基于图转换网络的药物atccode预测方法
技术领域
1.本发明属于生物信息学领域,具体涉及一种基于图转换网络的药物atccode预测方法即dacpgtn,即利用图转换网络预测已知药物的atc code。
背景技术:
2.药物研发是一个耗时耗钱的工作,一种新药从研发到投入使用,要经历数十年的研究,花费上亿美金。如何从现有已批准的药物中,发现其新的适应症,降低研发成本,是当前生物信息学领域的一个研究热点。药品的解剖学、治疗学及化学分类系统(anatomical therapeutic chemical,atc),是世界卫生组织对药品的官方分类系统。atc系统中标准atc code的引入,极大的方便了治疗阶段的药物使用。对一个给定化合物的解剖治疗化学(atc)分类进行预测,推断其有效成分,治疗,药理和化学性质,有助于正确使用该药物或推断该化合物的新用途,方便了解其适应症和潜在的毒副作用,并加快药物开发过程,是一种常见的老药新用研究思路。atc code将药物分为以下五个级别:一级,药物作用的器官或解剖系统;二级,药理作用;三级和四级,化学、药理和治疗亚组;五级,特定的单药或联合用药。第一级包括14个类别,分别为(1)alimentary tract and metabolism,(2)blood and blood forming organs,(3)cardiovascular system,(4)dermatologicals,(5)genitourinary system and sex hormones,(6)systemic hormonal preparations,excluding sex hormones and insulins,(7)anti-infectives for systemic use,(8)antineoplastic and immunomodulating agents,(9)musculoskeletal system,(10)nervous system,(11)antiparasitic products,insecticides and repellents,(12)respiratory system,(13)sensory organs,(14)various。
3.在目前使用广泛的药物信息数据库中,存在大量没有atccode的药物,应用传统的实验方法对新药或已有药物进行atccode分类,费时费力。伴随着药物相关数据的积累,以及各种药物信息学数据库的快速发展,通过现有技术手段对药物atccode进行预测作为一种国际上被广泛采用的研发战略,具有更高的投入产出效率。如何设计有效的药物atc code预测方法已经越来越引起人们的关注。在最初的药物atccode研究中,将atccode的预测定义为单标签学习任务,由于该生物系统的多标签性质,这被认为是不合适的,化合物的atccode系统是一个多标签的问题。
4.近年来,提出了一些针对药物atc类别分类的多标签分类方法。例如:chen等,首先提出了通过对药物化学-化学相互作用信息和化学-化学相似性信息进行整合,开发一种分类方法对药物atccode进行预测,并构建了药物atccode一级代码基准数据集。在此基准数据集的基础上,提出了一些集成多种药物相关信息的分类方法,预测药物的atccode一级代码。cheng等提出了一种多标签的gaussian核回归分类器iatc-misf,基于药物化学-化学相互作用、结构和指纹相似度将药物分配到14个atccode第一级类别中。在此之后,cheng等通过进一步整合基于药物本体的预测因子iatc-mdo,在此基础上将iatc-misf改进为iatc-mhyb,提升了分类器的预测性能。nanni和brahnam开发了一种基于梯度直方图算法的多标
签分类器enslif,将药物化合物的一维特征向量构建成为二维矩阵,在分类性能上有一定程度的提升。zhou等构建多个药物相互作用网络,并通过网络嵌入算法mashup提取网络中的药物特征,采用random k-labelsets(rakel)algorithm将原始的多标签分类问题转化为多个单标签分类问题,在分类阶段采用经典的机器学习算法支持向量机(svm)构建分类器iatc-nrakel,取得较好的预测效果。在此分类器的基础上,zhou等简化分类器的输入,提出了一种仅使用药物指纹信息(smiles格式)作为特征输入的多标签分类器iatc-frakel,用于识别药物的atccode,并提供了web服务。wang等提出了一种预测药物第一级别atccode的方法atc-nlsp,atc-nlsp使用机器学习框架,结合药物-药物相互作用信息、结构相似性和指纹相似性,并采用nlsp方法来探讨标签之间的相关性,提供更好的预测结果。随着深度学习技术在多个领域的成功应用,nanni等提出了一种基于深度学习方法集成的一级atc code多标签分类器系统(fus3),利用卷积神经网络(cnn)和长短期记忆网络提取特征,在两个通用分类器上进行训练,取得了较好的效果。当前最新的研究,zhao等提出了一种新的药物atc code端对端预测模型cgatcpred,其使用cnn层从7个药物关联得分矩阵中提取复合特征,并建立了atc标签的关联图,结合词嵌入信息通过两层gcn层学习标签信息。利用复合特征与生成的标签相关矩阵之间的点积来构造新的特征,将生成的新特征与cnn层提取的复合特征拼接到全连接神经网络层中,预测药物的atccode。
5.综上所述,对于现有的药物atccode预测方法,大多基于药物自身的性质和药物atccode标签间的相关性进行预测。在一定程度上,忽略了与药物相关的靶标蛋白质、疾病等关联信息对药物atc code预测的潜在作用,未对已知的不同类别数据间的关联信息进行充分利用。
技术实现要素:
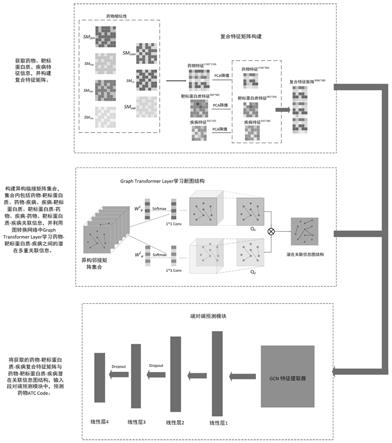
6.为了解决上述问题,本发明提出了一个基于图转换网络的药物atccode预测方法即dacpgtn(drug-atc code prediction method based on graph transformer network)。该方法的实施是基于药物及其相关的靶标蛋白质、疾病之间的潜在关联信息,可对药物atccode的预测提供有价值的信息。当两种药物作用于同种靶标蛋白质或疾病,或两种药物间与某种靶标蛋白质或疾病存在多重关联关系,两种药物的atccode类别就可能相同的假设。首先获取药物及其相关的靶标蛋白质、疾病的特征,构建复合特征矩阵;其次根据药物-靶标蛋白质、药物-疾病、靶标蛋白质-疾病之间的关联信息构建一组异构网络,并利用图转换网络中的graphtransformerlayer学习这一组异构网络中潜在的关联信息;最终将获取的复合特征矩阵及潜在关联信息矩阵,输入端对端预测模块,对药物atccode进行预测。通过与其他方法比较,及在数据集上测试表明,该方法在药物atc code预测方面具有较好的性能。
7.本发明采用的技术方案为:(1)构建药物-靶标蛋白质-疾病复合特征矩阵(2)构建药物、靶标蛋白质、疾病之间的异构网络(3)获取药物-靶标蛋白质-疾病之间潜在关联信息(4)预测药物atccode标签本发明的有益效果是:本发明通过集成药物与相关实体的复合特征信息,并利用
图转换网络中graph transformer layer获取药物与相关实体间的潜在关联,通过充分利用已知生物学信息,实验结果表明该药物atccode预测方法能有效预测药物的atccode标签。本发明简单有效,通过与其他方法比较,及在数据集上测试表明,该发明在药物atc code预测方面具有较好的性能。
附图说明
8.图1为本发明dacpgtn的流程图。
9.图2为本发明的药物-靶标蛋白-疾病复合特征构建示意图。
10.图3为本发明的多源异构网络构建及graphtransformerlayer学习潜在关联示意图。
11.图4为本发明的端对端预测模块示意图。
12.图5为本发明的gcn特征提取器输出节点数对结果影响示意图。
具体实施方式
13.如图1-图5所示,一种基于图转换网络的药物atccode预测方法,包括以下步骤:1)利用已知药物获取与药物相关的靶标蛋白质、疾病,并计算疾病相似性与获取靶标蛋白相似性,靶标蛋白质获取、疾病相似性计算具体过程如下:首先,从string数据库中获取药物相关靶标蛋白质间的综合得分,作为靶标蛋白质的相似性信息;其次,获取药物与相关疾病间的关联矩阵,利用关联矩阵计算每一列的皮尔逊相关系数,即每种疾病与所有药物关联信息中提供的信息,作为疾病相似性信息;对获取的已知的不同评价标准下的药物相似性信息,同一维度上做叠加操作并取均值,作为药物特征矩阵;靶标蛋白质相似性、疾病相似性,作为靶标蛋白质、疾病的特征矩阵;对三种实体的特征矩阵,利用pca技术降维到同一维度,上下拼接构建复合特征矩阵;2)构建药物-靶标蛋白质异构网络、药物-疾病异构网络、靶标蛋白质-疾病异构网络及各异构网络的转置:根据实体间关联信息,异构网络具体构建过程如下:drug-target异构网络,若当前药物i与靶标蛋白j之间存在关联关系,异构网络中相应位置元素drug-target
ij
值为1,相应位置元素值为0,最终得到值全为0、1的稀疏矩阵drug-target;同理,构建target-disease异构网络、target-disease异构网络;对由实体间关联信息构建的异构网络,进行转置操作,最终得到不同实体间异构网络集合即药物-靶标蛋白质异构网络(drug-target),药物-疾病异构网络(target-disease),靶标蛋白质-疾病异构网络(target-disease),靶标蛋白质-药物异构网络(drug-target
t
),疾病-药物异构网络(drug-disease
t
),疾病-靶标蛋白质异构网络(target-disease
t
);3)基于步骤2)获取的异构网络集合使用graph transformer layer获取药物-靶标蛋白质-疾病三种实体间潜在的关联信息,构建新的潜在关联信息矩阵;graph transformer layer具体的实现如下:其中φ为卷积层,w
φ
∈r1×1×k为卷积层φ的参数;graph transformer layer从异构网络集合中选择邻接矩阵(不同类型异构网络),并通过两个选择的邻接矩阵q1和q2的
矩阵乘法,学习到新的图结构;邻接矩阵的软选择是将从中获得非负权重,并对候选邻接矩阵进行1
×
1卷积加权求和;4)基于步骤3)中graph transformer layer获取的药物-靶标蛋白质-疾病间潜在的关联信息,与步骤1)中构建的复合特征矩阵,输入到端对端预测模块,对药物节点进行atccode预测。
14.所述的步骤4)中,端对端预测模块,由gcn层作为特征提取器,使用多层线性层进行降维操作,线性层间添加dropout;gcn层输出节点数为150,线性层1包含150个神经元,线性层2包含128个神经元,线性层3包含64个神经元,线性层4作为输出层,包含14个神经元;端对端预测模块训练及预测阶段,对多标签分类问题转化为预测的目标类得分与非目标类得分两两作差比较,利用softmax激活函数配合交叉熵损失函数在多标签分类上的平滑推广,引入一个额外的0类,使目标类的分数都大于s0,非目标类的分数都小于s0,具体实现通过下式完成:ω
neg
,ω
pos
分别为正负样本集合,设定阈值s0=0,最终得到loss即为softmax激活函数与交叉熵损失函数在多标签分类问题上的推广:loss(y
true
,y
pred
)=logsumexp(y
pred-neg
,0) logsumexp(y
pred-pos
,0)借助于logsumexp函数的良好性质,平衡权重且解决类别不平衡问题,进行端对端预测模块的训练,在最终预测阶段,最后一层线性层中,输出大于0的类别即为预测结果。
15.如图1所示,本发明具体实现过程如下:一、药物-靶标蛋白质-疾病复合特征构建本方法所应用的数据集包括药物集合、靶标蛋白质集合、疾病集合。
16.1.药物及其相关靶标蛋白质、疾病数据获取在atccode的研究方面,chen等人构建了基准数据集来促进模型在atccode第一层次的比较。基准数据集包含3883个化合物,每个化合物对应于14个atc code第一级类别中的一个或多个。本方法实验在此数据集基础上,做进一步改进后进行。在kegg与drugbank数据库中,收集药物的靶标和疾病关联数据,3883个药物中有1749个药物具有靶标和疾病关联信息,最终这1749个药物作为本方法的基准数据集。
17.表1.本方法数据集中实体信息具体情况实体类型数量统计药物1749靶标蛋白质982疾病3552.药物相似性信息首先,使用zhao等人提供的关于chen等数据集中所有药物的7个相似性信息见公
式(1),分别为:{sm
sim
,sm
exp
,sm
dat
,sm
tex
,sm
com
,sm
cp
,sm
sub
}r
3883
×
3883
×7#(1)“相似性”、“实验性”、“数据库”、“文本挖掘”和“综合分数”、相似性计算工具simcomp和subcomp计算得到化合物对之间的相似性。从这七个相似性分数矩阵中,提取出本方法所需的1749种药物的所有信息,最终得到药物相似性分数矩阵见公式(2),作为本方法中药物相似性信息:{sm
sim
,sm
exp
,sm
dat
,sm
tex
,sm
com
,sm
cp
,sm
sub
}r
1749
×
1749
×7#(2)3.靶标蛋白质相似性信息根据本方法中所用到的982种靶标蛋白,从string库下载文件
‘
9606.protein.info.v11.0’,从中遍历982种蛋白质序号,得到两个蛋白质之间的综合得分(combined score),构建蛋白质关系分数矩阵target
982
×
982
,通过公式(3)对得到的矩阵进行归一化处理,最终得到蛋白质综合分数矩阵:4.疾病相似性信息计算利用chen等基准数据集中所有药物与已知符合本方法要求的355种疾病,构建药物-疾病关系矩阵,若药物与疾病之间存在关系,矩阵中相应位置值为1,否则为0,得到药物-疾病之间的关系稀疏矩阵drug-disease
3883
×
355
。利用得到的药物-疾病关系矩阵,计算每一列之间的皮尔逊相关系数,得到疾病之间的相关性矩阵,通过公式(4)计算皮尔逊相关性:a,b代表矩阵中不相同的两列,i代表当前列中第i行,n=3883。
18.5.构建复合特征矩阵将获取的7个药物相似性信息,在同一维度上对7个相似性矩阵进行叠加操作,即对当前每个药物的7个相似性分数进行求和操作,并进行均值化处理,得到最终本方法中使用的药物相似性分数矩阵,作为药物特征矩阵。将蛋白质综合分数矩阵作为靶标蛋白质特征矩阵,将计算获取的疾病间皮尔逊相关系数矩阵作为疾病特征矩阵。为使其学习到足够多的特征,且避免维度太大造成模型学习过程中出现梯度消失等问题。在最大程度保留相关实体特征的同时,一定程度上去除对实验结果不利的噪声数据,使特征之间相互独立,更好的为atccode类别分类提供有价值的信息,将三种数据的特征矩阵依次使用pca技术进行降维。经过试验,选取最优特征维度为300。经过降维后,对三种数据的特征矩阵进行拼接,得到最终dacpgtn模型中的节点复合特征矩阵。
19.二、构建药物、靶标蛋白质、疾病不同实体间异构网络在实验数据的构建上,首先根据实验数据集中选出的1749种药物和982种靶标蛋白质,查找kegg和drugbank两个数据
库中的信息,构建drug-target邻接矩阵。若药物i与靶标蛋白j之间存在关系,drug-target
ij
为1,否则值为0,最终得到值全为0、1的稀疏矩阵drug-targe
1749
×
982
。
20.根据相同的原理,构建drug-disease邻接矩阵,若药物与疾病在kegg和drugbank两个数据库中存在关联关系,drug-disease
ij
值为1,否则值为0,最终得到稀疏矩阵drug-disease
1749
×
355
。
21.同时,从现有的药物信息数据库中,提取了实验中982种药物和355种疾病的关系信息,并构建target-disease关系矩阵。矩阵中值的定义与药物蛋白质关系矩阵的构建类似,最终得到稀疏矩阵target-disease
982
×
355
。
22.为更好的学习潜在关联信息,对上述构建的异构矩阵作转置处理,最终共得到六个邻接矩阵(d_t代表邻接矩阵drug-target
1749
×
982
,d_d代表邻接矩阵drug-disease
1749
×
355
,t_d代表邻接矩阵target-disease
982
×
355
,d_t
t
代表d_t的转置,d_d
t
代表d_d的转置,t_d
t
代表t_d的转置。)。
23.三、获取药物-靶标蛋白质-疾病之间潜在关联信息利用图转换网络中的graph transformerlayer获取药物-靶标蛋白质-疾病之间潜在关联信息,图转换网络中的graph transformerlayer是一种对不同边类型和复合关系的软选择,即使用多个候选邻接矩阵来寻找新的图结构,以执行更有效的图卷积,并学习更强大的节点表示的方法。graph transformer layer具体的实现通过公式(5)完成:其中φ为卷积层,w
φ
∈r1×1×k为卷积层φ的参数。graph transformer layer从邻接矩阵集合中选择邻接矩阵(不同类型异构网络),并通过两个选择的邻接矩阵q1和q2的矩阵乘法,学习到新的图结构。邻接矩阵的软选择是将从中获得非负权重,并对候选邻接矩阵进行1
×
1卷积加权求和。在实现过程中,通过公式(6-8)对构建的邻接矩阵进行graph transformer layer操作,每一个qi可以表示为可以表示为表示边的集合,l表示第l个graph transformer layer,表示当前边矩阵在第l层的权重。通过不同类型邻接矩阵的相乘操作,实现节点的转移,得到不同节点之间的连接关系。使用graph transformer layer时,若为单层,则在第一层设置两个卷积核,多层,则在除第一层外的其他graph transformer layer,设置1个卷积核。根据权重得到新的图结构后,再进行邻接矩阵之间的相乘操作。为了增强数值稳定性,对每一层得的邻接矩阵,用度矩阵d-1
对其进行归一化处理,最终得到当前graph transformer layer的图结构输出a
(l)
。。a
(l)
=d-1
q1q2#(8)
24.本发明基于上述步骤中构建的一组异构网络,采用graph transformer layer对不同异构网络中的关联信息进行学习,最终获取的代表不同节点间潜在关联的图信息矩
阵。
25.四、端对端预测模块对药物atccode进行预测(1)gcn层对复合特征及潜在关联信息矩阵进行特征提取获取全新的图信息矩阵后,引入图卷积神经网络(gcn),作为特征提取器,对图数据进行卷积操作。对于gcn网络,通过公式(9)进行层与层之间的传播:通过公式(9)进行层与层之间的传播:为当前输入的图结构即经过graph transformer layer学习后生成的新图结构,潜在关联信息矩阵,为的度矩阵,h为当前gcn网络层的输入特征,即构建的节点复合特征矩阵,w
(l)
∈rd×d为可训练的权重矩阵,h
(l 1)
为当前gcn网络层的特征矩阵输出,σ代表激活函数relu。
26.为学习不同节点类型之间的多种连接关系,在graph transformer layer 1
×
1卷积的输出通道可以设置为多通道c,通过加权求和后的邻接矩阵q1,q2变为临接张量经过l个graph transformer layer叠加后,得到张量对张量的每一个通道应用一个gcn层,将多通道通过公式(10)进行:||代表连接操作符,c代表输出通道数,代表张量的第i个邻接矩阵,di代表的度矩阵,w∈rd×d代表可训练的跨通道共享权重矩阵,x∈rn×d代表特征矩阵,对于有向图的计算,利用d-1
a代替对邻接矩阵进行归一化处理。
27.将构建的节点特征矩阵与graph transformer layer获得的临接张量,应用上述gcn层的操作后,获得特定维度的输出,(2)多层线性层进行降维预测使用多层线性层,对gcn层的输出进行降维处理,gcn模块提取的特征向量作为全连接层第一层的输入,最后一层线性层的输出维度与药物atccode标签向量维度相同,作为药物的atc分类预测结果。为了解决多层网络叠加存在的过拟合问题,在第一层线性层后使用relu激活函数处理,后续每一层线性层之间,添加dropout层。dropout层按照一定的概率将神经元节点从网络中移除,对于随机梯度下降来说,随机移除神经元的引入使每一个迭代都在训练不同的网络,dropout层可以有效的解决过拟合问题,且提高模型的泛化能力。
28.(3)模型优化算法及损失函数在dacpgtn模型训练过程中,采用adam optimizer随机优化算法进行学习,该算法在深度学习中具有优秀的性能,与其他类型的随机优化算法相比有很大的优势。
29.损失函数参考su将单标签分类问题中使用的softmax激活函数配合交叉熵损失函数(cross entropy loss),在多标签分类问题上的推广。在原有单标签分类中,其交叉熵损失函数定义为(11):
n代表所有可能出现的类别数,si为其中的单个类别。推导为max函数的近似,如公式(12)所示:在多标签分类问题中,同样希望每个目标类得分都不小于每个非目标类的得分,根据同样的原理得到loss的推广,公式(13)ω
neg
,ω
pos
分别为正负样本集合。
30.在多标签问题预测中,样本具有的标签数k为非固定值常数,需要一个阈值来确定输出哪些类。为此,引入一个额外的0类,希望目标类的分数都大于s0,非目标类的分数都小于s0,得到公式(14):若设定阈值s0=0对公式(14)进行简化得到公式(15):最终得到损失函数公式(16)即为softmax激活函数与交叉熵损失函数在多标签分类问题上的推广:loss(y
true
,y
pred
)=logsumexp(y
pred-neg
,0) logsumexp(y
pred-pos
,0)=logsumexp((y
pred-y
true
),0) logsumexp((y
pred-(1-y
true
)),0)#(16)y
true
为药物真实标签,y
pred
为药物预测标签,y
pred-neg
,y
pred-pos
分别为药物预测正负样本集合。在模型的预测阶段,输出最后一层线性层中输出大于0的类别。本发明与之前
atccode分类研究中的方法相比,不再将多标签问题转化为多个二分类问题,而是转化为目标类得分与非目标类得分的比较,解决了类别不平衡性且借助于logsumexp函数的良好性质,自动平衡了每一项的权重。
31.五、实验验证1.评价指标为了验证本方法的有效性,本方法采用十次十折交叉验证进行实验,测试dacpgtn模型的预测性能。
32.(1)十折交叉验证k-fold交叉验证是深度学习中常用的交叉验证方法,常用于更严谨的评价模型的性能,在本方法的性能验证中,使用10折交叉验证对模型性能进行评估。每一折中,将数据集中药物样本划分为(训练集:验证集):测试集=(9:1):1,每次10折交叉验证都取10折结果的平均值。最终进行十次10折交叉验证取平均值,评价模型的性能,保证实验结果的误差尽可能的小。
33.(2)评价指标在多标签分类问题中,由于单个样本存在一个或多个标签,传统的单标签评价指标在此不在具有实际意义,与传统的单标签评价标准相比,多标签问题的评价标准更加复杂精细。chou等定义了5个评价多标签分类器性能的评价标准,之前atccode标签分类问题的研究也使用此评价标准进行比较,为保证实验的公平性,本方法在实验中也使用此评价标准。评价标准具体的定义见公式(17-21):21):21):21):21):其中n为样本总数,m为标签数,运算符|
·
|用于计算集合中的元素个数,∪/∩代表集合的并/交运算,yi代表当前样本i的真实标签向量,y
i*
代表当前样本i经过模型的预测标签向量,k代表判断两个向量是否完全相同的函数,通过公式(22)定义:
2.实验结果为了评价dacpgtn的有效性,dacpgtn与其他五种方法进行比较(cgatcpred、iatc-nrakbl、iatc_misf、ml-knn和randomforest)。cgatcpred是基于药物相似性信息与标签相关性信息的药物atccode预测方法;iatc-nrakbl是基于药物相互作用网络和rakel算法的药物atccode预测方法;iatc_misf是基于药物化学-化学相互作用、结构和指纹相似度并利用gaussian核回归方法作为分类器预测药物atccode的方法;ml-knn和randomforest是多标签分类中通用的分类方法。对于比较的5种方法,具体的药物atccode预测方法,参数设置都与其确定的最优参数相同。对于基础多标签分类方法,参数都设置为默认。dacpgtn方法的参数设置如表2所示。
34.表2.dacpgtn方法参数设置grapb transformer layer层数1输出通道数2training epochs250learning rate0.005weight decay0.001gcn层数1输入特征维度300gcn层输出维度150fc1神经元数150fc2神经元数128fc3神经元数64fc4神经元数14dropout0.2(1)十倍交叉验证分析在数据集上进行对比实验,所有的实验都进行10次十折交叉验证并取均值,保证对比实验的公平性。具体的实验结果在下表中列出:表3.dacpgtn方法与其他方法对比结果(10
×
10-fold cv)classifieraimingcoverageaccuracyabsolute trueabsolute falsedacpgtn0.85430.85170.83200.79020.0241cgatcpred0.78640.80220.77110.72900.0338iatc-nrakel0.77440.80200.75500.69470.0376iatc_misf0.70940.71270.70360.63060.0244ml-knn0.72930.70710.68610.63000.0433randomforest0.67230.65330.64710.61870.0368由表3可知,本发明dacpgtn方法在当前数据集上的预测效果最好。与当前药物atccode分类问题中最优模型cgatcpred相比,在aiming上提升6.8%,在coverage上提升
5%,在accuracy上提升5.9%,在absolutetrue上提升5.8%。五种评价标准中,accuracy和absolutetrue是最重要的评价标准,dacpgtn方法在这两个指标上也取得了一定程度的提升。这些结果表明,当药物化合物具有靶标蛋白质和疾病之间的关联信息时,本发明dacpgtn方法使用图转换网络中graph transformer layer,可以从多个异构图中学习到药物、靶标蛋白质、疾病之间潜在的关联信息。通过整合多种节点间的关联信息与复合特征,可以在atccode分类中取得更好的分类性能。
35.(2)gcn层的输出维度对实验结果的影响在本实验中,gcn层通过学习复合特征矩阵和graph transformer layer得到的潜在关联信息矩阵,为端对端预测阶段提供分类信息。为验证gcn层节点特征输出维度对实验结果的影响,且保证模型达到最佳性能,进行了以下实验,结果如图5所示。gcn层的原始节点输入维度dim=300,预先设置4个输出维度,通过10折交叉验证实验,得到gcn层节点不同输出维度在5个评价标准上的表现。由图5可以看出,gcn层输出维度为150时,模型取得最佳预测性能。因此,将预测模块gcn层的节点输出维度设为dim=150,所有的实验都在此参数上进行。
36.(3)消融实验、为了更加合理的解释本发明中,药物-靶标蛋白质关联信息和药物-疾病关联信息,在经过graph transformer layer学习后获取不同节点潜在关联信息,对药物atc code分类问题的影响。分别将药物-靶标蛋白质关联信息、药物-疾病关联信息,作为graph transformer layer异构图的输入,并重新构建节点复合特征矩阵作为gcn端对端预测模块的输入。与上述实验相同的参数,进行10折交叉验证,得到的结果如表4所示。
37.表4.消融实验结果classifieraimingcoverageaccuracyabsolutetrueabsolutefalsedacpgtn-disease0.84420.84370.82310.77820.02516dacpgtn-target0.83270.83070.80510.75360.02875由上表可得,当只具有药物-靶标蛋白质关联信息或只具有药物-疾病关联信息作为graph transformer layer输入时,本发明的性能会有一定的下降,且单独的药物靶标蛋白质关联信息要优于单独的药物疾病信息。由于药物靶标蛋白质关联信息比药物疾病关联信息多,获取节点间潜在关联信息会较多,可以在分类问题中提供更多有价值的信息。atc code分类问题中,考虑多源关联信息与只考虑单一的关联信息相比,本发明dacpgtn方法能取得更好的预测性能。充分说明dacpgtn方法可以从多源关联信息中提取对分类有用的信息,通过学习不同异构图获得新的图结构,经过端对端预测模块的学习后,在atccode分类问题上具有明显的优势。
38.以上所述之实施例,只是本发明的较佳实例而已,并非限制本发明的实施范围,故凡依本发明专利范围所述的构造、特征及原理所做的等效变化或修饰,均应包括于本发明申请专利范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。