1.本公开涉及人工智能技术领域,尤其涉及深度学习和自然语言处理领域,具体涉及一种页面信息处理方法、装置、电子设备和存储介质。
背景技术:
2.随着互联网的普及和技术的发展,网页已经成为一种最为常见和丰富的信息来源。相关技术中,html(hyper text markup language,超文本标记语言)作为一种创建网页的标准标记语言,通常用于描述一个网页的文本语义信息和结构化语义信息,并且允许嵌入图像、动画、声音、表格、链接等对象来编码结构化信息。
3.对于html形式的页面进行特征提取,可以根据提取的特征执行基于网页的主题识别,标签分类等多种任务。因此,提高理解网页的页面内容的特征提取能力可以确保后续任务执行的准确度。
技术实现要素:
4.本公开提供了一种用于页面信息处理的方法、装置、设备以及存储介质。
5.根据本公开的一方面,提供了一种页面信息处理方法,包括:
6.获取目标页面的超文本信息;
7.对所述目标页面的超文本信息进行切词,以得到多个子词;
8.根据所述超文本信息进行页面渲染,以确定所述超文本信息中各子词对应的页面元素;
9.根据多个所述子词对应的页面元素在所述目标页面中的显示位置,对所述目标页面进行特征提取。
10.根据本公开的另一方面,提供了一种模型训练方法,包括:
11.获取训练页面的超文本信息;
12.对所述目标页面的超文本信息进行切词,以得到多个子词;
13.根据所述超文本信息进行页面渲染,以确定所述超文本信息中各子词对应的页面元素;
14.对所述多个子词加扰,以得到多个加扰后的子词;
15.根据多个所述子词对应的页面元素在所述训练页面中的显示位置,以及所述多个加扰后的子词,生成输入编码;
16.采用所述超文本信息对所述输入编码进行标注,得到训练样本;
17.采用所述训练样本,对预训练模型进行训练。
18.根据本公开的再一方面,提供了一种页面信息处理装置,包括:
19.获取模块,用于获取目标页面的超文本信息;
20.切词模块,用于对所述目标页面的超文本信息进行切词,以得到多个子词;
21.确定模块,用于根据所述超文本信息进行页面渲染,以确定所述超文本信息中各
子词对应的页面元素;
22.提取模块,用于根据多个所述子词对应的页面元素在所述目标页面中的显示位置,对所述目标页面进行特征提取。
23.根据本公开的又一方面,提供了一种模型训练装置,包括:
24.页面获取模块,用于获取训练页面的超文本信息;
25.处理模块,用于对所述训练页面的超文本信息进行切词,以得到多个子词;
26.渲染模块,用于根据所述超文本信息进行页面渲染,以确定所述超文本信息中各子词对应的页面元素;
27.加扰模块,用于对所述多个子词加扰,以得到多个加扰后的子词;
28.生成模块,用于根据多个所述子词对应的页面元素在所述训练页面中的显示位置,以及所述多个加扰后的子词,生成输入编码;
29.标注模块,用于采用所述超文本信息对所述输入编码进行标注,得到训练样本;
30.训练模块,用于采用所述训练样本,对预训练模型进行训练。
31.根据本公开的还一方面,提供了一种电子设备,包括:
32.至少一个处理器;以及
33.与所述至少一个处理器通信连接的存储器;其中,
34.所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行一方面所述的方法,或者,另一方面所述的方法。
35.根据本公开的还一方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行一方面所述的方法,或者,另一方面所述的方法。
36.根据本公开的还一方面,提供了一种计算机程序产品,包括计算机程序,所述计算机程序在被处理器执行时实现一方面所述的方法,或者,另一方面所述的方法。
37.本公开提供的页面信息处理方法、装置、设备以及存储介质,通过获取目标页面的超文本信息,对目标页面的超文本信息进行切词,以得到多个子词,从而根据超文本信息进行页面渲染,以确定超文本信息中各子词对应的页面元素,进而根据多个子词对应的页面元素在目标页面中的显示位置,对目标页面进行特征提取。基于超文本信息中各子词对应的页面元素的显示位置,对超文本信息对应的目标页面进行特征提取,从而可以在提取到的特征中携带有目标页面的结构化信息和富文本信息,增强了特征携带的信息量,以便执行后续任务时提高任务执行的准确度。
38.应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。
附图说明
39.附图用于更好地理解本方案,不构成对本公开的限定。其中:
40.图1是根据本公开第一实施例所提供的页面信息处理方法的流程示意图;
41.图2示出了目标页面的超文本信息中标签的布局位置示意图;
42.图3是根据本公开第二实施例所提供的页面信息处理方法的流程示意图;
43.图4示出了使用编码器确定输入编码的示例图;
44.图5是根据本公开第三实施例所提供的模型训练方法的流程示意图;
45.图6是根据本公开第四实施例所提供的模型训练方法的流程示意图;
46.图7示出了采用多加扰方式的示例图;
47.图8是根据本公开第五实施例所提供的页面信息处理装置的结构示意图;
48.图9是根据本公开第六实施例所提供的模型训练装置的结构示意图;
49.图10示出了可以用来实施本公开的实施例的示例电子设备1000的示意性框图。
具体实施方式
50.以下结合附图对本公开的示范性实施例做出说明,其中包括本公开实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本公开的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。
51.需要说明的是,本公开的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本公开的实施例能够以除了在这里图示或描述的那些以外的顺序实施。
52.需要说明的是,本公开的技术方案中,所涉及的超文本信息的获取,存储和应用等,均符合相关法律法规的规定,且不违背公序良俗。
53.本公开实施例针对相关技术中,基于纯文本上预训练好的语言模型上进行二阶段预训练,而未对结构化数据进行系统的预训练任务设计的问题,提出一种页面信息处理方法。
54.下面参考附图描述本公开实施例的页面信息处理方法、装置、电子设备、非瞬时计算机可读存储介质以及计算机程序产品。
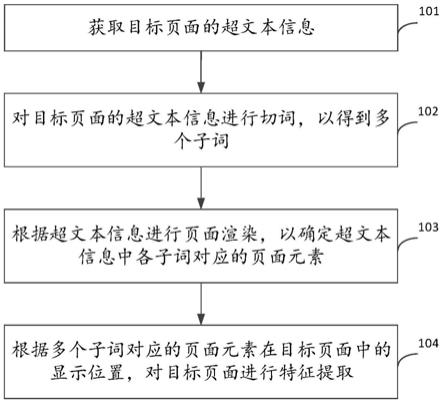
55.图1是根据本公开第一实施例所提供的页面信息处理方法的流程示意图。
56.本公开实施例提供的页面信息处理方法,可以由页面信息处理装置执行。该语音合成装置可以为电子设备,也可以被配置在电子设备中,以实现根据多个子词对应的页面元素在目标页面中的显示位置,对目标页面进行特征提取。本公开实施例以页面信息处理装置被配置在电子设备中为例进行说明。
57.其中,电子设备,可以是任意能够进行数据处理的静止或者移动计算设备,例如笔记本电脑、智能手机、可穿戴设备等移动计算设备,或者台式计算机等静止的计算设备,或者服务器,或者其它类型的计算设备等,本实施例对此不作限制。
58.如图1所示,该页面信息处理方法包括以下步骤:
59.步骤101,获取目标页面的超文本信息。
60.在本公开实施例中,目标页面可以为需要进行页面信息处理的任一页面,超文本信息中包括文本和超文本标签,可以为用来制作网页的html(hyper text markup language,超文本标记语言)数据,其中,超文本指的是超链接,即从一个网页指向一个目标的连接关系,这个目标可以是另一个网页,也可以是相同网页上的不同位置,还可以是一个图片,一个电子邮件地址,一个文件,甚至是一个应用程序,本公开对此不作限制。
61.需要说明的是,本公开实施例中的页面信息处理装置可以通过各种公开、合法合规的方式获取目标页面的超文本信息,例如可以在经过创建目标页面的所属个人或者所属公司授权后,通过页面信息处理装置对目标页面的超文本信息进行采集,或者也可以在经过创建目标页面的所属个人或者所属公司授权后从其它装置获取目标页面的超文本信息,或者也可以通过其它合法合规的方式获取目标页面的超文本信息,本公开对此不作限制。
62.作为一种可能的实现方式,可以通过在浏览器的地址栏中输入目标页面的url访问该页面,然后点击鼠标右键,通过“查看页面源代码”的方式获取公开的页面的超文本信息。
63.步骤102,对目标页面的超文本信息进行切词,以得到多个子词。
64.在本公开实施例中,可以通过对目标页面的超文本信息进行切词,从而得到多个子词,以便后续步骤确定超文本信息中各子词对应的页面元素。
65.作为一种可能的实现方式,可以通过保留目标页面全部的html数据,将html数据中的超文本标记化语言作为一种特定的语言,将html数据中的标签作为可扩展的单词进行切分,以得到多个子词。例如对《html》标签进行切分后,可以得到“《”、“html”和“》”三个子词,从而支持预训练模型迁移到任意结构化信息的领域。
66.步骤103,根据超文本信息进行页面渲染,以确定超文本信息中各子词对应的页面元素。
67.在本公开实施例中,可以根据目标页面的超文本信息进行页面渲染,从而将目标页面的超文本信息画出来,形成图像,进而确定超文本信息中各子词对应的页面元素。
68.举例来说,假设目标页面为“https://www.aaa.com”,使用selenium(浏览器自动化测试框架)对目标页面的超文本信息进行页面渲染,从而可以确定超文本信息中各子词对应的页面元素,图2示出了目标页面的超文本信息中标签的布局位置示意图,如图2所示,标签《div》的结构化位置编码为(l,t,r,b),其中,结构化位置编码用于表征超文本信息中各子词对应的页面元素在网页布局中的空间位置信息,l为页面元素的左上角距离页面左边缘的横向距离,t为页面元素的左上角距离页面上边缘的纵向距离,r为页面元素的右下角距离页面左边缘的横向距离,b为页面元素的右下角距离页面上边缘的纵向距离。
69.步骤104,根据多个子词对应的页面元素在目标页面中的显示位置,对目标页面进行特征提取。
70.在本公开实施例中,可以根据步骤103确定的超文本信息中各子词对应的页面元素在目标页面中的显示位置,对目标页面进行特征提取,以得到目标页面的特征。
71.作为一种可能的实现方式,可以根据多个子词对应的页面元素在目标页面中的显示位置,确定预训练模型的输入编码,将输入编码输入预训练模型进行特征提取,从而得到目标页面的特征。
72.本公开实施例的页面信息处理方法,通过获取目标页面的超文本信息,对目标页面的超文本信息进行切词,以得到多个子词,从而根据超文本信息进行页面渲染,以确定超文本信息中各子词对应的页面元素,进而根据多个子词对应的页面元素在目标页面中的显示位置,对目标页面进行特征提取。基于超文本信息中各子词对应的页面元素的显示位置,对超文本信息对应的目标页面进行特征提取,从而可以在提取到的特征中携带有目标页面的结构化信息和富文本信息,增强了特征携带的信息量,以便执行后续任务时提高任务执
行的准确度。
73.通过上述分析可知,本公开实施例中,可以根据多个子词对应的页面元素在目标页面中的显示位置,对目标页面进行特征提取,下面结合图3,对根据多个子词对应的页面元素在目标页面中的显示位置,对目标页面进行特征提取的过程进一步说明。
74.图3是根据本公开第二实施例所提供的页面信息处理方法的流程示意图。如图3所示,该页面信息处理方法可以包括以下步骤:
75.步骤301,获取目标页面的超文本信息。
76.需要说明的是,步骤301的具体实现过程可以参考上一实施例步骤101的描述,原理相同,此处不再赘述。
77.步骤302,对目标页面的超文本信息,采用子词切分器对超文本信息中的文本和超文本标签进行切词,以得到多个子词。
78.在本公开实施例中,针对步骤301获取的目标页面的超文本信息,可以采用子词切分器对超文本信息中的文本和超文本标签进行切词,从而得到多个子词。需要说明的是,子词切分器对超文本信息中的文本以词为单位进行切分,对超文本信息中的超文本标签以超文本标记语言的组成元素进行切分,将超文本标签切分为多个超文本标记语言的组成元素。
79.其中,对于超文本信息中的超文本标签,作为一种可能的实现方式,可以使用字节级别的bpe(byte pair encoding,字节对编码)对大规模网页数据训练过结构化超文本标记语言的子词切分器(subword tokenizer)进行切词,从而使得超文本标记语言的结构化数据具备很好的兼容性。同时,由于是在字节级别上进行切词,utf-8(unicode transformation format-8,8位元)字符集大小只有256,从而使得词典可以覆盖所有的文本输入,甚至是其他语言,或者未知字符,不存在在对任意标记语言进行切分时产生oov(out-of-vocabulary,未登录词)的情况。
80.步骤303,根据超文本信息进行页面渲染,以确定超文本信息中各子词对应的页面元素。
81.需要说明的是,步骤303的具体实现过程可以参考上一实施例步骤103的描述,原理相同,此处不再赘述。
82.步骤304,根据多个子词对应的页面元素在目标页面中的显示位置,确定多个子词的第一编码。
83.在本公开实施例中,可以根据步骤302确定的超文本信息中多个子词对应的页面元素在目标页面中的显示位置,确定多个子词的第一编码。
84.作为一种可能的实现方式,针对任意的一个子词,可以根据对应页面元素中第一角点距离目标页面边缘的距离,以及页面元素中与第一角点对角的第二角点距离目标页面边缘的距离,确定第一编码。具体地,参照图2,由于结构化位置编码用于表征超文本信息中各子词对应的页面元素在网页布局中的空间位置信息,从而页面元素中第一角点距离目标页面边缘的距离可以根据标签《div》的结构化位置编码中l和t的数值确定,页面元素中与第一角点对角的第二角点距离目标页面边缘的距离可以根据标签《div》的结构化位置编码中r和b的数值确定。
85.步骤305,根据多个子词的词向量、对应子词在超文本信息中的文本顺序,以及对
应子词所属的语句中的至少一个或多个组合,确定多个子词的第二编码。
86.在本公开实施例中,可以根据多个子词的词向量、对应子词在超文本信息中的文本顺序,以及对应子词所属的语句中的至少一个或多个组合,确定多个子词的第二编码。需要说明的是,词向量(word embedding),又叫词嵌入式nlp(natural language processing,自然语言处理)中的一组语言建模和特征学习技术的统称,即将来自词汇表的单词或短语映射到实数的向量,具体涉及从每个单词一维的空间到具有更低维度的连续向量空间的数学嵌入。其中,生成这种映射的方法包括神经网络、单词共生矩阵的降维、概率模型和可解释的知识库方法等,本公开对此不作限制。
87.步骤306,将多个子词的第一编码,与对应子词的第二编码融合,以得到输入编码。
88.在本公开实施例中,可以将步骤305确定的多个子词的第一编码与步骤306确定的对应子词的第二编码进行融合,从而得到输入编码。也就是说,可以根据多个子词对应的页面元素在目标页面中的显示位置,和多个子词的词向量、对应子词在超文本信息中的文本顺序,以及对应子词所属的语句中的至少一个或多个组合,确定输入编码。
89.作为一种可能的实现方式,各子词在词向量编码层(token embedding)输出的词向量、句向量编码层(segment embedding)输出的子词所属语句的编码、位置编码层(position embedding)输出的对应子词在超文本信息中的文本顺序和布局编码层(layout embedding)输出的基于对应页面元素在目标页面的显示位置所确定出的第一编码,确定输入编码。图4示出了使用编码器确定输入编码的示例图,如图4所示,输入为“my dog is cute,i love it.”,针对每个子词均使用词向量编码层、句向量编码层、位置编码层和布局编码层进行编码,确定输入编码。其中,标签《p》代表超文本信息的起始,《/p》代表超文本信息的结束,[cls]标志放在每个句子的首位,[sep]标志放在每个句子的末尾,用于分开超文本信息中两个输入句子。
[0090]
需要说明的是,本实施例中对于词向量编码层、句向量编码层、位置编码层和布局编码层所采用的模型结构不作限制。
[0091]
步骤307,将输入编码输入预训练模型进行特征提取,以得到目标页面的特征。
[0092]
在本公开实施例中,可以通过将输入编码输入预训练模型进行特征提取,以得到目标页面的特征。
[0093]
本公开实施例的页面信息处理方法,通过根据多个子词对应的页面元素在目标页面中的显示位置,确定多个子词的第一编码,以及根据多个子词的词向量、对应子词在超文本信息中的文本顺序,以及对应子词所属的语句中的至少一个或多个组合,确定多个子词的第二编码,从而将多个子词的第一编码,与对应子词的第二编码融合,以得到输入编码,进而将输入编码输入预训练模型进行特征提取,以得到目标页面的特征。由于可以根据超文本信息中各子词对应的页面元素的显示位置,和各子词的词向量、对应子词在超文本信息中的文本顺序,以及对应子词所属的语句中的至少一个或多个组合,确定输入编码,从而可以实现针对超文本标记语言的结构化数据进行编码,有效提高理解网页内容的特征提取能力。并且,对目标页面的超文本信息,可以采用子词切分器对超文本信息中的文本和超文本标签进行切词,以得到多个子词,从而使得超文本标记语言的结构化数据具备很好的兼容性。
[0094]
为了使预训练模型能够充分学习超文本标记语言的结构化语义信息,从而本公开
实施例提供了一种模型训练方法可能的实现方式,图5是根据本公开第三实施例所提供的模型训练方法的流程示意图。
[0095]
如图5所示,该模型训练方法可以包括以下步骤:
[0096]
步骤501,获取训练页面的超文本信息。
[0097]
在本公开实施例中,训练页面可以为对模型进行训练所需的任一页面,超文本信息中包括文本和超文本标签,可以为用来制作网页的html(hyper text markup language,超文本标记语言)数据,其中,超文本指的是超链接,即从一个网页指向一个目标的连接关系,这个目标可以是另一个网页,也可以是相同网页上的不同位置,还可以是一个图片,一个电子邮件地址,一个文件,甚至是一个应用程序,本公开对此不作限制。
[0098]
需要说明的是,可以通过各种公开、合法合规的方式获取训练页面的超文本信息,例如可以在经过创建训练页面的所属个人或者所属公司授权后,对训练页面的超文本信息进行采集,或者也可以通过其它合法合规的方式获取训练页面的超文本信息,本公开对此不作限制。
[0099]
步骤502,对训练页面的超文本信息进行切词,以得到多个子词。
[0100]
在本公开实施例中,可以通过对训练页面的超文本信息进行切词,从而得到多个子词,以便后续步骤确定超文本信息中各子词对应的页面元素。
[0101]
作为一种可能的实现方式,可以通过保留训练页面全部的html数据,将html数据中的超文本标记化语言作为一种特定的语言,将html数据中的标签作为可扩展的单词进行切分,以得到多个子词。例如对《html》标签进行切分后,可以得到“《”、“html”和“》”三个子词,从而支持预训练模型迁移到任意结构化信息的领域。
[0102]
步骤503,根据超文本信息进行页面渲染,以确定超文本信息中各子词对应的页面元素。
[0103]
需要说明的是,步骤503的具体实现过程可以参考上述实施例步骤103的描述,原理相同,此处不再赘述。
[0104]
步骤504,对多个子词加扰,以得到多个加扰后的子词。
[0105]
在本公开实施例中,可以通过对多个子词进行加扰,从而得到多个加扰后的子词。需要说明的是,可以通过对多个子词进行加扰,使得预训练模型能够对得到的多个加扰后的子词进行重建或者区分,恢复出原始的多个子词,增加预训练模型的鲁棒性。
[0106]
作为一种可能的实现方式,可以通过注入噪声的方式进行加扰。例如,对于任意的超文本标记语言序列x={x1,x2,x3,
…
,x
t
},定义噪声函数为使得噪声∈破坏真实序列x的结构化或者序列特性,从而通过参数为θ的预训练模型g对任意的噪声∈进行重建,即:x
′
=g(f(x;∈);θ),进而使得重建序列x
′
能够尽可能恢复原始序列x。
[0107]
步骤505,根据多个子词对应的页面元素在训练页面中的显示位置,以及多个加扰后的子词,生成输入编码。
[0108]
在本公开实施例中,可以根据步骤503确定的超文本信息中多个子词对应的页面元素在训练页面中的显示位置,以及步骤504得到的多个加扰后的子词,进行编码,从而生成输入编码。
[0109]
步骤506,采用超文本信息对输入编码进行标注,得到训练样本。
[0110]
在本公开实施例中,可以采用超文本信息对输入编码进行标注,以得到标注过的
输入编码,并将标注过的输入编码作为训练样本,从而得到预训练模型的训练样本。
[0111]
步骤507,采用训练样本,对预训练模型进行训练。
[0112]
在本公开实施例中,可以采用步骤506得到的训练样本,对预训练模型进行训练,使得预训练模型能够充分学习超文本标记语言的结构化语义信息,从而得到训练完成的预训练模型。
[0113]
本公开实施例的模型训练方法,通过获取训练页面的超文本信息,实现对训练页面的超文本信息进行切词,以得到多个子词,从而根据超文本信息进行页面渲染,以确定超文本信息中各子词对应的页面元素,在对多个子词加扰,以得到多个加扰后的子词之后,根据多个子词对应的页面元素在训练页面中的显示位置,以及多个加扰后的子词,生成输入编码,从而采用超文本信息对输入编码进行标注,得到训练样本,进而采用训练样本,对预训练模型进行训练。由此,通过特定的预训练任务设计,让预训练模型重建或者区分出注入噪声的结构化数据,使得预训练模型更具鲁棒性。
[0114]
为了清楚说明上一实施例,本公开实施例提供了另一种模型训练方法可能的实现方式,图6是根据本公开第四实施例所提供的模型训练方法的流程示意图。
[0115]
如图6所示,该模型训练方法可以包括以下步骤:
[0116]
步骤601,获取训练页面的超文本信息。
[0117]
步骤602,对训练页面的超文本信息进行切词,以得到多个子词。
[0118]
步骤603,根据超文本信息进行页面渲染,以确定超文本信息中各子词对应的页面元素。
[0119]
需要说明的是,步骤601-603的具体实现过程可以参考上一实施例步骤501-503的描述,原理相同,此处不再赘述。
[0120]
步骤604,采用设定加扰策略,对多个子词加扰,以得到多个加扰后的子词。
[0121]
在本公开实施例中,可以采用设定加扰策略,对多个子词进行加扰,从而得到多个加扰后的子词。其中,设定加扰策略包括下列中的至少一个:
[0122]
对待加扰子词中的超文本标签和/或文本进行字符掩码;
[0123]
对待加扰子词中的超文本标签和/或文本进行字符顺序调整;
[0124]
对待加扰子词中的超文本标签进行字符替换;
[0125]
删除待加扰子词中的超文本标签;
[0126]
删除待加扰子词中的超文本标签的首个字符和/或末尾字符;
[0127]
替换待加扰子词中的超文本标签的首个字符和/或末尾字符;
[0128]
对待加扰子词中的文本插入干扰字符。
[0129]
其中,对待加扰子词中的超文本标签和/或文本进行字符掩码包括对单个或者一对标签进行字符掩码和对连续的元素进行字符掩码,替换为”[m]n”,其中,n为掩码长度。为了增强预训练模型的鲁棒性,可以定义n=max(1,(n,n*α)),其中,α∈(0,0.15),是超参数,用于控制长度的噪声大小。
[0130]
需要说明的是,对待加扰子词中的超文本标签和/或文本进行字符掩码,能够使得预训练模型结合上下文学习超文本结构化信息和/或文本语义内容。对待加扰子词中的超文本标签和/或文本进行字符顺序调整,能够使得预训练模型学习超文本标签顺序和/或文本顺序。对待加扰子词中的超文本标签进行字符替换,能够使得预训练模型学到标签配对
和上下文文本语义关系。删除待加扰子词中的超文本标签,能够使得预训练模型检测到标签缺失并进行补充。删除待加扰子词中的超文本标签的首个字符和/或末尾字符为随机进行删除,超文本标签的首个字符和/或末尾字符可以为“《/”,“《”。
[0131]
举例来说,假设设定加扰策略为如下八种加扰方式:
[0132]
标签掩码(tag masking):对单个或者一对标签进行掩码,使得预训练模型结合上下文学习标签语义信息。
[0133]
文本内容掩码(text masking):对连续的元素进行掩码,替换为”[m]n”,其中,n为掩码长度。
[0134]
标签随机打乱(tag permutation):对待加扰子词中的标签顺序进行打乱,使得预训练模型学习标签顺序。
[0135]
标签随机替换(tag replacement):对待加扰子词中随机替换的标签进行恢复,使预训练模型学到标签配对和上下文语义关系。
[0136]
标签删除(tag deletion):随机删除待加扰子词中的标签,使预训练模型检测到标签缺失并补充。
[0137]
标签边界噪声(tag boundary corruption):随机删除或者替换标签的边界为错误边界字符,例如“《/”,“《”中的任意元素。
[0138]
序列旋转(sequence rotation):待加扰子词中随机找到一个位置进行字符串旋转。
[0139]
噪声插入(noise injection):待加扰子词中上下文插入冗余或者错误字符。
[0140]
从而可以得到图7所示的采用多加扰方式的示例图。
[0141]
步骤605,根据多个加扰前的子词对应的页面元素在训练页面中的显示位置,确定加扰前的各子词的第一编码。
[0142]
在本公开实施例中,可以根据步骤603确定的超文本信息中多个加扰前的子词对应的页面元素在训练页面中的显示位置,确定加扰前的各子词的第一编码。
[0143]
作为一种可能的实现方式,针对任意的一个加扰前的子词,可以根据对应页面元素中第一角点距离目标页面边缘的距离,以及页面元素中与第一角点对角的第二角点距离目标页面边缘的距离,确定第一编码。具体地,参照图2,由于结构化位置编码用于表征超文本信息中各子词对应的页面元素在网页布局中的空间位置信息,从而页面元素中第一角点距离目标页面边缘的距离可以根据标签《div》的结构化位置编码中left和top的数值确定,页面元素中与第一角点对角的第二角点距离目标页面边缘的距离可以根据标签《div》的结构化位置编码中right和bottom的数值确定。
[0144]
步骤606,根据多个加扰后的子词的词向量、对应加扰后的子词在超文本信息中的文本顺序,以及所属的语句中的至少一个或多个组合,确定加扰后的各子词的第二编码。
[0145]
在本公开实施例中,可以根据多个加扰后的子词的词向量、对应加扰后的子词在超文本信息中的文本顺序,以及对应加扰后的子词所属的语句中的至少一个或多个组合,确定加扰后的各子词的第二编码。
[0146]
步骤607,将加扰前的各子词的第一编码,与加扰后的对应子词的第二编码融合,以得到输入编码。
[0147]
在本公开实施例中,可以将步骤605确定的加扰前的各子词的第一编码与步骤606
确定的加扰后的对应子词的第二编码进行融合,从而得到输入编码。也就是说,可以根据多个加扰前的子词对应的页面元素在训练页面中的显示位置,和多个加扰后的子词的词向量、对应加扰后的子词在超文本信息中的文本顺序,以及所属的语句中的至少一个或多个组合,确定输入编码。
[0148]
步骤608,采用超文本信息对输入编码进行标注,得到训练样本。
[0149]
需要说明的是,步骤608的具体实现过程可以参考上一实施例步骤506的描述,原理相同,此处不再赘述。
[0150]
步骤609,将训练样本中的输入编码输入预训练模型进行特征提取,以得到训练页面的预测特征。
[0151]
在本公开实施例中,可以将训练样本中的输入编码输入预训练模型进行特征提取,从而得到训练页面的预测特征。
[0152]
步骤610,根据训练页面的预测特征,采用重建模型预测得到训练页面的重建超文本信息。
[0153]
在本公开实施例中,可以根据步骤609得到的训练页面的预测特征,采用重建模型预测得到训练页面的重建超文本信息。
[0154]
步骤611,根据训练样本中的超文本信息和重建超文本信息之间的差异,调整预训练模型的模型参数。
[0155]
由于训练样本中的超文本信息和重建超文本信息之间存在差异,从而可以根据训练样本中的超文本信息和重建超文本信息之间的差异,调整预训练模型的模型参数,更新预训练模型,得到训练完成的预训练模型。
[0156]
本公开实施例的模型训练方法,通过采用设定加扰策略,对多个子词加扰,以得到多个加扰后的子词,从而根据多个加扰前的子词对应的页面元素在目标页面中的显示位置,确定加扰前的各子词的第一编码,以及根据多个加扰后的子词的词向量、对应加扰后的子词在超文本信息中的文本顺序,以及所属的语句中的至少一个或多个组合,确定加扰后的各子词的第二编码。在将加扰前的各子词的第一编码,与加扰后的对应子词的第二编码融合,以得到输入编码之后,采用超文本信息对输入编码进行标注,得到训练样本,并将训练样本中的输入编码输入预训练模型进行特征提取,以得到训练页面的预测特征,从而根据训练页面的预测特征,采用重建模型预测得到训练页面的重建超文本信息,进而根据训练样本中的超文本信息和重建超文本信息之间的差异,调整预训练模型的模型参数。由此,可以通过采用设定加扰策略对多个子词进行加扰,从而可以设计不同的预训练目标任务,让预训练模型模型能够充分学习超文本标记语言的结构化语义信息。同时,由于可以根据训练样本中的超文本信息和重建超文本信息之间的差异,调整预训练模型的模型参数,能够有效增强预训练模型的鲁棒性。
[0157]
与上述图1至图4实施例提供的页面信息处理方法相对应,本公开还提供一种页面信息处理装置,由于本公开实施例提供的页面信息处理装置与上述图1至图4实施例提供的页面信息处理方法相对应,因此在页面信息处理方法的实施方式也适用于本公开实施例提供的页面信息处理装置,在本公开实施例中不再详细描述。
[0158]
图8是根据本公开第五实施例所提供的页面信息处理装置的结构示意图。如图8所示,该页面信息处理装置80包括:获取模块81、切词模块82、确定模块83和提取模块84。
[0159]
获取模块81,用于获取目标页面的超文本信息;
[0160]
切词模块82,用于对所述目标页面的超文本信息进行切词,以得到多个子词;
[0161]
确定模块83,用于根据所述超文本信息进行页面渲染,以确定所述超文本信息中各子词对应的页面元素;
[0162]
提取模块84,用于根据多个所述子词对应的页面元素在所述目标页面中的显示位置,对所述目标页面进行特征提取。
[0163]
在本公开实施例的一种可能的实现方式中,所述提取模块84,包括:
[0164]
第一确定单元841,用于根据多个所述子词对应的页面元素在所述目标页面中的显示位置,确定多个所述子词的第一编码;
[0165]
第二确定单元842,用于根据多个所述子词的词向量、对应子词在所述超文本信息中的文本顺序,以及对应子词所属的语句中的至少一个或多个组合,确定多个所述子词的第二编码;
[0166]
融合单元843,用于将多个所述子词的第一编码,与对应子词的第二编码融合,以得到输入编码;
[0167]
提取单元844,用于将所述输入编码输入预训练模型进行特征提取,以得到所述目标页面的特征。
[0168]
在本公开实施例的一种可能的实现方式中,所述第一确定单元841,用于:
[0169]
针对任意的一个子词,根据对应页面元素中第一角点距离所述目标页面边缘的距离,以及所述页面元素中与所述第一角点对角的第二角点距离所述目标页面边缘的距离,确定所述第一编码。
[0170]
在本公开实施例的一种可能的实现方式中,所述切词模块82,用于:
[0171]
对所述目标页面的超文本信息,采用子词切分器对所述超文本信息中的文本和超文本标签进行切词,以得到多个子词。
[0172]
本公开实施例的页面信息处理装置,通过获取目标页面的超文本信息,对目标页面的超文本信息进行切词,以得到多个子词,从而根据超文本信息进行页面渲染,以确定超文本信息中各子词对应的页面元素,进而根据多个子词对应的页面元素在目标页面中的显示位置,对目标页面进行特征提取。基于超文本信息中各子词对应的页面元素的显示位置,对超文本信息对应的目标页面进行特征提取,从而可以在提取到的特征中携带有目标页面的结构化信息和富文本信息,增强了特征携带的信息量,以便执行后续任务时提高任务执行的准确度。
[0173]
与上述图5至图7实施例提供的模型训练方法相对应,本公开还提供一种模型训练装置,由于本公开实施例提供的模型训练装置与上述图5至图7实施例提供的模型训练方法相对应,因此在模型训练方法的实施方式也适用于本公开实施例提供的模型训练装置,在本公开实施例中不再详细描述。
[0174]
图9是根据本公开第六实施例所提供的模型训练装置的结构示意图。如图9所示,该模型训练装置90包括:页面获取模块91、处理模块92、渲染模块93、加扰模块94、生成模块95、标注模块96和训练模块97。
[0175]
页面获取模块91,用于获取训练页面的超文本信息;
[0176]
处理模块92,用于对所述目标页面的超文本信息进行切词,以得到多个子词;
[0177]
渲染模块93,用于根据所述超文本信息进行页面渲染,以确定所述超文本信息中各子词对应的页面元素;
[0178]
加扰模块94,用于对所述多个子词加扰,以得到多个加扰后的子词;
[0179]
生成模块95,用于根据多个所述子词对应的页面元素在所述训练页面中的显示位置,以及所述多个加扰后的子词,生成输入编码;
[0180]
标注模块96,用于采用所述超文本信息对所述输入编码进行标注,得到训练样本;
[0181]
训练模块97,用于采用所述训练样本,对预训练模型进行训练。
[0182]
在本公开实施例的一种可能的实现方式中,所述加扰模块94,用于:
[0183]
采用设定加扰策略,对所述多个子词加扰,以得到多个加扰后的子词;其中,所述设定加扰策略包括下列中的至少一个:
[0184]
对待加扰子词中的超文本标签和/或文本进行字符掩码;
[0185]
对待加扰子词中的超文本标签和/或文本进行字符顺序调整;
[0186]
对待加扰子词中的超文本标签进行字符进行替换;
[0187]
删除待加扰子词中的超文本标签;
[0188]
删除待加扰子词中的超文本标签的首个字符和/或末尾字符;
[0189]
替换待加扰子词中的超文本标签的首个字符和/或末尾字符;
[0190]
对待加扰子词中的文本插入干扰字符。
[0191]
在本公开实施例的一种可能的实现方式中,所述生成模块95,包括:
[0192]
第一确定单元951,用于根据多个加扰前的子词对应的页面元素在所述目标页面中的显示位置,确定加扰前的各子词的第一编码;
[0193]
第二确定单元952,用于根据多个加扰后的子词的词向量、对应加扰后的子词在所述超文本信息中的文本顺序,以及所属的语句中的至少一个或多个组合,确定加扰后的各子词的第二编码;
[0194]
融合单元953,用于将加扰前的各子词的第一编码,与加扰后的对应子词的第二编码融合,以得到所述输入编码。
[0195]
在本公开实施例的一种可能的实现方式中,所述训练模块97,包括:
[0196]
特征提取单元971,用于将所述训练样本中的输入编码输入预训练模型进行特征提取,以得到所述训练页面的预测特征;
[0197]
重建单元972,用于根据所述训练页面的预测特征,采用重建模型预测得到所述训练页面的重建超文本信息;
[0198]
调整单元973,用于根据所述训练样本中的超文本信息和所述重建超文本信息之间的差异,调整所述预训练模型的模型参数。
[0199]
本公开实施例的模型训练装置,通过获取训练页面的超文本信息,实现对训练页面的超文本信息进行切词,以得到多个子词,从而根据超文本信息进行页面渲染,以确定超文本信息中各子词对应的页面元素,在对多个子词加扰,以得到多个加扰后的子词之后,根据多个子词对应的页面元素在训练页面中的显示位置,以及多个加扰后的子词,生成输入编码,从而采用超文本信息对输入编码进行标注,得到训练样本,进而采用训练样本,对预训练模型进行训练。由此,通过特定的预训练任务设计,让预训练模型重建或者区分出注入噪声的结构化数据,使得预训练模型更具鲁棒性。
[0200]
根据本公开的实施例,本公开还提供了一种电子设备、一种可读存储介质和一种计算机程序产品。
[0201]
图10示出了可以用来实施本公开的实施例的示例电子设备1000的示意性框图。电子设备旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机、和其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备和其它类似的计算装置。本文所示的部件、它们的连接和关系、以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或者要求的本公开的实现。
[0202]
如图10所示,设备1000包括计算单元1001,其可以根据存储在rom(read-only memory,只读存储器)1002中的计算机程序或者从存储单元1008加载到ram(random access memory,随机访问/存取存储器)1003中的计算机程序,来执行各种适当的动作和处理。在ram 1003中,还可存储设备1000操作所需的各种程序和数据。计算单元1001、rom 1002以及ram 1003通过总线1004彼此相连。i/o(input/output,输入/输出)接口1005也连接至总线1004。
[0203]
设备1000中的多个部件连接至i/o接口1005,包括:输入单元1006,例如键盘、鼠标等;输出单元1007,例如各种类型的显示器、扬声器等;存储单元1008,例如磁盘、光盘等;以及通信单元1009,例如网卡、调制解调器、无线通信收发机等。通信单元1009允许设备1000通过诸如因特网的计算机网络和/或各种电信网络与其他设备交换信息/数据。
[0204]
计算单元1001可以是各种具有处理和计算能力的通用和/或专用处理组件。计算单元1001的一些示例包括但不限于cpu(central processing unit,中央处理单元)、gpu(graphic processing units,图形处理单元)、各种专用的ai(artificial intelligence,人工智能)计算芯片、各种运行机器学习模型算法的计算单元、dsp(digital signal processor,数字信号处理器)、以及任何适当的处理器、控制器、微控制器等。计算单元1001执行上文所描述的各个方法和处理,例如上述页面信息处理方法和模型训练方法。例如,在一些实施例中,上述页面信息处理方法和模型训练方法可被实现为计算机软件程序,其被有形地包含于机器可读介质,例如存储单元1008。在一些实施例中,计算机程序的部分或者全部可以经由rom1002和/或通信单元1009而被载入和/或安装到设备1000上。当计算机程序加载到ram 1003并由计算单元1001执行时,可以执行上文描述的页面信息处理方法和模型训练方法的一个或多个步骤。备选地,在其他实施例中,计算单元1001可以通过其他任何适当的方式(例如,借助于固件)而被配置为执行上述页面信息处理方法和模型训练方法。
[0205]
本文中以上描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、fpga(field programmable gate array,现场可编程门阵列)、asic(application-specific integrated circuit,专用集成电路)、assp(application specific standard product,专用标准产品)、soc(system on chip,芯片上系统的系统)、cpld(complex programmable logic device,复杂可编程逻辑设备)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入
装置、和该至少一个输出装置。
[0206]
用于实施本公开的方法的程序代码可以采用一个或多个编程语言的任何组合来编写。这些程序代码可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器或控制器,使得程序代码当由处理器或控制器执行时使流程图和/或框图中所规定的功能/操作被实施。程序代码可以完全在机器上执行、部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。
[0207]
在本公开的上下文中,机器可读介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的程序。机器可读介质可以是机器可读信号介质或机器可读储存介质。机器可读介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的、或半导体系统、装置或设备,或者上述内容的任何合适组合。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计算机盘、硬盘、ram、rom、eprom(electrically programmable read-only-memory,可擦除可编程只读存储器)或快闪存储器、光纤、cd-rom(compact disc read-only memory,便捷式紧凑盘只读存储器)、光学储存设备、磁储存设备、或上述内容的任何合适组合。
[0208]
为了提供与用户的交互,可以在计算机上实施此处描述的系统和技术,该计算机具有:用于向用户显示信息的显示装置(例如,crt(cathode-ray tube,阴极射线管)或者lcd(liquid crystal display,液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入或者、触觉输入)来接收来自用户的输入。
[0209]
可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:lan(local area network,局域网)、wan(wide area network,广域网)、互联网和区块链网络。
[0210]
计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。服务器可以是云服务器,又称为云计算服务器或云主机,是云计算服务体系中的一项主机产品,以解决了传统物理主机与vps服务("virtual private server",或简称"vps")中,存在的管理难度大,业务扩展性弱的缺陷。服务器也可以为分布式系统的服务器,或者是结合了区块链的服务器。
[0211]
其中,需要说明的是,人工智能是研究使计算机来模拟人的某些思维过程和智能行为(如学习、推理、思考、规划等)的学科,既有硬件层面的技术也有软件层面的技术。人工智能硬件技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理等技术;人工智能软件技术主要包括计算机视觉技术、语音识别技术、自然语言处理技术以及机器学习/深度学习、大数据处理技术、知识图谱技术等几大方向。
[0212]
应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本发公开中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本公开公开的技术方案所期望的结果,本文在此不进行限制。
[0213]
上述具体实施方式,并不构成对本公开保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本公开的精神和原则之内所作的修改、等同替换和改进等,均应包含在本公开保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。