1.本发明涉及视频分割技术领域,具体涉及使用差异对比学习网络的半监督目标视频分割方法及系统。
背景技术:
2.半监督目标视频分割任务基于给定的初始帧掩码,把整个视频序列中的目标对象从背景中精细分割出来,实现准确的目标定位,在视频理解、人机交互、自动驾驶等领域有广泛的应用价值和落地需求。但由于视频中目标背景持续变化,同时存在光照变化、相似背景干扰等影响因素,单目标视频分割依然面临很多挑战。
3.现有半监督视频分割方法可以分为基于运动传播、检测和模板匹配三类方法。基于运动传播的方法主要利用目标运动和时间相关性,依赖于像素之间的时空关系,目标位置和形状变化相对平滑就可以实现准确分割,但当遇到遮挡或快速运动等时间不连续因素影响时,会导致漂移问题。基于检测的方法不依赖于时间信息,利用初始帧分割结果中的目标信息,学习外观模型,对视频帧中的目标进行检测和分割,在测试序列时,将初始帧图像与其分割结果图分别进行数据增强,以便于训练模型进行调整,从而获得更为准确的实例特征信息,但在线训练带来了很大的计算量。基于模板匹配的方法通过将当前视频帧与初始帧特征进行像素级匹配,根据比对结果对像素进行分割,不会由于累计的传播误差对分割结果产生影响,但其没有充分利用时空信息,且对初始帧特征提取的要求较高。
技术实现要素:
4.针对现有技术存在上述问题,本发明提出了一种使用差异对比学习网络的半监督目标视频分割方法及系统,从特征空间中获得鲁棒且具有区分性的目标特征,采用对比学习思想,结合时空信息提高视频分割算法性能。
5.为实现上述目的,本技术的技术方案为:使用差异对比学习网络的半监督目标视频分割方法,包括:
6.第1步:将尺寸为h
×
w的初始视频帧输入骨干网络,得到特征通道数为c的通用视觉特征,然后经过边缘增强卷积处理,得到细节纹理更加清晰的视觉特征作为后续对比网络基础;将所述视觉特征与分割结果分别相乘并进行尺寸调整得到目标特征和背景特征
7.第2步:提取所述目标特征的全局映射特征
8.第3步:将所述全局映射特征与所述目标特征进行像素级的相似度对比,获取c个通道,尺寸为m
×
n的相似度响应图;
9.第4步:将所述全局映射特征与所述背景特征进行像素级的相似度对比,
获取c个通道,尺寸为m
×
n的差异度响应图;
10.第5步:将所述全局映射特征与所述视觉特征进行像素对比,并结合参考帧分割结果,通过卷积的方式,依据全局映射特征与背景特征之间的区分性、与目标之间的相似性,将目标、背景在像素级别区分开,得到目标区域和背景区域
11.第6步:通过3
‑
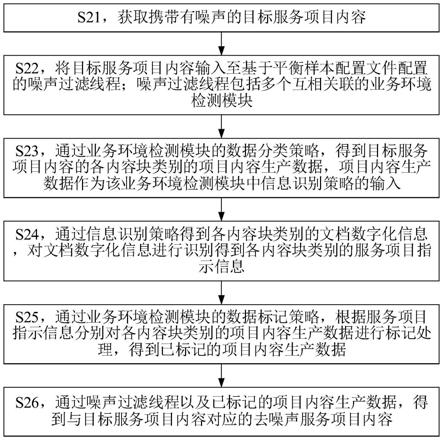
5步学习得到更好的全局特征映射方式和初始帧的全局映射特征将卷积层参数共享,重复第1步,输入尺寸为h
×
w 的后续视频帧通过骨干网络和边缘增强卷积处理,得到视觉特征
12.第7步:将初始帧的全局映射特征与后续帧的视觉特征作为基础,结合参考帧分割结果重复第五步,输出后续帧的分割结果;
13.第8步:重复第6
‑
7步,直到完成整段视频的目标分割任务。
14.进一步的,将视觉特征与分割结果分别相乘并进行尺寸调整得到目标特征和背景特征公式为:
[0015][0016][0017]
进一步的,提取所述目标特征的全局映射特征包括全局平均池化和全连接层两部分,分别是:
[0018]
(1)首先对所述目标特征采用j3×
3,c
的卷积核进行全局平均池化处理,输出c维特征向量公式为:
[0019][0020]
其中,h
average
(x,j
k
×
k,c
,s,p)为平均池化函数,为卷积操作,使用步长s 为1,卷积核尺寸k=3的卷积核依次对c个特征通道的像素特征进行池化操作,直到输出c维特征向量在保证图像内容特征完整性的同时,减少参数,降低计算量。
[0021]
(2)将经过全局平均池化处理的c维特征向量输入全连接层,得到全局映射特征公式为:
[0022][0023]
其中,μ为映射系数,η为修正量。通过全连接层处理提高全局特征的纯度,降低位置对特征表达的影响。
[0024]
进一步的,获取c个通道,尺寸为m
×
n的相似度响应图,公式为:
[0025][0026][0027]
其中,i=1,2,...m,j=1,2,...n;l=1,2,...c;h
standard
为归一化函数,将每一个像素点的相似度分数映射到0
‑
1区间内;每一像素点取最高的r个分数,得到三通道,尺寸为m
×
n的评分结果图,对其采用平均池化操作,得到相似对比的最终响应图,公式为:
[0028][0029]
进一步的,获取c个通道,尺寸为m
×
n的差异度响应图,公式为:
[0030][0031][0032]
其中,i=1,2,...m,j=1,2,...n;l=1,2,...c;
[0033]
对每一像素点取最高的r个分数,得到三通道,尺寸为m
×
n的评分结果图,对其采用平均池化操作,得到差异对比的最终响应图,公式为:
[0034][0035]
更进一步的,目标区域和背景区域的计算公式为:
[0036][0037][0038]
其中,σ为阈值,通过训练得到,用于判定视频帧中的目标、背景区域。设定卷积核大小为1
×
1,步长s=1,对目标、背景初步分割结果采用卷积操作,进行精细处理,输出分割图公式为:
[0039][0040]
本发明还提供一种使用差异对比学习网络的半监督目标视频分割系统,包括:
[0041]
差异对比学习网络,获取视频初始帧经骨干网络处理得到通用视觉特征,然后经边缘增强卷积处理得到细节纹理更加清晰的视觉特征所述视觉特征与初始帧分割图分别相乘得到目标特征背景特征所述目标特征送经过全局平均池化处理得到特征向量再经过全连接层精细处理得到全局映射特征
[0042]
相似对比分支单元,通过提高全局映射特征与目标局部特征的相似度,提升全局映射特征对目标的描述能力。获取目标特征将每一个像素点特征向量与全局映射特征通过卷积核大小为1
ꢀ×
1的卷积进行相似度对比,得到c个通道、尺寸为m
×
n的相似度评分图,即每一个像素点包含c个通道,每一通道有对应的相似度分数,保留每一通道前k名分数,进行平均池化处理,得到最终相似度响应图局部特征感受野有限,相似对比分支通过局部特征与全局映射特征对比学习,提高全局映射特征从不同局部区域捕获信息的能力。
[0043]
差异对比分支单元,通过扩大背景特征与全局映射特征之间的区分度,提高模型分割目标、背景的能力。获取背景特征将每一个像素点特征向量与全局映射特征通过卷积核大小为 1
×
1的卷积进行相似度对比,得到c个通道、尺寸为m
×
n的相似度评分图,即每一个像素点包含c个通道,每一通道有对应的相似度分数,与相似分支一样,保留每一通道前k名分数,进行平均池化处理,得到最终差异度响应图
[0044]
参考学习分支单元,将全局映射特征与视觉特征以像素为单位,通过卷积核大小为1
×
1的卷积进行相似度对比,得到c个通道、尺寸为m
×
n的相似度评分图,结合参考帧分割结果,通过卷积核大小为3
×
3的卷积得到精确度更高的响应图,最终输出目标、背景的分割结果。
[0045]
本发明由于采用以上技术方案,能够取得如下的技术效果:
[0046]
(1)完成视频目标分割及目标跟踪多领域任务
[0047]
本发明的差异对比学习网络,可以在完成视频目标分割的同时,完成目标跟踪任务,同时提升了目标跟踪的准确度。缩小了分割任务和跟踪任务之间的差距,扩大了网络的应用范围。
[0048]
(2)适用于自动驾驶中目标分割任务
[0049]
本发明中结合参考帧分割结果,有效提高了目标快速运动或出现变形情况时的分割精度,适用于自动驾驶领域,得到精确的分割结果可以达到准确避障的效果。
[0050]
(3)适用于自动驾驶中实时跟踪任务
[0051]
本发明可以应用于自动驾驶中的跟踪模块,对目标分割结果进行框定,得到行人等目标的实时跟踪框,进而完成后续自动驾驶的路径规划。
[0052]
(4)适用于安防监控系统
[0053]
本发明通过差异对比学习网络,提高目标、背景之间的区分度,通过像素级对比,实现准确分割,在复杂场景下也可以准确定位并将目标从背景中分割出来,可以应用于安
防监控系统。
附图说明
[0054]
为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0055]
图1是本方法整体框架示意图;
[0056]
图2是实例1中自动驾驶目标实时跟踪任务情况示意图;
[0057]
图3是实例2中自动驾驶避障任务示意图;
[0058]
图4是实例3中安防监控指定目标任务示意图。
具体实施方式
[0059]
本发明的实施例是在以本发明技术方案为前提下进行实施的,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述实施例。
[0060]
本实施例提供一种使用差异对比学习网络的半监督目标视频分割方法及系统,其根据初始帧掩码,提取目标的全局和局部特征信息,采用对比学习思想,提高目标全局特征和局部特征之间的相似度,扩大目标、背景特征之间的区分度,以获得更加鲁棒的目标特征表达。利用得到的全局特征进行像素对比,同时结合参考帧分割结果,保证视频分割结果中目标、背景区域划分的准确性。
[0061]
本发明中初始帧为任务视频的第一帧,会给定目标、背景的分割结果。分割结果为按照目标轮廓,将目标、背景区域准确区分的结果。参考帧分割结果即指当前测试帧的上一帧分割结果。测试帧为任务视频除初始帧外需要进行分割的后续视频帧,即指代当前需要进行分割任务的视频帧。通用视觉特征为经过骨干网络提取包括颜色、形状、空间关系等的基本视觉特征。清晰的视觉特征为经过边缘增强卷积网络处理,增强图像中细节纹理及边缘特征表达的结果。目标特征为整体特征图中框选包含目标的区域。背景特征为整体特征图中去除包含目标的区域。全局映射特征为指可以代表目标的全局特征表达。特征向量是特征表达的一种数学形式。特征通道为卷积层进行信息交互的场所,也是特征的映射区域表达。相似度响应图为反应输入对比特征之间的相似度关系。差异度响应图为反应输入对比特征之间的差异度关系。目标区域为图像与目标全局映射特征比对,高于设定阈值的区域,被判定为目标。背景区域为图像与目标全局映射特征比对,低于设定阈值的区域,被判定为背景。
[0062]
输入视频帧尺寸可以为1280
×
720的rgb三通道图像,经过骨干网络处理,输出通用视觉特征尺寸可以为640
×
360,骨干网络每层输出通道数c∈{32,64,128,256,512},可依照需求设定,输出不同尺寸为(1,640,360,32),(1,640,360,64),(1,640,360,128),(1,640,360,256), (1,640,360,512)的通用特征图。经过cnn卷积层处理,输出尺寸可以为(1,640,360,256)的特征图。相似对比分支和差异对比分支中,经过卷积相似度对比,取每一像素点取最高的r个分数后,进行平均池化,其中r∈{1,2,3,4,5,6,7,8,9,10}。
[0063]
在提取初始帧与后续帧中目标的全局映射特征过程中,卷积参数共享。相似对比
分支和差异对比分支中,每一个像素点包含c个通道,每一通道有对应的相似度分数,取每个像素点最高的r个分数,两分支中c、r取值相同。
[0064]
实施例1:
[0065]
自动驾驶目标实时跟踪任务
[0066]
本实例针对自动驾驶的目标跟踪任务。将本发明应用于车载摄像头,对车辆周围环境进行实时定位跟踪,为系统路径规划做准备,保证行车安全。自动驾驶实时定位任务情况如图2所示。
[0067]
实施例2:
[0068]
自动驾驶避障任务
[0069]
本实例针对自动驾驶行驶过程,应用于车载摄像头,提高对拍摄画面中的路面障碍物进行定位和分割的精度,实现准确避障。自动驾驶避障任务如图3所示。
[0070]
实施例3:
[0071]
安防监控系统指定目标任务
[0072]
本实例应用于安防监控系统,对于复杂场景下的指定目标进行定位、分割,提高监控排查系统的效率,安防监控系统制定目标任务如图4所示。
[0073]
前述对本发明的具体示例性实施方案的描述是为了说明和例证的目的。这些描述并非想将本发明限定为所公开的精确形式,并且很显然,根据上述教导,可以进行很多改变和变化。对示例性实施例进行选择和描述的目的在于解释本发明的特定原理及其实际应用,从而使得本领域的技术人员能够实现并利用本发明的各种不同的示例性实施方案以及各种不同的选择和改变。本发明的范围意在由权利要求书及其等同形式所限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。