1.本发明涉及集成电路硬件安全领域,特别涉及一种数据处理方法及装置、设备和系统。
背景技术:
2.随着智能家居、智能家电、车联网、物联网等技术的发展,信息技术渗透到我们的工作和生活中,人们在享受信息技术带来的各种便利时,信息安全也随之成为重要的技术和社会问题。密码技术通过对信息数据进行加密,来提高信息在传输过程中的安全性,是保障信息安全的关键技术。密码技术中,可以将明文进行加密运算得到密文,在需要获取密文的信息时,对密文进行解密运算得到对应的明文。
3.密码算法的安全可以从3个角度衡量:1)密钥足够长,可以防止暴力攻击;2)计算安全,攻击者知道明文和密文,通过分析方法无法恢复内部密钥;3)实现安全,攻击者可以访问物理实现,通过技术手段无法提取密钥信息。早期的密码算法主要关注密钥长度和计算安全,人们普遍认为只要保证了密码算法的安全,就可以保证密码芯片的安全。这种认识被paul kocher于1996年提出的“时间攻击(timing attack)”打破,paul kocher根据密码芯片运行时泄漏的执行时间信息成功地破解了rsa算法的密钥,引起了学术界对实现安全的关注。
4.侧信道攻击(side channel attack,sca)又称侧信道密码分析,是一种针对密码实现(包括密码芯片、密码模块、密码系统等)的物理攻击方法。侧信息指除了攻击者通过除主通信信道以外的途径获取到的关于密码实现运行状态相关的信息,典型的侧信息包括密码实现运行过程中的能量消耗、电磁辐射、运行时间等信息。物理侧信道攻击为主动式侧信道攻击和被动式侧信道攻击,主动式侧信道攻击包括电压故障攻击、时钟攻击、激光故障攻击,被动式侧信道攻击包括功耗攻击、电磁攻击和时间攻击。功耗分析攻击是sca中最有效的形式之一,主要通过采集加密算法执行时所泄露的功耗信息,再通过差分分析等数学计算来恢复密钥,是一种非入侵式攻击方法。常见的功耗分析攻击方式有简单功耗攻击(simple power attack,spa)、差分功耗攻击(differential power attack,dpa)、相关功耗攻击(correlation power attack,cpa)等。
5.侧信道攻击大大降低了密钥攻击复杂度,如何提高密码算法抗侧信道攻击能力,提高加密装置和系统的安全性,是本领域一项重要的研究。
技术实现要素:
6.有鉴于此,本发明的目的在于提供一种数据处理方法及装置、设备和系统,提高加密装置和系统的安全性。
7.为实现上述目的,本发明有如下技术方案:
8.本技术实施例提供了一种数据处理方法,包括:
9.获取待处理数据;所述待处理数据包括顺序排列的多个分组数据;
10.利用非线性置换组件对所述多个分组数据进行字节替换得到输出数据;所述非线性置换组件用于分别对所述多个分组数据进行字节替换得到多个替换数据,所述输出数据由所述多个替换数据按照预设顺序排列形成,所述预设顺序由运算随机数指示;
11.利用所述运算随机数对所述输出数据进行还原得到还原数据;所述多个分组数据中的任意一个分组数据记为第一数据,所述第一数据在所述待处理数据中的位置,与所述第一数据对应的替换数据在所述还原数据中的位置一致。
12.可选的,所述非线性置换组件的数量为多个,所述输出数据中的多个替换数据的排列顺序根据输出所述多个替换数据的多个非线性置换组件的排列顺序确定;
13.所述运算随机数包括调用随机数,所述调用随机数和调用数列具有映射关系,所述调用数列用于指示所述非线性置换组件的排列顺序,所述分组数据根据所述分组数据的排列顺序和所述非线性置换组件的排列顺序分配给各个所述分线性置换组件。
14.可选的,所述非线性置换组件的数量小于所述分组数据的数量,多个所述非线性置换组件用于通过多次迭代运算对多个分组数据进行字节替换得到多个替换数据;
15.所述输出数据包括多个顺序排列的数据组,每个所述数据组包括多个顺序排列的替换数据,每个数据组为所述多个非线性置换组件在单次迭代运算中得到,所述输出数据中数据组的排列顺序根据所述数据组的输出顺序确定;每个数据组中的多个替换数据的排列顺序根据输出所述多个替换数据的多个非线性置换组件的排列顺序确定。
16.可选的,所述输出数据中第i个数据组通过所述多个非线性置换组件在第i次迭代运算中得到,所述i为正整数;所述运算随机数还包括乱序随机数,所述乱序随机数和乱序数列具有映射关系,所述乱序数列用于指示所述输出数据中的第i次迭代运算得到的数据组的位置;所述利用所述运算随机数对所述输出数据进行还原得到还原数据,包括:
17.利用所述乱序随机数对所述输出数据中的多个数据组的排列顺序进行还原得到恢复数据;
18.利用所述调用随机数对所述数据组中的多个替换数据的排列顺序进行还原得到还原数据。
19.可选的,第i 1次迭代运算中的调用随机数根据所述第i个数据组中预设位置的数据确定。
20.可选的,第1次迭代运算中的调用随机数和所述乱序随机数一致。
21.可选的,所述调用随机数和所述调用数列的映射关系与所述乱序随机数和所述乱序数列的映射关系利用同一映射表表示。
22.可选的,所述方法还包括:
23.将所述输出数据写入状态寄存器中的多个存储区,所述乱序数列指示所述多个存储区的顺序,多个所述数据组根据所述数据组的输出顺序和所述存储区的顺序写入各个所述存储区;
24.利用所述运算随机数对所述输出数据进行还原得到还原数据之前,所述方法还包括:从所述状态寄存器中获取所述输出数据。
25.可选的,所述非线性置换组件的数量为一个,所述非线性置换组件用于根据所述分组数据的排列顺序通过多次迭代运算依次对所述多个分组数据进行字节替换得到多个替换数据;所述输出数据中的多个替换数据的排列顺序根据所述多个替换数据的输出顺序
确定;
26.所述输出数据中第i个替换数据通过所述非线性置换组件在第i次迭代运算中得到,所述i为正整数;所述运算随机数包括乱序随机数,所述乱序随机数和乱序数列具有映射关系,所述乱序数列用于指示所述输出数据中的第i个替换数据的位置。
27.本技术实施例提供了一种数据处理装置,包括:
28.数据获取单元,用于获取待处理数据;所述待处理数据包括顺序排列的多个分组数据;
29.字节替换单元,用于利用非线性置换组件对所述多个分组数据进行字节替换得到输出数据;所述非线性置换组件用于分别对所述多个分组数据进行字节替换得到多个替换数据,所述输出数据由所述多个替换数据按照预设顺序排列形成,所述预设顺序由运算随机数指示;
30.数据还原单元,用于利用所述运算随机数对所述输出数据进行还原得到还原数据;所述多个分组数据中的任意一个分组数据记为第一数据,所述第一数据在所述待处理数据中的位置,与所述第一数据对应的替换数据在所述还原数据中的位置一致。
31.可选的,所述非线性置换组件的数量为多个,所述输出数据中的多个替换数据的排列顺序根据输出所述多个替换数据的多个非线性置换组件的排列顺序确定;
32.所述运算随机数包括调用随机数,所述调用随机数和调用数列具有映射关系,所述调用数列用于指示所述非线性置换组件的排列顺序,所述分组数据根据所述分组数据的排列顺序和所述非线性置换组件的排列顺序分配给各个所述分线性置换组件。
33.可选的,所述非线性置换组件的数量小于所述分组数据的数量,多个所述非线性置换组件用于通过多次迭代运算对多个分组数据进行字节替换得到多个替换数据;
34.所述输出数据包括多个顺序排列的数据组,每个所述数据组包括多个顺序排列的替换数据,每个数据组为所述多个非线性置换组件在单次迭代运算中得到,所述输出数据中数据组的排列顺序根据所述数据组的输出顺序确定;每个数据组中的多个替换数据的排列顺序根据输出所述多个替换数据的多个非线性置换组件的排列顺序确定。
35.可选的,所述输出数据中第i个数据组通过所述多个非线性置换组件在第i次迭代运算中得到,所述i为正整数;所述运算随机数还包括乱序随机数,所述乱序随机数和乱序数列具有映射关系,所述乱序数列用于指示所述输出数据中的第i次迭代运算得到的数据组的位置;所述数据还原单元,包括:
36.第一子单元,用于利用所述乱序随机数对所述输出数据中的多个数据组的排列顺序进行还原得到恢复数据;
37.第二子单元,用于利用所述调用随机数对所述数据组中的多个替换数据的排列顺序进行还原得到还原数据。
38.可选的,第i 1次迭代运算中的调用随机数根据所述第i个数据组中预设位置的数据确定。
39.可选的,第1次迭代运算中的调用随机数和所述乱序随机数一致。
40.可选的,所述调用随机数和所述调用数列的映射关系与所述乱序随机数和所述乱序数列的映射关系利用同一映射表表示。
41.可选的,所述装置还包括:
42.数据写入单元,用于将所述输出数据写入状态寄存器中的多个存储区,所述乱序数列指示所述多个存储区的顺序,多个所述数据组根据所述数据组的输出顺序和所述存储区的顺序写入各个所述存储区;
43.数据读出单元,用于在利用所述运算随机数对所述输出数据进行还原得到还原数据之前,从所述状态寄存器中获取所述输出数据。
44.可选的,所述非线性置换组件的数量为一个,所述非线性置换组件用于根据所述分组数据的排列顺序通过多次迭代运算依次对所述多个分组数据进行字节替换得到多个替换数据;所述输出数据中的多个替换数据的排列顺序根据所述多个替换数据的输出顺序确定;
45.所述输出数据中第i个替换数据通过所述非线性置换组件在第i次迭代运算中得到,所述i为正整数;所述运算随机数包括乱序随机数,所述乱序随机数和乱序数列具有映射关系,所述乱序数列用于指示所述输出数据中的第i个替换数据的位置。
46.本技术实施例提供了一种数据处理设备,其特征在于,包括:
47.存储器和处理器;
48.其中,所述存储器,用于存储计算机程序;
49.所述处理器,用于执行所述计算机程序,以实现所述的数据处理方法。
50.本技术实施例提供了一种数据处理系统,包括:系统总线和所述的数据处理设备。
51.本技术实施例提供了一种数据处理方法及装置、设备和系统,获取待处理数据,待处理数据包括顺序排列的多个分组数据,利用非线性置换组件对多个分组数据进行字节替换得到输出数据,非线性置换组件用于分别对多个分组数据进行字节替换得到多个替换数据,输出数据由多个替换数据按照预设顺序排列形成,预设顺序由运算随机数确定,运算随机数用于指示分组数据对应的替换数据在输出数据中的位置,由于输出数据中替换数据的顺序被打乱,使非线性置换组件对分组数据进行字节替换的功耗轨迹发生变化,打乱了功耗轨迹和处理数据之间的必然联系,实现了功耗轨迹的随机化,增加了攻击难度。之后,可以利用运算随机数对输出数据进行还原得到还原数据,以便后续对还原数据进行线性操作等,多个分组数据中的任意一个分组数据记为第一数据,第一数据在待处理数据中的位置,与第一数据对应的替换数据在还原数据中的位置一致,这样实现了替换数据的位置的还原,使用于执行现行操作的数据中替换数据的位置正确,因此不影响加密/解密的正确性。
附图说明
52.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
53.图1为目前一种dpa攻击的实施过程示意图;
54.图2为本技术实施例提供的一种数据处理方法的流程图;
55.图3为本技术实施例提供的一种aes-128算法的运算过程示意图;
56.图4为本技术实施例提供的一种sm4算法的运算过程示意图;
57.图5为本技术实施例提供的一种soc系统中典型的密码算法ip核结构框图;
58.图6为本技术实施例提供的一种迭代型密码算法ip核结构框图;
59.图7为本技术实施例中一种lfsr的结构示意图;
60.图8为本技术实施例提供的一种迭代性密码算法实现结构框图;
61.图9为本技术实施例提供的一种数据处理装置的结构框图。
具体实施方式
62.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。
63.在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其它不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
64.目前,功耗分析攻击是sca中最有效的形式之一,主要通过采集加密算法执行时所泄露的功耗信息,再通过差分分析等数学计算来恢复密钥。举例来说,dpa攻击是常见的功耗攻击方法,参考图1所示,为目前一种dpa攻击的实施过程示意图,dpa攻击的实施中,重点是选取能量轨迹的区分函数(即d函数,或者称为功耗攻击模型),遍历某密钥段k个假设密钥和n条明(密)文,计算加解密算法的假设中间值,通过功耗模型将假设中间结果映射为假设功耗矩阵h,根据选择函数取值将给定明文对应的实际能量轨迹划分到不同的子集。对于某个猜测密钥,求每个子集的平均值,并求平均值的差异,然后根据平均值差异作dpa曲线,如果dpa曲线显示出尖峰,表示猜测密钥是正确的,否则,猜测密钥是错误的。常见的功耗攻击模型有汉明距离模型、汉明重量模型等。汉明距离模型计算某时间段内“0
→
1”和“1
→
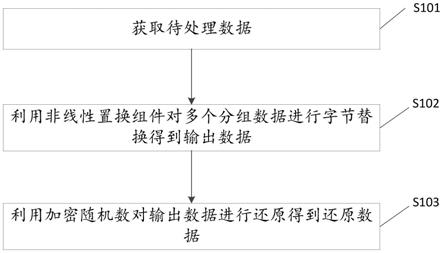
0”跳变的数量,指两个值异或后的汉明重量;汉明重量模型计算某时刻电路中的攻击位置出现“1”的个数。
65.侧信道攻击大大降低了密钥攻击复杂度,以高级数据加密标准(advanced encrypt standard,aes)-128为例,暴力破解密钥的复杂度为2
128
,而侧信道攻击破解密钥的复杂度仅为28×
16=2
12
。另一方面,密钥长度的增加并不能大幅提高密码算法的抗侧信道攻击能力,aes-128到aes-256,暴力破解密钥的复杂度提升了2
128
倍,但是侧信道攻击破解密钥的复杂度仅提升了2倍。由此可见,侧信道攻击给密码芯片带来了严重的安全威胁,我们在密码算法实现过程中必须探索对抗侧信道攻击的防御措施。
66.功耗分析攻击本质是利用密码实现运行过程中产生的依赖于密钥的功耗侧信息来实施密钥恢复攻击的,因此防御对策的核心就是减弱甚至消除功耗与密钥之间的直接依赖性,常见的方法有隐藏(hiding)和掩码(masking)。
67.其中,信息隐藏方法通过打破功耗侧信息与处理数据之间关联的方法来实现抗功耗分析攻击,有两类方法可以实现隐藏防护方案:第一类同在不同时刻执行加密操作,随机化设备功耗,影响的是功耗的时间维度,常见的方法有随机伪操作,伪操作插入越多,攻击难度越大,但是也相应地增加了算法运算量,影响算法性能;第二类方法直接改变设备操作的功耗统计特征,随机化设备功耗,影响的是功耗的数量维度,常见的方法有随机乱序操作、随机噪声等,随机乱序操作可以随机化功耗曲线,但是不会显著影响算法性能。
68.掩码方法通过对设备处理的数据进行随机化的来抗功耗分析攻击,常见的掩码方法有乘法掩码、布尔掩码、复合域掩码等,掩码方法确实能够有效抵御功耗攻击,但是因为
掩码技术要求对密码算法的每个中间值进行掩码,对于分组密码算法,掩码方法需要首先修改非线性置换组件(sbox)操作,并且在此基础上修改算法,掩码方法使得电路硬件资源明显增加,有文献表明,全掩码技术带来的面积开销约为2x;另一方面,掩码技术与密码算法强相关,在不同密码算法间的可移植性较弱。
69.如何提高密码算法抗侧信道攻击能力,提高加密装置和系统的安全性,是本领域一项重要的研究。
70.基于此,本技术实施例提供了一种数据处理方法及装置、设备和系统,获取待处理数据,待处理数据包括顺序排列的多个分组数据,利用非线性置换组件对多个分组数据进行字节替换得到输出数据,非线性置换组件用于分别对多个分组数据进行字节替换得到多个替换数据,输出数据由多个替换数据按照预设顺序排列形成,预设顺序由运算随机数确定,运算随机数用于指示分组数据对应的替换数据在输出数据中的位置,由于输出数据中替换数据的顺序被打乱,使非线性置换组件对分组数据进行字节替换的功耗轨迹发生变化,打乱了功耗轨迹和处理数据之间的必然联系,实现了功耗轨迹的随机化,增加了攻击难度。之后,可以利用运算随机数对输出数据进行还原得到还原数据,以便后续对还原数据进行线性操作等,多个分组数据中的任意一个分组数据记为第一数据,第一数据在待处理数据中的位置,与第一数据对应的替换数据在还原数据中的位置一致,这样实现了替换数据的位置的还原,使用于执行现行操作的数据中替换数据的位置正确,因此不影响加密/解密的正确性。
71.为了更好的理解本发明的技术方案和技术效果,以下将结合附图对具体的实施例进行详细的描述。
72.本技术实施例提供了一种数据处理方法,参考图2所示,为本技术实施例提供的一种数据处理方法的流程图,该方法可以包括:
73.s101,获取待处理数据。
74.在加密算法中,可以将明文进行加密运算得到密文,在需要获取密文的信息时,对密文进行解密运算得到对应的明文。加密运算和解密运算中包括线性变换(l变换)和非线性变换,非线性变换可以包括字节替换等,线性变换可以包括行移位(shiftrows)、列混淆(mixcolumns)等,当然,加密运算和解密运算还可以包括其他运算。
75.高级数据加密标准(advanced encryption standard,aes)是目前最常用的国际加密标准,aes是一个可以加密和解密128位数据块的对称分组密码算法,加密和解密过程使用的密钥长度可以为128位、192位和256位,分别对应aes-128/192/256。参考图3所示,为本技术实施例提供的一种aes-128算法的运算过程示意图,明文首先和密钥进行异或;然后,根据密钥长度进行10/12/14次轮变换,其中最后一次轮变换和前面几次稍微不同,它没有列变换操作;最后最终状态被输出。轮变换包含四个步骤:字节替换(subbytes)、行移位(shiftrows)、列混淆(mixcolumns)、轮密钥加(addroundkey)。
76.sm4是我国公开发布的第一个商用密码算法,sm4也是一个可以加密和解密128位数据块的对称分组密码算法,明文和密钥长度均为128比特。参考图4所示,为本技术实施例提供的一种sm4算法的运算过程示意图,sm4算法包含32轮操作,每轮操作包括字节替换和l变换(线性变换),进行字节替换的组件可以称为非线性置换组件,每轮操作产生1个32位的数据。32轮操作完成之后,对最新的4个32位数据进行反序变换,并将反序变换的结果作为
密文输出。rki为第i轮密钥扩展产生的轮密钥。
77.将aes和sm4分组密码算法为研究对象,可以看出,字节替换是aes和sm4密码算法中唯一的非线性操作,与线性操作相比,攻击非线性操作需要的测量较少,效率较高,因为字节替换把输入数据映射到输出数据具有很大的扩散性,输入数据即使只有1比特的差异,也会引起输出数据很多位的变化,从而消耗大量的能量。另一方面,aes和sm4的sbox数据位宽为8bits,攻击sbox输出仅需要假设28个不同的密钥组合,其他线性操作定义为32bits,攻击线性操作需要假设2
32
个不同的密钥组合,成本较高。因此,字节替换成为对称密码算法易受功耗分析攻击最薄弱的环节,提高字节替换抵抗侧信道攻击的能力在很大程度上提高了整个密码算法的安全性。
78.本技术实施例中,将需要进行字节替换的数据作为待处理数据,在加密运算中,待处理数据可以是对明文进行其他运算得到的数据,例如可以是aes密码算法中对明文和密钥进行密钥加后得到的数据,也可以是sm4密码算法中多组数据和轮密钥进行异或后得到的数据;在解密运算中,待处理数据可以是对密文进行其他运算得到的数据。在对待处理数据进行字节替换操作后,还可以对得到的数据进行线性运算等其他运算,本技术实施例中的改进在于增加了字节替换操作的安全性,而这种字节替换可以存在于任何需要进行字节替换的密码算法中。
79.本技术实施例中,对待处理数据进行字节替换的组件为非线性置换组件(即sbox),待处理数据可以包括顺序排列的多个分组数据,每个分组数据供单个非线性置换组件单次处理,这样多个分组数据被非线性置换组件分别进行字节替换得到多个替换数据。举例来说,单个非线性置换组件单次可以处理8位(bits)数据,则每个分组数据的数据量可以为8bits,则待处理数据可以包括多个数据量为8bits的分组数据,多个分组数据可以顺序排列,例如各个分组数据分别对应待处理数据的不同数据位。
80.s102,利用非线性置换组件对多个分组数据进行字节替换得到输出数据。
81.本技术实施例中,在获取到待处理数据后,可以利用非线性置换组件对待处理数据进行字节替换得到输出数据。具体的,非线性置换组件可以分别对多个分组数据进行字节替换得到多个替换数据,输出数据由多个替换数据按照预设顺序排列形成,预设顺序由运算随机数指示,即运算随机数用于指示分组数据对应的替换数据在输出数据中的位置,由于输出数据中替换数据的顺序被打乱,使非线性置换组件对分组数据进行字节替换的功耗轨迹发生变化,打乱了功耗轨迹和处理数据之间的必然联系,实现了功耗轨迹的随机化,增加了攻击难度。
82.密码算法的硬件实现有两种方式,一种是硬件铺开型,在一个周期内并行地实现每轮的所有操作,例如利用多个非线性置换组件并行对多个分组数据进行字节替换得到多个替换数据,每个非线性置换组件对应一个分组数据;另一种是硬件迭代型,在有限的硬件资源上串行地实现每轮的所有操作,例如利用一个或多个非线性置换组件串行对多个分组数据进行字节替换得到多个替换数据,每个非线性置换组件对应多个分组数据。前者需要较大的面积开销,但是有较高的效率;后者面积开销小,但是完成每轮操作需要的周期数较多,加密/解密效率较低。
83.以sbox为例,aes和sm4的sbox数据位宽均为8bits。假设单个sbox对8bits的字节替换操作可以在1个周期内完成,针对128bits数据,铺开型硬件的sbox数目(记为nsbox)为
16,即n
sbox
=16,计算128bits数据的sbox输出时间开销(记为t
sbox
)为1个周期,即t
sbox
=1;针对128bits数据,迭代型硬件的sbox数目由设计者根据系统总线位宽决定,计算128bits数据的sbox输出时间开销为16/nsbox个周期,即t
sbox
=16
÷nsbox
。
84.参考图5所示,为本技术实施例提供的一种soc系统中典型的密码算法ip核结构框图,系统总线(system bus)的位宽可以是32-bits或者64-bits,总线从机接口(bus slave interfaces)用于和中央处理器(cpu)进行通信,密码算法ip核通过总线从机接口获取来自cpu的明文/密文序列,并向cpu提供经过加密/解密的密文/明文序列;配置寄存器(configuration registers)用于存储配置参数,以便密码算法ip核根据配置参数进行加密/解密运算,例如根据配置参数确定加密/解密运算开始时间(start)和模式(mode)等;密码算法ip核包括aes或sm4(aes/sm4)处理核(processing core),用于对明文序列进行加密得到密文序列,或者对密文序列进行解密得到明文序列;当密码算法ip核进行加密操作时,输入寄存器(in reg)是明文寄存器,用于存储供aes/sm4处理核读取的明文序列,输出寄存器(out reg)是密文寄存器,用于存储aes/sm4处理核写入的密文序列;当密码算法ip核进行解密操作时,inreg是密文寄存器,out reg是明文寄存器;in reg和out reg的位宽与系统总线位宽一致;输入(in)先入先出(first input first output,fifo)存储器用来保存cpu写入的明文/密文序列,输出(out)先入先出(fifo)存储器用来保存供cpu读取的密文/明文序列,in fifo和out fifo的位宽与系统总线位宽一致,in fifo和out fifo的深度大于in reg和out reg的深度,因此相比于in reg和out reg可以存储更多的明文序列和密文序列。举例来说,in fifo和out fifo的深度可以是4的倍数,总线位宽为32bits时,每个in reg可以用于存储32bits的明文/密文序列,每个out reg可以用于存储32bits的密文/明文序列;cpu向in reg写入的32bits明文/密文被转存到in fifo;当in fifo被写入4个数据时,说明cpu已经写入128bits明文/密文序列,密码算法ip核可以开始加密/解密操作;同样,当out fifo被写入4个数据时,说明128bits密/明文序列已经被写入out fifo,密码算法ip核已经完成加密/解密操作,cpu可以通过out reg读取密文/明文。
85.迭代型需要的sbox数目为:n
sbox
=buswidth/8,当然也可以小于该sbox数目。以系统总线的位宽为32bits为例,迭代型密码算法ip核需要1、2或4个sbox,具体的,迭代型密码算法ip核包括4个sbox(n
sbox
=buswidth/8=4)时,128bits数据的字节替换需要的时间开销为4个时钟周期(t
sbox
=16
÷nsbox
=4);在迭代性密码算法ip核包括2个sbox时,128bits数据的字节替换需要的时间开销为8个时钟周期;在迭代性密码算法ip核包括1个sbox时,128bits数据的字节替换需要的时间开销为16个时钟周期。
86.同理,在系统总线为8bits时,迭代型密码算法ip核需要1个sbox;在系统总线为16bits时,迭代型密码算法ip核需要1或2个sbox;在系统总线为64bits时,迭代型密码算法ip核需要1、2、4或8个sbox;在系统总线为128bits时,迭代型密码算法ip核需要1、2、4、8或16个sbox。
87.参考图6所示,为本技术实施例提供的一种迭代型密码算法ip核结构框图,迭代型密码算法ip核包括4个sbox:sbox0、sbox1、sbox2和sbox3,它们分别实现输入4个字节的字节替换(32bits数据由高到低分别为字节3/2/1/0),其中:sbox3实现第3个字节的字节替换,sbox2实现第2个字节的字节替换,sbox1实现第1个字节的字节替换,sbox0实现第0个字节的字节替换;4个sbox迭代运算4次完成128bits数据的字节替换。
88.sbox的具体实现由设计者确定,可以基于查找表实现,也可以基于有限域或者加法链实现。基于查找表的方式计算速度快,但面积开销较大;基于有限域的方式依据有限域的特点,把gf(28)上求逆变换转化到gf((24)2)上作求逆运算,以此减少逻辑关系的运算复杂度,降低sbox面积开销;基于加法链的方式根据gf(28)上的x
255
=1的性质,将有限域gf(28)上元素x的乘法逆元转化为求元素x的254次方(x-1
=x
254
)的运算。
89.目前,由于每次字节替换的32bits输入调用sbox的顺序是一致的,输出数据中的多个替换数据的排列顺序根据输出多个替换数据的多个非线性置换组件的排列顺序确定,因此分组数据在待处理数据中的位置和分组数据对应的替换数据在输出数据中的位置一致,攻击者可以根据第一轮sbox输出的汉明重量泄露进行dpa攻击。因此,本技术实施例中,可以对输出数据中的替换数据的位置进行随机化,提高加密/解密的安全性。
90.在非线性置换组件的数量为多个时,多个非线性置换组件并行对多个分组数据进行字节替换得到多个替换数据,每个非线性置换组件可以对一个分组数据进行处理,则sbox输出时间开销为1个周期,或者每个非线性置换组件也可以通过多次迭代运算在对多个分组数据进行处理,则sbox输出时间开销为多个周期。此时,输出数据中的多个替换数据的排列顺序根据输出多个替换数据的多个非线性置换组件的排列顺序确定,例如多个非线性置换组件包括第一组件、第二组件、第三组件、第四组件,则输出数据中的多个替换数据的排列顺序可以为:第一组件输出的替换数据、第二组件输出的替换数据、第三组件输出的替换数据、第四组件输出的替换数据。
91.运算随机数可以包括调用随机数,调用随机数用于指示非线性置换组件的排列顺序,分组数据根据分组数据的排列顺序和非线性置换组件的排列顺序分配给各个非线性置换组件,这样调用随机数不同时非线性置换组件的排列顺序也不同,分到各个非线性置换组件的分组数据也不完全相同,实现了输出数据中的替换数据的位置的随机化。
92.具体的,调用随机数可以通过线性反馈移位寄存器(linear feedback shift register,lfsr)生成,每个调用随机数映射到一个调用数列,调用数列用于指示非线性置换组件的排列顺序。例如调用数列中的数值分别对应各个非线性置换组件的标识,这样利用调用数列即可指示非线性置换组件的排列顺序。
93.lfsr的特征多项式以及初始输入值由设计者决定,设计者基于随机和乱序调用sbox映射表确定sbox调用情况。调用随机数的数量可以和调用数列的数量相同,这样调用随机数和调用数列可以一一对应;或者调用随机数的数量可以大于调用数列的数量,这样可以利用多个调用随机数对应同一调用数列。调用数列的数量可以根据非线性置换组件的数量确定,调用数列的数量可以为非线性置换组件的数量的阶乘,表示非线性置换组件的排列情况的数量。本发明实施例中,lfsr可以是一个5抽头线性反馈移位寄存器,输出的调用随机数为5位,可以表示32种不同的非线性置换组件的排列情况。当然,在其他实施例中,调用随机数的位数也可以为根据实际情况确定的其他值,例如可以为16等。
94.参考图7所示,为本技术实施例中一种lfsr的结构示意图,参考图7a所示,lfsr可以选择外异或型结构的目标寄存器的连接方式,或参考图7b所示,lfsr可以选择内异或型结构的目标寄存器的连接方式,从而利用预设的线性反馈移位特征多项式以及目标寄存器的初始输入值计算得到随机数。图中,ffk(k=1,2,
…
,n)表示第k个目标寄存器;gi表示有无异或门反馈连接,即gi=1表示反馈接入,gi=0表示不存在反馈,其中,i=1,2,
…
,n;qk表
示第k个目标寄存器的存储值;clk表示时钟信号。
95.每个调用随机数映射到一个调用数列,该调用数列中的数值分别对应各个非线性置换组件的标识。举例来说,在迭代型密码算法ip核包括4个sbox:sbox0、sbox1、sbox2和sbox3时,调用数列中的数值“0”对应sbox0,调用数列中的数值“1”对应sbox1,调用数列中的数值“2”对应sbox2,调用数列中的数值“3”对应sbox3,则可以利用包括“1”、“2”、“3”、“4”的调用数列表示非线性置换组件的排列顺序,例如调用随机数对应的调用数列为{1,2,3,0},这代表四个非线性置换组件的排列顺序为sbox1、sbox2、sbox3、sbox0。
96.调用随机数和调用数列的映射表可以根据实际情况确定,参考表1所示,为本技术实施例提供的一种调用随机数和调用数列的映射表的示例,调用随机数0映射到调用数列{3,2,1,0},表征未对输出数据进行随机化的情况,调用随机数1映射到调用数列{3,2,0,1},调用随机数2映射到调用数列{3,1,0,2}等,用于分别表征对非线性置换组件的调用情况。
97.表1调用随机数和调用数列的映射表
98.索引012345sbox调用情况{3,2,1,0}{3,2,0,1}{3,1,0,2}{3,1,2,0}{3,0,1,2}{3,0,2,1}索引67891011sbox调用情况{2,1,0,3}{2,1,3,0}{2,0,3,1}{2,0,1,3}{2,3,0,1}{2,3,1,0}索引121314151617sbox调用情况{1,2,3,0}{1,2,0,3}{1,3,0,2}{1,3,2,0}{1,0,2,3}{1,0,3,2}索引181920212223sbox调用情况{0,3,1,2}{0,3,2,1}{0,2,3,1}{0,2,1,3}{0,1,3,2}{0,1,2,3}
99.该映射表决定32bits字节替换输入的每个字节调用sbox的情况,由设计者确定,一共有4!种映射方式,对应调用随机数索引为0~23。当调用随机数大于或等于24时,将调用随机数对24求余(lfsr
out
%24),使用余数作为索引查找sbox映射表。假设某个调用随机数所对应的sbox映射情况为{1,2,3,0},这代表第3个字节调用sbox1,第2个字节调用sbox2,第1个字节调用sbox3,第0个字节调用sbox0。
100.假设字节替换的输入为32’h00102030,未进行输出数据的随机化时,sbox调用情况为{3,2,1,0},字节替换的输出为32’h63cab704;进行输出数据的随机化后,假设lfsr产生的随机数为12,以上面的sbox映射表为例,sbox调用情况为{1,2,3,0},字节替换的输出为32’hb7ca6304。字节替换输出的顺序被打乱,攻击者按字节攻击密钥,根据汉明重量功耗模型,在密钥猜测正确时,攻击者得到的汉明重量为4(8’h63),而实际功耗轨迹上对应的是8’hb7的功耗,增加了攻击难度。
101.在每个非线性置换组件对一个分组数据进行处理,即sbox输出时间开销为1个周期时,非线性置换组件的数量等于分组数据的数量,各个替换数据均由不同的非线性置换组件输出,多个替换数据按顺序排列之后形成输出数据,多个替换数据在输出数据中的排列顺序根据输出多个替换数据的多个非线性置换组件的排列顺序确定。
102.在每个非线性置换组件对多个分组数据进行处理,即sbox输出时间开销为多个周期,非线性置换组件的数量小于分组数据的数量,字节替换操作需要非线性置换组件进行多次迭代运算,则各个非线性置换组件在单次迭代运算中得到的替换数据可以组合成为一
个数据组,多个迭代运算得到多个数据组,多个数据组顺序排列得到输出数据,输出数据中数据组的排列顺序可以根据数据组的输出顺序确定。也就是说,输出数据包括多个数据组,每个数据组中包括各个非线性置换组件输出的替换数据,这些替换数据顺序排列,且排列顺序根据输出多个替换数据的多个非线性替换组件的排列顺序确定。
103.针对非线性置换组件的多次迭代运算,可以具有相同的调用随机数,即非线性置换组件在多次迭代运算中,可以具有相同的排列顺序;当然,针对非线性置换组件的多次迭代运算,可以具有不同的调用随机数,即非线性置换组件在多次迭代运算中,可以具有不完全相同的排列顺序,使输出数据中替换数据的顺序更为随机化,此时,可以在每次字节替换前,生成一个调用随机数,由于在特征多项式和初始输入值确定后,lfsr连续4个周期的输出序列是固定的,降低了乱序sbox调用的随机性。
104.也就是说,输出数据中第i个数据组通过多个非线性置换组件在第i次迭代运算中得到,i为正整数,则第i次迭代运算中的调用随机数可以和第i 1次迭代运算中的调用随机数相同,也可以和第i 1次迭代运算中的调用随机数不同。
105.本技术实施例中,在后一次的迭代运算中的调用随机数可以根据在前一次的迭代运算结果确定,例如输出数据中第i个数据组通过多个非线性置换组件在第i次迭代运算中得到,i为正整数,第i 1次迭代运算中的调用随机数根据第i个数据组中预设位置的数据确定。预设位置可以为第i个数据组中任意多位连续的数,也可以为任意多位不连续的数,举例来说,预设位置可以为sbox0输出的低5位数据。
106.lfsr设计过程中应该避免寄存器进入全为0的状态。具体实施时,第i 1次迭代运算中的调用随机数根据第i个数据组中预设位置的数据确定,可以具体为,在第i个数据组中预设位置的数据不为0时,将lfsr的初始输入值更新为第i个数据组中预设位置的数据,增大乱序sbox调用的随机性。在第i个数据组中预设位置的数据为0时,可以保持lfsr初始输入值不变。
107.在调用随机数为5位时,在每次字节替换完成后,如果sbox0输出的低5位数据不为0,则将lfsr的初始输入值更新为sbox0输出的低5位数据,如果sbox0输出的低5位数据为0,则保持lfsr初始输入值不变。基于随机数的乱序调用使得每次所调用的sbox情况基本上不一样,一共有4
×
4!种情况,增加了加密/解密算法的随机性。本发明在增加不多的随机数的情况下,很大程度提高了加密/解密算法的安全性。
108.在以上示例中字节替换的输出为32’hb7ca6304时,sbox0的低5位输出为5’h04,该值被更新到lfsr初始值中,用来产生的新的随机数。
109.在每个非线性置换组件对多个分组数据进行处理,字节替换操作需要非线性置换组件进行多次迭代运算时,各个非线性置换组件在单次迭代运算中得到的数据可以作为一个数据组,多次迭代运算得到多个数据组,多个数据组顺序排列得到输出数据,此时,还可以对多个数据组的排列顺序进行随机化,运算随机数还包括乱序随机数,乱序随机数用于指示输出数据中的多个数据组的排列顺序,这样乱序随机数不同时数据组的排列顺序也不同,而数据组中包括多个替换数据,因此实现了输出数据中的替换数据的位置的进一步随机化。其中,乱序随机数可以通过lfsr生成。
110.具体的,输出数据中第i个数据组通过非线性置换组件在第i次迭代运算中得到,乱序随机数可以和乱序数列具有映射关系,乱序数列用于指示输出数据中第i次迭代运算
得到的数据组的位置,这样利用乱序数列即可指示各个数据组的排列顺序,进一步提高攻击难度。
111.lfsr的特征多项式以及初始输入值由设计者决定,设计者基于随机和乱序调用sbox映射表确定sbox调用情况。乱序随机数的数量可以和乱序数列的数量相同,这样乱序随机数和乱序数列可以一一对应;或者乱序随机数的数量可以大于乱序数列的数量,这样可以利用多个乱序随机数对应同一乱序数列。乱序数列的数量可以根据非线性置换组件的迭代次数确定,乱序数列的数量可以为非线性置换组件的迭代次数的阶乘,表示数据组的排列情况的数量。本发明实施例中,lfsr可以是一个5抽头线性反馈移位寄存器,输出的乱序随机数为5位,可以表示32种不同的数据组的排列情况。当然,在其他实施例中,乱序随机数的位数也可以为根据实际情况确定的其他值,例如可以为16等。
112.本技术实施例中,还可以将输出数据写入状态寄存器的多个存储区,运算随机数还包括乱序随机数时,与乱序随机数具有映射关系的乱序数列可以指示多个存储区的顺序,多个数据组根据数据组的输出顺序和存储区的顺序写入各个存储区。具体的,乱序随机数对应的乱序数列中的数值分别对应多个存储区的顺序,在将输出数据写入多个存储区后,利用存储区的物理顺序对存储区中的输出数据进行读取后,得到的输出数据是经过乱序的数据。
113.乱序随机数可以和调用随机数相同,在调用随机数包括多个时,乱序随机数可以和非线性置换组件在第1次迭代运算中的调用随机数一致。乱序随机数和乱序数列的映射关系,与调用随机数和调用数列的映射关系可以一致,例如乱序随机数和乱序数列的映射表,与调用随机数和调用数列的映射表相同,这样可以在不增加新的随机数的情况下,进一步提高攻击难度。乱序随机数和乱序数列的映射关系,与调用随机数和调用数列的映射关系也可以不一致。
114.举例来说,字节替换的输出被送到状态寄存器,字节替换输出为32bits,状态寄存器位宽为128bits,默认情况下,第1次字节替换的32bits输出被送到state[127:96](记为word 3),第2次字节替换的32bits输出被送到state[95:64](记为word 2),第3次字节替换的32bits输出被送到state[63:32](记为word 1),第4次字节替换的32bits输出被送到state[31:0](记为word 0)。
[0115]
在乱序随机数和非线性置换组件在第1次迭代运算中的调用随机数一致,且乱序随机数和乱序数列的映射表,与调用随机数和调用数列的映射表相同时,假设第1次字节替换使用的调用随机数为2,则乱序随机数也为2,根据表1中可知乱序随机数对应的乱序数列为{3,1,0,2},则第1次字节替换被输出到状态寄存器的第3个字(word 3),第2次字节替换输出被送到状态寄存器的第1个字(word 1),第3次字节替换输出被送到状态寄存器的第0个字(word 0),第4次字节替换输出被送到状态寄存器第2个字(word 2)。乱序随机数仅在每轮第1次字节替换时更新一次,在整个迭代过程中不再更新,由于每轮第1次字节替换生成的lfsr不一样,各个数据组的位置也不一样,一共有4!种情况,提高了攻击者的攻击难度。
[0116]
假设连续4次字节替换的输出分别为:32’h63cab704、32’h0953d051、32’hcd60e0e7、32’hba70e18c,在未进行替换数据的排列顺序随机化时,在4次迭代完成并将输出数据写入状态寄存器后,状态寄存器的值应该为:128’h63cab7040953d051cd60e0e7ba7
0e18c。假设按某已知的lfsr特征多项式和初始值计算得到4次字节替换使用的调用随机数分别为{12,2,25,12},根据sbox映射表,同时考虑数据组中多个替换数据的排列顺序随机化和输出数据中多个数据组的排列顺序随机化后,状态寄存器的值可以为:128’hcd60e7e009d05153b7ca6304e170ba8c。其中,数据组中多个替换数据的排列顺序随机化参考表2所示。虽然第1次字节替换和第4次字节替换使用相同的随机数,但是结合数据组的排列顺序随机化后,字节关系已经被打乱,攻击者按字节破解密钥时,攻击难度大幅提升。
[0117]
参考表2所示,为按某已知的lfsr特征多项式和初始值计算得到的字节乱序sbox的输出。
[0118]
表2输出数据中各个数据组的示意图
[0119] sbox输出随机数sbox映射关系字节乱序后sbox输出132’h63cab7045’d12{1,2,3,0}32’hb7ca6304232’h0953d0515’d2{3,1,0,2}32’h09d05153332’hcd60e0e75’d25{3,2,0,1}32’hcd60e7e0432’hba70e18c5’d12{1,2,3,0}32’he170ba8c
[0120]
参考图8所示,为本技术实施例提供的一种迭代性密码算法实现结构框图,待处理数据为128bits,分为16个分组数据,每个分组数据为8bits,通过四个非线性置换组件进行4次迭代运算实现处理,每次迭代运算中每个非线性置换组件对一个分组数据进行处理。其中,调用随机数和乱序随机数通过5b lfsr生成,多次迭代运算使用的调用随机数可以不同。
[0121]
在对待处理数据进行字节替换输入后,可以先进行字节乱序(byte shuffling)以随机化替换数据在数据组中的排列顺序,具体的,根据调用随机数为四个非线性置换组件(sbox0、sbox1、sbox2和sbox3)分配分组数据,四个非线性置换组件并行对四个分组数据进行字节替换,每次迭代运算可以处理32bits的数据得到一个数据组,迭代4次完成128bits的字节替换处理,得到四个数据组。之后,可以进行字乱序(word shuffling)以随机化数据组在输出数据中的排列顺序,具体的,根据乱序随机数为四个数据组确定存储位置,根据存储位置将四个数据组存储到状态寄存器中。
[0122]
本技术实施例中,若非线性置换组件(sbox)的数量为一个,非线性置换组件可以根据分组数据的排列顺序通过多次迭代运算依次对多个分组数据进行字节替换得到多个替换数据,输出数据中的多个替换数据的排列顺序根据多个替换数据的输出顺序确定。则运算随机数可以包括乱序随机数,乱序随机数用于指示输出数据中的多个替换数据的排列顺序,具体的,输出数据中第i个替换数据通过非线性置换组件在第i次迭代运算中得到,i为正整数,运算随机数包括乱序随机数,乱序随机数和乱序数列具有映射关系,乱序数列用于指示输出数据中的第i个替换数据的位置。
[0123]
s103,利用运算随机数对输出数据进行还原得到还原数据。
[0124]
本技术实施例中,输出数据经过了乱序操作,使替换数据在输出数据中的位置随机化,为了不影响加密/解密过程中数据的准确性,可以利用运算随机数对输出数据进行还原得到还原数据,从而对还原数据进行其他操作,例如进行线性操作等。经过还原后的还原数据中的替换数据排列顺序是准确的,以保证密文正确输出,具体的,多个分组数据中的任意一个分组数据记为第一数据,第一数据在待处理数据中的位置,与第一数据对应的替换
数据在还原数据中的位置一致,也就是说,还原数据才是待处理数据经过字节替换应该得到的数据。
[0125]
在非线性置换组件的数量为多个时,每个非线性置换组件对应一个分组数据,运算随机数可以包括调用随机数,调用随机数用于指示非线性置换组件的排列顺序,则利用运算随机数对输出数据进行还原得到还原数据,可以具体为,利用调用随机数对输出数据中的替换数据的排列顺序进行还原得到还原数据。
[0126]
在非线性置换组件的数量为多个时,每个非线性置换组件对应多个分组数据,字节替换操作需要非线性置换组件进行多次迭代运算,则各个非线性置换组件在单次迭代运算中得到的数据可以作为一个数据组,多次迭代运算得到多个数据组,多个数据组顺序排列得到输出数据,运算随机数可以包括调用随机数和乱序随机数,调用随机数用于指示非线性置换组件的排列顺序,乱序随机数用于指示输出数据中的多个数据组的排列顺序,则利用运算随机数对输出数据进行还原得到还原数据,可以具体为,利用乱序随机数对输出数据中的数据组的排列顺序进行还原得到包括多个数据组的恢复数据,利用调用随机数对恢复数据中的多个数据组中的多个替换数据的排列顺序进行还原得到还原数据。
[0127]
参考图8所示,可以利用乱序随机数进行字去乱序(word re-shuffling)以还原各个数据组的排列顺序,之后可以利用调用随机数进行字节去乱序(byte re-shuffling)以还原各个数据组中的替换数据的排列顺序。在各个数据组对应不完全相同的调用随机数时,还原各个数据组中的替换数据所所用的调用随机数和数据组一一对应。以前述例子为例,字去乱序使用的乱序随机数为12,字节去乱序使用的调用随机数为{12,5,25,12}。
[0128]
这种情况下,通过使用1个5b lfsr作为随机数发生器,产生4个随机数,可以利用这4个随机数进行字节乱序和字节去乱序,也可以利用4个随机数中的第一个随机数进行字乱序和字去乱序,增加加密/解密算法的随机性,所使用的随机乱序功能是简单的字节置换和字置换,对于32bit或128bit并行数据路径,使用走线和简单逻辑门可以实现。
[0129]
在非线性置换组件的数量为一个时,非线性置换组件可以根据分组数据的排列顺序通过多次迭代运算依次对多个分组数据进行字节替换得到多个替换数据,运算随机数可以包括乱序随机数,乱序随机数用于指示输出数据中的多个替换数据的排列顺序,则利用运算随机数对输出数据进行还原得到还原数据,可以具体为,利用乱序随机数对输出数据中的替换数据的排列顺序进行还原得到还原数据。
[0130]
在输出数据存储到状态存储器的情况下,利用运算随机数对输出数据进行还原得到还原数据之前,还可以从状态寄存器中获取输出数据。当然,在对还原数据线性变换得到变换数据后,可以将变换数据存储到状态寄存器中,参考图8所示。
[0131]
参考表3所示,为本技术实施例中一种不同实施例的对应情况,当系统总线位宽为8bits时,需要1个sbox迭代16次完成128bits数据字节替换,字节乱序情况有1种,字乱序有16!种情况;当系统总线位宽为16bits时,需要2个sbox迭代8次完成128bits数据字节替换,随机字节乱序有2!种情况,随机字乱序有8!种情况;当系统总线位宽为32bits时,需要4个sbox迭代4次完成128bits数据字节替换,随机字节乱序有4!种情况,随机字乱序有4!种情况;当系统总线位宽为64bits时,需要8个sbox迭代2次完成128bits数据字节替换,随机字节乱序有8!种情况,随机字乱序有2!种情况;当系统总线位宽为128bits时,需要16个sbox并行进行1次迭代完成128bits数据字节替换,随机字节乱序有16!种情况,字乱序有1种情
况。
[0132]
表3不同实施例的对应情况
[0133][0134]
可以看出,对于128bits的待处理数据而言,相比于系统总线位宽为32bits,系统总线位宽为16bits的随机字乱序和系统总线位宽为64bits的随机字节乱序情况大幅增加,但是,这两种情况下由于随机乱序操作所带来的面积开销也大幅增加,因此,本发明实施例中,总线位宽为32bits的系统具有更优的性能。
[0135]
本技术实施例提供了一种数据处理方法,获取待处理数据,待处理数据包括顺序排列的多个分组数据,利用非线性置换组件对多个分组数据进行字节替换得到输出数据,非线性置换组件用于分别对多个分组数据进行字节替换得到多个替换数据,输出数据由多个替换数据按照预设顺序排列形成,预设顺序由运算随机数确定,运算随机数用于指示分组数据对应的替换数据在输出数据中的位置,由于输出数据中替换数据的顺序被打乱,使非线性置换组件对分组数据进行字节替换的功耗轨迹发生变化,打乱了功耗轨迹和处理数据之间的必然联系,实现了功耗轨迹的随机化,增加了攻击难度。之后,可以利用运算随机数对输出数据进行还原得到还原数据,以便后续对还原数据进行线性操作等,多个分组数据中的任意一个分组数据记为第一数据,第一数据在待处理数据中的位置,与第一数据对应的替换数据在还原数据中的位置一致,这样实现了替换数据的位置的还原,使用于执行现行操作的数据中替换数据的位置正确,因此不影响加密/解密的正确性。
[0136]
此外,本技术实施例中的加密/解密算法引入随机字节乱序操作和随机字乱序操作中的至少一种,随机化密码算法非线性字节替换的调用和输出,使得加密/解密算法在每轮函数的每次迭代运算中调用sbox的顺序以及sbox输出在状态寄存器中的位置都不一样,以达到随机化功耗曲线和提高密码算法抗侧信道攻击能力的目的,这种随机性具有不可预测性,解决了固定调用sbox和固定输出sbox的安全性较低的问题,同时使得攻击者攻击密钥的成本呈指数级增加,提高了加密装置的抗功耗侧信道攻击的能力,同时降低了防御措施带来的面积开销,提高了防御措施在不同密码算法间的可移植性。
[0137]
基于本技术实施例提供的一种数据处理方法,本技术实施例还提供了一种数据处理装置,参考图9所示,为本技术实施例提供的一种数据处理装置的结构框图,该装置可以包括:
[0138]
数据获取单元110,用于获取待处理数据;所述待处理数据包括顺序排列的多个分组数据;
[0139]
字节替换单元120,用于利用非线性置换组件对所述多个分组数据进行字节替换
得到输出数据;所述非线性置换组件用于分别对所述多个分组数据进行字节替换得到多个替换数据,所述输出数据由所述多个替换数据按照预设顺序排列形成,所述预设顺序由运算随机数指示;
[0140]
数据还原单元130,用于利用所述运算随机数对所述输出数据进行还原得到还原数据;所述多个分组数据中的任意一个分组数据记为第一数据,所述第一数据在所述待处理数据中的位置,与所述第一数据对应的替换数据在所述还原数据中的位置一致。
[0141]
可选的,所述非线性置换组件的数量为多个,所述输出数据中的多个替换数据的排列顺序根据输出所述多个替换数据的多个非线性置换组件的排列顺序确定;
[0142]
所述运算随机数包括调用随机数,所述调用随机数和调用数列具有映射关系,所述调用数列用于指示所述非线性置换组件的排列顺序,所述分组数据根据所述分组数据的排列顺序和所述非线性置换组件的排列顺序分配给各个所述分线性置换组件。
[0143]
可选的,所述非线性置换组件的数量小于所述分组数据的数量,多个所述非线性置换组件用于通过多次迭代运算对多个分组数据进行字节替换得到多个替换数据;
[0144]
所述输出数据包括多个顺序排列的数据组,每个所述数据组包括多个顺序排列的替换数据,每个数据组为所述多个非线性置换组件在单次迭代运算中得到,所述输出数据中数据组的排列顺序根据所述数据组的输出顺序确定;每个数据组中的多个替换数据的排列顺序根据输出所述多个替换数据的多个非线性置换组件的排列顺序确定。
[0145]
可选的,所述输出数据中第i个数据组通过所述多个非线性置换组件在第i次迭代运算中得到,所述i为正整数;所述运算随机数还包括乱序随机数,所述乱序随机数和乱序数列具有映射关系,所述乱序数列用于指示所述输出数据中的第i次迭代运算得到的数据组的位置;所述数据还原单元,包括:
[0146]
第一子单元,用于利用所述乱序随机数对所述输出数据中的多个数据组的排列顺序进行还原得到恢复数据;
[0147]
第二子单元,用于利用所述调用随机数对所述数据组中的多个替换数据的排列顺序进行还原得到还原数据。
[0148]
可选的,第i 1次迭代运算中的调用随机数根据所述第i个数据组中预设位置的数据确定。
[0149]
可选的,第1次迭代运算中的调用随机数和所述乱序随机数一致。
[0150]
可选的,所述调用随机数和所述调用数列的映射关系与所述乱序随机数和所述乱序数列的映射关系利用同一映射表表示。
[0151]
可选的,所述装置还包括:
[0152]
数据写入单元,用于将所述输出数据写入状态寄存器中的多个存储区,所述乱序数列指示所述多个存储区的顺序,多个所述数据组根据所述数据组的输出顺序和所述存储区的顺序写入各个所述存储区;
[0153]
数据读出单元,用于在利用所述运算随机数对所述输出数据进行还原得到还原数据之前,从所述状态寄存器中获取所述输出数据。
[0154]
可选的,所述非线性置换组件的数量为一个,所述非线性置换组件用于根据所述分组数据的排列顺序通过多次迭代运算依次对所述多个分组数据进行字节替换得到多个替换数据;所述输出数据中的多个替换数据的排列顺序根据所述多个替换数据的输出顺序
确定;
[0155]
所述输出数据中第i个替换数据通过所述非线性置换组件在第i次迭代运算中得到,所述i为正整数;所述运算随机数包括乱序随机数,所述乱序随机数和乱序数列具有映射关系,所述乱序数列用于指示所述输出数据中的第i个替换数据的位置。
[0156]
本技术实施例提供了一种数据处理装置,获取待处理数据,待处理数据包括顺序排列的多个分组数据,利用非线性置换组件对多个分组数据进行字节替换得到输出数据,非线性置换组件用于分别对多个分组数据进行字节替换得到多个替换数据,输出数据由多个替换数据按照预设顺序排列形成,预设顺序由运算随机数确定,运算随机数用于指示分组数据对应的替换数据在输出数据中的位置,由于输出数据中替换数据的顺序被打乱,使非线性置换组件对分组数据进行字节替换的功耗轨迹发生变化,打乱了功耗轨迹和处理数据之间的必然联系,实现了功耗轨迹的随机化,增加了攻击难度。之后,可以利用运算随机数对输出数据进行还原得到还原数据,以便后续对还原数据进行线性操作等,多个分组数据中的任意一个分组数据记为第一数据,第一数据在待处理数据中的位置,与第一数据对应的替换数据在还原数据中的位置一致,这样实现了替换数据的位置的还原,使用于执行现行操作的数据中替换数据的位置正确,因此不影响加密/解密的正确性。
[0157]
此外,本技术实施例中的加密/解密算法引入随机字节乱序操作和随机字乱序操作中的至少一种,随机化密码算法非线性字节替换的调用和输出,使得加密/解密算法在每轮函数的每次迭代运算中调用sbox的顺序以及sbox输出在状态寄存器中的位置都不一样,以达到随机化功耗曲线和提高密码算法抗侧信道攻击能力的目的,这种随机性具有不可预测性,解决了固定调用sbox和固定输出sbox的安全性较低的问题,同时使得攻击者攻击密钥的成本呈指数级增加,提高了加密装置的抗功耗侧信道攻击的能力,同时降低了防御措施带来的面积开销,提高了防御措施在不同密码算法间的可移植性。
[0158]
本技术实施例还提供了一种数据处理设备,该设备包括处理器和存储器;其中存储器用于存储计算机程序;所述处理器用于执行所述计算机程序,以实现前述的数据处理方法。数据处理设备可以为实现各种存在字节替换的分组密码算法ip核,具体地,可以为aes或sm4(aes/sm4)处理核,用于对明文序列进行加密得到密文序列,或者对密文序列进行解密得到明文序列。
[0159]
本技术实施例还提供了一种数据处理系统,该系统包括系统总线以及前述的数据处理设备。该系统还可以包括总线从机接口(bus slave interfaces),总线从机接口可以包括配置寄存器(configuration registers)、输入(in)/输出(out)先入先出(fifo)存储器等,总线从机接口用于和中央处理器(cpu)进行通信,密码算法ip核通过总线从机接口获取来自cpu的明文/密文序列,并向cpu提供经过加密/解密的密文/明文序列。配置寄存器用于存储配置参数,以便密码算法ip核根据配置参数进行加密/解密运算,例如根据配置参数确定加密/解密运算开始时间(start)和模式(mode);in fifo存储器用来保存cpu写入的明文/密文序列,out fifo存储器用来保存供cpu读取的密文/明文序列,in fifo和out fifo的位宽与系统总线位宽一致。
[0160]
该系统还可以包括输入(in)/输出(out)寄存器(reg),当密码算法ip核进行加密操作时,in reg是明文寄存器,用于存储供aes/sm4处理核读取的明文序列,out reg是密文寄存器,用于存储aes/sm4处理核写入的密文序列;当密码算法ip核进行解密操作时,inreg
是密文寄存器,out reg是明文寄存器。in reg和out reg的位宽与系统总线位宽一致。
[0161]
in fifo和out fifo的深度大于in reg和out reg的深度,因此相比于in reg和out reg可以存储更多的明文序列和密文序列。举例来说,in fifo和out fifo的深度可以是4的倍数,总线位宽为32bits时,每个in reg可以用于存储32bits的明文/密文序列,每个out reg可以用于存储32bits的密文/明文序列;cpu向in reg写入的32bits明文/密文被转存到in fifo;当in fifo被写入4个数据时,说明cpu已经写入128bits明文/密文序列,密码算法ip核可以开始加密/解密操作;同样,当out fifo被写入4个数据时,说明128bits密/明文序列已经被写入out fifo,密码算法ip核已经完成加/解密操作,cpu可以通过out reg读取密/明文。
[0162]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其它实施例的不同之处。
[0163]
以上所述仅是本发明的优选实施方式,虽然本发明已以较佳实施例披露如上,然而并非用以限定本发明。任何熟悉本领域的技术人员,在不脱离本发明技术方案范围情况下,都可利用上述揭示的方法和技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何的简单修改、等同变化及修饰,均仍属于本发明技术方案保护的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。