筛选;
8.对n个三音子模型的viterbi匹配得分进行排序,选择得分最高的模型所对应的序号作为最终识别结果。
9.进一步地,所述的使用1mixture的monophone单音子模型(状态数为209)进行初步匹配和筛选包括如下步骤:
10.初始单音子模型状态数为为1024;
11.使用baum-welch参数重估方法,利用已标注的哭声训练数据库对初始单音子模型状态进行聚类,将有效状态数为m由1024缩减为209(输出概率密度函数的整体似然度得分最高);具体过程如下:假设s为hmm模型状态的集合,f为训练集,l(s)为对数似然值,假设绑定的状态共享高斯分布的均值和方差,且状态绑定不影响帧和状态的alignment,则
[0012][0013]
其中rs(of)是状态s产生特征的后验概率,假设输出概率密度函数为高斯分布,
[0014]
则
[0015]
公式中n为数据维度(实例中n取27);
[0016]
选择l(s)0作为l(s)的第一个数作为有效状态0的似然值,比较l(s)1至l(s)
m-1
中与l(s)0的差值小于5%的状态,将其合并为同一个状态;
[0017]
重复上述步骤s103,得到l(s)1~l(s)
m-1
。
[0018]
进一步地,所述的使用3mixture的triphone三音子模型(状态数为358)进行精细匹配和筛选包括如下步骤:
[0019]
初始三音子模型状态数为为1500;
[0020]
使用baum-welch参数重估方法,利用已标注的哭声训练数据库对初始三音子模型状态进行聚类,将有效状态数为t由1500缩减为358(输出概率密度函数的整体似然度得分最高);
[0021]
具体过程如下:假设s为hmm模型状态的集合,f为训练集,l(s)为对数似然值,假设绑定的状态共享高斯分布的均值和方差,且状态绑定不影响帧和状态的alignment,则
[0022][0023]
其中rs(of)是状态s产生特征的后验概率,假设输出概率密度函数为高斯分布,
[0024]
则
[0025]
公式中n为数据维度(实例中n取27);
[0026]
s304:选择l(s)0为l(s)的第一个数作为有效状态0的似然值,比较l(s)1至l(s)
t-1
中与l(s)0的差值小于5%的状态,将其合并为同一个状态;
[0027]
s305:重复上述步骤s304,得到l(s)1~l(s)
t-1
。
[0028]
采用本发明的技术方案,具有以下有益效果:本发明的技术方案,通过采用基于低mixture数 多状态共享的模型降维方法和基于vad触发的非实时计算方法,能够在保证识别算法准确率前提下,大幅度降低模型结构复杂度和计算复杂度,从而显著减少婴儿哭声检测算法所需的芯片硬件计算资源消耗。
附图说明
[0029]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图示出的结构获得其他的附图。
[0030]
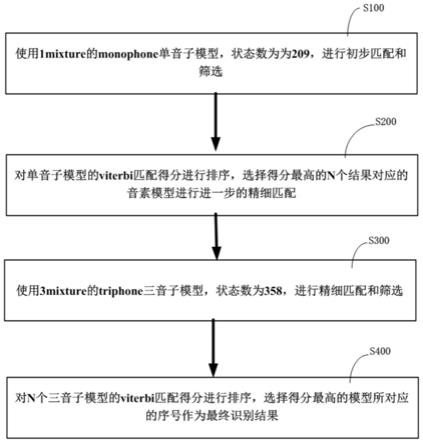
图1为本发明提出的一种低资源婴儿哭声检测方法的整体框架流程结示意图。
[0031]
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
[0032]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0033]
需要说明,本发明实施例中所有方向性指示(诸如上、下、左、右、前、后
……
)仅用于解释在某一特定姿态(如附图所示)下各部件之间的相对位置关系、运动情况等,如果该特定姿态发生改变时,则该方向性指示也相应地随之改变。
[0034]
另外,各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术
人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。
[0035]
本发明提出一种低资源婴儿哭声检测方法。
[0036]
如图1所示,在本发明一实施例中,该低资源婴儿哭声检测方法,包括如下步骤:
[0037]
s100:使用1mixture的monophone单音子模型(状态数为209)进行初步匹配和筛选:
[0038]
s200:对单音子模型的viterbi匹配得分进行排序,选择得分最高的n个结果对应的音素模型进行进一步的精细匹配;
[0039]
s300:使用3mixture的triphone三音子模型(状态数为358)进行精细匹配和筛选:
[0040]
s400:对n个三音子模型的viterbi匹配得分进行排序,选择得分最高的模型所对应的序号作为最终识别结果。
[0041]
具体地,所述的s100:使用1mixture的monophone单音子模型(状态数为209)进行初步匹配和筛选包括如下步骤:
[0042]
s101:初始单音子模型状态数为为1024;
[0043]
s102:使用baum-welch参数重估方法,利用已标注的哭声训练数据库对初始单音子模型状态进行聚类,将有效状态数为m由1024缩减为209(输出概率密度函数的整体似然度得分最高);具体过程如下:假设s为hmm模型状态的集合,f为训练集,l(s)为对数似然值,假设绑定的状态共享高斯分布的均值和方差,且状态绑定不影响帧和状态的alignment,则
[0044][0045]
其中rs(of)是状态s产生特征的后验概率,假设输出概率密度函数为高斯分布,
[0046]
则公式中n为数据维度(实例中n取27);
[0047]
s103:选择l(s)0作为l(s)的第一个数作为有效状态0的似然值,比较l(s)1至l(s)
m-1
中与l(s)0的差值小于5%的状态,将其合并为同一个状态;
[0048]
s104:重复上述步骤s103,得到l(s)1~l(s)
m-1
。
[0049]
具体地,所述的s300:使用3mixture的triphone三音子模型(状态数为358)进行精细匹配和筛选包括如下步骤:
[0050]
s301:初始三音子模型状态数为为1500;
[0051]
s302:使用baum-welch参数重估方法,利用已标注的哭声训练数据库对初始三音子模型状态进行聚类,将有效状态数为t由1500缩减为358(输出概率密度函数的整体似然度得分最高);
[0052]
s303:具体过程如下:假设s为hmm模型状态的集合,f为训练集,l(s)为对数似然值,假设绑定的状态共享高斯分布的均值和方差,且状态绑定不影响帧和状态的alignment,则
[0053][0054]
其中rs(of)是状态s产生特征的后验概率,假设输出概率密度函数为高斯分布,
[0055]
则
[0056]
公式中n为数据维度(实例中n取27);
[0057]
s304:选择l(s)0为l(s)的第一个数作为有效状态0的似然值,比较l(s)1至l(s)
t-1
中与l(s)0的差值小于5%的状态,将其合并为同一个状态;
[0058]
s305:重复上述步骤s304,得到l(s)1~l(s)
t-1
。
[0059]
具体地,相比传统方法,本发明提出的低资源婴儿哭声检测方法的计算复杂度降低近20倍,存储复杂度降低10倍以上,使得在主频100mhz以下的普通单片机上即可实现高性能的婴儿哭声检测应用方案。
[0060]
另一方面,本发明还提供一种基于vad触发的非实时计算方法,采用5状态切换技术,用非实时计算代替大运算量的实时计算,降低计算复杂度和运行功耗,包括如下步骤:
[0061]
1、vad初始状态为silence,此时系统运行在低频(不超过2mhz),仅判断语音帧的当前状态;
[0062]
2、如果当前帧能量大于激活门限ta,为active状态;此时系统仍然运行在低频(不超过2mhz),仅判断语音帧当前状态;
[0063]
3、如果当前帧能量大于有声门限to,或者当前帧能量大于激活门限ta连续超过3次,状态切换为on;此时系统仍然运行在低频(不超过2mhz),仅判断语音帧当前状态;
[0064]
4、如果当前帧能量小于无声门限ti,状态切换到inactive;此时系统仍然运行在低频(不超过2mhz),仅判断语音帧当前状态;
[0065]
5、如果当前帧能量小于无声门限ti连续超过16次,状态切换到end;此时系统切换到高频(大于50mhz),针对active至end间的语音计算与各个模型的匹配得分;
[0066]
6、完成模型匹配得分计算后,当前帧状态切换到silence;此时系统切换到低频(不超过2mhz),仅判断语音帧当前状态;
[0067]
7、重复执行上述步骤2至步骤6;
[0068]
相比传统方法,本发明提出的vad触发的非实时计算方法仅针对有效语音进行密集计算,能够显著减少计算量并降低运行功耗。
[0069]
具体地,本发明通过采用基于低mixture数 多状态共享的模型降维方法和基于vad触发的非实时计算方法,在保证识别算法准确率前提下大幅度降低模型结构复杂度和计算复杂度,从而显著减少婴儿哭声检测算法所需的芯片硬件计算资源消耗。
[0070]
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是在本发明的发明构思下,利用本发明说明书及附图内容所作的等效结构变换,或直接/间接运用在其他相关的技术领域均包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。