1.本发明涉及板带力学性能预测技术领域,特别是指一种板带力学性能预测准确性评估方法。
背景技术:
2.热轧板带力学性能预测是一种利用原料化学成分和生产过程工艺参数预测成品力学性能的技术,力学性能预测不仅能够帮助生产现场进行质量预警,还能够减少复杂且滞后的取样检验过程,大幅度减少取样检测量,缩短交货周期。
3.目前用于力学性能预测的大部分模型在实际应用中的效果不佳,主要原因是目前基于数据驱动的力学性能预测模型精度不稳定,特别是在某些特殊工况下,模型泛化能力比较差,导致较低的预测精度。此外,即使模型存在自学习能力,也需要一定的时间来适配,这就导致现有模型无法及时应对这种突变造成较大的预测误差,进而使钢厂面临质量异议风险。
4.在钢铁生产中,生产工况变动是时常发生的,只有预知了模型预测结果的准确性之后,才能在相关场景中得到充分应用。因此,就需要一种自适应的预测准确性评估模型来对生产工况的变动进行识别,进而对模型的预测准确性进行评估,对于新工况下的产品,如果不能够准确预测,需要提供准确性指标来指导现场取样。这样,对于生产现场而言,不仅能够完善大数据建模中特殊工况下的数据集,还能够为现场取样提供准确的指导,大幅降低质量异议的风险。这种力学性能预测准确性评估模型也将是钢铁企业有效实施智能制造理念的重要一步。
技术实现要素:
5.本发明实施例提供了一种板带力学性能预测准确性评估方法,能够为基于数据驱动的热轧板带力学性能预测提供一种力学性能预测结果准确性评估指标,从而为现场取样提供指导,大幅降低质量异议的风险。所述技术方案如下:
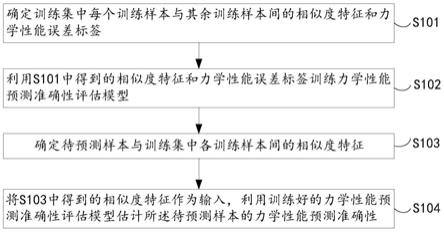
6.本发明实施例提供了一种板带力学性能预测准确性评估方法,该方法在已有力学性能预测模型的基础上实施,通过构建所述力学性能预测准确性评估模型实现对已有的力学性能预测模型预测结果的准确性评估,所述力学性能预测准确性评估方法包括:
7.s101,确定训练集中每个训练样本与其余训练样本间的相似度特征和力学性能误差标签;
8.s102,利用s101中得到的相似度特征和力学性能误差标签训练力学性能预测准确性评估模型;
9.s103,确定待预测样本与训练集中各训练样本间的相似度特征;
10.s104,将s103中得到的相似度特征作为输入,利用训练好的力学性能预测准确性评估模型估计所述待预测样本的力学性能预测准确性。
11.进一步地,所述确定训练集中每个训练样本与其余训练样本间的相似度特征和力
学性能误差标签包括:
12.a1,获取训练力学性能预测模型所用的训练样本,其中,各训练样本包括:特征变量、力学性能真实标签值和力学性能预测标签值;
13.a2,利用数据特征计算训练集中各训练样本与其余训练样本间的相似度,按照相似度值从大到小排序得到各训练样本与其余训练样本间的相似度向量;
14.a3,利用相似度向量计算各训练样本与其余训练样本间的相似度特征;
15.a4,计算各训练样本力学性能真实标签值与力学性能预测标签值之间的平均绝对误差,作为力学性能误差标签。
16.进一步地,所述特征变量包括:化学成分和工艺参数。
17.进一步地,所述利用数据特征计算训练集中各训练样本与其余训练样本间的相似度,按照相似度值从大到小排序得到各训练样本与其余训练样本间的相似度向量包括:
18.对训练集中的特征变量进行归一化处理;
19.在归一化基础上,采用相似性度量函数计算各训练样本与其余训练样本间的相似度;
20.对于每个训练样本,按照得到的相似度值从大到小排序,得到一个由相似度值构成的相似度向量,其形式表示为:
21.s=[s0,s1,...,s
k-2
]
[0022]
其中,si为相似度值,且si>s
i 1
;s为相似度向量;k为训练集包含的训练样本数。
[0023]
进一步地,所述利用相似度向量计算各训练样本与其余训练样本间的相似度特征包括:
[0024]
对于每一个训练样本,从其相似度向量的第一个元素开始,选取n组不同长度的子向量,每组子向量s
*
可表示为:
[0025]s*
=[s0,s1,...,sj]
[0026]
其中,j≤k-2;
[0027]
对于每个训练样本,计算各子向量中相似度值的算术平均数,作为该训练样本与训练集中其余训练样本间的n个相似度特征。
[0028]
进一步地,所述利用s101中得到的相似度特征和力学性能误差标签训练力学性能预测准确性评估模型包括:
[0029]
将s101中得到的相似度特征作为输入、力学性能误差标签作为输出,训练力学性能预测准确性评估模型。
[0030]
进一步地,所述确定待预测样本与训练集中各训练样本间的相似度特征包括:
[0031]
合并训练集和待预测样本的特征变量;
[0032]
对合并后的数据集中的特征变量进行归一化处理,在归一化基础上,计算待预测样本与训练集中各训练样本间的相似度特征。
[0033]
进一步地,所述将s103中得到的相似度特征作为输入,利用训练好的力学性能预测准确性评估模型估计所述待预测样本的力学性能预测准确性包括:
[0034]
将s103中得到的相似度特征作为输入,利用训练好的力学性能预测准确性评估模型输出所述待预测样本力学性能误差的估计值,作为针对该待预测样本力学性能预测的准确性评估指标。
[0035]
本发明实施例提供的技术方案带来的有益效果至少包括:
[0036]
本发明实施例中,确定训练集中每个训练样本与其余训练样本间的相似度特征和力学性能误差标签;利用得到的相似度特征和力学性能误差标签训练力学性能预测准确性评估模型;确定待预测样本与训练集中各训练样本间的相似度特征;将待预测样本与训练集中各训练样本间的相似度特征作为输入,利用训练好的力学性能预测准确性评估模型估计所述待预测样本的力学性能预测准确性。这样,能够为基于数据驱动的热轧板带力学性能预测提供一种力学性能预测结果准确性评估指标,从而为现场取样提供指导,大幅降低质量异议的风险。
附图说明
[0037]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0038]
图1为本发明实施例提供的板带力学性能预测准确性评估方法的流程示意图;
[0039]
图2为本发明实施例提供的板带力学性能预测准确性评估方法的详细流程示意图;
[0040]
图3为本发明实施例提供的板带力学性能预测的历史数据集中屈服强度预测误差与相似度特征之间的关系示意图。
具体实施方式
[0041]
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
[0042]
如图1和图2所示,本发明实施例提供了一种板带力学性能预测准确性评估方法,该方法在已有力学性能预测模型的基础上实施,通过构建所述力学性能预测准确性评估模型实现对已有的力学性能预测模型预测结果的准确性评估,所述力学性能预测准确性评估方法包括:
[0043]
s101,确定训练集中每个训练样本与其余训练样本间的相似度特征和力学性能误差标签,具体可以包括以下步骤:
[0044]
a1,获取训练力学性能预测模型所用的训练样本,其中,各训练样本需具有必要的特征变量、力学性能真实标签值和力学性能预测标签值(例如,各训练样本的屈服强度真实值和预测值);
[0045]
本实施例中,所述必要的特征变量包括:化学成分和工艺参数。
[0046]
需要说明的是:
[0047]
本实施例提供的所述板带力学性能预测准确性评估方法需要构建一个力学性能预测准确性评估模型(记为模型b),而构建模型b的目的是为了评估传统的力学性能预测模型(记为模型a),因此,模型b构建的初始数据集需要与模型a一致。
[0048]
a2,利用数据特征计算训练集中各训练样本与其余训练样本间的相似度,按照相似度值从大到小排序得到各训练样本与其余训练样本间的相似度向量;具体可以包括以下
步骤:
[0049]
a21,对训练集中的特征变量进行归一化处理;其中归一化公式表示为:
[0050][0051]
其中,x
*
表示归一化后的数据;x表示待归一化的数据;x
min
和x
max
分别表示数据的最小值和最大值。
[0052]
a22,在归一化基础上,采用相似性度量函数计算各训练样本与其余训练样本间的相似度;
[0053]
本实施例中,相似性度量函数可采用欧式距离或马氏距离,计算公式可表示为:
[0054][0055]
其中,s为样本x与样本x之间的相似度;p为常数,当p=1时,为曼哈顿距离相似度,当p=2时,为欧式距离相似度。
[0056]
a23,对于每个训练样本,按照得到的相似度值从大到小排序,得到一个由相似度值构成的相似度向量,其形式表示为:
[0057]
s=[s0,s1,...,s
k-2
]
[0058]
其中,si为相似度值,且si>s
i 1
;s为相似度向量;k为训练集包含的训练样本数。
[0059]
a3,利用相似度向量计算各训练样本与其余训练样本间的相似度特征;具体可以包括以下步骤:
[0060]
a31,对于每一个训练样本,从其相似度向量的第一个元素开始,选取n组不同长度的子向量,每组子向量s
*
可表示为:
[0061]s*
=[s0,s1,...,sj]
[0062]
其中,j≤k-2;
[0063]
本实施例中,例如,n=7,可以选取7组不同长度(如长度分别为50,100,200,300,400,500,600)的子向量,例如:
[0064]s1*
=[0.9999,0.9999,...,0.9836]
[0065]s2*
=[0.9999,0.9999,...,0.9786]
[0066]s3*
=[0.9999,0.9999,...,0.9551]
[0067]s4*
=[0.9999,0.9999,...,0.9502]
[0068]s5*
=[0.9999,0.9999,...,0.9478]
[0069]s6*
=[0.9999,0.9999,...,0.9345]
[0070]s7*
=[0.9999,0.9999,...,0.9308])。
[0071]
a32,对于每个训练样本,计算各子向量中相似度值的算术平均数,作为该训练样本与训练集中其余训练样本间的n个相似度特征。
[0072]
本实施例中,对于每个训练样本,计算各子向量中相似度值的算术平均数,作为该训练样本与训练集中其余训练样本间的n(如,n=7)个相似度特征(如)。
[0073]
a4,计算各训练样本力学性能真实标签值与力学性能预测标签值之间的平均绝对误差(如屈服强度误差),作为力学性能误差标签。
[0074]
如图3所示,图3为训练集中屈服强度预测中误差标签与相似度特征之间的关系。
[0075]
s102,利用s101中得到的相似度特征和力学性能误差标签训练力学性能预测准确性评估模型;
[0076]
本实施例中,将s101中得到的相似度特征作为输入、力学性能误差标签作为输出,训练力学性能预测准确性评估模型。
[0077]
本实施例中,力学性能预测准确性评估模型可以选用线性或非线性的回归类算法进行训练(如回归类的随机森林算法)。
[0078]
s103,确定待预测样本与训练集中各训练样本间的相似度特征;具体可以包括以下步骤:
[0079]
b1,合并训练集和待预测样本的特征变量;
[0080]
b2,对合并后的数据集中的特征变量进行归一化处理,在归一化基础上,计算待预测样本与训练集中各训练样本间的相似度特征,计算方式与步骤a2、a3一致。
[0081]
本实施例中,合并训练集和待预测样本的特征变量(包括化学成分和工艺参数),并对合并后的数据集中的特征变量进行归一化处理;在归一化基础上,采用相似性度量函数计算待预测样本与各训练样本间的相似度;之后,对于待预测样本,按照得到的相似度值从大到小排序,得到一个由相似度值构成的相似度向量;从其相似度向量的第一个元素开始,选取n组不同长度的子向量;最后,计算各子向量中相似度值的算术平均数,作为针对该待预测样本的n个相似度特征。
[0082]
s104,以待预测样本的相似度特征为输入,利用训练好的力学性能预测准确性评估模型估计所述待预测样本的力学性能预测准确性。
[0083]
本实施例中,将s103中得到的n个相似度特征作为输入,利用训练好的力学性能预测准确性评估模型输出所述待预测样本力学性能误差的估计值,作为针对该待预测样本力学性能预测的准确性评估指标。
[0084]
本实施例中,力学性能以屈服强度为例,可以将s103中得到的n个相似度特征作为输入,利用训练好的力学性能预测准确性评估模型输出所述待预测样本屈服强度误差的估计值,作为针对该待预测样本屈服强度预测的准确性评估指标。
[0085]
本发明实施例所述的板带力学性能预测准确性评估方法,确定训练集中每个训练样本与其余训练样本间的相似度特征和力学性能误差标签;利用得到的相似度特征和力学性能误差标签训练力学性能预测准确性评估模型;确定待预测样本与训练集中各训练样本间的相似度特征;将待预测样本与训练集中各训练样本间的相似度特征作为输入,利用训练好的力学性能预测准确性评估模型估计所述待预测样本的力学性能预测准确性。这样,能够为热轧板带力学性能预测提供一种力学性能预测结果准确性评估指标,从而为现场取样提供指导,大幅降低质量异议的风险。
[0086]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。