一种新型电力变压器故障模糊q学习推理方法
技术领域
1.本发明涉及一种新型电力变压器故障模糊q学习推理方法,具体涉及一种通过学习每个“状态—动作”从而不断调整决策,将模糊推理系统与q学习算法相结合的方法。
背景技术:
2.电力变压器的安全稳定运行决定了电力系统的可靠性水平,一旦电力变压器发生故障势必会引起局部乃至大范围面积的停电事故,虽然在设计层面上电力变压器具有足够的机械强度和优良的电气性能,但由于制作工艺的不足,在制作过程中难免会存在譬如气泡、裂缝、悬浮导电质点、电极毛刺等局部缺陷。当变压器处于长期运行状态时,在电场、热及其余外部因素的影响作用下会不可避免的发生绝缘老化、材料劣化等现象,从而引发电力变压器故障和事故。随着制作工艺的不断增长,我国电力变压器设备平均故障率总体上呈下降趋势,但由变压器故障带来的停电损失仍是巨大的。传统变压器故障诊断预测方法方法大多局限于阈值诊断的范畴,存在缺编码和编码界限过于绝对等问题;基于神经网络诊断的方法存在网络框架难以搭建、训练易陷入局部最优、诊断输出为硬分类间隔等问题;基于支持向量机的诊断方法存在核函数受mercer条件限制、规则化参数确定困难等问题;基于贝叶斯网络的诊断方法需要大量数据和先验理论。传统q学习方法法提取可以表征电力变压器运行状态的变量,之后利用决策树算法修剪输入变量以实现通过最少的输入变量数获得高分类精度的目的。
3.由于q学习在每次迭代循环中都会考察agent的每一个行为,因而从本质上来说q学习在一定条件下只需要采用贪心策略(greedy policy)就可以保证算法的收敛。传统q学习算法只能接受离散的状态输入并产生离散的动作,但是agent系统所处的环境通常是空间连续的,对连续的状态空间和动作空间进行离散化往往会带来信息丢失和维数灾难。
技术实现要素:
4.本发明的目的在于提供一种新型电力变压器故障模糊q学习推理方法,通过学习每个电力变压器故障“状态—动作”从而不断调整决策,进一步的将模糊推理系统与q学习算法相结合,用q学习算法不断更新规则库中的结果向量权值直至其收敛。
5.本发明采取如下技术方案来实现的:
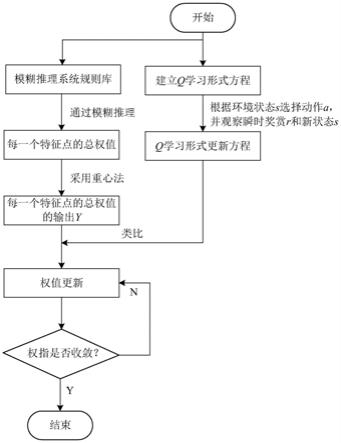
6.一种新型电力变压器故障模糊q学习推理方法,包括以下步骤:
7.1)建立电力变压器故障q学习形式方程;
8.2)根据环境状态s选择动作a,并观察瞬时奖赏r和新状态s,将步骤1)q学习形式方程进行更新;
9.3)定义模糊推理系统规则库;
10.4)假设步骤3)模糊推理系统规则库中结果向量表示连续空间的特征点向量,通过模糊推理,得到每一个特征点的总权值;
11.5)采用重心法得到步骤4)模糊推理系统规则中每一个特征点的总权值的输出y;
12.6)将步骤5)得到的模糊推理系统规则中每一个特征点的总权值的输出y类比于步骤2);q学习形式更新方程,得到权值更新公式;
13.7)反复进行步骤6)权值更新,直至权指表收敛,完成新型电力变压器故障模糊q学习推理。
14.本发明进一步的改进在于,步骤1)的具体实现方法为:建立q学习形式方程:其中,q
*
(s,a)表示agent在状态s下执行动作a所获得的最优奖赏折扣和;r(s,a)表示agent从状态s执行动作a后获得的奖励;γ为折扣因子;t(s,a,s’)表示agent在状态s下执行动作a的一个t周期;表示agent在一个t周期内s’状态下执行动作a’所获得的最优奖赏。
15.本发明进一步的改进在于,步骤2)的具体实现方法为:根据环境状态s选择动作a,并观察瞬时奖赏r和新状态s,将步骤1)q学习形式方程进行更新:其中,q
t 1
(s,a)为t 1时刻的是从状态s执行动作a后获得的累计回报值,α为控制收敛的学习率。
16.本发明进一步的改进在于,步骤3)的具体实现方法为:定义模糊推理系统规则库,模糊推理系统的规则库一般由n个规则组成,假设输入向量为x=(x1,x2,
……
,xn),输出向量为(w1,w2,
……
,wn),则规则库的表示形式如式(3)所示:其中,rj代表第j条规则;a
ji
代表输入变量模糊集,其中i=1,
…
,n;w
ji
代表输出变量的结果,其中j=1,
……
,m。
17.本发明进一步的改进在于,步骤4)的具体实现方法为:假设步骤3)模糊推理系统规则库中结果向量表示连续空间的特征点向量,通过模糊推理,假设上述规则库中结果向量(w1,w2,
……
,wn)表示连续空间的特征点向量a=(a1,a2,
……
,am),相应的权值为(w
j1
,w
j2
,
……
,w
jm
),那么当输入向量为x=(x1,x2,
……
,xn)时,通过模糊推理,每一个特征点的总权值为:其中,μ
jk
(xk),k=1,2,...,n代表相应的模糊集a
ji
的隶属函数值。
18.本发明进一步的改进在于,步骤5)的具体实现方法为:采用重心法得到步骤4)模糊推理系统规则中每一个特征点的总权值的输出y:由此根据模糊推理系统的输出值进行动作选择,环境进入下一个状态并给予预设的回报值。
19.本发明进一步的改进在于,步骤6)的具体实现方法为:将步骤5)得到的模糊推理
系统规则中每一个特征点的总权值的输出y类比于步骤2);q学习形式更新方程,得到权值更新公式:w
jk
=(1-α)w
jk
α(r γ
·wmax
),k=1,2,...,m中:r为回报值;w
max
为wk,k=1,2,
…
,m中的最大值。
20.本发明进一步的改进在于,步骤7)的具体实现方法为:反复进行步骤6)权值更新,直至权指表收敛,完成新型电力变压器故障模糊q学习推理。
21.与现有技术相比,本发明至少具有如下有益的技术效果:
22.1.本发明提出一种新型电力变压器故障模糊q学习推理方法,通过学习每个“状态—动作”从而不断调整决策。
23.2.本发明提出一种将模糊推理系统与q学习算法相结合,用q学习算法不断更新规则库中的结果向量权值直至其收敛。
附图说明
24.图1为不同电力变压器故障输入向量数下,本发明所提方法测试效果图。
具体实施方式
25.下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
26.如图1所示,新型电力变压器q学习的思想是通过学习每个“状态—动作”对的奖赏的评价值q(s,a)从而不断调整决策。q(s,a)的值是从状态s执行动作a后获得的累计回报值。在进行决策时,agent只需要比较状态s下每个动作a的q值就可以明确状态s下的最优策略。由于不需要考虑状态s的所有后续状态,因此决策过程被大大简化。q学习的形式如式(1)所示:
[0027][0028]
式(1)中:q
*
(s,a)表示agent在状态s下执行动作a所获得的最优奖赏折扣和;r(s,a)表示agent从状态s执行动作a后获得的奖励;γ为折扣因子;t(s,a,s’)表示agent在状态s下执行动作a的一个t周期;表示agent在一个t周期内s’状态下执行动作a’所获得的最优奖赏。根据公式(1)可知:在s状态下选择q值最大即选择的行为为最优策略。agent在每个时刻t,根据环境状态s选择动作a,并观察瞬时奖赏r和新状态s,之后按照式(2)更新q值:
[0029][0030]
式(2)中:α为控制收敛的学习率,决定着目标函数能否收敛到局部最小值以及何时收敛到最小值,α按训练轮数增长指数差值递减。
[0031]
由于q学习在每次迭代循环中都会考察agent的每一个行为,因而从本质上来说q
学习在一定条件下只需要采用贪心策略(greedy policy)就可以保证算法的收敛。在传统电力变压器故障q学习算法只能接受离散的状态输入并产生离散的动作,但是agent系统所处的环境通常是空间连续的,对连续的状态空间和动作空间进行离散化往往会带来信息丢失和维数灾难。模糊推理系统与q学习算法的结合很好的解决了上述问题。新型电力变压器故障模糊q学习算法将模糊推理系统与q学习算法相结合,agent接受到一个输入状态向量后,通过模糊推理系统选择一个动作执行,用q学习算法不断更新规则库中的结果向量权值直至其收敛,这样就可以得到一个完整的规则库为agent的行为选择提供先验知识。
[0032]
模糊推理系统的规则库一般由n个规则组成,假设输入向量为x=(x1,x2,
……
,xn),输出向量为(w1,w2,
……
,wn),则规则库的表示形式如式(3)所示:
[0033][0034]
式(3)中:rj代表第j条规则;a
ji
代表输入变量模糊集,其中i=1,
…
,n;w
ji
代表输出变量的结果,其中j=1,
……
,m。
[0035]
假设上述规则库中结果向量(w1,w2,
……
,wn)表示连续空间的特征点向量a=(a1,a2,
……
,am),相应的权值为(w
j1
,w
j2
,
……
,w
jm
),那么当输入向量为x=(x1,x2,
……
,xn)时,通过模糊推理,每一个特征点的总权值计算如式(4)所示:
[0036][0037]
式(4)中:μ
jk
(xk),k=1,2,...,n代表相应的模糊集a
ji
的隶属函数值。可采用重心法解模糊得到该模糊推理系统总的输出y如式(5)所示:
[0038][0039]
由此根据模糊推理系统的输出值进行动作选择,环境进入下一个状态并给予预设的回报值。根据动作所得回报更新知识库的结果向量权值,这一过程类似于传统强化学习中q表的更新,权值更新公式如式(6)所示:
[0040]wjk
=(1-α)w
jk
α(r γ
·wmax
),k=1,2,...,m
ꢀꢀ
(6)
[0041]
式(6)中:r为回报值;w
max
为wk,k=1,2,
…
,m中的最大值,上述更新过程反复进行直至权指表收敛。
[0042]
虽然,上文中已经用一般性说明及具体实施方案对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。