1.本发明涉及数据库管理领域,特别是涉及物化视图(mv)的自动生成。
背景技术:
2.在数据库管理系统(dbms)中,物化视图是数据库性能的重要特征。当从非常大的表中获取相对少量的数据时,物化视图的最优混合最大化资源利用率(cpu和io),并提高应用吞吐量。
3.由于物化视图的重要性,识别物化视图的最优混合是重要的任务。一般而言,识别物化视图的最优混合包括识别少量物化视图,这些物化视图具有合理的尺寸、包含连接(join)和分组的大量预计算,并且可以重写大量工作负载查询。
4.识别物化视图可以手动执行。但是,手动识别物化视图要求对数据库的结构、查询的工作负载和dbms的内部操作有广泛的了解。开发人员需要花费大量时间和精力手动识别物化视图、识别要创建的物化视图、为物化视图建立索引、更新它们以及建议他们的用户使用哪些物化视图。
5.本文描述了用于自动生成物化视图的技术。本节中描述的方法是可以采用的方法,但不一定是先前已经设想或采用的方法。因此,除非另有指示,否则不应当仅由于将本节中所述的任何方法包括在本节中而将其假设为现有技术。
附图说明
6.在某些实施例的附图中,相同的附图标记在所有附图中指代对应的部分:
7.图1描绘了给定查询块的示例连接图。
8.图2是图示不变连接的图。
9.图3是图示变体连接的图。
10.图4是描绘用于使用扩展的覆盖连接子表达式技术从查询块列表自动生成物化视图的过程的流程图。
11.图4a是描绘用于使用覆盖连接子表达式技术从查询块列表自动生成物化视图的过程的流程图。
12.图4b是描绘用于生成连接集的子集或超集的过程的流程图。
13.图4c和图4d一起提供ecse算法的示例。
14.图5a图示了用于执行启发法a的示例流程图。
15.图5b图示了用于执行启发法b的示例流程图。
16.图5c图示了用于执行启发法c的示例流程图。
17.图5d图示了用于执行启发法d的示例流程图。
18.图5e图示了用于执行启发法e的示例流程图。
19.图5f图示了用于执行启发法f的示例流程图。
20.图6是描绘用于最优全局贪心算法的过程的流程图。
21.图7是图示可以在其上实现本发明的实施例的计算机系统的框图。
具体实施方式
22.在下面的描述中,出于解释的目的,阐述了许多具体细节以便提供对本发明的透彻理解。但是,将明显的是,可以在没有这些具体细节的情况下实践本发明。在其它情况下,以框图形式示出了结构和设备,以避免不必要地使本发明模糊。
23.总体概述
24.本文描述了用于物化视图的自动生成的技术。此类技术在本文中被称为自动mv生成。
25.一般而言,自动mv生成通过检查查询块的工作集来识别候选mv的集合。一旦形成候选,就进一步评估候选mv以计算对候选mv的益处。
26.益处的计算考虑了诸如mv的存储成本和维护成本之类的因素。另一个考虑的重要因素是通过对工作集中的一个或多个查询执行mv重写实现的查询执行成本节省。此外,对其使用特定mv的mv重写导致查询执行成本节省的查询越多,mv提供的益处就越多。
27.用于生成候选mv集合的一种方法在本文中被称为覆盖子表达式技术(cse)。在cse中,完全等效的连接图之间的关系被用于生成新的结果连接集。然后使用结果连接集来形成候选mv集合。例如,当组成连接集等效时,可以对工作集中的一对组成连接集及其对应的查询块集应用等效连接集操作。表示mv的结果连接集可以被用于重写两个组成查询块集。在这种情况下,结果连接集的连接图与每个组成连接集的相应连接图是等效的。
28.本文描述了用于生成候选mv集合的改进方法。改进方法被称为扩展覆盖子表达式技术(ecse)。在ecse下,除了严格等效之外,连接集之间的各种关系被用于生成新的结果连接集。此类关系包括子集、交集、超集和并集,下面将进一步详细描述。在一些情况下,结果连接集和初始连接集之间的关系被考虑以生成新的结果连接集。然后使用最终结果连接集来形成候选mv集合。例如,当相应的组成连接集相交时,可以对工作集中的一对组成连接集和对应的一对组成查询块集应用相交连接集操作。表示mv的结果连接集可以被用于重写两个组成查询块集。在此,结果连接集与任一个组成连接集都不等效。
29.关键定义和概念
30.查询块
31.查询块是结构化查询语言(sql)语句的基本单元,它指定对表、内联视图或由from子句引用的视图的投影操作(例如,在select子句中指定的列),并且可以指定对表和视图的附加操作,诸如连接和分组。查询块可以嵌套在查询块中。
32.下面提供的是嵌套在另一个查询块内的查询块的示例。
[0033][0034][0035]
在以上示例中,查询包含两个查询块。作为内联视图的嵌套的查询块包含sql语句
select*from emp e where e.salary》5000,其投影当工资大于5000时来自表emp e的所有字段。主查询块包含sql语句select e.name,e.salary from(
‘
the nested query block(嵌套的查询块)’),它投影来自嵌套的查询块的结果的名称和工资字段。
[0036]
连接图
[0037]
连接图是表示在查询块中指定的所有连接的图结构。连接图包括节点之间的边,每个节点表示一个表,每条边表示该边连接到的两个表之间的连接并且表示连接的特性,诸如特定的连接类型(例如,内部、外部等)和特定的连接条件,其包括一个或多个连接谓词。
[0038]
下面提供了查询块的示例。图1描绘了给定查询块的连接图。
[0039]
select s.student_name,s.address,c.course_name
[0040]
from student s,course c
[0041]
where s.year=2018and c.department=
‘
mathematics’and s.
[0042]
course_id=c.course_id
[0043]
参考图1,节点101表示表student“s”(“s”是student表的别名),该表包含列id、student_name、address、course_id和year;节点102表示表course“c”,该表包含列course_id、course_name、department、course_fee和instructor。边104表示基于连接条件或连接谓词s.course_id=c.course_id的表student“s”和表course“c”之间的内部连接。
[0044]
连接集
[0045]
连接集是基于一个或多个查询块的连接图的抽象。连接集本质上是连接边的集合。在连接图中,表(或视图)形成顶点(或节点)。两个表之间的连接条件形成两个顶点之间的连接边。连接边可以包括一个或多个连接谓词。例如,考虑以下查询块。
[0046]
select*
[0047]
from t1,t2,t3
[0048]
where t1.x=t2.y and t1.a》t2.b
[0049]
用于这个查询块的连接图具有三个顶点:t1、t2和t3。t1和t2之间只有单个连接边,它由连接谓词的集合表示:{t1.x=t2.y,t1.a》t2.b}。
[0050]
如果连接集包括单个表,那么将同一个表之间的空或伪连接边添加到连接集。连接集允许将集合操作应用于其底层连接图。连接集与对应的查询块集相关联,查询块集表示可以基于连接集(即,连接集的连接图)以mv的形式潜在地重写的查询块的集合。
[0051]
连接集及其相关联的查询块集在本文中可以表示为[连接集,查询块集]。例如,[{f1,d2,d3,d6},{q5,q7}]表示连接集{f1,d2,d3,d5}及其关联的查询块集{q5,q7}。连接集{f1,d2,d3,d6}包含表f1、d2、d3和d6及其连接边(但是示例中未示出连接边);其相关联的查询块集包含查询块q5和q7,它们可以基于连接集{f1,d2,d3,d6}以mv的形式潜在地被重写。可以基于连接集使用mv被重写的查询块集在本文中可以被称为能够使用连接集被重写。
[0052]
连接集操作
[0053]
在ecse下,集合操作被应用于组成连接集以形成结果连接集;当应用于组成连接集时,集合操作考虑表和连接边。连接集操作使用组成连接集之间的基于集合的关系来生成结果连接集,使得组成连接集的所有相关联的查询块集可以基于结果连接集按照mv被重
写。组成连接集的相关联的查询块集的并集是与结果连接集相关联的查询块集。
[0054]
下面提供了两个组成连接集及其相关联的查询块集。在这个简单的示例中,执行等效连接集操作以形成表示潜在mv的结果连接集,可以使用该潜在mv重写两个查询块。
[0055]
q1:
[0056]
select f.n,sum(f.m),d1.m
[0057]
from f,d1
[0058]
where f.f=d1.p and f.x=6andd1.y=25
[0059]
group by f.n,d1.m;
[0060]
[{f,d1},{q1}]
[0061]
q2:
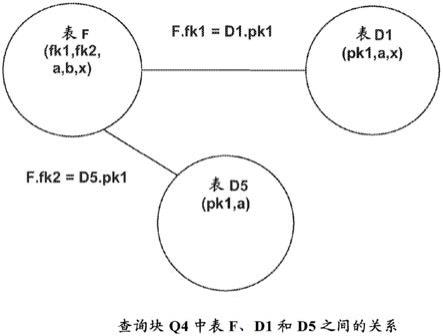
[0062]
select f.y,count(f.m),d1.h
[0063]
from f,d1
[0064]
where f.f=d1.p and f.x=11and d1.y=33
[0065]
group by f.y,d1.h;
[0066]
[{f,d1},{q2}]
[0067]
[{f,d1},{q1,q2}]
[0068]
创建物化视图mv1
…
作为
[0069]
select f.n,sum(f.m),count(f.m),d1.m,f.y,d1.h,f.x,d1.y
[0070]
from f,d1
[0071]
where f.f=d1.p and f.x in(6,11)and d1.y in(25,33)
[0072]
group by f.n,d1.m,f.y,d1.h,f.x,d1.y;
[0073]
在上述示例中,查询块q1包含sql语句select f.n,sum(f.m),d1.m from f,d1 where f.fk=d1.p and f.x=6 andd1.y=25group by f.y,d1.h。当满足条件f.x=6和d1.y=25时,该select语句投影来自表f和d1的列f.n、sum(f.m)和d1.m。group by语句基于列f.n、d1.m和f.m对结果进行分组。连接集{f,d1}有涉及表f和d1的连接图并且可以被用于重写查询块集{q1}。
[0074]
类似地,查询块q2包含sql语句select f.y,count(f.m),d1.h from f,d1 where f.f=d1.p and f.x=11 and d1.y=33 group by f.y,d1.h。当满足条件f.x=11和d1.y=33时,该select语句投影来自表f和d1的列f.y、count(f.m)、d1.h。group by f.m语句基于列f.y和d1.h对结果进行分组。连接集{f,d1}有涉及表f和d1的连接图并且可以被用于重写查询块集{q2}。
[0075]
由于两个连接集是相同的,因此等效连接集操作可以被用于形成结果连接集{f,d1}。该结果连接集表示潜在的mv1,它有涉及表f和d1的连接图并且可以被用于重写查询块q1和q2两者。在上面的示例中,给定的连接集操作使用select f.n,sum(f.m),count(f.m),d1.m,f.y,d1.h,fx,d1.y语句来合并查询块q1和q2中的被投影的列。mv1中的谓词f.x in(6,11)统一了查询块q1中的谓词f.x=6和查询块q2中的谓词f.x=11。类似地,mv1中的谓词d1.y in(25,33)统一了查询块q1中的谓词d1.x=25和查询块q2中的谓词d1.y=33。group by f.m语句基于列f.n、d1.m、f.y、d1.h、fx和d1.y对结果进行分组。连接集操作统一谓词并合并查询块q1和q2中的被投影的列。因此,基于连接集{f,d1}的mv可以被用于重写
查询块q1和q2两者。
[0076]
符号
[0077]
为简洁起见,符号用于内连接并且用于左外连接。指示t2是外连接的表并且t1在这个外连接的左边。连接集表示一个或多个查询块中的连接图;它在第[0038]段中定义并在下面更详细地解释。
[0078]
符号()用于有序列表,{}用于集合,[]用于复合结构,并且|s|用于集合s的基数(即,元素的数量)。符号用于空集,∈用于集合成员资格。a∈b表示a是集合b的元素。符号用于全称量词。表示t的所有元素。
[0079]
符号用于真子集。真子集是与原始集合不完全相同的子集-它包含更少的连接边。表示b是a的真子集。符号用于集合的不包含。表示b既不是a的子集也不等于a。
[0080]
符号=用于等效。当连接集b等效于连接集a时,连接集b和a之间的关系可以表示为b=a或a=b。
[0081]
符号∩用于交集。两个连接集a和b的交集可以表示为a∩b,它是包含也属于b的a的所有连接边的连接集,反之亦然,但没有其他东西。
[0082]
符号用于超集。连接集a的超集是另一个连接集,它包含连接集a中的所有连接边,还包含其它连接边。当连接集b是连接集a的超集时,连接集b和a之间的关系可以表示为
[0083]
符号∪用于并集。两个连接集a和b的并集是另一个连接集,其包含连接集a和b中存在的所有连接边。a∪b表示a和b的并集。
[0084]
符号用于子集。连接集a的子集是另一个集合,它仅包含连接集a的连接边,但可能不包含a的所有连接边。当连接集b是连接集a的子集时,连接集b和a之间的关系可以表示为
[0085]
符号∧用于and(和)关系,∨用于or(或)关系。如果a和b都为真,那么语句a∧b为真;如果其中任何一个为假,那么该语句为假。如果a或者b为真,那么语句a∨b为真;当且仅当两者都为假时,该语句为假。
[0086]
列名pk和fk分别用于作为外键和主键的列。因此,t1.pk表示表t1的主键,t2.fk表示表t2的外键。
[0087]
不变连接
[0088]
一般而言,如果连接为x中的每一行恰好生成一行,那么x关于其与表t的连接是不变的;即,连接不会复制或消除x的任何行。在此x或者是表或者是连接集。x关于t的不变性由invariant(x,t)表示。连接中的表是否不变可以从连接中涉及的连接边的特性得出。
[0089]
如果满足以下四个条件,那么表t1关于其与表t2的连接处于不变连接:
[0090]
1.连接是具有连接条件t1.fk=t2.pk的等内连接,其中t1.fk是引用主键t2.pk的外键;
[0091]
2.列t1.fk具有非空约束;
[0092]
3.查询块不包含t2上的任何过滤器或子查询谓词,或者这些谓词不包括在结果连接集中。
[0093]
4.t2在与除了查询块中指定的t1以外的表(如果有)的连接中是不变的,或者其它表不包括在结果连接集中。
[0094]
如将更详细解释的,不变连接的存在被用于生成连接集,该连接集是底层连接集的并集或超集,从而允许物化视图包含更大的预计算。
[0095]
下面提供不变连接的示例。
[0096]
q4:
[0097]
select f.a,d1.a,d5.a
[0098]
from f,d1,d5
[0099]
where f.fk1=d1.pk1and f.fk2=d5.pk1
[0100]
group by f.a,d1.a,d5.a;
[0101]
[{f,d1,d5},{q4}]
[0102]
图2描述了查询块q4中的表f、d1和d5之间的关系。
[0103]
列fk1是表f中的非空外键,其引用表d1中的主键pk1。表f和d1基于条件f.fk1=d1.pk1连接。这是f参与和d1的不变连接的示例。列fk2是表f中的非空外键,其引用表d5中的主键pk1。表f和d5基于条件f.fk2=d5.pk1连接。此外,不变连接f.fk1=d1.pk1保证f的所有行在它与表d1的连接中都被保留而不重复;类似地,不变连接f.fk2=d5.pk1保证f的所有行在它与表d5的连接中都被保留而不重复。
[0104]
相反,下面提供的是非不变连接的示例。
[0105]
q5:
[0106]
select f.a,f.b,d1.a
[0107]
from f,d1
[0108]
where f.fk1=d1.pk1
[0109]
group by f.a,f.b,d1.a;
[0110]
[{f,d1},{q5}]
[0111]
图3描绘了查询块q5中的表f和d1之间的关系,以及查询块q6中的表f、d1和d5之间的关系。
[0112]
在查询块q5中,外键f.fk1不具有非空约束,但是表f中的外键fk1引用表d1中的主键pk1。这违反了[0058]中的规则#2。因此,表f在与d1的连接中不是不变的。
[0113]
等效
[0114]
如果两个连接集的连接图是等效的,那么认为这两个连接集是等效的。当连接集a与连接集b等效时,可以修剪连接集之一。
[0115]
当连接集b与连接集a等效时,连接集b和a之间的关系可以表示为b=a。
[0116]
下面提供了修剪连接集的等效连接集操作的示例。
[0117]
q7:
[0118]
select f.n,f.g,sum(f.m1),d7.y,d2.z
[0119]
from f,d7,d2
[0120]
where f.f1=d7.p and f.f2=d2.p and f.x in(4,6)and d7.c=25
[0121]
group by f.n,f.g,d7.y,d2.z;
[0122]
[{f,d7,d2},{q7}]
[0123]
q8:
[0124]
select f.n,avg(f.m2),d7.p,d2.y
[0125]
from f,d7,d2
[0126]
where f.f1=d7.k and f.f2=d2.p and f.x=9and d7.c=5
[0127]
group by f.n,d7.p,d2.y;
[0128]
[{f,d7,d2},{q8}]
[0129]
[{f,d7,d2},{q7,q8}]
[0130]
创建物化视图mv2
…
作为
[0131]
select f.n,f.g,d7.y,d2.z,d7.p,d2.y,f.x,d7.c,avg(f.m2),sum(f.m1)
[0132]
from f,d7,d2
[0133]
where f.f1=d7.p and f.f2=d2.p and f.x in(4,6,9)and d7.c in(5,25)
[0134]
group by f.n,f.g,d7.y,d2.z,d7.p,d2.y,f.x,d7.c;
[0135]
在以上示例中,连接集{f,d7,d2}与查询块集{q7}相关联,并且具有涉及表f、d7和d2及其连接边的连接图。类似地,连接集{f,d7,d2}与查询块集{q8}相关联,并且具有涉及表f、d7和d2及其连接边的连接图。由于与查询块q7相关联的连接集{f,d7,d2}和与查询块q8相关联的连接集{f,d7,d2}包含相同的表集合和连接这些表的完全相同的连接谓词(即,它们的连接图是相同的),因此等效集操作可以被应用以修剪连接集之一,并且剩余的连接集可以被用于将查询块q7和q8重写到mv中。
[0136]
等效连接集操作包括过滤谓词的统一以及选择和分组(group-by)列表的合并,这创建了可以被用于重写查询块q7和q8两者的mv2。在上面的示例中,mv2中的谓词f.x in(4,6,9)统一了查询块q7中的谓词f.x in(4,6)和查询块q8中的谓词f.x=9。类似地,mv2中的谓词d7.c in(5,25)统一了查询块q7中的谓词d7.c=5和查询块q8中的谓词d7.c=25。等效连接集操作还使用语句select f.n,f.g,d7.y,d2.z,d7.p,d2.y,f.x,d7.c,avg(f.m2),sum(f.m1),sum(f.m1)来合并查询块q7和q8中的被投影的列。
[0137]
交集
[0138]
两个连接集a和b的交集可以表示为a∩b,它是包含也属于b的a的所有连接边的连接集,反之亦然,但是不包括其他东西。
[0139]
在一个实施例中,当相应的连接图相交时,可以对连接集应用交集操作。
[0140]
更具体而言,当存在对两个组成连接集共有的连接边时,可以应用交集连接集操作来生成结果连接集和与结果连接集相关联的结果查询块集。两个组成连接集共有的连接边被建立为结果连接并且其相关联的查询块集是组成连接集的查询块集的并集。
[0141]
下面提供的是生成表示mv的结果连接集的交集连接集操作的示例。
[0142]
q9:
[0143]
select f.n,sum(f.m1),d7.y,d2.z
[0144]
from f,d7,d2
[0145]
where f.f1=d7.p and f.f2=d2.p and f.x in(4,6)and d7.c=25
[0146]
group by f.n,d7.y,d2.z;
[0147]
[{f,d7,d2},{q9}]
[0148]
q10:
[0149]
select f.y,count(f.m2),d1.h
[0150]
from f,d7,d3
[0151]
where f.f1=d7.p and f.f3=d3.p and f.x=11and d3.w》11
[0152]
group by f.y,d7.h;
[0153]
[{f,d7,d3},{q10}]
[0154]
[{f,d7},{q9,q10}]
[0155]
创建物化视图mv3
…
作为
[0156]
select f.n,f.y,d7.y,d7.h,d7.c,f.x,f.f2,f.f3,count(f.m2),
[0157]
sum(f.m1)
[0158]
from f,d7
[0159]
where f.f1=d7.p and f.x in(4,6,11)
[0160]
group by f.n,f.y,f.x,d7.y,d7.h,d7.c,f.f2,f.f3;
[0161]
在以上示例中,连接集{f,d7,d2}与查询块集{q9}相关联,并且具有涉及表f、d7和d2及其连接边的连接图。类似地,连接集{f,d7,d3}与查询块集{q10}相关联,并具有涉及表f、d7和d3及其连接边的连接图。连接集{f,d7,d2}和{f,d7,d3}都包含表f和d7以及连接f和d7的完全相同的连接谓词(即,f.f1=d7.p)。因此,可以应用交集连接集操作来形成表示mv3的结果连接集,它可以被用于重写查询块q9和q10两者。
[0162]
mv3由过滤谓词的统一以及查询块中的投影列和分组列表的合并形成,从而允许mv3被用于重写查询块q9和q10两者。在上面的示例中,mv3中的谓词f.x in(4,6,11)统一了查询块q6中的谓词f.x in(4,6)和查询块q9中的谓词f.x=11。上面的连接集操作还使用语句select f.n,f.y,d7.y,d7.h,d7.c,f.x,f.f2,f.f3,count(f.m2),sum(f.m1)来合并查询块q9和q10中的被投影的列。
[0163]
子集
[0164]
连接集a的子集是仅包含来自连接集a的连接边的另一个集合,但是可能不包含a的所有连接边。当连接集b是连接集a的子集时,连接集b和a之间的关系可以表示为这意味着连接集b仅包含连接集a的连接边中的一些连接边。
[0165]
在一个实施例中,当一个连接集是另一个连接集的子集时,可以应用子集连接集操作。作为另一个连接集的子集的连接集被建立为结果连接集并且其相关联的查询块集是组成连接集的查询块集的并集。
[0166]
更具体而言,当第一组成连接集包括第二组成连接集中涉及的所有表时,可以应用子集连接集操作来重写与第一组成连接集相关联的查询块集;第二组成连接集至少包括第一组成连接集中不涉及的连接边。
[0167]
下面提供的是生成表示mv的结果连接集的子集连接集操作的示例。
[0168]
q11:
[0169]
select f.x,d1.y,d2.z,sum(f.m1)
[0170]
from f,d1,d2
[0171]
where f.f1=d1.k and f.f2=d2.k and f.y=5and d1.c=9and d2.s《25
[0172]
group by f.x,d1.y,d2.z;
[0173]
[{f,d1,d2},{q11}]
[0174]
q12:
[0175]
select f.x,d1.h,count(f.m2)
[0176]
from f,d1
[0177]
where f.f1=d1.k and f.y=7and d1.g=7and d1.c=33
[0178]
group by f.x,d1.h;
[0179]
[{f,d1},{q12}]
[0180]
[{f,d1},{q11,q12}]
[0181]
创建物化视图mv4
…
作为
[0182]
select f.x,d1.y,d1.h,d1.c,d1.g,f.y,f.f2,count(f.m2),sum(f.m1)
[0183]
from f,d1
[0184]
where f.f1=d1.k and d1.c in(9,33)and f.y in(5,7)
[0185]
group by f.x,f.y,d1.y,d1.h,d1.c,d1.g,f.f2;
[0186]
在上面的示例中,连接集{f,d1,d2}与查询块集{q11}相关联,并且具有涉及表f、d1和d2及其连接边的连接图。类似地,连接集{f,d1}与查询块集{q12}相关联,并且具有涉及表f和d1及其连接边的连接图。连接集{f,d1}仅包含来自连接集{f,d1,d2}的表,但不包含所有表。因此,连接集{f,d1}是连接集{f,d1,d2}的子集,并且在这两个连接集中,连接f和d1的连接谓词是完全相同的。因此,子集连接集操作可以被应用以生成表示mv4的结果连接集,其可以被用于重写查询块q11和q12。
[0187]
mv4由过滤谓词的统一以及选择和分组列表的合并形成,从而允许mv4被用于重写查询块q11和q12两者。在上面的示例中,mv4中的谓词d1.c in(9,33)统一了查询块q11中的谓词d1.c=9和查询块q12中的谓词d1.c=33。类似地,mv4中的谓词f.y in(5,7)统一了查询块q11中的谓词f.y=5和查询块q12中的谓词f.y=7。上面的连接集操作还使用语句select f.x,d1.y,d1.h,d1.c,d1.g,f.y,f.f2,count(f.m2),sum(f.m1)来合并查询块q11和q12中的被投影的列。
[0188]
超集
[0189]
连接集a的超集是另一个连接集,它包含来自连接集a的所有连接边,还包含其它连接边。当连接集b是连接集a的超集时,连接集b和a之间的关系可以表示为这意味着连接集b包含来自连接集a的所有连接边,但也可以包含其它连接边。
[0190]
在一个实施例中,当第一连接集是第二连接集的超集并且相对于第二连接集不变时,可以应用超集连接集操作。超集连接集被识别为结果连接集。结果连接集不等效于两个组成连接集的一个组成连接集。
[0191]
更具体而言,当第一连接集包括第二连接集中涉及的所有连接边并且第一连接集包括至少一条第二连接集中不涉及的连接边时,可以应用超集连接集操作来重写与第一组成连接集相关联的查询块集。作为另一个连接集的超集的连接集被建立为结果连接集并且其相关联的查询块集是组成连接集的查询块集的并集。
[0192]
下面提供的是生成表示mv的结果连接集的超集连接集操作的示例。
[0193]
q13:
[0194]
select f.n,sum(f.m1),d1.m
[0195]
from f,d1
[0196]
where f.f1=d1.k and f.x=6and d1.y=25
[0197]
group by f.n,d1.m;
[0198]
[{f,d1},{q13}]
[0199]
q14:
[0200]
select f.y,min(f.m2),d1.h,d5.z
[0201]
from f,d1,d5
[0202]
where f.f1=d1.k and f.fk5=d5.pk and f.x=11and d1.y=33and
[0203]
d5.g》6
[0204]
group by f.y,d1.h,d5.z;
[0205]
[{f,d1,d5},{q14}]
[0206]
[{f,d1,d5},{q13,q14}]
[0207]
创建物化视图mv5
…
作为
[0208]
select f.n,f.y,d1.m,d1.h,d5.z,d1.y,d5.g,f.x,min(f.m2),
[0209]
sum(f.m1)
[0210]
from f,d1,d5
[0211]
where f.f1=d1.k and f.fk5=d5.pk and f.x in(6,11)and d1.y in(25,33)
[0212]
group by f.n,f.y,f.x,d1.y,d1.m,d1.h,d5.z,d5.g;
[0213]
在上述示例中,连接集{f,d1}与查询块集{q13}相关联,并且具有涉及表f和d1及其连接边的连接图。类似地,连接集{f,d1,d5}与查询块集{q14}相关联,并且具有涉及表f、d1和d5及其连接边的连接图。在查询块q11中,表f和d5基于连接条件f.fk5=d5.pk连接。在查询块q13和q14中,表f和d1基于连接条件f.f1=d1.pk连接。在此,连接集{f,d1}和d5之间的连接是不变连接,其可以表示为invariant({f,d1},d5)。
[0214]
连接集{f,d1}仅包含来自连接集{f,d1,d5}的表,但不包含所有表。因此,连接集{f,d1}是连接集{f,d1,d5}的子集。因为连接集{f,d1}关于它与表d5的连接是不变的,因此超集连接集操作可以被用于形成表示mv5的结果连接集,其可以被用于重写查询块q13和q14两者。
[0215]
mv5由过滤谓词的统一以及选择和分组列表的合并形成,这使得mv5能够被用于重写查询块q13和q14两者。在上面的示例中,mv5中的谓词f.x in(6,11)统一了查询块q13中的谓词f.x=6和查询块q14中的谓词f.x=11。类似地,mv5中的谓词d1.y in(25,33)统一了查询块q13中的谓词d1.y=25和查询块q14中的谓词d1.y=33。为了满足第3个不变性条件,d5上的过滤谓词不包括在mv5的定义中。上面的连接集操作也使用sql语句select f.n,f.y,d1.m,d1.h,d5.z,d1.y,d5.g,f.x,min(f.m2),sum(f.m1)来合并查询块q13和q14中的被投影的列。
[0216]
并集
[0217]
两个连接集a和b的并集是另一个连接集,它包含存在于连接集a和b中的所有连接谓词。符号∪用于并集。a∪b表示并集包含集合a和b的所有元素。
[0218]
在一个实施例中,当第一连接集与第二连接集相交时,可以应用并集连接集操作,它们的交集不为空,并且交集中的表与两个组成连接集的其它表不变地连接。(其它表属于两个连接集中的任一个,但不在交集内。)结果连接集与组成连接集中的任一个都不等效。
[0219]
更具体而言,当第一组成连接集包括第二组成连接中不涉及的至少一个表时,并集连接集操作可以被应用于生成发送的结果连接和与结果连接集相关联的结果查询块集合;第二组成连接集包括第一组成连接集中不涉及的至少一个表;并且第一组成连接集和第二组成连接集包含至少一个共有的表,并且交集内的表与不在交集内的表具有不变连接。结果连接集包括第一和第二组成连接集中涉及的所有连接边;并且结果查询块集是与第一和第二组成连接集相关联的查询块集的并集。
[0220]
下面提供的是生成表示mv的结果连接集的并集连接集操作的示例。
[0221]
q15:
[0222]
select f.n,d1.m,sum(f.m1)
[0223]
from f,d1
[0224]
where f.fk1=d1.pk and f.x=6and d1.z=25
[0225]
group by f.n,d1.m;
[0226]
[{f,d1},{q15}]
[0227]
q16:
[0228]
select f.y,d2.w,max(f.m2)
[0229]
from f,d2
[0230]
where f.fk2=d2.pk and f.x=12and d2.g》7
[0231]
group by f.y,d2.w;
[0232]
[{f,d2},{q16}]
[0233]
[{f,d1,d2},{q15,q16}]
[0234]
创建物化视图mv6
…
作为
[0235]
select f.n,f.y,d1.m,d2.w,d1.z,d2.g,f.x,max(f.m2),sum(f.m1)
[0236]
from f,d1,d2
[0237]
where f.fk1=d1.pk and f.fk2=d2.pk and f.x in(6,12)
[0238]
group by f.n,f.y,f.x,d1.m,d2.w,d1.z,d2.g;
[0239]
在上面的示例中,连接集{f,d1}与查询块集{q15}相关联,并且具有涉及表f和d1及其连接边的连接图。类似地,连接集{f,d2}与查询块集{q16}相关联,并且具有涉及表f和d2及其连接边的连接图。在查询块q15中,f.fk1是引用主键d1.pk的非空外键。在查询块q16中,f.fk2是引用主键d2.pk的非空外键。f关于它与d1和d2的连接是不变的。这可以表示为invariant({f,d1},d2}和invariant({f,d2},d1)。
[0240]
mv6通过统一过滤谓词以及选择和分组列表的合并形成,这使得mv6能够被用于重写查询块q15和q16两者。在上面的示例中,mv6中的谓词f.x in(6,12)统一了查询块q15中的谓词f.x=6和查询块q16中的谓词f.x=12。为了满足第3个不变性条件,关于d1和d2的过滤谓词不包括在mv6的定义中。上面的连接集操作还使用语句select f.n,f.y,d1.m,d2.w,d1.z,d2.g,f.x,max(f.m2),sum(f.m1)from f,d1,d2来合并查询块q15和q16中的被投影的列。
[0241]
物化视图的自动生成
[0242]
图4是描绘用于使用ecse从查询块列表自动生成物化视图的过程的流程图。图4c和图4d一起提供ecse算法的示例。
[0243]
参考图4,在操作400处,如果查询块包含的表的数量少于两个,那么从查询块列表中修剪该查询块。为查询块列表中的每个查询块生成连接图。识别每个连接图中的事实、维度和分支表,并检测不变连接。
[0244]
在一个实施例中,如果连接图具有多对多连接弧,那么在操作400处执行连接图分区和缩减,本文称为启发法a。图5a图示了用于执行启发法a 510的示例流程图。参考图5a,系统在操作511处接收来自连接图的列表的连接图。系统在操作512处确定连接图是否包含多对多连接弧。当事实表中的多个记录与另一个事实表中的多个记录相关联时,连接图包含多对多连接弧。如果连接图包含多对多连接弧,那么系统可以从连接图中移除多对多连接弧中所涉及的维度表节点。如果连接图不包含多对多连接弧,那么在操作514处不移除连接图。
[0245]
参考图4,给定的查询块列表被划分为子列表,使得每个子列表包含在操作410处具有共有事实表的连接图。
[0246]
参考图4,在操作420处创建列表alst和nlst。alst存储从在操作400处生成的连接图导出的连接集和相关联的查询块集。nlst存储结果连接集和从连接集操作产生的相关联的查询块集。
[0247]
参考图4,连接集和查询块集从连接图导出并在操作430处插入到alst中。
[0248]
操作440至470从查询块列表识别物化视图包括应用于组成连接集以形成结果连接集或者更新至少一个组成连接集的连接集操作。
[0249]
连接集操作用伪代码描述。在伪代码中,子列表中的项x是指子列表中的连接集及其关联的查询块集,y是指同一子列表中的另一个连接集及其相关联的查询块集。在此,在子列表的每个项与同一子列表的每个其它项之间进行成对比较。通过确保x不等于(即,《》)y来避免自我比较。每个连接集操作将子列表中的一个连接集及其相关联的查询块集与另一个连接集和对应的相关联的查询块集进行比较。连接集操作更新连接集及其相关联的查询块集或者生成新项z,其包括结果连接集和对应的相关联的查询块集,其中结果连接集可以被用于重写其查询块集中的每个查询块。
[0250]
操作440使用扩展覆盖子表达式(ecse)技术来生成新的结果连接集。例如,工作集中的多个不同查询可以具有相同的连接图,因此被相同的连接子表达式“覆盖”。然后使用结果连接集来形成候选mv集。
[0251]
图4a是描绘用于使用ecse算法从查询块列表自动生成物化视图的过程的流程图。参考图4a,操作441至442作为循环被迭代地执行以提取cse。循环的每次迭代都可以产生新的连接集、连接集状态的改变或连接集的移除。由连接集操作产生的更新后的连接集和相关联的查询块集存储在alst中。由连接集操作产生的新连接集和相关联的查询块集存储在nlst中。在执行操作441至442之后,将nlst附加到alst。
[0252]
参考图4a,在操作441处执行等效连接集操作以修剪连接集和查询块集。对于alst中存储的两个不同的项x和y,如果项x和y的连接集相同,那么执行等效集操作以将项y从alst中移除。剩余的连接集x.jnset可以被用于重写查询块x.qbset和y.qbset两者。下面提供的是操作441的伪代码描述。在此,“《》”表示“不等于”比较运算符。
[0253]
if(x《》y∧x.jnset=y.jnset)
[0254]
{
[0255]
x.qbset=x.qbset∪y.qbset;
[0256]
从alst移除y;
[0257]
}
[0258]
在上面的伪代码描述中,x.qbset是用于连接集x.jnset的相关联的查询块集。y.qbset是用于连接集y.jnset的相关联的查询块集。在符号上,连接集x.jnset与其相关联的查询块集x.qbset之间的关系可以写成[{x.jnset},{x.qbset}]。类似地,连接集y.jnset与其相关联的查询块集y.qbset之间的关系可以写成[{y.jnset},{y.qbset}]。
[0259]
当从两个查询块的连接图导出的连接集相同时,执行等效连接集操作,以对从两个查询块之一导出的连接集和查询块集进行修剪。剩余的连接集x.jnest与其相关联的查询块集之间的新关系可以写成[{x.jnset},{x.qbset∪y.qbset}],这意味着现在可以使用连接集x.jnset重写从两个查询块导出的两个查询块集x.qbset和y.qbset。
[0260]
参考图4a,在操作442处,执行交集操作以识别交集连接集。对于alst中存储的两个不同的项x和y,如果项x的连接集不是项y的连接集的子集、项y的连接集不是项x的连接集的子集,并且项x的连接集与项y的连接集之间存在重叠,那么生成表示两个连接集的重叠部分的新连接集。新连接集被添加到nlst。下面提供的是操作442的伪代码描述。
[0261][0262][0263]
在上面的伪代码描述中,执行交集连接集操作,以生成新的连接集z.jnset。对于存储在alst中的两个不同的项x和y,如果项x的连接集(x.jnset)不是项y的连接集(y.jnset)的子集、项y的连接集(y.jnset)不是项x的连接集(x.jnset)的子集并且y.jnset与x.jnset之间存在重叠(例如,包含至少一个表),那么执行交集连接集操作以生成新连接集z.jnset。z.jnset包含连接集y.jnset和x.jnset的共有部分,并且可以被用于重写查询块集x.qbset和y.quset两者。新连接集z.jnset与其相关联的查询块集之间的关系可以写成[{z.jnest},{x.qbset∪y.qbset}]。
[0264]
参考图4a,在执行操作441至442之后,在操作443处将nlst附加到alst。
[0265]
参考图4,在操作450处识别基于不变性的并集连接集。对于alst中存储的两个不同的项x和y,如果项y的连接集不是项x的连接集的子集、项x的连接集不是项y的连接集的子集并且项x的连接集与项y的连接集之间存在重叠,并且两个连接集中都存在不变连接,那么执行并集连接集操作以生成表示项x的连接集和项y的连接集的并集的新连接集,并且新连接集可以被用于重写项x和y的查询块集两者。新连接集被添加到alst。下面提供的是
操作450的伪代码描述。
[0266][0267][0268]
在上面的伪代码描述中,执行并集连接集操作,以生成新连接集z.jnset。对于alst中存储的两个不同的项x和y,如果项y的连接集(y.jnset)不是项x的连接集(x.jnset)的子集、项x的连接集(x.jnset)不是项y的连接集(y.jnset)的子集、y.jnset与x.jnset之间存在重叠,并且存在不变连接,那么执行并集连接集操作以生成新连接集z.jnset。z.jnset包含y.jnset和x.jnset的并集连接集,并且可以被用于重写查询块集x.qbset和y.qbset两者。新连接集z.jnset与其相关联的查询块集之间的关系可以写成[{z.jnest},{x.qbset∪y.qbset}]。新连接集z.jnset被添加到alst。
[0269]
参考图4,在操作460处执行等效连接集操作以修剪连接集和查询块集。
[0270]
图4b是描绘操作470的过程的流程图。参考图4b,操作471至472作为循环被迭代地执行以识别连接集的子集或超集。循环的每次迭代都可以改变连接集的状态。由连接集操作产生的更新后的连接集和相关联的查询块集存储在alst中。
[0271]
参考图4b,在操作471处,执行子集连接集操作以识别子集连接集。对于存储在alst中的两个不同的项x和y,如果项x的连接集是项y的连接集的子集,那么更新项x的查询块集以包含项x的查询块集和项y的查询块集。下面提供的是操作471的伪代码描述。
[0272][0273]
x.qbset=x.qbset∪y.qbset;
[0274]
在上面的伪代码描述中,当项x的连接集(x.jnset)是项y的连接集(y.jnset)的子集时,从查询块x的连接图导出的查询块集(x.qbset)被更新为包含项x的查询块集和项y的查询块集两者。连接集x.jnset与其相关联的查询块集之间的新关系可以被写成[{x.jnest},{x.qbset∪y.qbset}],这意味着连接集x.jnset现在可以用两个查询块集x.qbset和y.qbset来重写。
[0275]
参考图4b,在操作472处执行超集连接集操作以识别超集连接集,如果alst中的项y的连接集是同一列表中的项x的连接集的子集并且存在不变连接,那么更新项x的查询块集以包含项x的查询块集和项y的查询块集两者。下面提供的是操作472的伪代码描述。
[0276]
[0277]
x.qbset=x.qbset∪y.qbset;
[0278]
在上面的伪代码描述中,当项y的连接集(y.jnset)是项x的连接集(x.jnset)的子集并且存在不变连接时,项x的查询块集(x.qbset)被更新为包含项x的查询块集(x.qbset)和项y的查询块集(y.qbset)两者。连接集x.jnset与其相关联的查询块集之间的新关系可以写成[{x.jnest},{x.qbset∪y.qbset}],这意味着连接集x.jnset现在可以用两个查询块集x.qbset和y.qbset来重写。
[0279]
参考图4,在操作480处执行连接集和相关联的查询块集缩减,本文称为启发法b、c和d。
[0280]
在一个实施例中,如果连接集包含的连接的数量低于给定阈值,那么执行连接集分区和缩减,本文称为启发法b。图5b图示了用于执行启发法b 520的示例流程图。参考图5b,系统在操作521处接收来自连接集和相关联的查询块集的列表的连接集及其相关联的查询块集。系统在操作522处确定连接集包含的连接的数量是否低于给定阈值。例如,给定的阈值ψ可以被计算为给定工作负载的所有查询中所有查询块中的平均连接数的一半。如果连接集包含的连接的数量低于给定阈值,那么系统在操作523处从连接集和相关联的查询块集的列表中移除该连接集及其相关联的查询块集。如果连接集包含的连接的数量不低于给定阈值,那么在操作524处不移除该连接集及其相关联的查询块集。
[0281]
下面提供的是启发法b的伪代码描述。
[0282][0283]
在上面的伪代码描述中,如果x.jnest包含的连接的数量低于给定阈值ψ,那么从alst中修剪连接集x.jnest及其相关联的查询块集x.qbset。
[0284]
在一个实施例中,如果连接集的相关联的查询块集的元素的数量低于给定阈值,那么执行连接集分区和缩减,本文称为启发法c。图5c图示了用于执行启发法c 530的示例流程图。参考图5c,系统在操作531处接收来自连接集和相关联的查询块集的列表的连接集及其相关联的查询块集。系统在操作532处确定相关联的查询块包含的元素的数量是否低于给定阈值。例如,可以将给定阈值β设置为2,这确保仅推荐可以重写至少2个查询块的那些mv。如果相关联的查询块包含的元素的数量低于给定阈值,那么系统在操作533处从连接集和相关联的查询块集的列表中移除该连接集及其相关联的查询块集。如果相关联的查询块包含的元素的数量不低于给定阈值,那么在操作534处,不移除该连接集及其相关联的查询块集。
[0285]
下面提供的是启发法c的伪代码描述。
[0286]
[0287][0288]
在上面的伪代码描述中,如果x.qbset的元素的数量低于给定阈值β(例如,2),那么从alst修剪连接集x.jnest及其相关联的查询块集x.qbset。
[0289]
在一个实施例中,如果存在最大连接集,那么执行连接集分区和缩减,本文称为启发法d。图5d图示了用于执行启发法d 540的示例流程图。参考图5d,系统在操作541处接收来自连接集和相关联的查询块集的列表的连接集及其相关联的查询块集。系统在操作542处确定在连接集的列表中是否存在最大连接集。例如,如果连接集jk是连接集ji的子集并且jk的相关联的查询块集是ji的相关联的查询块集的子集,那么连接集ji相对于连接集jk被认为是最大的。如果在连接集的列表中存在最大连接集,那么系统在操作543处从连接集和相关联的查询块集的列表中移除该连接集及其相关联的查询块集。如果在连接集的列表中不存在最大连接集,那么在操作544处不移除该连接集及其相关联的查询块集。
[0290]
下面提供的是启发法d的伪代码描述。
[0291][0292]
从alst移除x
[0293]
参考图4,在操作490处,基于其连接集和查询块集,对alst中的每个项执行过滤谓词的统一以及选择或分组列表的合并,并形成候选物化视图。
[0294]
参考图4,在操作480处执行连接集和相关联的查询块集缩减,本文称为启发法e和f。
[0295]
在一个实施例中,如果连接集的事实表的行数与行数的比率大于给定阈值,那么执行连接集分区和缩减,本文称为启发法e。图5e图示了用于执行启发法e 550的示例流程图。参考图5e,系统在操作551处接收来自连接集和相关联的查询块集的列表的连接集及其相关联的查询块集。系统在操作552处确定连接集的事实表的行数与行数的比率是否大于给定阈值。在一个示例中,连接集的行数的估计考虑了连接谓词、统一过滤谓词和分组列。如果连接集的事实表的行数与行数的比率大于给定阈值,那么系统将在操作553处从连接集和相关联的查询块集的列表中移除该连接集及其相关联的查询块集。如果连接集的事实表的行数与行数的比率不大于给定阈值,那么在操作554处,不移除该连接集及其相关联的查询块集。
[0296]
在另一个实施例中,如果在其相关联的查询块集中的所有重写的查询块的估计成本降低高于给定阈值,那么执行连接集分区和缩减,本文称为启发法f。图5f图示了用于执行启发法f 560的示例流程图。参考图5f,系统在操作561处接收来自连接集和相关联的查询块集的列表的连接集及其相关联的查询块集。系统在操作562处确定其相关联的查询块集中所有重写的查询块的估计成本降低是否高于给定阈值。例如,如果[cost(rw(q1)) cost(rw(q2)) cost(rw(q3))]/[cost(q1) (cost(q2) cost(q3)]》ω,那么连接集的相关
联的查询块集{q1,q2,q3}将被修剪。如果其相关联的查询块集中所有重写的查询块的估计成本降低高于给定阈值,那么系统在操作563处从连接集和相关联的查询块集的列表中移除该连接集及其相关联的查询块集。如果其相关联的查询块集中的所有重写的查询块的估计成本降低不高于给定阈值,那么在操作564处不移除该连接集及其相关联的查询块集。
[0297]
每个结果连接集和相关联的查询块集可以被用于生成候选mv。参考图4,最优全局贪心(optgg)算法可以在操作492处基于对工作负载性能的净益处来决定是否推荐候选mv。optgg考虑了诸如存储空间、mv维护成本等之类的约束。
[0298]
图6是描绘用于optgg算法的过程的流程图。参考图6,optgg算法首先在步骤610处根据其估计的创建成本和缩减因子对从结果连接集生成的候选mv进行排序。在步骤620处,optgg算法然后为每个候选mv调用mv重写模块。在步骤630处,opptgg算法在符合条件时按照mv重写工作负载查询。在步骤640处,opptgg算法然后比较有和没有mv重写的工作负载查询的估计成本。在步骤650处,如果mv向工作负载性能提供净益处,那么推荐mv。
[0299]
硬件概述
[0300]
根据实施例,本文描述的技术由一个或多个专用计算设备实现。专用计算设备可以是硬连线的以执行这些技术,或者可以包括数字电子设备(诸如被持久地编程为执行这些技术的一个或多个专用集成电路(asic)或现场可编程门阵列(fpga)),或者可以包括被编程为根据固件、存储器、其它存储装置或组合中的程序指令执行这些技术的一个或多个通用硬件处理器。这种专用计算设备还可以将定制的硬连线逻辑、asic或fpga与定制编程相结合,以实现这些技术。专用计算设备可以是台式计算机系统、便携式计算机系统、手持设备、联网设备或者结合硬连线和/或程序逻辑以实现这些技术的任何其它设备。
[0301]
例如,图7是图示可以在其上实现本发明实施例的计算机系统700的框图。计算机系统700包括总线702或用于传送信息的其它通信机制,以及与总线702耦合以处理信息的硬件处理器704。硬件处理器704可以是例如通用微处理器。
[0302]
在一些实施例中,协处理器可以驻留在与硬件处理器或处理器核心相同的芯片上。这种协处理器的示例包括数据分析加速器(dax)协处理器和单指令多数据(simd)处理器。
[0303]
dax协处理器使数据库操作能够直接在协处理器中运行,而硬件处理器核心执行其它指令。此类操作包括(1)扫描数组以查找匹配(或大于或小于)输入值的元素,并返回位向量,其中设置了用于匹配的位;(2)基于位向量从数组中选择元素;以及(3)在集合运算中,给定整数的输入集合,确定它们中有多少也存在于另一个集合中。
[0304]
simd处理器同时对多个数据项执行相同的操作。simd处理器通过对多个寄存器或子寄存器中的数据执行单个指令来利用数据级并行性。因此,可以相应地增加每条指令的吞吐量。
[0305]
计算机系统700还包括耦合到总线702的主存储器706,诸如随机存取存储器(ram)或其它动态存储设备,用于存储将由处理器704执行的指令和信息。主存储器706还可以用于存储在执行由处理器704执行的指令期间的临时变量或其它中间信息。当存储在处理器704可访问的非瞬态存储介质中时,这些指令使计算机系统700成为被定制以执行指令中指定的操作的专用机器。
[0306]
计算机系统700还包括耦合到总线702的只读存储器(rom)708或其它静态存储设
备,用于存储用于处理器704的静态信息和指令。存储设备710(诸如磁盘、光盘或固态驱动器)被提供并耦合到总线702,用于存储信息和指令。
[0307]
计算机系统700可以经由总线702耦合到显示器712(诸如阴极射线管(crt)),用于向计算机用户显示信息。包括字母数字键和其它键的输入设备714耦合到总线702,用于将信息和命令选择传送到处理器704。另一种类型的用户输入设备是光标控件716(诸如鼠标、轨迹球或光标方向键),用于将方向信息和命令选择传送到处理器704并用于控制显示器712上的光标移动。这种输入设备通常在两个轴(第一轴(例如,x)和第二轴(例如,y))上具有两个自由度,这允许设备指定平面中的位置。
[0308]
计算机系统700可以使用定制的硬连线逻辑、一个或多个asic或fpga、固件和/或程序逻辑(它们与计算机系统相结合,使计算机系统700成为专用机器或将计算机系统700编程为专用机器)来实现本文所述的技术。根据实施例,响应于处理器704执行包含在主存储器706中的一个或多个指令的一个或多个序列,计算机系统700执行所述的技术。这些指令可以从另一个存储介质(诸如存储设备710)读入到主存储器706中。包含在主存储器706中的指令序列的执行使得处理器704执行本文所述的处理步骤。在替代实施例中,可以使用硬连线的电路系统代替软件指令或与软件指令组合。
[0309]
如本文使用的术语“存储介质”是指存储使机器以特定方式操作的数据和/或指令的任何非瞬态介质。这种存储介质可以包括非易失性介质和/或易失性介质。非易失性介质包括例如光盘、磁盘或固态驱动器,诸如存储设备710。易失性介质包括动态存储器,诸如主存储器706。存储介质的常见形式包括例如软盘、柔性盘、硬盘、固态驱动器、磁带或任何其它磁数据存储介质、cd-rom、任何其它光学数据存储介质、任何具有孔图案的物理介质、ram、prom和eprom、flash-eprom、nvram、任何其它存储器芯片或盒式磁带。
[0310]
存储介质不同于传输介质但可以与传输介质结合使用。传输介质参与在存储介质之间传送信息。例如,传输介质包括同轴电缆、铜线和光纤,包括包含总线702的导线。传输介质也可以采用声波或光波的形式,诸如在无线电波和红外数据通信期间生成的声波或光波。
[0311]
将一个或多个指令的一个或多个序列携带到处理器704以供执行可以涉及各种形式的介质。例如,指令最初可以携带在远程计算机的磁盘或固态驱动器上。远程计算机可以将指令加载到其动态存储器中,并使用调制解调器通过电话线发送指令。计算机系统700本地的调制解调器可以在电话线上接收数据并使用红外发送器将数据转换成红外信号。红外检测器可以接收红外信号中携带的数据,并且适当的电路系统可以将数据放在总线702上。总线702将数据携带到主存储器706,处理器704从主存储器706检索并执行指令。由主存储器706接收的指令可以可选地在由处理器704执行之前或之后存储在存储设备710上。
[0312]
计算机系统700还包括耦合到总线702的通信接口718。通信接口718提供耦合到网络链路720的双向数据通信,其中网络链路720连接到本地网络722。例如,通信接口718可以是集成服务数字网(isdn)卡、电缆调制解调器、卫星调制解调器或者提供与对应类型的电话线的数据通信连接的调制解调器。作为另一个示例,通信接口718可以是局域网(lan)卡,以提供与兼容lan的数据通信连接。还可以实现无线链路。在任何此类实现中,通信接口718都发送和接收携带表示各种类型信息的数字数据流的电信号、电磁信号或光信号。
[0313]
网络链路720通常通过一个或多个网络向其它数据设备提供数据通信。例如,网络
链路720可以提供通过本地网络722到主机计算机724或到由互联网服务提供商(isp)726操作的数据设备的连接。isp 726进而通过全球分组数据通信网络(现在通常称为“互联网”728)提供数据通信服务。本地网络722和互联网728都使用携带数字数据流的电信号、电磁信号或光信号。通过各种网络的信号以及网络链路720上并通过通信接口718的信号(其将数字数据携带到计算机系统700和从计算机系统700携带数字数据)是传输介质的示例形式。
[0314]
计算机系统700可以通过(一个或多个)网络、网络链路720和通信接口718发送消息和接收数据,包括程序代码。在互联网示例中,服务器730可以通过互联网728、isp 726、本地网络722和通信接口718发送对应用程序的所请求代码。
[0315]
接收到的代码可以在它被接收到时由处理器704执行,和/或存储在存储设备710或其它非易失性存储装置中以供稍后执行。
[0316]
软件概述
[0317]
图8是可以用于控制计算机系统700的操作的软件系统800的框图。软件系统800及其组件,包括它们的连接、关系和功能,意在仅仅是示例性的,并且不意味着限制(一个或多个)示例实施例的实现。适于实现(一个或多个)示例实施例的其它软件系统可以具有不同的组件,包括具有不同的连接、关系和功能的组件。
[0318]
提供软件系统800用于指引计算机系统700的操作。可以存储在系统存储器(ram)706和固定存储装置(例如,硬盘或闪存)710上的软件系统800包括内核或操作系统(os)810。
[0319]
os 810管理计算机操作的低级方面,包括管理进程的执行、存储器分配、文件输入和输出(i/o)以及设备i/o。表示为802a、802b、802c...802n的一个或多个应用程序可以被“加载”(例如,从固定存储装置710传送到存储器706中)以供系统700执行。意图在系统700上使用的应用或其它软件也可以被存储为可下载的计算机可执行指令集,例如,用于从互联网位置(例如,web服务器、应用商店或其它在线服务)下载和安装。
[0320]
软件系统800包括图形用户界面(gui)815,用于以图形(例如,“点击”或“触摸手势”)方式接收用户命令和数据。进而,这些输入可以由系统800根据来自操作系统810和/或(一个或多个)应用802的指令来起作用。gui 815还用于显示来自os 810和(一个或多个)应用802的操作结果,用户可以对操作结果提供附加的输入或终止会话(例如,注销)。
[0321]
os 910可以直接在系统800的裸硬件820(例如,(一个或多个)处理器704)上执行。可替代地,管理程序或虚拟机监视器(vmm)830可以插入在裸硬件820和os 810之间。在这个配置中,vmm 830充当os 810与系统700的裸硬件820之间的软件“缓冲”或虚拟化层。
[0322]
vmm 830实例化并运行一个或多个虚拟机实例(“客人机”)。每个客人机包括“客人”操作系统(诸如os 810),以及被设计为在客人操作系统上执行的一个或多个应用(诸如(一个或多个)应用802)。vmm 830向客人操作系统呈现虚拟操作平台并管理客人操作系统的执行。
[0323]
在一些情况下,vmm 830可以允许客人操作系统如同其直接在系统700的裸硬件820上运行一样运行。在这些实例中,被配置为直接在裸硬件820上执行的客人操作系统的相同版本也可以在vmm 830上执行而无需修改或重新配置。换句话说,vmm 830可以在一些情况下向客人操作系统提供完全硬件和cpu虚拟化。
[0324]
在其它情况下,客人操作系统可以被专门设计或配置为在vmm 830上执行以提高效率。在这些实例中,客人操作系统“意识到”它在虚拟机监视器上执行。换句话说,vmm 830可以在一些情况下向客人操作系统提供半虚拟化。
[0325]
呈现上述基本计算机硬件和软件的目的是为了说明可以用于实现(一个或多个)示例实施例的基本底层计算机组件。但是,(一个或多个)示例实施例不一定限于任何特定的计算环境或计算设备配置。代替地,根据本公开,(一个或多个)示例实施例可以在本领域技术人员将理解为能够支持本文呈现的(一个或多个)示例实施例的特征和功能的任何类型的系统体系架构或处理环境中实现。
[0326]
云计算
[0327]
本文一般地使用术语“云计算”来描述计算模型,该计算模型使得能够按需访问计算资源的共享池,诸如计算机网络、服务器、软件应用和服务,并且允许以最少的管理工作或服务提供商交互来快速提供和释放资源。
[0328]
云计算环境(有时称为云环境或云)可以以各种不同方式实现,以最好地适应不同要求。例如,在公共云环境中,底层计算基础设施由组织拥有,该组织使其云服务可供其它组织或一般公众使用。相反,私有云环境一般仅供单个组织使用或在单个组织内使用。社区云旨在由社区内的若干组织共享;而混合云包括通过数据和应用可移植性绑定在一起的两种或更多种类型的云(例如,私有、社区或公共)。
[0329]
一般而言,云计算模型使得先前可能由组织自己的信息技术部门提供的那些职责中的一些职责代替地作为云环境内的服务层来递送,以供消费者使用(根据云的公共/私有性质,在组织内部或外部)。取决于特定实现,由每个云服务层提供或在每个云服务层内提供的组件或特征的精确定义可以有所不同,但常见示例包括:软件即服务(saas),其中消费者使用在云基础设施上运行的软件应用,同时saas提供者管理或控制底层云基础设施和应用。平台即服务(paas),其中消费者可以使用由paas提供者支持的软件编程语言和开发工具,以开发、部署和以其它方式控制它们自己的应用,同时paas提供者管理或控制云环境的其它方面(即,运行时执行环境下的一切)。基础设施即服务(iaas),其中消费者可以部署和运行任意软件应用,和/或提供处理、存储装置、网络和其它基础计算资源,同时iaas提供者管理或控制底层物理云基础设施(即,操作系统层下面的一切)。数据库即服务(dbaas),其中消费者使用在云基础设施上运行的数据库服务器或数据库管理系统,同时dbaas提供者管理或控制底层云基础设施、应用和服务器,包括一个或多个数据库服务器。
[0330]
在前面的说明书中,已经参考众多具体细节描述了本发明的实施例,这些细节可以根据实现有所变化。因而,说明书和附图应被视为说明性而非限制性的。本发明范围的唯一和排他性指示,以及申请人意图作为本发明范围的内容,是以发布这种权利要求的具体形式从本技术发布的权利要求集合的字面和等同范围,包括任何后续更正。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。