一种基于xgboost的温室滴灌番茄腾发量计算方法
技术领域
1.本发明属于温室腾发量计算技术领域,具体涉及一种基于xgboost的温室滴灌番茄腾发量计算方法。
背景技术:
2.准确估算温室作物的蒸发蒸腾量(et)是科学制定温室灌溉制度的有效依据,以往研究认为解决这一问题的有效方法是建立腾发量数学模型。然而温室作物腾发量et的监测受到诸多条件的限制,且温室内影响et的因素较多,et的计算方法和适用条件不尽相同。目前有关温室作物et的计算方法主要有经验公式法和现代数学算法。
3.其中,经验公式法主要是根据能量平衡和水汽扩散原理建立的基于气象因子的腾发量预测模型,其操作性较强,应用较为广泛,目前主要有单源penman-monteith(p-m)模型、双源shuttle-wallace(s-w)模型、以能量为基础的priestley-taylor模型和双作物系数法。此类模型研究在一定程度上为温室作物腾发量的预测提供了参考,但模型本身仍然存在一些不足,例如,经验公式法在求解过程中需要的参数较多,模型对辐射加热效率、显热交换系数及辐射有关参数的取值较为敏感,也会影响预测精度。
4.而采用机器学习等现代数学算法进行作物腾发量的数值计算,将已有气象数据输入机器学习模型中进行非线性关系分析,找到最优拟合路径并记忆,将最优路径作为预报模型,进行数值计算和图像显示,此类方法拥有用时短、精度高、泛化性能好等优点。但此类模型本身也存在一些不足,例如,支持向量回归模型大规模训练样本速度慢,对缺失数据、参数、核函数敏感;神经网络对样本数量要求较高;adaboost算法依赖的弱分类器训练时间往往很长;随机森林算法在一定条件下可能欠拟合等问题。
技术实现要素:
5.针对目前现在数学算法计算腾发量存在的缺陷和问题,本发明提供一种基于xgboost的温室滴灌番茄腾发量计算方法。
6.本发明解决其技术问题所采用的方案是:一种基于xgboost的温室滴灌番茄腾发量计算方法,包括以下步骤:
7.步骤一、定时监测并采集温室内的太阳净辐射rn、相对湿度rh、空气温度ta和风速v,每隔时间t计算一次各项指标的平均值存储于数据采集器中;并选取太阳净辐射rn、相对湿度平均值rh、相对湿度最大值rh
max
、相对湿度最小值rh
min
、空气温度平均值ta、空气温度最大值ta
max
、空气温度最小值ta
min
以及风速v的日平均值作为影响因子;
8.步骤二、分析影响et的各项指标的相关性,根据相关性结果确定自变量因素,然后计算et实测值的日平均值作为因变量构建xgboost模型;
9.步骤三、对样本数据进行标准化处理并随机打乱按比例分配分别作为训练集和测试集,以训练集对模型进行训练和调优,并以测试集对训练好的模型进行验证,得到预测模型用于计算et值,
[0010][0011]
式中:为前面t-1棵树优化后的模型预测值,yi为实测值,f
t
(xi)为新加入的第t棵树所得分值,ω(f
t
)表示第t棵树的正则项,constant表示前面t-1棵树的正则化项之和。
[0012]
上述的基于xgboost的温室滴灌番茄腾发量计算方法,步骤一中在温室中部2m高度位置安装一套全自动气象站,每隔10s记录一次各项指标的数据,并每隔30min计算一次各项指标的平均值。
[0013]
上述的基于xgboost的温室滴灌番茄腾发量计算方法,步骤二中采用水量平衡法计算出温室内番茄的腾发量作为实测值,
[0014]
et=ir δs
[0015]
式中:et为耗水量(mm);ir为灌水量(mm);δs为土壤储水量的变化量的绝对值(mm)。
[0016]
上述的基于xgboost的温室滴灌番茄腾发量计算方法,步骤二还包括计算所有自变量的特征重要性和排列重要性,并根据排列重要性顺序进行消融试验优选出模型的输入变量。
[0017]
上述的基于xgboost的温室滴灌番茄腾发量计算方法,选取rn、rh、rh
min
、ta
max
和ta
min
作为模型的输入变量。
[0018]
上述的基于xgboost的温室滴灌番茄腾发量计算方法,步骤三中将获得的样本数据进行标准化处理,标准化处理方式为:
[0019][0020]
式中:y表示标准化后的数值,x表示原始数据,表示原始数据的平均数,σ表示原始数据的方差。
[0021]
上述的基于xgboost的温室滴灌番茄腾发量计算方法,步骤三中将标准化后的样本数据的80%作为训练集,将剩下的20%样本数据作为测试集。
[0022]
本发明的有益效果:本发明基于xgboost算法构建温室番茄et预测模型对温室番茄et进行预测,预测精度和准确性明显优于其他算法,对温室滴灌作物需水量计算具有重要的参考价值。
[0023]
本发明采用消融实验对xgboost模型输入参数的特征重要性和排列重要性进行了分析,优选出能够预测结果精度高的预测模型,不仅可以防止模型出现过拟合,同时还能得到影响模型的变量因素,提高预测精度。
附图说明
[0024]
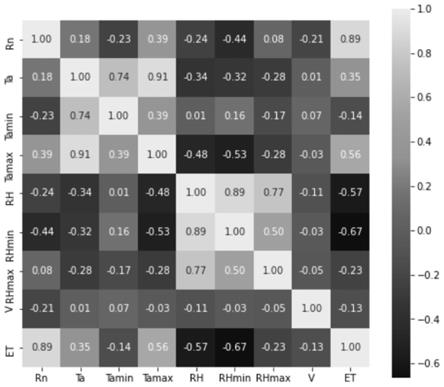
图1为本发明参数相关性分析图。
[0025]
图2为本发明参数对et影响的特征重要性和排列重要性。
[0026]
图3为本发明消融实验mse结果图。
[0027]
图4为八种算法下et测试集标准化后的拟合结果分布图。
具体实施方式
[0028]
下面结合附图和实施例对本发明进一步说明。
[0029]
实施例1:本实施例提供一种基于xgboost算法的温室滴灌番茄腾发量计算方法,该方法包括以下步骤:
[0030]
步骤一、定时监测并采集温室内的太阳净辐射rn、相对湿度rh、空气温度ta和风速v,每隔时间t计算一次各项指标的平均值存储于数据采集器中;并选取太阳净辐射rn、相对湿度平均值rh、相对湿度最大值rh
max
、相对湿度最小值rh
min
、空气温度平均值ta、空气温度最大值ta
max
、空气温度最小值ta
min
以及风速v的日平均值作为影响因子;
[0031]
步骤二、分析影响et的各项指标的相关性,根据相关性结果确定自变量因素,然后计算et实测值的日平均值作为因变量构建模型。
[0032]
具体的,本实施例以上述8个自变量进行相关性分析,结果如图1所示,通过相关性分析结果可以看出,rn、ta、ta
max
与et有正相关关系,而ta
min
、rh、rh
min
、rh
max
、v与et呈现负相关关系,其中,rn与et的相关性最大,而风速与v对et的相关性最小。
[0033]
其中采用水量平衡法计算出温室内番茄的腾发量作为实测值,
[0034]
et=ir δs
[0035]
式中:et为耗水量(mm);ir为灌水量(mm);δs为土壤储水量的变化量的绝对值(mm)。
[0036]
建模前,将试验获得的样本数据进行标准化处理,标准化处理公式如下:
[0037][0038]
式中:y表示标准化后的数值,x表示原始数据,表示原始数据的平均数,σ表示原始数据的方差。
[0039]
步骤三、将样本数据随机打乱顺序,选择其中80%的样本数据作为训练集进行模型训练和调优,得到训练好的xgboost模型;
[0040][0041]
式中:为前面t-1棵树优化后的模型预测值,yi为实测值,f
t
(xi)为新加入的第t棵树所得分值,ω(f
t
)表示第t棵树的正则项,constant表示前面t-1棵树的正则化项之和。
[0042]
然后以剩余20%的样本数据作为测试集对训练好的模型进行验证和评价。
[0043]
为了进一步验证xgbr模型是否出现过拟合,本实施例对构建的模型进行了消融实验分析。
[0044]
但是由于各自变量之间也存在多重的相关关系,有些相关性可能存在重复,因此本实施例对各自变量的特征重要性进行了分析。
[0045]
首先我们对xgbr模型中所有自变量的特征重要性和排列重要性进行了分析,参见图2。由图2可知,8个自变量对于et的特征重要性从大到小依次为:rn》rh》rh
min
》ta
max
》rh
max
》ta
min
》ta》v。而经过对测试集的排列重要性分析可知,8个自变量对于et的排列重要性从大到小依次为:rn》rh》rh
min
》ta
max
》ta
min
》rh
max
》ta》v。
[0046]
可见,在基于xgboost算法的xgbr模型中,自变量rn对模型性能的影响最大,其mdi值为0.867,而v对et预测模型的影响最小,其mdi值仅为0.003。
[0047]
通过以上分析,本文将按照排列重要性顺序rn》rh》rh
min
》ta
max
》ta
min
》rh
max
》ta》v来进行系列消融实验,训练集和测试集消融实验结果如图3所示。其中,x轴表示按排列重要性从小到大顺序逐个去掉自变量后模型剩余的输入项个数,例如,8表示8个自变量都是模型输入项,7表示模型输入项rn rh rh
min
ta
max
ta
min
rh
max
ta,6表示模型输入项rn rh rh
min
ta
max
ta
min
rh
max,
以此类推;y轴表示模型预测值与实测值的mse。
[0048]
由图3可知,在测试集中,随着输入变量的逐渐减少,模型输出的mse呈现先减小后增大的趋势,这说明当所有变量都设为输入项(x轴为8)时模型出现了过拟合(mse=0.052)。而随着输入项逐渐减少,当x轴为5,即输入变量为rn rh rh
min
ta
max
ta
min
时,模型预测精度达到最高(mse=0.047),若继续减少模型输入项,mse再次增大。通过上述消融实验可得,当基于xgboost算法对温室滴灌番茄et进行建模时,推荐选择rn rh rh
min
ta
max
ta
min
为模型输入变量,此时能最大程度的保证模型有效性。
[0049]
实施例2:本实施例以河南当地主要温室蔬菜作物番茄为研究对象对本发明的计算方法进行进一步阐述。
[0050]
一、气象资料
[0051]
在温室中部2m高度位置安装一套全自动气象站(hobo,onset computer corp.,usa),监测太阳净辐射(rn,w/m2)、相对湿度(rh,%)、空气温度(ta,℃)和风速(v,m/s).数据每隔10s记录一次,30min计算一次平均值储存于cr1000数据采集器中。
[0052]
二、番茄腾发量
[0053]
采用水量平衡法计算番茄腾发量:
[0054]
et=p ir w-d δs
[0055]
式中:et为耗水量(mm);ir为灌水量(mm);p为降雨量(mm);w为地下水补给量(mm);d为深层渗漏量(mm);δs为土壤储水量的变化量的绝对值(mm)。
[0056]
由于试验是在温室内进行,故p=0;试验地的地下水位较深(在5.0m以下),作物无法吸收利用,即w=0;所有处理单次灌水定额较小(最大为20mm),几乎不产生深层渗漏,即d=0。因此,上述公式可简化为:
[0057]
et=ir δs
[0058]
三、xgboost算法
[0059]
1、算法原理
[0060]
xgboost是由chen和guestrin(陈和盖斯特林,2016年)首先提出来的,它是对梯度提升决策树gbdt的一种提升。传统的增强树模型只使用一阶导数,但是xgboost算法创新性地引入了二阶导数和正则项,使得该算法不仅训练效果好,而且运算速度也很快。xgboost算法学习过程简要介绍如下:
[0061]
假设模型有k个决策树,其集成模型可表示为如下形式:
[0062][0063]
where f={f(x)=ω
q(x)
}(q:rm→
t,ω∈r
t
)
[0064]
式中:ω
q(x)
为叶子节点q的分数,f对应了所有k棵回归树的集合,而f(x)为其中一棵回归树。
[0065]
xgboost算法的核心就是不断地添加树,将多棵树的得分累加得到最终的预测得分,具体展示如下:
[0066][0067][0068][0069]
…
[0070][0071]
式中:为第t轮的预测结果,为上一轮(t-1)的预测结果,f
t
(xi)为新加入的回归树进行残差拟合。
[0072]
2、模型训练误差
[0073]
xgboost的目标函数如下所示:
[0074][0075]
将目标函数简化如下:
[0076][0077]
第一项表示损失函数,选取一个f(x)来使得我们的目标函数尽量最大地降低,这时目标函数可以被写成下面这样的二次函数:
[0078][0079]
此时,为前面t-1棵树优化后的模型预测值,yi为实测值,f
t
(xi)为新加入的第t棵树所得分值,ω(f
t
)表示第t棵树的正则项,constant表示前面t-1棵树的正则化项之和。
[0080]
实施例3:为验证本发明算法在et估算方面的适用性,本实施例引用了8种算法,包括传统的线性回归(lr)、支持向量回归(svr)、核非线性回归(knr)和随机森林回归(rfr),还有一些广泛应用于其他领域的算法,包括:adaboost算法(abr)、bagging算法(br)、xgboost算法(xgbr)、gradient boosting算法(gbr);结果如图4所示。
[0081]
由图4可知,标准化后的et值在八种算法下都有一定的拟合精度,其中以br、xgbr
和gbr表现最好,knr、rfr和abr表现相对较差。下面来定量对比分析,详细见表1。
[0082]
表1八种算法的mse、rmse、mae、r2值统计表
[0083][0084]
从表1可以看出,8个模型的mse和rmse从大到小排序相同,均为:knr》rfr》br》abr》lr》gbr》svr》xgbr,其中,xgbr的mse和rmse值分别为0.027和0.163,xgbr的mse值比计算精度仅次于它的svr低33.21%,比精度最差的knr低246.79%。xgbr的rmse值比计算精度仅次于它的svr低15.55%,比精度最差的knr低86.4%。8个模型的mae从大到小依次为:knr》br》rfr》abr》lr》gbr》svr》xgbr,此时只有rfr和br的先后排序有所变化,但总体排序与mse和rmse一致,从rfr和br的mse、rmse、mae的结果对比来看,两者的精度无明显差异,与xgbr比较而言,rfr和br的精度较低。8个模型的r2从大到小依次为:xgbr》svr》gbr》lr》abr》br》knr》rfr,其中xgbr的r2最大,其值为0.981,比精度仅次于它的svr高1.26%,比精度最差的knr高8.12%。
[0085]
综合上分析可知:xgbr的mse、rmse、mae最小,r2最大,说明基于xgboost算法的xgbr模型预测效果优于其他模型。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。