1.本发明涉及语义识别
技术领域:
:,并特别涉及一种相对位置编码方法及系统。
背景技术:
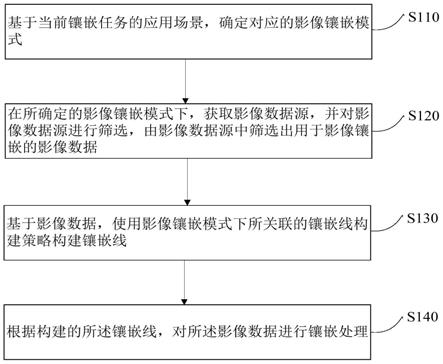
::2.对于任何一门语言,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念。一个单词在句子的位置或排列顺序不同,可能整个句子的意思就发生了偏差。例如当一个词在一个句子里多次出现时,如果神经网络模型不能区分前后分别出现的这个词而误认为它们都是一样的,那么模型的输出很可能会出错。引入词序信息有助于理解句子的本意,这种词序信息就表示为位置编码(positionencode/embedding,pe)。3.在传统的递归神经网络(recurrentneuralnetworks,rnns)中,输入序列(比如一个句子)里的各个单词按它们在序列中的前后位置被一个一个地处理,每个时间步rnn处理一个单词。虽然本身的表达向量(比如词嵌入向量)并不携带任何位置信息,但因为每个时间步的状态向量是不同的,所以即使在不同的时间步出现相同的词,rnn仍会区分开前后出现的词,从而产生不同的输出。我们可以认为,状态向量隐含了输入序列中的位置信息。其实它包含了过去时间步输入的词之间的语法和语义信息,这个信息对后续输入的词和输出产生的作用可以与位置信息的作用等同起来。4.为了避免rnns的递归机制导致的训练复杂度,transformer架构采用多头注意力(multi-headattention)机制。当一个序列进入multi-headattention时,将所有单词塞入并行处理,这大大提高了训练速度,如果不提供位置信息,那么这个序列里的相同的单词对multi-headattention(self-attention)模块来说就不会有语法和语义上的差别,它们会产生相同的输出。所以,需要在输入序列里人为地加入每个单词的位置信息。这个位置信息相当于起rnn中的时间步的作用。5.因为位置信息是以向量或者说编码的形式被产生的,这样才能与输入序列里的嵌入向量相加(或者做其它运算),因此位置信息也被称为位置编码或者位置嵌入向量。注意,输入序列的每个位置都有自己的位置编码,这个位置编码不是一个标量而是一个多维向量。如图1所示,加入位置编码的位置一般有两种:一种是在embedding与self-attention之间加入,位置编码向量可以直接按元素加进输入序列的词嵌入向量里,再输入进self-attention模块,可称之为外置的位置编码,也叫静态位置编码;另一种是在self-attention内部加入,位置编码向量通过训练产生,当self-attention模块被训练时,这个位置向量也一同被训练。训练结束前,这个位置编码的值不是固定的,因而这种内置的位置编码也可称之为动态位置编码。技术实现要素:6.具体来说,本发明为了解决上述技术问题,提出了一种相对位置编码方法,其中包括:7.步骤1、构建包括多头注意层的递归神经网络,获取待相对位置编码的数据序列,该数据序列可例如是语音序列数据或文本序列数据;8.步骤2、将该数据序列进行拆分后并行输入该多头注意层,该多头注意层通过计算拆分后数据在该数据序列中的相对位置,为每一个拆分后数据分配注意力分数;9.步骤3、基于各拆分后数据对应的注意力分数,生成各拆分后数据的相对位置编码。10.所述的相对位置编码方法,其中该多头注意层通过下述内容为拆分后数据分配注意力分数:11.步骤11、计算q,k,a:12.q=x*wq→q[n,t,h,64][0013]k=x*wk→k[n,t,h,64][0014]a[t,t,64]select←postable[2k 1,64][0015]其中q为查询;k为键值;a为相对位置编码;a通过rprpos_tab[2k 1,64]权重矩阵查表扩展得到,x:[n,t,da],wq:[h*64,da],wk:[h*64,da],postable:[2k 1,64],n表示输入数据序列的批次,t表示数据序列的长度,da表示数据序列的嵌入向量的维度,h表示该多头注意层中的头数量,64为该多头注意层中的头长度;[0016]步骤22、分别为q和k进行矩阵相乘,并相加矩阵相乘结果,得到该注意力分数:attentionscoree=q*k q*a。[0017]所述的相对位置编码方法,其中该步骤22包括:[0018]q[n,t,h,64]trans→qt[n,h,t,64][0019][0020]式中trans代表改变张量数据摆放顺序。[0021]所述的相对位置编码方法,其中q*a的计算过程为:[0022]q[n,t,h,64]trans→qt[n,h,t,64][0023]q*a:qt[n,h,t,64]*postable[2k 1,64]→[n*h,t,2k 1]select→[n,h,t,t][0024]式中trans代表改变张量数据摆放顺序。[0025]本发明还提出了一种相对位置编码系统,其中包括:[0026]初始模块,用于构建包括多头注意层的递归神经网络,获取待相对位置编码的数据序列;[0027]拆分模块,将该数据序列进行拆分后并行输入该多头注意层,该多头注意层通过计算拆分后数据在该数据序列中的相对位置,为每一个拆分后数据分配注意力分数;[0028]编码模块,基于各拆分后数据对应的注意力分数,生成各拆分后数据的相对位置编码。[0029]所述的相对位置编码系统,其中该多头注意层通过下述模块为拆分后数据分配注意力分数:[0030]第一计算模块,用于计算q,k,a:[0031]q=x*wq→q[n,t,h,64][0032]k=x*wk→k[n,t,h,64][0033]a[t,t,64]select←postable[2k 1,64][0034]其中q为查询;k为键值;a为相对位置编码;a通过rprpos_tab[2k 1,64]权重矩阵查表扩展得到,x:[n,t,da],wq:[h*64,da],wk:[h*64,da],postable:[2k 1,64],n表示输入数据序列的批次,t表示数据序列的长度,da表示数据序列的嵌入向量的维度,h表示该多头注意层中的头数量,64为该多头注意层中的头长度;[0035]第二计算模块,用于分别为q和k进行矩阵相乘,并相加矩阵相乘结果,得到该注意力分数:attentionscoree=q*k q*a。[0036]所述的相对位置编码系统,其中该第二计算模块,用于执行下式:[0037]q[n,t,h,64]trans→qt[n,h,t,64][0038][0039]式中trans代表改变张量数据摆放顺序。[0040]所述的相对位置编码系统,其中该第二计算模块,用于执行下式:[0041]q[n,t,h,64]trans→qt[n,h,t,64][0042]q*a:qt[n,h,t,64]*postable[2k 1,64]→[n*h,t,2k 1]select→[n,h,t,t][0043]式中trans代表改变张量数据摆放顺序。[0044]本发明还提出了一种存储介质,用于存储执行所述任意一种相对位置编码方法的程序。[0045]本发明还提出了一种客户端,用于上述任意一种基于相对位置编码系统。[0046]由以上方案可知,本发明的优点在于:[0047]1.减少2次transpose(q与a相乘前的transpose q×a的结果的tranpose)。[0048]2.[t,nh,64]*[t,t,64]的batchdot改为[nh,t,64]*[2k 1,64],减少了矩阵乘的计算量。其中batch_dot是tensorflow框架里面的叫法,同batch_matmul,即batch个matmul。附图说明[0049]图1为位置编码插入示意图;[0050]图2为self-attention中相对位置编码插入位置示意;[0051]图3为相对位置关系示意图;[0052]图4为rprembeddinglookuptable示意图;[0053]图5为本发明流程图。具体实施方式[0054]为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。[0055]transformer采用的是外置的静态位置编码,记编码向量的维度为dmodel,dmodel由解码器(decoder)模型的参数决定,同事也是嵌入式编码(embedding)的维度,位置向量pe的具体的编码公式如下:[0056][0057][0058]其中pos表示位置,i表示维度,式中2i和2i 1用于区分该维度是奇数位还是偶数位,奇数位和偶数位编码不同,然后会将词向量和位置向量相加得到每个词最终的输入。[0059]相对位置编码:[0060]1.相对位置编码的提出[0061]按照位置编码的定义,一个序列中,第i个单词和第j个单词的注意力分数attentionscore为:[0062][0063]其中wq,wk分别是self-attention给每个head加的query和key参数,和是输入xi和xj的词嵌入向量,ui和uj是第i个位置和第j个位置的位置向量。[0064]transformer所采用的位置编码方式,其相对位置信息是在self-attention计算的时候丢失,需要在self-attention的计算过程中加回来。具体做法是在计算attentionscore和weightedvalue时各加入一个可训练的表示相对位置的参数,这种表示相对位置的参数叫做相对位置编码(relativepositionrepresentations,rpr)。注意:rprembedding在同一层的attentionheads之间共享,但是在不同层的rpr可能不同。attentionscore和weightedvalue位置如图2所示。[0065]其中,attentionscoreeij和weightedvaluezi的计算公式如下:[0066][0067][0068]用表示xi和xj的相对位置信息,他们只和i和j的差值k有关。具体如下[0069][0070][0071]clip(x,k)=max(-k,min(k,x))ꢀꢀꢀꢀꢀꢀꢀ(5)[0072]如图3所示,self-attentionwithrelativepositionrepresentations论文中的图比较形象的表示序列中的相对位置关系。[0073]最大单词数被clipped在一个绝对的值k以内。向左k个,再左边均为0,向右k个,再右边均为k,所表示的index范围:2k 1,rpr权重a[t,t,headsize]是由pos_tab[2*k 1,headsize]查表而来,以k=3,t=10为例,rprembeddinglookuptable如图4所示。[0074]2.相对位置优化计算:[0075]将(3)式展开得到:[0076][0077]输入各个张量tensor及维度shape为:[0078]x:[n,t,da],wq:[h*64,da],wk:[h*64,da]和postable:[2k 1,64],其中,n表示输入语句序列的批次batch,t表示句子长度,da表示嵌入向量的维度,h表示self-attention的头数量headnum,64为头长度head_size。其中a由rprpos_tab[2k 1,64]权重矩阵查表扩展而来。[0079]计算流程如下:[0080]第一步:计算q,k,a。q:query查询;k:keys键值;a:相对位置编码,从位置编码的embeding向量table中去查询扩展得到的;trans是transpose的缩写,即改变张量数据摆放顺序。[0081]q=x*wq→q[n,t,h,64][0082]k=x*wk→k[n,t,h,64][0083]a[t,t,64]select←postable[2k 1,64][0084]箭头表示数据运算的结果,例如x和wq相乘得到维度为[n,t,h,64]的q。第二步:两个batch_matmul[0085][0086][0087]第三步:将第二步的两个结果累加[0088]attentionscoree=q*k q*a[0089]由于最大距离k截断,rpr权重a中存在大量重复元素,(6)式的第2项存在大量冗余计算,并且上述的计算过程中存在多次转置transpose。本方案提出将上述的第二步q与a的batch_matmul替换为q与rprpos_tab矩阵的batch_matmul,上述计算的第二步修改为:[0090]q[n,t,h,64]trans→qt[n,h,t,64][0091][0092]q*a:qt[n,h,t,64]*postable[2k 1,64]→[n*h,t,2k 1]select→[n,h,t,t][0093]具体来说,如图5所示,本发明提出了一种相对位置编码方法,其中包括:[0094]步骤1、构建包括多头注意层的递归神经网络,获取待相对位置编码的数据序列;[0095]步骤2、将该数据序列进行拆分后并行输入该多头注意层,该多头注意层通过计算拆分后数据在该数据序列中的相对位置,为每一个拆分后数据分配注意力分数;[0096]步骤3、基于各拆分后数据对应的注意力分数,生成各拆分后数据的相对位置编码。[0097]以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。[0098]本发明还提出了一种相对位置编码系统,其中包括:[0099]初始模块,用于构建包括多头注意层的递归神经网络,获取待相对位置编码的数据序列;[0100]拆分模块,将该数据序列进行拆分后并行输入该多头注意层,该多头注意层通过计算拆分后数据在该数据序列中的相对位置,为每一个拆分后数据分配注意力分数;[0101]编码模块,基于各拆分后数据对应的注意力分数,生成各拆分后数据的相对位置编码。[0102]所述的相对位置编码系统,其中该多头注意层通过下述模块为拆分后数据分配注意力分数:[0103]第一计算模块,用于计算q,k,a:[0104]q=x*wq→q[n,t,h,64][0105]k=x*wk→k[n,t,h,64][0106]a[t,t,64]select←postable[2k 1,64][0107]其中q为查询;k为键值;a为相对位置编码;a通过rprpos_tab[2k 1,64]权重矩阵查表扩展得到,x:[n,t,da],wq:[h*64,da],wk:[h*64,da],postable:[2k 1,64],n表示输入数据序列的批次,t表示数据序列的长度,da表示数据序列的嵌入向量的维度,h表示该多头注意层中的头数量,64为该多头注意层中的头长度;[0108]第二计算模块,用于分别为q和k进行矩阵相乘,并相加矩阵相乘结果,得到该注意力分数:attentionscoree=q*k q*a。[0109]所述的相对位置编码系统,其中该第二计算模块,用于执行下式:[0110]q[n,t,h,64]trans→qt[n,h,t,64][0111][0112]式中trans代表改变张量数据摆放顺序。[0113]所述的相对位置编码系统,其中该第二计算模块,用于执行下式:[0114]q[n,t,h,64]trans→qt[n,h,t,64][0115]q*a:qt[n,h,t,64]*postable[2k 1,64]→[n*h,t,2k 1]select→[n,h,t,t][0116]式中trans代表改变张量数据摆放顺序。[0117]本发明还提出了一种存储介质,用于存储执行所述任意一种相对位置编码方法的程序。[0118]本发明还提出了一种客户端,用于上述任意一种基于相对位置编码系统。当前第1页12当前第1页12
技术领域:
:,并特别涉及一种相对位置编码方法及系统。
背景技术:
::2.对于任何一门语言,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念。一个单词在句子的位置或排列顺序不同,可能整个句子的意思就发生了偏差。例如当一个词在一个句子里多次出现时,如果神经网络模型不能区分前后分别出现的这个词而误认为它们都是一样的,那么模型的输出很可能会出错。引入词序信息有助于理解句子的本意,这种词序信息就表示为位置编码(positionencode/embedding,pe)。3.在传统的递归神经网络(recurrentneuralnetworks,rnns)中,输入序列(比如一个句子)里的各个单词按它们在序列中的前后位置被一个一个地处理,每个时间步rnn处理一个单词。虽然本身的表达向量(比如词嵌入向量)并不携带任何位置信息,但因为每个时间步的状态向量是不同的,所以即使在不同的时间步出现相同的词,rnn仍会区分开前后出现的词,从而产生不同的输出。我们可以认为,状态向量隐含了输入序列中的位置信息。其实它包含了过去时间步输入的词之间的语法和语义信息,这个信息对后续输入的词和输出产生的作用可以与位置信息的作用等同起来。4.为了避免rnns的递归机制导致的训练复杂度,transformer架构采用多头注意力(multi-headattention)机制。当一个序列进入multi-headattention时,将所有单词塞入并行处理,这大大提高了训练速度,如果不提供位置信息,那么这个序列里的相同的单词对multi-headattention(self-attention)模块来说就不会有语法和语义上的差别,它们会产生相同的输出。所以,需要在输入序列里人为地加入每个单词的位置信息。这个位置信息相当于起rnn中的时间步的作用。5.因为位置信息是以向量或者说编码的形式被产生的,这样才能与输入序列里的嵌入向量相加(或者做其它运算),因此位置信息也被称为位置编码或者位置嵌入向量。注意,输入序列的每个位置都有自己的位置编码,这个位置编码不是一个标量而是一个多维向量。如图1所示,加入位置编码的位置一般有两种:一种是在embedding与self-attention之间加入,位置编码向量可以直接按元素加进输入序列的词嵌入向量里,再输入进self-attention模块,可称之为外置的位置编码,也叫静态位置编码;另一种是在self-attention内部加入,位置编码向量通过训练产生,当self-attention模块被训练时,这个位置向量也一同被训练。训练结束前,这个位置编码的值不是固定的,因而这种内置的位置编码也可称之为动态位置编码。技术实现要素:6.具体来说,本发明为了解决上述技术问题,提出了一种相对位置编码方法,其中包括:7.步骤1、构建包括多头注意层的递归神经网络,获取待相对位置编码的数据序列,该数据序列可例如是语音序列数据或文本序列数据;8.步骤2、将该数据序列进行拆分后并行输入该多头注意层,该多头注意层通过计算拆分后数据在该数据序列中的相对位置,为每一个拆分后数据分配注意力分数;9.步骤3、基于各拆分后数据对应的注意力分数,生成各拆分后数据的相对位置编码。10.所述的相对位置编码方法,其中该多头注意层通过下述内容为拆分后数据分配注意力分数:11.步骤11、计算q,k,a:12.q=x*wq→q[n,t,h,64][0013]k=x*wk→k[n,t,h,64][0014]a[t,t,64]select←postable[2k 1,64][0015]其中q为查询;k为键值;a为相对位置编码;a通过rprpos_tab[2k 1,64]权重矩阵查表扩展得到,x:[n,t,da],wq:[h*64,da],wk:[h*64,da],postable:[2k 1,64],n表示输入数据序列的批次,t表示数据序列的长度,da表示数据序列的嵌入向量的维度,h表示该多头注意层中的头数量,64为该多头注意层中的头长度;[0016]步骤22、分别为q和k进行矩阵相乘,并相加矩阵相乘结果,得到该注意力分数:attentionscoree=q*k q*a。[0017]所述的相对位置编码方法,其中该步骤22包括:[0018]q[n,t,h,64]trans→qt[n,h,t,64][0019][0020]式中trans代表改变张量数据摆放顺序。[0021]所述的相对位置编码方法,其中q*a的计算过程为:[0022]q[n,t,h,64]trans→qt[n,h,t,64][0023]q*a:qt[n,h,t,64]*postable[2k 1,64]→[n*h,t,2k 1]select→[n,h,t,t][0024]式中trans代表改变张量数据摆放顺序。[0025]本发明还提出了一种相对位置编码系统,其中包括:[0026]初始模块,用于构建包括多头注意层的递归神经网络,获取待相对位置编码的数据序列;[0027]拆分模块,将该数据序列进行拆分后并行输入该多头注意层,该多头注意层通过计算拆分后数据在该数据序列中的相对位置,为每一个拆分后数据分配注意力分数;[0028]编码模块,基于各拆分后数据对应的注意力分数,生成各拆分后数据的相对位置编码。[0029]所述的相对位置编码系统,其中该多头注意层通过下述模块为拆分后数据分配注意力分数:[0030]第一计算模块,用于计算q,k,a:[0031]q=x*wq→q[n,t,h,64][0032]k=x*wk→k[n,t,h,64][0033]a[t,t,64]select←postable[2k 1,64][0034]其中q为查询;k为键值;a为相对位置编码;a通过rprpos_tab[2k 1,64]权重矩阵查表扩展得到,x:[n,t,da],wq:[h*64,da],wk:[h*64,da],postable:[2k 1,64],n表示输入数据序列的批次,t表示数据序列的长度,da表示数据序列的嵌入向量的维度,h表示该多头注意层中的头数量,64为该多头注意层中的头长度;[0035]第二计算模块,用于分别为q和k进行矩阵相乘,并相加矩阵相乘结果,得到该注意力分数:attentionscoree=q*k q*a。[0036]所述的相对位置编码系统,其中该第二计算模块,用于执行下式:[0037]q[n,t,h,64]trans→qt[n,h,t,64][0038][0039]式中trans代表改变张量数据摆放顺序。[0040]所述的相对位置编码系统,其中该第二计算模块,用于执行下式:[0041]q[n,t,h,64]trans→qt[n,h,t,64][0042]q*a:qt[n,h,t,64]*postable[2k 1,64]→[n*h,t,2k 1]select→[n,h,t,t][0043]式中trans代表改变张量数据摆放顺序。[0044]本发明还提出了一种存储介质,用于存储执行所述任意一种相对位置编码方法的程序。[0045]本发明还提出了一种客户端,用于上述任意一种基于相对位置编码系统。[0046]由以上方案可知,本发明的优点在于:[0047]1.减少2次transpose(q与a相乘前的transpose q×a的结果的tranpose)。[0048]2.[t,nh,64]*[t,t,64]的batchdot改为[nh,t,64]*[2k 1,64],减少了矩阵乘的计算量。其中batch_dot是tensorflow框架里面的叫法,同batch_matmul,即batch个matmul。附图说明[0049]图1为位置编码插入示意图;[0050]图2为self-attention中相对位置编码插入位置示意;[0051]图3为相对位置关系示意图;[0052]图4为rprembeddinglookuptable示意图;[0053]图5为本发明流程图。具体实施方式[0054]为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。[0055]transformer采用的是外置的静态位置编码,记编码向量的维度为dmodel,dmodel由解码器(decoder)模型的参数决定,同事也是嵌入式编码(embedding)的维度,位置向量pe的具体的编码公式如下:[0056][0057][0058]其中pos表示位置,i表示维度,式中2i和2i 1用于区分该维度是奇数位还是偶数位,奇数位和偶数位编码不同,然后会将词向量和位置向量相加得到每个词最终的输入。[0059]相对位置编码:[0060]1.相对位置编码的提出[0061]按照位置编码的定义,一个序列中,第i个单词和第j个单词的注意力分数attentionscore为:[0062][0063]其中wq,wk分别是self-attention给每个head加的query和key参数,和是输入xi和xj的词嵌入向量,ui和uj是第i个位置和第j个位置的位置向量。[0064]transformer所采用的位置编码方式,其相对位置信息是在self-attention计算的时候丢失,需要在self-attention的计算过程中加回来。具体做法是在计算attentionscore和weightedvalue时各加入一个可训练的表示相对位置的参数,这种表示相对位置的参数叫做相对位置编码(relativepositionrepresentations,rpr)。注意:rprembedding在同一层的attentionheads之间共享,但是在不同层的rpr可能不同。attentionscore和weightedvalue位置如图2所示。[0065]其中,attentionscoreeij和weightedvaluezi的计算公式如下:[0066][0067][0068]用表示xi和xj的相对位置信息,他们只和i和j的差值k有关。具体如下[0069][0070][0071]clip(x,k)=max(-k,min(k,x))ꢀꢀꢀꢀꢀꢀꢀ(5)[0072]如图3所示,self-attentionwithrelativepositionrepresentations论文中的图比较形象的表示序列中的相对位置关系。[0073]最大单词数被clipped在一个绝对的值k以内。向左k个,再左边均为0,向右k个,再右边均为k,所表示的index范围:2k 1,rpr权重a[t,t,headsize]是由pos_tab[2*k 1,headsize]查表而来,以k=3,t=10为例,rprembeddinglookuptable如图4所示。[0074]2.相对位置优化计算:[0075]将(3)式展开得到:[0076][0077]输入各个张量tensor及维度shape为:[0078]x:[n,t,da],wq:[h*64,da],wk:[h*64,da]和postable:[2k 1,64],其中,n表示输入语句序列的批次batch,t表示句子长度,da表示嵌入向量的维度,h表示self-attention的头数量headnum,64为头长度head_size。其中a由rprpos_tab[2k 1,64]权重矩阵查表扩展而来。[0079]计算流程如下:[0080]第一步:计算q,k,a。q:query查询;k:keys键值;a:相对位置编码,从位置编码的embeding向量table中去查询扩展得到的;trans是transpose的缩写,即改变张量数据摆放顺序。[0081]q=x*wq→q[n,t,h,64][0082]k=x*wk→k[n,t,h,64][0083]a[t,t,64]select←postable[2k 1,64][0084]箭头表示数据运算的结果,例如x和wq相乘得到维度为[n,t,h,64]的q。第二步:两个batch_matmul[0085][0086][0087]第三步:将第二步的两个结果累加[0088]attentionscoree=q*k q*a[0089]由于最大距离k截断,rpr权重a中存在大量重复元素,(6)式的第2项存在大量冗余计算,并且上述的计算过程中存在多次转置transpose。本方案提出将上述的第二步q与a的batch_matmul替换为q与rprpos_tab矩阵的batch_matmul,上述计算的第二步修改为:[0090]q[n,t,h,64]trans→qt[n,h,t,64][0091][0092]q*a:qt[n,h,t,64]*postable[2k 1,64]→[n*h,t,2k 1]select→[n,h,t,t][0093]具体来说,如图5所示,本发明提出了一种相对位置编码方法,其中包括:[0094]步骤1、构建包括多头注意层的递归神经网络,获取待相对位置编码的数据序列;[0095]步骤2、将该数据序列进行拆分后并行输入该多头注意层,该多头注意层通过计算拆分后数据在该数据序列中的相对位置,为每一个拆分后数据分配注意力分数;[0096]步骤3、基于各拆分后数据对应的注意力分数,生成各拆分后数据的相对位置编码。[0097]以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。[0098]本发明还提出了一种相对位置编码系统,其中包括:[0099]初始模块,用于构建包括多头注意层的递归神经网络,获取待相对位置编码的数据序列;[0100]拆分模块,将该数据序列进行拆分后并行输入该多头注意层,该多头注意层通过计算拆分后数据在该数据序列中的相对位置,为每一个拆分后数据分配注意力分数;[0101]编码模块,基于各拆分后数据对应的注意力分数,生成各拆分后数据的相对位置编码。[0102]所述的相对位置编码系统,其中该多头注意层通过下述模块为拆分后数据分配注意力分数:[0103]第一计算模块,用于计算q,k,a:[0104]q=x*wq→q[n,t,h,64][0105]k=x*wk→k[n,t,h,64][0106]a[t,t,64]select←postable[2k 1,64][0107]其中q为查询;k为键值;a为相对位置编码;a通过rprpos_tab[2k 1,64]权重矩阵查表扩展得到,x:[n,t,da],wq:[h*64,da],wk:[h*64,da],postable:[2k 1,64],n表示输入数据序列的批次,t表示数据序列的长度,da表示数据序列的嵌入向量的维度,h表示该多头注意层中的头数量,64为该多头注意层中的头长度;[0108]第二计算模块,用于分别为q和k进行矩阵相乘,并相加矩阵相乘结果,得到该注意力分数:attentionscoree=q*k q*a。[0109]所述的相对位置编码系统,其中该第二计算模块,用于执行下式:[0110]q[n,t,h,64]trans→qt[n,h,t,64][0111][0112]式中trans代表改变张量数据摆放顺序。[0113]所述的相对位置编码系统,其中该第二计算模块,用于执行下式:[0114]q[n,t,h,64]trans→qt[n,h,t,64][0115]q*a:qt[n,h,t,64]*postable[2k 1,64]→[n*h,t,2k 1]select→[n,h,t,t][0116]式中trans代表改变张量数据摆放顺序。[0117]本发明还提出了一种存储介质,用于存储执行所述任意一种相对位置编码方法的程序。[0118]本发明还提出了一种客户端,用于上述任意一种基于相对位置编码系统。当前第1页12当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。