1.本发明属于地理大数据分析与挖掘领域,特别是一种基于随机森林和众源地理信息的土地利用变化驱动因子挖掘方法。
背景技术:
2.城市土地利用格局作为城市发展的直观表现,受人类意识驱使,在自然、经济、文化和政策等多重因素的综合影响下,经历了地表上最为复杂的演化过程,对自然和生态系统产生了深远影响。我国作为世界最大的发展中国家,目前正处于高速城市化发展阶段,在人口增长与经济发展的双重压力下,土地空间资源被大幅度开发利用,城市土地利用经历着频繁而剧烈的变化。掌握城市空间结构演化规律,揭示土地利用变化微观驱动机制,可以为政府部门进行城市土地资源配置优化提供科学参考依据,对城市可持续发展具有重要意义。
3.土地利用变化的驱动因子挖掘是揭示土地利用变化发生机理、演化规则以及未来趋势模拟的基础,一直是土地利用研究的重要方向。国内外学者已经开展了大量的土地利用变化驱动力研究工作,早期研究主要利用实证分析的形式揭示特点区域内某一种土地利用类型宏观层面的驱动机制。例如,moran指出巴西亚马逊地区从1975年到1987年的森林退化主要受到当地政府对于畜牧场政策变化的影响,而不是人口增长因素。sneath通过对比1992年至1995年间中国、俄罗斯以及蒙古国的草地变化,发现现代化的畜牧方式是导致牧场退化的主要原因。pulido和bocco以发展中国家的农户为研究对象,证明了农民的主观意识和传统文化对当地的土地退化情况起到决定性作用。尽管这些定性分析对土地利用驱动力识别奠定了良好基础,但是难以评估不同类型的人类或自然因素对土地利用变化的影响程度。为此,后续研究中陆续采用了统计学方法,进行因子驱动力的量化研究,以多元驱动因子为自变量,土地利用变化为因变量构建线性方程模型,如相关性分析、逻辑回归、线性回归、主成分分析等方法。
4.考虑到我国城市发展正由外向型的空间扩展,逐渐转为土地功能更新与旧城改造等小尺度上的城市空间再开发这一现状,迫切需要进行土地利用变化微观驱动机制的研究。然而,现有研究中主要存在两点不足难以满足土地利用变化的微观驱动力研究:首先,现有研究大部分集中在大尺度的土地利用变化的宏观驱动因素探究,存在研究尺度过大,驱动因素分类不精等问题,难以支撑城市内部建设用地功能转化的规律发现与机制研究;其次,城市土地利用变化受到自然环境和社会经济等多重因素的交互影响,用地功能与结构在高强度的人类活动影响下更加复杂,传统的统计学模型多以线性方程为基础,简化了多元驱动因子与土地利用变化之间的关系模型,无法真实、全面的反映出二者之间复杂的、非线性映射关系。
5.随着web 2.0技术的发展,众源地理信息(crowedsourcing geographic information)这种由民众在日常生活中主动或被动产生的海量数据,成为专业地理信息数
据的重要补充。利用众源地理信息中反映出的人类活动和社会经济微观特征,地学研究的深度和广度得到进一步提升。兴趣点(point of interest,poi)数据是众源地理信息中应用最为广泛的一类,将poi标签蕴含的大量动态、精细的社会经济信息应用于城市土地利用研究中,为挖掘城市土地利用微观驱动机制提供了可能。但是在实际应用中,丰富的众源地理信息所带来的数据冗余度高和信息相关性强等问题,势必给核心驱动力的准确识别与筛选带来严重干扰。为此,有必要建立一种受变量间相关性影响较小的土地利用变化驱动力分析方法,既能构建驱动因子与土地利用变化之间的非线性模型,又能避免数据冗余的干扰,从多元驱动因子中精准识别中占主导地位和贡献能力强的驱动因子,更加深入、细化的挖掘影响城市土地利用变化的核心驱动因子。随机森林在特征筛选方面具有天然优势,根据变量对模型的贡献程度评估特征变量的重要性,作为分析土地利用变化的驱动力因子结果。随机森林可以根据变量对预测结果的贡献来衡量特征变量的重要性,将随机森林模型应用于构建土地利用类别与空间变量之间的关系,则可以通过计算变量重要性,分析出土地利用变化的核心驱动因子。随机森林模型提供了变量重要性评价方法,如根据gini不纯度计算变量重要性mdi(mean decrease in impurity)指标,该方法计算每个变量对分类树每个节点上观测值异质性的影响,从而比较变量的重要性,然而这种算法可能会导致变量重要性评价产生严重偏差,主要是因为mdi指标是根据模型训练数据计算的统计值,不能完全体现出变量对于模型预测的贡献。相关研究表明在样本数据分布不均的情况下,mdi指标在模型过拟合时,没有明显贡献的指标会被误判为重要因子。此外,基于gini不纯度的变量重要性评价更加倾向于赋予连续型变量高值,而低估离散型变量的重要性。为此,本研究基于随机森林模型与众源地理信息,引入变量置换检验方法评估特征变量的重要性,通过单一变量的随机置换,打破模型已经建立起来的变量与预测目标之间的关系,然后针对变量改变引发的模型误差变化进行指标计算,从而得出单一变量的重要性。该方法的优势在于对离散型和连续型变量的重要性评估不存在明显偏向,能够更加精准的对影响城市土地利用变化的驱动因子进行重要性量化评估和核心因子筛选。
技术实现要素:
6.本发明需要解决的技术问题是:为了揭示土地利用变化的微观驱动机制,提出了一种基于随机森林和众源地理信息的土地利用变化驱动因子挖掘方法,精准反映影响城市土地利用变化的特征因素重要性,实现土地利用变化核心驱动因素的筛选。
7.本发明解决其技术问题采用以下的技术方案:
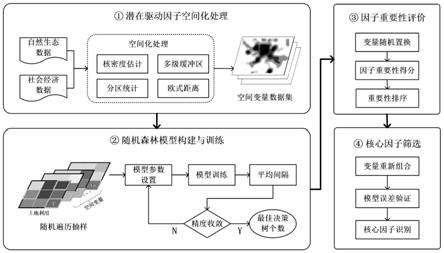
8.本发明提供的一种基于随机森林和众源地理信息的土地利用变化驱动因子挖掘方法,该方法是:首先利用以poi点为主的众源地理数据构建影响土地利用变化的多元潜在驱动因子数据集,并进行数据空间化处理;然后,以多元潜在驱动因素为特征变量,土地利用专题图的用地类型作为预测变量,构建随机森林分类器模型,并进行模型训练;接着,利用训练好的模型,进行单一变量的k次随机置换,从而计算变量的重要性得分,根据得分进行驱动因子重要性排序;最后,利用递归特征消除原理,筛选影响土地利用变化的核心驱动力。
9.本发明可以采用以下方法进行数据空间化处理:根据不同因子的数据类型特征,利用核密度估计、缓冲区创建、欧式距离计算、分区统计和坡度、坡向计算等多种方法,进行
数据的空间化处理,生成分辨率一致、连续面状型的空间变量集。
10.本发明可以采用以下方法消除空间变量集数据量纲的差异:利用arcmap10.2软件中的fuzzy工具将变量进行离差标准化处理,实现空间变量像元值的归一化,变量的数值范围映射到0至1之间。
11.本发明可以采用以下方法构建随机森林分类器模型:以多元潜在驱动因素为特征变量,土地利用专题图的用地类型作为预测变量,构建二者之间的映射关系。
12.本发明所述的构建随机森林分类器模型可以采用以下方法进行模型训练样本采集:
13.(1)将研究区两个不同年份的土地利用专题图导入arcmap软件,数据空间分类率为30m,土地利用类型分为水域、林地和草地、耕地、未利用地、居住用地、工业用地、商业用地、公共管理用地和混合用地共九类,类别代码依次为1至9的数字;
14.(2)利用arcmap软件中raster calculator进行不同年份土地利用类型的变化检测,代数表达式为con(
″
landuse1.tif
″
!=
″
landuse2.tif
″
,1,0),生成新的栅格数据集landuse_difference.tif,像元值为1代表土地利用类型发生变化的区域,像元值为0则代表未发生变化;
15.(3)针对土地利用发生变化的像元,根据像元的空间位置索引,采用随机遍历抽样法,对不同类型用地设置相应的遍历步长,进行全域搜索和采样,形成训练样本集d=[(x1,y1),,...,(xn,yn)]。
[0016]
本发明所述的构建随机森林分类器模型可以采用以下方法进行随机森林模型训练:将训练样本d输入随机森林模型进行模型训练,将最大特征数设置为潜在驱动因子个数n的平方根;通过决策树个数的迭代增长进行模型训练,模型训练效果的度量采用模型误差的平均间隔:
[0017][0018]
式中:mg
avg
代表所有样本的平均间隔,n代表样本个数,mg(xi,yi)代表单一样本的间隔。如果mg(xi,yi)大于零,这时正确类别占据最多票数,在投票表决下最终分类结果正确;相反则最终分类结果错误。
[0019]
本发明可以采用以下方法进行驱动因子的重要性得分计算与排序:对于样本d中每个特征变量j,随机置换该变量中的数值,生成新的、被破坏的训练样本计算新的样本间隔mgj,对每一个变量重复50次随机置换,以平均值作为变量重要性的最终结果:
[0020][0021]
式中:ij代表变量j的重要性得分,mg代表进行随机置换之前的模型平均间隔,k为随机置换次数,mg
k,j
代表对变量j进行第k次随机置换之后的模型平均间隔;
[0022]
利用这一步得到的特征因子重要性得分,按照降序将特征变量进行排序,即为土地利用变化的驱动因素重要性排序。
[0023]
本发明可以采用以下方法进行核心驱动力筛选:利用递归特征消除原理,根据驱动因子的重要性排序,从最为重要的驱动因子开始,每次添加一个因子,形成新的特征子集,输入到随机森林模型中,利用交叉验证方法训练模型并得到新的模型分类精度;重复上
述步骤,直至特征子集中包含所有驱动因子。
[0024]
所述的核心驱动力筛选方法可以采用以下方法进行核心驱动力数目确定:绘制模型分类精度随特征变量数目减少而变化曲线,寻找曲线中分类精度趋于收敛对应的点,则为核心驱动因子的数目。
[0025]
本发明提供的上述基于随机森林和众源地理信息的土地利用变化驱动因子挖掘方法,其用于精准评估和筛选对影响城市土地利用变化的微观驱动因素。
[0026]
本发明与现有技术相比具有以下主要的技术效果:
[0027]
(1)针对现有土地利用变化驱动力研究中存在研究尺度过大和驱动因素分类不精的问题,本发明发现引入蕴含丰富社会经济信息的众源地理数据,通过空间统计学方法,将抽象的城市发展驱动机制转化为二维空间上的量化特征表达,从数据形式上实现驱动因子与土地利用状态的完全统一,不仅解决了多源驱动因素与土地利用变化空间尺度不一致的问题,而且大大提升了土地利用驱动力分析的精细化程度,为揭示城市演化的微观驱动机制奠定了良好的数据基础。
[0028]
(2)考虑到传统统计学模型过于简化多元驱动因子与土地利用变化的复杂关系,难以真实反映微观驱动机制,本发明进行土地利用微观驱动因子挖掘时设计了基于随机森林的土地利用变化驱动因子重要性评估方法,该方法通过单一变量的随机置换,进行随机森林模型的重建与变化检验,独立考察每个驱动因子对模型预测能力的影响程度,从而有效避免了多元因子之间信息冗余对识别核心驱动因子的不利影响。相比随机森林模型中传统的变量重要性mdi指标,本发明的优势在于对离散型和连续型变量进行重要性评估时不存在明显偏向,能够更加精准的筛选出核心驱动因素。
附图说明
[0029]
图1是本发明的方法流程图。
[0030]
图2是基于众源地理信息的潜在驱动因子空间化结果图。
[0031]
图3是随机森林模型迭代训练结果。
[0032]
图4是驱动因子重要性排序图。
[0033]
图5是核心驱动因子筛选结果图。
具体实施方式
[0034]
本发明针对传统统计学模型过于简化多元驱动因子与土地利用变化的复杂关系,难以真实反映微观驱动机制的问题,提出了基于随机森林模型和众源地理信息的土地利用变化驱动因子重要性评估方法,利用蕴含丰富社会经济因素的众源地理信息构建地利用变化的多元潜在驱动因子数据集,设计了分类间隔指标来衡量重构模型的泛化误差,依据变量置换前后间隔序列的差异性来识别特征因子的重要程度。该方法独立考察每个驱动因子对模型预测能力的影响程度,从而有效避免了多元因子之间信息冗余对识别核心驱动因子的不利影响,而且解决了传统随机森林算法对微小变量扰动的响应不够灵敏的难题,提高了土地利用变化微观驱动因素识别的准确性。
[0035]
下面结合应用实施例及附图对本发明作进一步说明,但并不局限于下面所述内容。
[0036]
本发明提供了一种基于随机森林和众源地理信息的土地利用变化驱动因子挖掘方法,具体是:首先,利用以poi点数据(如教育、公共服务和交通类)为主的众源地理信息构建影响土地利用变化的多元潜在驱动因子数据集,并生成数据空间化处理;然后,以多元潜在驱动因素为特征变量,土地利用类型作为预测变量,构建随机森林分类器模型,并进行模型迭代训练;接着,利用训练好的模型,进行单一变量的k次随机置换,从而计算变量的重要性得分,进行驱动因子的重要性排序;最后,利用递归特征消除原理,筛选出影响土地利用变化的核心驱动力。本发明能够精准的对影响城市土地利用变化的驱动因素进行重要性量化评估和核心因素筛选,从而挖掘土地利用变化的微观演化机制。
[0037]
上述方法中,可以采用以下方法进行数据空间化处理:针对poi点数据、线状数据、面状数据和栅格数据所代表多元潜在驱动因子,利用核密度估计、缓冲区创建、欧式距离计算、分区统计和坡度、坡向计算空间化方法进行数据的空间化处理(不同驱动因子对应的空间化方法如表1所示),生成分辨率为30m、连续面状型的空间变量集。具体空间化方法的实现采用arcmap10.2软件中的kernel density、multiple ring buffer、euclidean allocation、zonal statistics、slope和aspect工具,将原始特征数据分别导入对应的工具中,统一设置输出为分辨率30m和tif格式的结果图,形成空间变量集,即为多元潜在驱动因子数据集。
[0038]
上述方法中,可以采用以下方法消除空间变量集数据量纲的差异:利用arcmap10.2软件中的fuzzy membership工具将变量进行离差标准化处理,将所有空间变量的tif格式数据依次导入该工具中,保持默认设置,导出结果图依然为tif格式,而像元值转化为0至1之间的浮点型小数,实现空间变量像元值的归一化,消除不同变量之间的量纲和数据级差异影响。
[0039]
上述方法中,可以采用以下方法构建随机森林分类器模型:以20个归一化之后的空间变量作为特征变量(自变量),土地利用专题图的9种用地类型作为预测变量(因变量),利用随机森林模型来构建二者之间的映射关系。
[0040]
上述方法中,可以采用以下方法进行模型训练样本采集:
[0041]
(1)将研究区两个不同年份的土地利用专题图导入arcmap软件,数据空间分类率为30m,土地利用类型分为水域、林地和草地、耕地、未利用地、居住用地、工业用地、商业用地、公共管理用地和混合用地共九类,类别代码依次为1至9的数字。
[0042]
(2)利用arcmap软件中raster calculator进行不同年份土地利用类型的变化检测,代数表达式为con("landuse1.tif"!="landuse2.tif",1,0),生成新的栅格数据集landuse_difference.tif,像元值为1代表土地利用类型发生变化的区域,像元值为0则代表未发生变化。
[0043]
(3)编写python语言程序,针对土地利用发生变化的像元,根据像元的空间位置索引,采用随机遍历抽样法,对不同类型用地设置相应的遍历步长,进行全域搜索和采样,形成训练样本集d=[(x1,y1),,...,(xn,yn)],式中:x1...xn代表随机森林模型中n个样本的自变量,y1...yn代表n个样本的因变量。
[0044]
上述方法中,可以采用以下方法进行随机森林模型迭代训练:编写python语言程序,将训练样本d输入随机森林模型进行模型训练,将最大特征数设置为潜在驱动因子个数n的平方根;通过决策树个数的迭代增长进行模型训练,模型训练效果的度量采用模型误差
的平均间隔:
[0045][0046]
式中:mg
avg
代表所有样本的平均间隔,n代表样本个数,mg(xi,yi)代表单一样本的间隔。如果mg(xi,yi)大于零,这时正确类别占据最多票数,在投票表决下最终分类结果正确;相反则最终分类结果错误。
[0047]
上述方法中,可以采用以下方法进行驱动因子的重要性得分计算与排序:编写python语言程序,对于样本d中每个特征变量j,随机置换该变量中的数值,生成新的、被破坏的训练样本计算新的样本间隔mgj,对每一个变量重复k次(本例中为50次)随机置换,以平均值作为变量重要性的最终结果:
[0048][0049]
式中:ij代表变量j的重要性得分,mg代表进行随机置换之前的模型平均间隔,k为随机置换次数,mg
k,j
代表对变量j进行第k次随机置换之后的模型平均间隔。
[0050]
利用这一步得到的特征因子重要性得分,按照降序将特征变量进行排序,即为土地利用变化的驱动因素重要性排序。
[0051]
上述方法中,可以采用以下方法进行核心驱动力筛选:利用递归特征消除原理,根据驱动因子的重要性排序,从最为重要的驱动因子开始,每次添加一个因子,形成新的特征子集,输入到随机森林模型中,利用交叉验证方法训练模型并得到新的模型分类精度;重复上述步骤,直至特征子集中包含所有驱动因子。
[0052]
上述方法中,可以采用以下方法进行核心驱动力数目确定:绘制模型分类精度随特征变量数目减少而变化曲线,寻找该曲线中分类精度趋于收敛对应的点,则为核心驱动因子的数目。
[0053]
本发明提供的上述基于随机森林和众源地理信息的土地利用变化驱动因子挖掘方法,用于揭示城市演化的微观驱动机制。
[0054]
应用案例:
[0055]
本案例以武汉市中心区域作为研究区域,该区域面积2724.228平方千米,占武汉市总面积的31.79%,是城市化程度最高的区域。以该区域2015年-2020年土地利用变化的驱动力分析为例,结合附图与附表对本发明作进一步的说明。
[0056]
具体处理步骤(图1)如下:
[0057]
步骤1,从社会经济与自然生态量两个角度出发,基于众源地理信息构建影响土地利用变化的多元潜在驱动因子数据集,并进行数据空间化处理,具体包括:
[0058]
(1)选择影响城市土地利用变化的因素主要包括自然生态与社会经济两大类共计20个因子,其中自然生态因子包括高程、坡度和坡向3种地形因子,水土保持功能、土壤有机质和水系3种生态因子;社会经济因子来源于poi等众源地理信息,包括人口、经济、教育、公共服务和交通类共14种(表1)。
[0059]
(2)获取研究区域内代表所有自然生态与社会经济因子的栅格(tif格式)或矢量数据(shapefile格式),依次导入专业地理信息数据处理与分析软件arcmap10.2中,使用工具箱中的project功能,对多种来源的数据进行坐标投影转化,保持数据的坐标投影一致,
为:wgs_1984_utm_zone_49n;再使用clip功能,以研究区边界为剪裁范围,将所有数据裁剪为统一形状。
[0060]
(3)对不同类型的因子采取不同的空间化处理方式,包括核密度估计、缓冲区创建、欧式距离计算和分区统计四种方法,分别利用arcmap10.2软件中的kernel density,multiple ring buffer,euclidean distance和zonal statistic工具实现,20种因子对应的空间化处理方法详见表1。处理完成后将生成分辨率为30m,像元数为3366990(2090*1611),数据格式为tif类型的空间变量数据集(图2)。
[0061]
(4)第一步,为了消除不同因子之间数据量纲的差异,利用arcmap10.2软件中的fuzzy工具将变量进行离差标准化处理,实现空间变量像元值的归一化,变量的数值范围映射到0至1之间。
[0062]
第二步,以多元潜在驱动因素为特征变量,土地利用专题图的用地类型作为预测变量,构建随机森林分类器模型,并进行模型训练,具体包括:
[0063]
(1)将武汉市中心区域2015和2020年土地利用专题图导入arcmap软件,数据空间分类率为30m,土地利用类型分为水域、林地和草地、耕地、未利用地、居住用地、工业用地、商业用地、公共管理用地和混合用地共九类,类别代码依次为1至9的数字。
[0064]
(2)利用arcmap软件中raster calculator进行2015年到2020年土地利用类型的变化检测,代数表达式为con(
″
landuse2015.tif
″
!=
″
landuse2020.tif
″
,1,0),生成新的栅格数据集landuse_difference.tif,像元值为1代表2015年至2020年期间土地利用类型发生变化,像元值为0代表未发生变化。将像元值为1的像元挑选出来,即为2015年至2020年期间土地利用类型发生变化的区域,共计823636个像元。
[0065]
(3)针对土地利用发生变化的823636个像元,根据像元的空间位置索引,采用随机遍历抽样法,对不同类型用地设置相应的遍历步长,进行全域搜索和采样,以20个潜在驱动因素为特征变量,2020年用地类型作为预测变量,形成训练样本集d=[(x1,y1),,...,(xn,yn)],其中水域样本5717个、林地和草地样本3283个、耕地样本10583个、未利用地样本6509个、居住用地样本6852个、工业用地样本6791个、商业用地样本4985个、公共管理用地样本2416个和混合用地样本2570个。
[0066]
具体实现采用代码如下:
[0067]
[0068]
[0069]
[0070]
[0071][0072]
(4)将训练样本d输入随机森林模型进行模型训练,将最大特征数设置为潜在驱动因子个数n的平方根,本案例中采用20个驱动因子,则最大特征数为通过决策树个数的
迭代增长进行模型训练,分析模型训练效果采用模型误差的平均间隔:
[0073][0074]
式中:mg
avg
代表所有样本的平均间隔,n代表样本个数,mg(xi,yi)代表单一样本的间隔。如果mg(xi,yi)大于零,这时正确类别占据最多票数,在投票表决下最终分类结果正确;相反则最终分类结果错误。结果显示,决策树个数为60时,模型的平均间隔趋于稳定(图3)。具体实现采用代码如下所示:
[0075]
[0076]
[0077][0078]
第三步,进行变量的重要性评价,对于样本d中每个特征变量j,随机置换该变量中的数值,生成新的、被破坏的训练样本计算新的样本间隔mgj,考虑到随机置换的不稳定性,对每一个变量重复50次随机置换,以平均值作为变量重要性的最终结果:
[0079][0080]
式中:ij代表变量j的重要性得分,mg代表进行随机置换之前的模型平均间隔,k为随机置换次数,mg
k,j
代表对变量j进行第k次随机置换之后的模型平均间隔。
[0081]
利用这一步得到的特征因子重要性得分,按照降序将特征变量进行排序,即为土地利用变化驱动力排序(图4),本案例中20个驱动因子的重要性从高到低排序为:人口、k12学校、工业设施、文化休闲场馆、公园绿地、公交站、高等院校、体育场馆、医院、水系、住宅价格、地铁站、水土保持、商业设施、主要干道、高程、土壤有机质、长途车站、坡度和坡向。具体实现代码如下:
[0082]
[0083]
[0084][0085]
第四步,利用递归特征消除原理,进行核心驱动力筛选,根据驱动因子的重要性排序,从最为重要的驱动因子开始,每次添加一个因子,形成新的特征子集,输入到随机森林模型中,利用交叉验证方法训练模型并得到新的模型分类精度;重复上述步骤,直至特征子集中包含所有驱动因子;绘制模型分类精度随特征变量数目减少而变化的曲线,寻找曲线中分类精度趋于收敛对应的点位于第15个因子处(图5),此后模型的分类精度基本保持不变,则筛选出的15个核心驱动因子为:人口、k12学校、工业设施、文化休闲场馆、公园绿地、公交站、高等院校、体育场馆、医院、水系、住宅价格、地铁站、水土保持、商业设施和主要干道。
[0086]
表1土地利用潜在驱动因子分类与空间化处理方式
[0087]
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
