1.本发明涉及自然语言处理、深度学习、文本情感分析、对话生成领域,特别涉及一种融合主题预测和情感推理的共情对话生成方法。
背景技术:
2.人机对话的场景充斥在人们生活中,作为人工智能领域的核心领域,人机对话一直以来受到各界的广泛关注。一直以来人们都希望创造出能够与人流畅交流的机器人,早在1950年,图灵就明确提出了判断机器人是否智能的标准,即图灵测试。受到图灵测试的启发,人机对话引起了学者们的关注,随着深度学习技术的发展,人工智能迎来了第三次浪潮,网上海量的对话数据,为基于深度学习的人机对话技术提供了数据驱动与支撑,但是早期的对话生成系统生成的对话是不具有任何情感的,然而用户一般希望机器产生的回复能够与自己产生情感共鸣,没有情感的回复,很容易使用户失去聊天的兴趣,所以提出一种情感对话生成方法是有必要的。
3.早期情感对话模型的研究大多数集中于指定情感的单轮次对话生成,这类模型不能根据用户的输入语句判断出用户此时此刻的情感,而是通过在模型编码器或者解码器额外输入一个指定的情感,用于生成带有情感的回复,而且每次回复的生成是单轮次的,也就是说模型只能与用户进行一个轮次的对话。但是在现实生活中,人们希望与机器的对话能够持续很多轮次,而且在生成带有情感的回复时,也不需要指定情感,而是通过用户的输入和对话历史信息来分析用户的情感,并预测用户希望得到什么样的情感回复,这种生成回复的方式称为共情对话生成。
4.共情对话是从情感对话任务中衍生而来的,根据对话历史,来理解用户当前的感受,产生相应的回复,从而与用户产生情感上的共鸣。共情对话生成的主要挑战集中于对话主题的预测和情感的识别。在对话主题预测方面,以往的研究仅仅根据对话历史进行预测对话主题,只考虑了每个话题的个体语义,忽略了其特定的对话语境,这可能会导致不准确的话题表征和影响反应连贯;在情感识别方面,目前的方法主要集中在学习一个预测情绪标签的模型,却被忽略了情感背后原因的检测,这将会导致模型只能利用表面的情感信息。
技术实现要素:
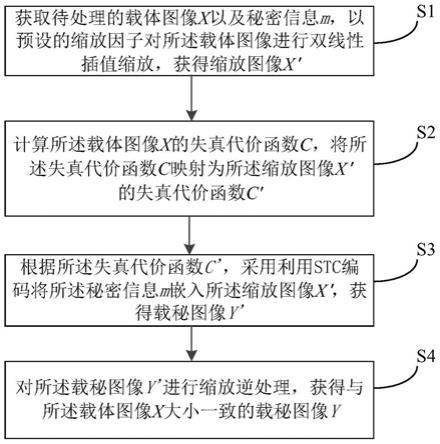
5.为解决以上现有技术问题,本发明提出了一种融合主题预测和情感推理的共情对话生成方法,包括构建融合主题预测和情感推理的共情对话生成模型,该模型包括主题预测模块、情感推理模块以及对话生成模块,利用主题预测模块进行受上下文控制的对话主题预测,得到预测的主题;使用情感推理模块预测上下文情感标签和进行情感原因词识别,得到相应的情感信息;将获得主题信息和情感信息输入到对话生成模块中,得到与用户情感共鸣的共情回复,对融合主题预测和情感推理的共情对话生成模型的训练过程具体包括以下步骤:
6.s1:获取共情对话数据,对数据进行处理,生成训练数据集、验证数据集和测试数
据集;
7.s2:采用word embedding将共情对话数据集中的输入序列转换成相应的词向量表示;
8.s3:将经过word embedding得到的向量表示分别输入主题预测和情感推理模块,进行对话主题预测和情感推理;
9.s4:利用可训练的emotion embedding作为每个上下文标签ε的表示;
10.s5:将emotion embedding与word embedding和position embedding相加输入对话生成模块获取主题词和情感原因词;
11.s6:最大化条件概率p(um|u
<m
)生成最终回复,根据生成的结果计算模型的损失函数,并将测试样本中的数据输入到模型中,不断调整模型的参数,当模型的损失函数值小于设定阈值时,完成模型的训练。
12.进一步的,主题预测模块包括层次上下文编码、上下文相关主题表示和上下文控制主题预测,层次上下文编码用于获取话语的上下文表示;上下文相关主题表示用于根据话语的上下文表示获取话语的主题表示;上下文控制主题预测用于根据话语的主题表示对主题进行预测。
13.进一步的,层次上下文编码由两层bigru网络组成,层次上下文编码的第一层bigru能够对上下文中每个话语进行编码,得到话语级表示进行编码,得到话语级表示是话语ui的话语级表示的最后一个隐藏层向量,表示为:
[0014][0015]
层次上下文编码的第二层bigru能够对话第一层编码得到的话语级表示进行编码得到上下文级表示,包括:
[0016][0017]
其中,u
<m
表示对话上下文,ni为话语ui词的数量,m为整个对话过程中话语数量;为w
n,i
隐藏向量,是w
n,i
的初始词嵌入,w
n,i
表示话语ui的第n个词;bigru()表示bigru网络;是ui的上下文级表示。
[0018]
进一步的,上下文相关主题表示由主题词提取、主题内注意力、上下文主题注意力、话语内主题表示和话语间主题表示构成,其中:
[0019]
进行主题词抽取时,利用lda主题模型从上下文u
<m
中抽取出一个唯一的主题词序列ts={t1,
…
tk},并从ts中为每个话语ui挑选主题词得到上下文主题为t
<m
={t1,
…
,t
m-1
};
[0020]
主题内注意力为利用注意力机制计算每个话语中不同主题词相互重要权重,并利用权重更新每个主题词的表示,该过程表示为:
[0021][0022][0023]
上下文主题注意力是利用注意力机制将话语表示融入主题表示过程,该过程表示
为:
[0024][0025][0026]
话语内主题表示利用softmax函数计算出主题词与其相关话语之间的相关性,得到综合的话语内主题表示,包括:
[0027][0028][0029]
话语间主题表示用gru网络对话语内主题表示进行编码,捕捉不同话语间的关系,得到话语间主题表示,包括:
[0030][0031]
其中,α
j,l
表示相互重要权重,f()表示点乘操作,分别为主题词t
j,i
、t
l,i
的词嵌入表示,g
relu
()为单层全连接网络,relu是激活函数,z
j,i
为词级主题表示,glinear为单层线性全连接网络,ki为每个话语挑选的主题词数量;β
j,n
为z
j,i
和之间的相关性,为主题词t
j,i
的上下文相关主题表示,ni为话语ui词的数量;ξ
j,i
是主题t
j,i
与ui之间的相关性,是话语ui综合的话语内主题表示;是话语ui整合后的具有话语感知的主题表示。
[0032]
进一步的,进行上下文控制主题预测时,利用h层前馈网络进行预测出对话主题转移到回复中的转移概率,并从中选择转移概率最大的l个主题词,包括以下过程:
[0033][0034][0035][0036][0037]
其中,concat[;]表示连接操作,w1,
…
,wh、b1,
…
,bh表示模型中可训练的参数,是h层前馈网络的输出,k表示上下文相关的主题词个数,表示主题词的转移权重,表示主题词tk转移到回复um中的概率,t表示从ts={t1,
…
tk}中挑选的在前l的主题词,top
l
()表示选择最大的l个参数,表示预测的转移主题的词嵌入表示,g
t
是主题门序列,表示选择作为预测转移主题词的概率。
[0038]
进一步的,情感推理模块由transformer模型构成,该模型根据对话上下文预测出
上下文情感标签ε,包括:
[0039]
x={x0,x1,
…
,xn}
[0040][0041][0042]
其中,x是给定对话上下文m={u1,
…
,u
m-1
}连接起来后的输入序列,x0表示序列的开始符号,v为x的词表示,we和be表示模型中可训练参数;p(ε|x)表示根据对话上下文预测情感标签ε的概率。
[0043]
进一步的,进行情感原因词识别包括:
[0044][0045][0046][0047][0048]
其中,表示第i个词与情感原因相关的概率,ci为第i个词情感原因相关的标签,wc和bc为可训练参数,c表示从输入中选择的时的前k个主题词,表示从输入中选择的时的第k个主题词;是一个[0,1]中取值连续的软门,表示在输入中选择作为情感原因词的概率;表示第一个特殊字符[cls]的向量表示,ni为话语ui词的数量。
[0049]
进一步的,对话生成模块中包括编码器、解码器,将词向量表示ew、对话上下文的情感标签嵌入e
ε
和词向量的位置嵌入表示e
p
相加输入到对话生成模块的编码器中进行编码得到上下文化的词表示;在解码器中利用一个交叉注意力机制对上下文化的词表示进行关注,在交叉注意力层上添加一个主题门注意力和情感原因词门注意力,对主题预测模块得到主题门序列进行关注,动态选择预测的转移主题序列中出现在回复中主题词,对情感推理模块得到的门序列进行关注,动态控制输入中情感原因相关词的选择,包括:
[0050][0051][0052]
其中,的值表示选择预测主题序列中的作为出现在回复中的主题词的概率;的值表示在输入中选择作为情感原因词的概率,q
l
表示问询向量,为多头注意力层的输出;表示的嵌入表示,表示的嵌入表示,表示在输入中选择作为情感原因词的概率,
⊙
表示点积操作,表示解码器第l块注意力层第i个位置的主题门注意力权
重,表示解码器第l块注意力层第i个位置的情感原因词门注意力权重。
[0053]
进一步的,通过最大化在给定对话上下文u
<m
的条件下,生成回复um的概率p(um|u
<m
)得到共情回复,表示为:
[0054][0055]
其中,p(w
n,m
|w
<n,m
,u
《m
,t,c,ε)表示在n时刻前生成词为w
<n,m
、对话上下文为u
《m
、预测的转移主题词序列为t、情感原因词序列为c、对话上下文情感标签为ε的条件下,n时刻生成词w
n,m
的概率;w
n,m
表示回复um中n时刻生成词,w
<n,m
表示回复um中n时刻之前生成词,u
《m
表示对话上下文,t表示从ts={t1,
…
tk}中挑选的在前l的主题词,表示主题词的转移权重,c表示从输入中选择的时的前k个主题词,ε表示对话上下文情感标签。
[0056]
进一步的,模型的损失函数由主题预测模块、情感推理模块和对话生成模块三者损失函数之和,其中:
[0057]
主题预测模块损失函数为:
[0058][0059][0060]
情感推理模块的损失函数为:
[0061][0062][0063]
对话生成模块的损失函数为:
[0064][0065]
其中,l
tran
表示转移主题词预测损失,k表示上下文相关的主题词个数;l
tran
(k)表示焦点损失函数,ψ∈[0,1]是一个权重控制因子,γ≥02是调节因子,表示主题词转移权重;τk表示预测的转移主题词是否出现在回复中,当τk=1表示预测的转移主题词出现在回复um中,当τk=0表示预测的转移主题词不出现在回复um中;l
ε
表示上下文情感标签预测损失,表示上下文情感标签的预测概率,表示第i个词与情感原因相关的概率,ni为话语ui词的数量,lc表示情感原因词检测损失;lg表示解码器的生成损失,nm表示生成回复中的词的个数;p(w
n,m
|w
<n,m
,u
《m
,t,c,ε)表示在n时刻前生成词为w
<n,m
、对话上下文为u
《m
、预测的转移主题词序列为t、情感原因词序列为c、对话上下文情感标签为ε的条件下,n时刻生成词w
n,m
的概率;u
<m
表示对话上下文,表示主题词的转移权重,c表示从
输入中选择的时的前k个主题词,ε表示对话上下文情感标签。
[0066]
本发明很好的融合了主题信息和情感信息,有效地利用上下文控制主题的预测,准确地预测出上下文情感标签和识别情感原因相关的词,从而提升了模型生成的回复在情感上的共情性、主题上的一致性和内容上的相关性。
附图说明
[0067]
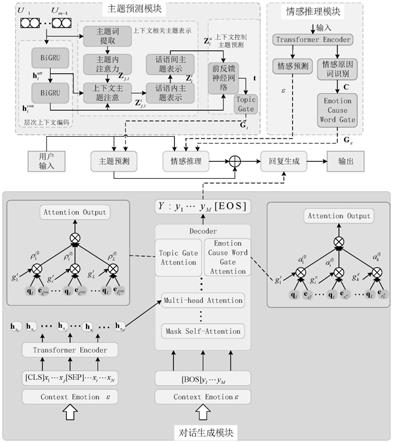
图1为本发明的融合主题预测和情感推理的共情对话生成模型结构示意图。
具体实施方式
[0068]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0069]
本发明提供一种基于融合主题预测和情感推理的共情对话生成方法,构建融合主题预测和情感推理的共情对话生成模型,该模型包括主题预测模块、情感推理模块以及对话生成模块,利用主题预测模块进行受上下文控制的对话主题预测,得到预测的主题;使用情感推理模块预测上下文情感标签和进行情感原因词识别,得到相应的情感信息;将获得主题信息和情感信息输入到对话生成模块中,得到与用户情感共鸣的共情回复,对融合主题预测和情感推理的共情对话生成模型的训练过程具体包括以下步骤:
[0070]
s1:获取共情对话数据,对数据进行处理,生成训练数据集、验证数据集和测试数据集;
[0071]
s2:采用word embedding将共情对话数据集中的输入序列转换成相应的词向量表示;
[0072]
s3:将经过word embedding得到的向量表示分别输入主题预测和情感推理模块,进行对话主题预测和情感推理;
[0073]
s4:利用可训练的emotion embedding作为每个上下文标签ε的表示;
[0074]
s5:将emotion embedding与word embedding和position embedding相加输入对话生成模块获取主题词和情感原因词;
[0075]
s6:最大化条件概率p(um|u
<m
)生成最终回复,根据生成的结果计算模型的损失函数,并将测试样本中的数据输入到模型中,不断调整模型的参数,当模型的损失函数值小于设定阈值时,完成模型的训练。
[0076]
如图1,本实施例中融合主题预测和情感推理的共情对话生成模型包括主题预测模块、情感推理模块以及对话生成模块,用户将数据分别输入主题预测模块和情感推理模块,主题推理模块和情感推理模块得到的输出进行相加后输入对话生成模块生成回复作为模型的输出,其中主题预测模块结合对话上下文进行受上下文控制的对话主题预测,由层次上下文编码、上下文相关主题表示和上下文控制主题预测三个部分构成,如图1,主题预测模块包括以下操作:
[0077]
第一步,首先,对话上下文中每个话语经过第一层bigru进
行编码,得到话语级表示行编码,得到话语级表示是ui话语级表示的最后一个隐藏层向量,然后,将第一层编码得到的话语级表示通过第二层bigru进行编码,最后,得到上下文级表示,公式可表示如下:
[0078][0079][0080]
其中,为w
n,i
隐藏向量,是w
n,i
的初始词嵌入,w
n,i
表示话语ui的第n个词,是ui的上下文级表示。
[0081]
第二步,利用lda主题模型从上下文u
<m
中抽取出一个唯一的主题词序列ts={t1,
…
tk},并从ts中为每个话语ui挑选主题词得到上下文主题为t
<m
={t1,
…
,t
m-1
},再利用主题内注意力计算每个话语中不同主题词相互重要权重,根据权重更新每个主题词的表示,计算公式如下:
[0082][0083][0084]
其中,和为主题词t
j,i
与t
l,i
的词嵌入表示,α
j,l
相互重要权重,g
relu
是单层全连接网络,relu是激活函数,z
j,i
为词级主题表示,glinear是单层线性全连接网络。
[0085]
第三步,利用下文主题注意力计算z
j,i
与之间的相关性β
j,n
,并根据β
j,n
更新主题表示,得到上下文相关的主题表示,计算公式如下:
[0086][0087][0088]
其中,β
j,n
是z
j,i
和之间的相关性,是t
j,i
的上下文相关主题表示。
[0089]
第四步,利用softmax函数计算出主题词与其相关话语之间的相关性ξ
j,i
,并根据ξ
ji
进行话语内主题表示,计算公式如下:
[0090][0091][0092]
其中,ξ
j,i
是主题t
j,i
与ui之间的相关性,是ui的话语内主题表示。
[0093]
第五步,利用gru网络对话语内主题表示进行编码,捕捉不同话语间的关系,得到话语间主题表示计算公式如下:
[0094][0095]
其中,是ui整合后的具有话语感知的主题表示。
[0096]
第六步,将第五步得到的话语间的主题表示和第一步得到的上下文级表示通过一
个h层的前馈神经网络预测主题词tk转移到回复um中的概率,得到转移权重并从中挑选出转移概率在前l的主题词作为预测的主题词序列t,最后,由t得到主题门序列g
t
,主题预测过程的计算公式如下:
[0097][0098][0099][0100][0101]
其中,concat[;]表示连接操作,w1,
…
,wh和b1,
…
,bh表示可训练的参数,是h层前馈网络的输出,k表示上下文相关的主题词个数,表示主题词的转移权重,表示主题词tk转移到回复um中的概率,t表示从ts={t1,
…
tk}中挑选的在前l的主题词,表示预测的转移主题的词嵌入表示,g
t
是主题门序列,表示选择作为预测转移主题词的概率。
[0102]
情感推理模块包含情感预测和情感原因词识别,分别进行上下文情感标签预测和识别情感原因相关的词,如图1所示,该模块的操作包括:
[0103]
将对话上下文m={u1,
…
,u
m-1
}连接起来得到输入序列x={x0,x1,
…
,xn},再将x进行词表示后得到并利用一个transformer模型预测上下文情感标签ε,接着进行情感原因词识别,情感原因词能够为对话生成提供更深层次的情感信息,如果第i个词与情感原因相关,其情感原因标签为1,否则为0,给定x={x0,x1,
…
,xn},得到每个词与情感原因相关的概率,从输入中选择时的前k个主题词作为情感原因词,根据情感原因标签概率得到情感原因词门序列计算公式如下:
[0104][0105][0106][0107][0108]
其中,x0表示序列的开始符号,v是x的词表示,we和be表示可训练参数,表示第i个词与情感原因相关的概率,ci为第i个词情感原因相关的标签,wc和bc为可训练参数,c表示从输入中选择的时的前k个主题词,是一个[0,1]中取值连续的软
门,表示在输入中选择作为情感原因词的概率。
[0109]
对话生成模块,即利用主题预测模块得到的主题信息和情感推理模块得到的情感信息生成主题相关、情感共鸣的回复,如图1所示,该模块操作包括:
[0110]
将词嵌入ew、情感嵌入e
ε
和位置嵌入e
p
相加输入到对话生成模块的编码器和解码器中进行编码,输入序列x={x0,x1,
…
,xn}经过编码器进行编码后得到上下文化的词表示
[0111]
在解码器中利用一个交叉注意力机制对h进行关注,再在交叉注意力层上添加一个主题门注意力和情感原因词门注意力,对主题预测模块得到主题门序列进行关注,动态选择预测的转移主题序列中出现在回复中主题词,对情感推理模块得到的门进行关注,动态控制输入中情感原因相关词的选择,计算公式如下:
[0112][0113][0114]
其中,的值表示选择预测主题序列中的作为出现在回复中的主题词的概率,的值表示在输入中选择作为情感原因词的概率,q
l
表示问询向量,是多头注意力层的输出,表示的嵌入表示,表示的嵌入表示,最后,通过最大化得到共情回复。
[0115]
本发明在训练模型时采用的模型的损失函数是主题预测模块、情感推理模块和对话生成模块三者损失函数之和。主题预测模块损失函数为:
[0116][0117][0118]
其中,l
tran
是动态加权交叉熵损失,表示转移主题词预测损失,它能够解决训练样本不平衡的问题,l
tran
(k)表示焦点损失函数,ψ∈[0,1]是一个权重控制因子,γ≥02是调节因子。
[0119]
情感推理模块的损失函数为:
[0120][0121]
[0122]
其中,l
ε
表示上下文情感标签预测损失,lc表示情感原因词检测损失。
[0123]
对话生成模块的损失函数为:
[0124][0125]
其中,lg是一个负对数似然损失,表示解码器的生成损失,nm表示生成回复中的词的个数。
[0126]
模型总的损失函数为:
[0127]
l=l
ε
lc l
tran
lg。
[0128]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。