1.本发明涉及情绪侦测与情感分析技术领域,具体地说,涉及一种基于情感知识增强的词语分布式表示学习系统。
背景技术:
2.情感分析是自然语言处理中的一个重要任务,它可以帮助消费者,公司以及专家系统做出更加合理的决策。在现有的研究中通常把词向量作为研究的特征,利用词向量来完成包括情感分析在内的许多任务。然而现存的词向量学习技术在应对情感分析时,没有考虑到情感信息的目标依赖性。比如:在评论句子s1“新买的电脑运行得很快,不过它的电量消耗得也很快”中,对于同样的评价“快”,现有的模型不能够识别出对于电脑而言,运行速度“快”是有利的,而对于电池来说,消耗得“快”反而是不利的。对情感信息目标依赖性的缺乏将影响模型的情感分析效果。
3.知识图谱是语义网络的知识库,通常以三元组的形式呈现:头部(head),关系(relation)和尾部(tail)。通用的知识图谱,头部和尾部由实体名词构成,关系表述了头部与尾部实体在现实世界中的联系。情感知识图谱是语义网络的进一步延伸,它的头部是评价目标,关系是评价内容,尾部是情感倾向。比如在评论句子s1中,电脑、电池可以作为评价目标,快可以作为评价内容。
4.情感知识图谱是包含了许多依赖信息的外部知识的集合体,整合情感知识图谱可以在一定程度上解决“情感信息目标依赖性”的问题。然而在现有的研究中,情感知识图谱非常稀少,并且他们的构建都是人工完成的,构建它需要花费大量的人力资源。因此简单利用现存的情感知识图谱并不能完全解决“情感信息目标依赖性”的问题。
5.情感词典中包含了许多的情感信息,对于给定的一个词汇,情感词典可以分析出这个词汇的情感极性。他们在许多开放领域中有着不错的效果。
6.因此有些学者希望通过整合情感词典来改进情感分析的效果,然而这些情感知识效果非常有限,他们缺少专业领域下的情感依赖信息。不能很好地解决专业领域的“情感信息目标依赖性”的问题。
技术实现要素:
7.本发明的内容是提供一种基于情感知识增强的词语分布式表示学习系统,其能够克服现有技术的某种或某些缺陷。
8.根据本发明的一种基于情感知识增强的词语分布式表示学习系统,其包括情感知识整合框架和弱监督知识生成框架;情感知识整合框架包括知识查询模块,知识整合模块以及词表示生成模块;弱监督知识生成框架用于生成领域情感词典dsd,dsd整合了目标领域的无标签文本、领域独立的情感词典和目标领域文本的标签三部分的资源。
9.作为优选,在知识查询模块中,给定一个评论句子s,知识查询模块的功能是帮助这个句子s找到最有可能帮助分析句子s的知识;为了达到这个目标,对于输入的句子,对其
进行分词,然后将每个词作为一个查询目标,对领域情感词典dsd进行查询;对于查询得到的知识使用过滤器对其进行过滤,并引入知识期望和知识全局注意力机制,将过滤后的知识分为了三个状态:原始知识集合o_set,期望知识集合e_set以及候选知识集合c_set;通过知识查询请求得的知识集合即原始知识集合,它可以由(1)得到:
10.o_set=knowledge_query(t,dsd)
ꢀꢀꢀ
(1)
11.t即为查询词,knowledge_query是知识查询函数,o_set具体内容如(2)所示:
12.o_set=[(t,op0,judge0,fr0,conflict0,p_num0,n_num0,lexicon_po0),...,(t,opi,judgei,fri,conflicti,p_numi,n_numi,lexicon_poi)]
ꢀꢀꢀ
(2)
[0013]
在o_set中的知识是未经过处理的原始知识,其中opi是查询词t所匹配的观点知识,judgei是查询词t匹配观点词opi后被分配的情感极性,fri是查询词t与观点词opi在知识来源语料上出现的次数,conflicti是指在知识来源预料中知识是否存在着冲突的认知,p_num和n_num分别代表冲突认知中积极认知和消极认知的次数,lexicon_poi表示该知识在外部情感词典中的情感倾向值;为了更好得筛选有冲突认知的知识,引入知识期望过滤器,通过(3)来过滤潜在冲突的知识:
[0014]
e_set=e_filter(o_set,expectation_gate)
ꢀꢀꢀ
(3)
[0015]
在(3)中,e_filter是知识期望过滤函数,e_set是o_set的一个子集,expectation_gate是来过滤冲突知识的超参数;然而,知识期望无法判断查询到的知识是否真的对情感分析具有帮助,引入知识全局注意力机制,并通过(4)的注意力过滤器过滤e_set中的知识:
[0016]
c_set=k_attention(e_set,input0)
ꢀꢀꢀ
(4)
[0017]
在(4)中的c_set是一组三元组的集合,具体内容如(5)所示:
[0018]
c_set=[(t,op0,judge0),...,(t,ops,judges)]
ꢀꢀꢀ
(5)
[0019]
op是知识库中与查询词想匹配的观点词,judge为当查询词t与观点词op匹配时的情感极性;c_set中的知识将会整合到文本中去。
[0020]
作为优选,通过公式(6)、(7)来计算知识期望并过滤潜在冲突的知识:
[0021]
em
op
=(p_num/fr-n_num/fr)
ꢀꢀꢀ
(6)
[0022][0023]
对于情感分类任务而言,p_num和n_num是在数据集中用户对查询词和观点词所分配的积极和消极标签的数量;对于情绪侦测任务而言,把情绪划分为两大类,分别为情感取向积极的情绪和情感取向消极的情绪,让这两大类标签下子标签的数量作为p_num和n_num的值;对于冲突概率越大的知识,它的知识期望越小,因此通过设置expectation_gate就能够有效过滤潜在冲突的知识;在公式(7)中,expectation即为计算出的知识期望,em
op
为知识期望计算的中间结果,可以由公式(6)取得,emi表示当知识出现频率为i时知识所拥有的期望值,通过求和式子可以达到对知识期望进行归一化的目的。
[0024]
作为优选,知识全局注意力机制中,通过公式(8)、(9)、(10)来选择对于文本最匹配的知识:
[0025][0026]
simi=sim(op1,op2)=cos(vec(op1,op2))
ꢀꢀꢀ
(9)
[0027]
dis=|argmax(s)-idx(t)|
[0028]
s=sim(opj,input0[i])
ꢀꢀꢀ
(10)
[0029]
公式(8)包括两个步骤:
[0030]
1)首先计算e_set中的相似度信息和距离信息;相似度信息simi和距离信息是通过比较知识中的观点词以及输入文本中的观点词得来的;如公式(9)所示,simi是向量化后的op1和op2通过余弦相似度计算得来的,op1是出现在知识中的观点词,op2是出现在输入文本中的观点词;距离信息表示了观点词和查询词t的匹配程度;s_l是输入文本中单词的个数,在公式(10)中,首先遍历输入文本并得到观点词与文本的相似度数组s,然后查找相似度最大的观点词与查询词t所间隔的单词个数;
[0031]
2)在计算好相似度信息和位置信息后,考虑信息平衡问题;所要整合的知识它的知识期望值比较低,因为在公式(3)中,为了让e_set中拥有更多知识,设置了较低的期望阈值;因此在公式(8)中,再次利用由公式(7)计算得到的知识期望expectation,并将知识期望信息和步骤1)的计算结果做一个平衡计算;其中公式(8)中的超参数c就是平衡因子;通过公式(8-10),最终得到了知识的权值w,通过对知识按w进行排序即可选出对输入文本最有效的知识。
[0032]
作为优选,知识整合模块用于将知识查询模块最后输出的知识整合到输入文本中去;对于输入文本input0,最终整合的知识为k1和k2;整合进k1和k2能够帮助系统做出更合理的推断,然而直接把k1和k2拼接到输入文本中会曲解输入文本自身的含义。
[0033]
作为优选,词表示生成模块用于把知识增强的文本input1转化为知识增强的词表示;首先知识增强的文本input1会被转化为三种编码的和:序列编码、段编码和位置编码;然后编码的和会作为输入传给系统。
[0034]
本发明提出了自动生成情感知识的策略,并设计了一个通用的情感知识整合框架,帮助模型产出情感语义增强的、包含情感依赖信息的词向量。考虑到自动生成的情感知识可能存在噪音,对注入的情感知识进行了过滤,并辅以严格的知识过滤策略。
[0035]
本发明提出的自动生成情感知识策略,可以直接从文本数据中抽取出情感知识。考虑到人的情感具有复杂性与冲突性,本发明提出的知识期望,利用知识的统计信息来过滤潜在的冲突知识。避免这些冲突知识对模型造成误导。
[0036]
本发明提出的通用情感知识整合框架可以通过设计的过滤器为文本选择最匹配的知识,考虑到过滤策略可能无法过滤所有的噪音,为系统增加知识噪音优化目标,使得模型能够更好得生成包含“情感信息目标依赖”的词向量。
附图说明
[0037]
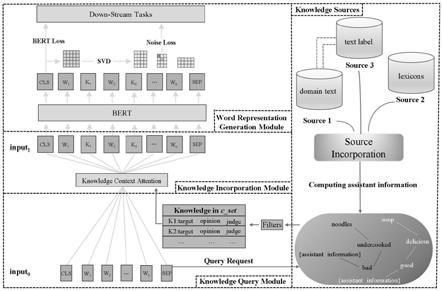
图1为实施例1中一种基于情感知识增强的词语分布式表示学习系统的架构示意图;
[0038]
图2为实施例1中目标领域文本分析示意图;
[0039]
图3为实施例1中约束变量g对于实验效果的影响图;
[0040]
图4为实施例1中约束变量λ对于实验效果的影响图。
具体实施方式
[0041]
为进一步了解本发明的内容,结合附图和实施例对本发明作详细描述。应当理解的是,实施例仅仅是对本发明进行解释而并非限定。
[0042]
实施例1
[0043]
如图1所示,本实施例1提供了一种基于情感知识增强的词语分布式表示学习系统,其包括情感知识整合框架和弱监督知识生成框架;情感知识整合框架包括知识查询模块,知识整合模块以及词表示生成模块;弱监督知识生成框架用于生成领域情感词典dsd,dsd整合了目标领域的无标签文本、领域独立的情感词典和目标领域文本的标签三部分的资源。
[0044]
图1中,英文翻译如下:
[0045]
input0原始的输入文本
[0046]
input1经过知识增强的文本
[0047]
knowledge context attention知识全局注意力
[0048]
bertbidirectional encoder representations from transformers,利用transformer结构的双向编码表征,自然语言处理中文本数据预训练的模型,可以用于词向量的生成
[0049]
domain text不带标签的领域文本,可以利用它抽取出观点词对
[0050]
text label领域文本的对应标签
[0051]
lexicons情感词典,可以为抽取出的观点词对分配情感倾向
[0052]
source incorporation资源整合,对领域文本,文本标签以及情感词典整合成领域情感词典。
[0053]
filters知识过滤器,在质询查询模块中对无效知识进行过滤
[0054]
bert loss bert模型的损失函数,包括mlm和nsp损失函数
[0055]
noise loss噪声损失函数,与bert loss一起构成了模型的损失函数
[0056]
svd奇异值分解算法
[0057]
[cls]bert中用于分类任务的特殊符号,代表全局上下文语义
[0058]
[sep]bert中用于句子分隔的符号,若输入句子只有一个,则代表句子的结束符号
[0059]
down-stream taks下游任务,在本框架中主要指情感分类和情绪侦测
[0060]
knowledge query module知识查询模块
[0061]
knowledge incorporation module知识整合模块
[0062]
word representation generation module词表示生成模块。
[0063]
知识查询模块
[0064]
给定一个评论句子s,知识查询模块的功能是帮助这个句子s找到最有可能帮助分析句子s的知识;为了达到这个目标,对于输入的句子,对其进行分词,然后将每个词作为一个查询目标,对领域情感词典dsd进行查询;对于查询得到的知识使用过滤器对其进行过滤,并引入知识期望和知识全局注意力机制,将过滤后的知识分为了三个状态:原始知识集合o_set,期望知识集合e_set以及候选知识集合c_set;通过知识查询请求得的知识集合即原始知识集合,它可以由(1)得到:
[0065]
o_set=knowledge_query(t,dsd)
ꢀꢀꢀ
(1)
[0066]
t即为查询词,knowledge_query是知识查询函数,o_set具体内容如(2)所示:
[0067][0068]
下标0和i均表示项数,在o_set中的知识是未经过处理的原始知识,其中opi是查询词t所匹配的观点知识,judgei是查询词t匹配观点词opi后被分配的情感极性,fri是查询词t与观点词opi在知识来源语料上出现的次数,conflicti是指在知识来源预料中知识是否存在着冲突的认知,p_num和n_num分别代表冲突认知中积极认知和消极认知的次数,lexicon_poi表示该知识在外部情感词典中的情感倾向值;为了更好得筛选有冲突认知的知识,引入知识期望过滤器,通过(3)来过滤潜在冲突的知识:
[0069]
e_set=e_filter(o_set,expectation_gate)
ꢀꢀꢀ
(3)
[0070]
在(3)中,e_filter是知识期望过滤函数,e_set是o_set的一个子集,expectation_gate是来过滤冲突知识的超参数;然而,知识期望无法判断查询到的知识是否真的对情感分析具有帮助,引入知识全局注意力机制,并通过(4)的注意力过滤器过滤e_set中的知识:
[0071]
c_set=k_attention(e_set,input0)
ꢀꢀꢀ
(4)
[0072]
在(4)中的c_set是一组三元组的集合,具体内容如(5)所示:
[0073]
c_set=[(t,op0,judge0),...,(t,ops,judges)]
ꢀꢀꢀ
(5)
[0074]
下标s表示共有s项知识,op是知识库中与查询词想匹配的观点词,judge为当查询词t与观点词op匹配时的情感极性;c_set中的知识将会整合到文本中去。
[0075]
知识期望
[0076]
不同用户对于同一对查询词以及观点词,可能会持有不同的看法。以查询词“电影”为例子,对于观点词“新”,通过归纳公开的电影评论数据集发现在9个查询到的用户评论中有5个用户喜欢新电影,4个用户不喜欢新电影。我们认为这样的知识是潜在冲突的知识,因为无论我们为“电影”,“新”分配怎么样的情感极性,都可能误导模型对新电影的认知。因此通过公式(6)、(7)来过滤潜在冲突的知识:
[0077]
em
op
=(p_num/fr-n_num/fr)
ꢀꢀꢀ
(6)
[0078][0079]
对于情感分类任务而言,p_num和n_num是在数据集中用户对查询词和观点词所分配的积极和消极标签的数量;对于情绪侦测任务而言,把情绪划分为两大类,分别为情感取向积极的情绪和情感取向消极的情绪,让这两大类标签下子标签的数量作为p_num和n_num
的值;对于冲突概率越大的知识,它的知识期望越小,因此通过设置expectation_gate就能够有效过滤潜在冲突的知识。在公式(7)中,expectation即为计算出的知识期望,em
op
为知识期望计算的中间结果,可以由公式(6)取得,emi表示当知识出现频率为i时知识所拥有的期望值,通过求和式子可以达到对知识期望进行归一化的目的。
[0080]
知识全局注意力机制
[0081]
为了避免整合与文本不相关的知识,我们设计了知识全局注意力机制,通过公式(8)、(9)、(10)来选择对于文本最匹配的知识:
[0082][0083]
simi=sim(op1,op2)=cos(vec(op1,op2))
ꢀꢀꢀ
(9)
[0084][0085]
公式(8)包括两个步骤:
[0086]
1)首先计算e_set中的相似度信息和距离信息;相似度信息simi和距离信息是通过比较知识中的观点词以及输入文本中的观点词得来的;如公式(9)所示,simi是向量化后的op1和op2通过余弦相似度计算得来的,op1是出现在知识中的观点词,op2是出现在输入文本中的观点词;距离信息表示了观点词和查询词t的匹配程度;s_l是输入文本中单词的个数,在公式(10)中,首先遍历输入文本并得到观点词与文本的相似度数组s,然后查找相似度最大的观点词与查询词t所间隔的单词个数;
[0087]
2)在计算好相似度信息和位置信息后,考虑信息平衡问题;所要整合的知识它的知识期望值比较低,因为在公式(3)中,为了让e_set中拥有更多知识,设置了较低的期望阈值;因此在公式(8)中,再次利用由公式(7)计算得到的知识期望expectation,并将知识期望信息和步骤1)的计算结果做一个平衡计算;其中公式(8)中的超参数c就是平衡因子;通过公式(8-10),最终得到了知识的权值w,通过对知识按w进行排序即可选出对输入文本最有效的知识。
[0088]
知识整合模块
[0089]
知识整合模块的功能是将知识查询模块最后输出的知识整合到输入文本中去;如图1所示,对于输入文本input0,最终整合的知识为k1和k2;整合进k1和k2能够帮助系统(bert模型)做出更合理的推断,然而直接把k1和k2拼接到输入文本中会曲解输入文本自身的含义。
[0090]
词表示生成模块
[0091]
词表示生成模块的功能是把知识增强的文本input1转化为知识增强的词表示;首先知识增强的文本input1会被转化为三种编码的和:序列编码、段编码和位置编码;然后编码的和会作为输入传给系统(bert模型)。这里的bert模型包含了12层,12个多头注意力块
以及最终会输出的词向量的维度为768维。和其他预训练语言模型相同,这里的bert模型也包含了两个阶段:预训练与微调。“预训练”所取得的词表示包含了通用的知识,“微调”阶段首先使用预训练训练出的词向量进行初始化,并且将词表示与挑选出的知识进行整合学习。词表示学习模块除了受本身的训练任务约束外,还受到知识噪音模块的约束。
[0092]
训练目标函数
[0093]
目标函数由三个部分组成:1)遮罩语言模型损失函数(mlm,masked language modeling),该损失函数可以帮助模型捕捉句子内各个词的语义。2)邻接句子预测损失函数(nsp,next sentence prediction),该损失函数可以帮助模型捕获句子间的关系。3)知识噪音约束损失函数(knc,knowledge noise constraints),该损失函数可以对整合好知识的文本进行降噪。其中1)和2)和bert模型是一致的,3)是我们设计的损失函数。
[0094]
如公式(11)所示,对于knc损失函数,通过对[cls]标签,即上文所提及的包含整个文本含义的标签,进行奇异值分解(svd,singularvalue decomposition)。
[0095]
[cls]=uσv
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0096]
在公式(11)中,u和σ分别是通过svd算法计算分解而得的特征向量与对应的特征值。在经过奇异值分解后,σ矩阵主对角线的元素会处于降序排列。在对主对角线元素进行提取后可以得到如(12)所示的特征值排列。
[0097]
svt=[σ1,σ2,σ3,...,σb]
ꢀꢀꢀ
(12)
[0098]
对于svt中的元素,通过公式(13)约束它的g个尾部特征值。
[0099][0100]
框架整体的目标函数如(14)所示,其中λ是平衡噪音约束损失函数bert自带的1)与2)的损失函数的超参数。
[0101]
l
total
=l
mlm
l
nsp
λ
·
l
knc
ꢀꢀꢀ
(14)
[0102]
弱监督知识生成框架
[0103]
对于每个领域下的文本数据,弱监督知识生成框架将会为其自动生成一个领域情感词典(dsd)。生成的情感词典整合了三部分的资源,分别为:
[0104]
a)目标领域的无标签文本
[0105]
b)领域独立的情感词典
[0106]
c)目标领域文本的标签
[0107]
其中a)和b)是必要资源,c)是可选资源,若目标领域的文本具有标签则可以产生更高质量的知识,若没有标签,也一样能生成知识。
[0108]
a)目标领域的无标签文本
[0109]
通过利用目标领域的文本,可以抽取出观点词对(将由观点词和查询词组合而成的词简称为观点词对,比如“电影”“新”,即为一个观点词对)。使用斯坦佛的句法依赖分析树以及对应的amod和nsubj规则来抽取出观点词对。
[0110]
如图2所示,对于文本“delicious soup,though the noodles were just like undercooked.”,利用句法依赖树可以发现amod规则可以抽取出的观点词对为:“delicious food”,nsubj可以抽取出的观点词对为“undercooked noodles”。
[0111]
b)领域独立的情感词典
[0112]
领域情感词典会为每个抽取出的观点词对分配合适的情感极性。以sentiwordnet3.0情感词典为例,观点词对中的观点词会首先查询情感词典并计算该观点词在情感词中的情感极性。对于一些观点词,可能在情感词典中查不到该词,那么对于包含这样观点词的观点词对,它们的情感极性分配将取决于抽取出这个观点词对的文本标签,若文本有标签,那么该文本标签将转化为观点词对的情感极性,若文本没有标签,这样的观点词对将被直接丢弃,以避免引入知识噪音。在整合好目标领域的文本以及情感词典信息后,能够产生特定领域的知识三元组集合(观点词对 情感倾向)。
[0113]
c)目标领域文本的标签
[0114]
目标领域的文本标签除了能给观点词对分配情感标签外,还能够帮助知识期望的计算。在整合资源a)和资源b)后,得到了三元组集合(观点词对 情感倾向),将三元组集合中的情感倾向定义为投票标签,对于整个领域的文本而言,同样的观点词对可能会有多个投票标签,比如在上文中提及的对于“新电影”这样的观点词对,就一共有9个投票标签,他们的情感极性有5个是积极的,4个是消极的。这些标签的数量就是公式(6)中的p_num和n_num。在这些投票标签的帮助下就能计算出知识的期望,并通过知识期望过滤掉潜在冲突的知识。
[0115]
数据集
[0116]
我们在情感分类以及情绪侦测数据集上验证我们模型的效果。各个数据集的细节入表1所示,对于每一个数据集,我们都为其生成了对应的情感知识。为了更好地评估模型在这些不同领域数据集上的效果,我们把数据集按照7:1:2的比例将其划分为了训练(train),验证(dev)和测试(test)集。
[0117]
表1多领域数据集信息表
[0118][0119]
其中s.c.表示任务类型为情感分类,e.d.表示任务类型为情绪侦测
[0120]
sst数据集:斯坦佛情感树库(sst,stanford sentiment treebank)所包含的数据集来源于电影评论。该数据集对应的任务是句子级别的情感分类任务,通过分析该数据集的原始数据可以得到一个句子情感倾向为积极的概率。其中sst-3按照该概率把原始数据转化为了三类情感极性标签,分别为:积极、中性、消极。sst-5按照概率把原始数据转化为了五类情感标签,分别为:非常积极,积极,中性,消极,非常消极。
[0121]
mr数据集:电影评论数据集(mr,movie review)将收集到的电影评论数据按照情感极性分为了积极和消极。该数据集对应的任务是句子级别的情感分类任务,是一个二分类任务。
[0122]
alm数据集:童话故事数据集(affect data,distributed by cecilia ovesdotter alm)。alm数据集来源于书本的童话故事。它包含了五类的情绪:恼怒(angry-disgust),害怕(fearful),开心(happy),伤心(sad),惊讶(surprised)。它是句子级别的情
绪侦测任务。
[0123]
aman数据集:博客数据集(emotion-annotated dataset,distributed by saima aman)。aman数据集包含了大量非正式的博客数据,该数据集对应的任务为情绪侦测任务。数据集包含了1290条带标签的数据,这些标签分别为开心(happy),伤心(sad),恶心(disgust),害怕(fearful),惊讶(surprised)。
[0124]
基线模型
[0125]
我们将我们的知识增强模型分别与大规模语料预训练模型、情感知识增强的预训练语言模型、未经过预训练的通用情感词表示学习模型进行对比。这三类模型以及我们的情感知识增强模型包含的内容以及介绍如下:
[0126]
大规模语料预训练模型:我们使用bert以及bert-pt作为大规模预训练语言模型的基线。其中bert是在维基百科还有书本语料上预训练而得来的模型,bert-pt是在五星级评论的亚马逊数据以及yelp数据集上预训练得来的模型。这两个模型在多种自然语言处理的任务上都取得较为出色的表现
[0127]
情感知识增强的预训练语言模型:我们使用sentibert和k-bert作为情感知识增强的预训练语言模型的基线。sentibert通过整合语义转折知识来促进多类情感分析任务的效果。而k-bert则是通过整合知识图谱来促进包括情感分析在内的知识驱动型任务。由于k-bert并不是专门针对英文文本设计的,所以我们改进了k-bert代码,并将我们自己生成的知识以不带约束的方式让k-bert进行整合。
[0128]
未经过预训练的通用情感词表示学习模型:我们使用sglove和emo2ve来作为未经过预训练的通用情感词表示学习模型基线。在预训练语言模型出现以前,他们都在情感分析上取得了非常有竞争力的表现。
[0129]
我们的情感知识增强模型:我们的情感知识增强的模型是skg-bert以及skg-bert-pt。skg-bert和skg-bert-pt是将我们自动生成的知识以及对应的知识约束策略应用到大规模预训练语言模型中的bert模型以及bert-pt模型上得到的模型。这两个模型能够进一步探究我们的框架和知识约束策略在预训练已经学得相关知识的情况下是否仍旧有效。
[0130]
实验设置
[0131]
三大类基线模型的实验数据,都是由我们复现得到的。为了保证实验对比的公平性,对三大基线模型中的大规模语料预训练模型和情感知识增强的预训练语言模型,我们保持他们的设置与base版的bert模型一致。对未经过预训练的通用情感词表示学习模型,我们将他们的词向量和glove拼接,使用一个逻辑回归分类器来进行情感分析的相关研究。
[0132]
我们的情感知识增强模型是skg-bert和skg-bert-pt,他们的预训练参数是直接从bert和bert-pt中转换得来。知识增强与融合的过程在微调的过程中进行。我们的实验是在amax计算服务器(一个tesla v100 gpu)上进行的。在搜寻最佳的参数时,我们使用了网格调参法。
[0133]
表2超参数搜寻表
[0134][0135]
choice表示在选项中的参数都会被测试到。
[0136]
超参数的设置细节如表2所示,在整合资源生成领域情感词典dsd时,我们设置了实体过滤器来过滤频率较高的单词,在知识查询模块中我们提出了知识期望,通过对知识的数据分析与观察,我们将知识期望的阈值设置为0.6,所有期望低于0.6的知识将被过滤。我们通过g和λ来对知识进行约束,其中g是在公式(13)中我们要约束的特征数,λ是在公式(14)中我们用来平衡损失函数的超参数。c是公式(8)中用于平衡距离信息和相似度信息的超参数,similarity gate(相似度阈值)是在知识全局注意力机制中使用的超参数,对于低于相似度阈值的知识将不会被整合到文本中去。我们使用网格调参来寻找最合适的超参数,对于情感分类任务,准确率是调参时确定最佳参数的参考标准,对于情绪侦测,宏观f1时调参时的参考标准。我们将数据集划分为了训练集、验证集和测试集,为了使我们的模型更加符合现实世界的情况,我们的知识生成策略只会为训练集生成知识,因为现实世界中,测试数据往往是未知的。
[0137]
实验结果
[0138]
情感分析
[0139]
在sst-3,sst5以及mr数据集上的评估效果如表3所示。尽管数据集来自不同的领域,相比于其他所有基线模型,skg-bert-pt仍旧取得了最好的效果。体现了外面情感知识增强的词表示的有效性。相比于未经情感知识增强的大规模语料预训练模型bert以及bert-pt,在经过我们提出的框架以及生成的自动知识的增强后,skg-bert以及skg-bert-pt分别对情感分析的效果做出了显著的改进。证明了我们所提出的通用框架、所生成的情感知识以及对应的知识约束策略的有效性。
[0140]
表3模型的情感分类准确率(%)
[0141][0142]
情绪侦测
[0143]
我们在alm数据集和aman数据集上进一步验证了skg-bert以及skg-bert-pt的效果,模型的表现如表4所示。我们使用宏观的f1值来评估模型,同时对每个模型我们也记录
了他们的宏观精确率以及召回率。表4呈现了我们模型的整体效果,总的来说,相比于其他所有基线模型,我们的情感知识增强模型skg-bert在alm数据集上取得了最好的表现,skg-bert-pt在aman数据集上取得了最好的表现。这进一步体现了我们的模型在更加细粒度的情绪侦测任务上的优越效果。此外,因为bert预训练的语料是书籍和维基百科,bert-pt预训练的语料是评论数据,而alm数据来源于童话故事书,这与bert预训练的语料可能存在重合,所以在alm是数据集上bert模型的表现会优于bert-pt模型,skg-bert模型的表现会优于skg-bert-pt模型。而aman数据集来源于博客,博客的文本大都为非正式的文本,这样形式的文本与bert-pt语料预训练的形式类似,所以在aman数据集上,bert-pt模型的表现优于bert模型,skg-bert-pt模型的表现优于skg-bert模型。
[0144]
表4.模型情绪侦测的精确率(p.,precision)、召回率(r.,recall)、宏观f1
[0145][0146]
实验效果分析
[0147]
为了更好地证明我们所提出的框架、生成的包含“情感目标依赖知识”以及知识约束的有效性,我们进行了进一步的实验探究。在不同的知识约束策略下,我们计算了alm数据集的宏观f1值。效果图如图3、图4所示。
[0148]
约束变量g和λ的影响
[0149]
变量g是我们在公式(13)中提及的约束的特征数量,λ是我们在公式(14)中所提及的损失函数平衡变量,这两个变量在知识约束的过程中起到了非常重要的作用。图3和图4对他们的作用进行了实验的分析。我们得到如下的发现:
[0150]
1)在没有知识约束的情况下(当g为0或者λ为0时,我们的模型不存在知识约束)我们的模型仍旧能够改进基线模型在alm数据集上的表现。证明了我们生成情感知识的质量是较高的。
[0151]
2)合适的g和λ可以帮助模型达到最好的表现。把g设置得过大将会影响下游任务,因为约束过多的特征将会改变文本本身的含义。把λ设置得过大也会降低模型的表现效果,因为过大的λ将会导致模型在优化时,不再考虑情绪侦测任务本身,而是过多关注于降低噪音。
[0152]
3)仅仅把我们的知识约束策略用在没有经过知识增强的模型上,也能够促进模型的表现。因为输入的文本本身可能就存在着噪音。
[0153]
实体过滤器的影响
[0154]
对于那些在预训练中频繁出现的实体词,他们的相关知识很有可能已经在预训练中学到了,把这些知识注入到模型中将不会带来显著的帮助。因此我们使用实体过滤器来过滤掉那些可能在预训练语料中频繁出现的单词,确保我们生成的知识的高质量。通过图3和图4,我们得到如下的发现:
[0155]
1)对于不同长度的实体过滤器,我们生成的知识的质量也不同。整体趋势是,实体过滤去限制的长度越长,我们生成的知识质量越高(在图3和图4中,当我们将g和λ分别设置为0时,可以得到该发现)。
[0156]
2)实体过滤器长度并非越长越好,合适的实体过滤器长度才能够更好地提高模型的效果。因为当实体过滤器长度增加时,生成的知识的总量也会减少。平衡好知识的质量与知识的总量的关系非常重要。
[0157]
通过我们的分析探究实验,我们可以得出结论:我们生成的知识,对应的知识约束策略以及我们提出的通用情感知识整合框架是有效的,它解决了我们在一开始提出的“情感信息的目标依赖”问题。
[0158]
以上示意性的对本发明及其实施方式进行了描述,该描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。所以,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。