1.本发明涉及数据处理领域,具体涉及一种日志采集的脏数据快速检测及处理方法。
背景技术:
2.在采集日志过程中,经常出现由于规则配置不对或者规则配置有缺陷,或者配置不完整,系统中就会不时产生脏数据,这些脏数据会影响到我们系统的正常数据展示,清理起来又费时费力。
3.现有采集清洗方案中,总的流程是先根据解析规则提取字段。然后基于分类规则进行分类,达到日志的规范化,现有的方法能最大限度避免脏数据的方法是在解析过程中,如果没有正确的提取字段,就判定为脏数据,而没有进一步的进行判断。
4.现有采集过程中对脏数据处理的方案主要有以下几个缺点:1:只是简单判断日志解析是否成功,如果失败,就判为脏数据2:有些隐藏更深的脏数据没法检测成功,比如某些字段的分类不是我们想要的结果。
5.3:有些系统具有脏数据判定规则,匹配复杂,效率不高,且判断准确性也不高。
技术实现要素:
6.本发明的目的在于解决目前网络安全日志采集流程中,检测并避免各种脏数据污染正常数据,因此提供一种日志采集的脏数据快速检测及处理方法。
7.为实现上述目的,本发明的技术方案是:一种日志采集的脏数据快速检测及处理方法,包括如下步骤:s1、通过网络采集各种不同网络设备类型的日志,最终汇聚到消息中间件;s2、依据解析库中的解析规则对消息中间件中日志进行解析规则匹配,匹配成功的提取字段,并执行步骤s3;匹配不成功的认为是脏数据,并执行步骤s5;s3、依据字段分类库中的字段分类规则对提取的某些分类字段进行分类;s4、对分类完的字段,依据其对应的分类值,通过广度优先遍历,找到这个分类值的概率,同理找到相应日志下所有字段的分类值的概率,依次对各个字段的分类值的概率进行判断,只要其中一个字段的分类值的概率大于设置的阈值,就判定为脏数据;s5、将脏数据存放到脏数据库中,维护人员根据脏数据库中脏数据对规则进行重新调整。
8.在本发明一实施例中,所述段分类规则中字段分类类型是按行进行存储,所述段分类规则是从根节点开始构建成的分类规则树,每个叶子节点由相应字段的分类值即数字代码与对应的概率值构成。
9.相较于现有技术,本发明具有以下有益效果:本发明方法因为在内存中进行树的广度优先遍历,能够快速提高查找效率,以及对概率值的判定比较准确,针对每个字段的判
定,具有更高的准确性,整个流程能快速及准确的判断出脏数据。
10.另外,如果判断为脏数据,另外存入相应的库中,然后进行人工校正,这样脏数据就不会导入正常的仓库中而影响正常的流程。
附图说明
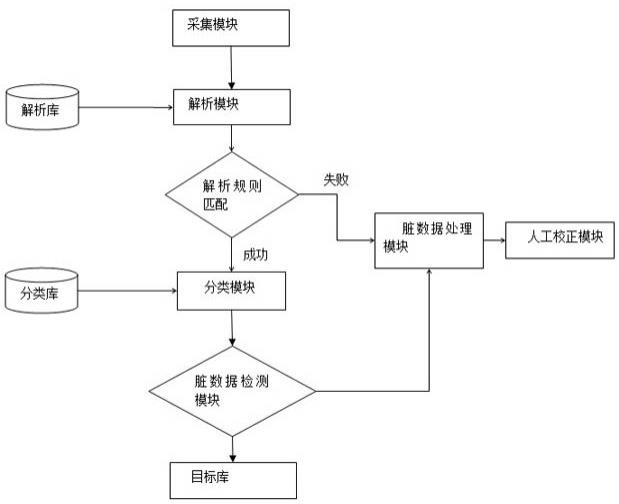
11.图1为本发明方法流程示意图。
12.图2为本发明分类规则树结构示意图。
13.图3为本发明字段判断流程示意图。
具体实施方式
14.下面结合附图,对本发明的技术方案进行具体说明。
15.本发明一种日志采集的脏数据快速检测及处理方法,包括如下步骤:s1、通过网络采集各种不同网络设备类型的日志,最终汇聚到消息中间件;s2、依据解析库中的解析规则对消息中间件中日志进行解析规则匹配,匹配成功的提取字段,并执行步骤s3;匹配不成功的认为是脏数据,并执行步骤s5;s3、依据字段分类库中的字段分类规则对提取的某些分类字段进行分类;s4、对分类完的字段,依据其对应的分类值,通过广度优先遍历,找到这个分类值的概率,同理找到相应日志下所有需要分类字段的分类值的概率,依次对各个字段的分类值的概率进行判断,只要其中一个字段的分类值的概率大于设置的阈值,就判定为脏数据;s5、将脏数据存放到脏数据库中,维护人员根据脏数据库中脏数据对规则进行重新调整。
16.以下为本发明具体实施过程。
17.本发明一种日志采集的脏数据快速检测及处理方法,提供有以下模块:采集模块通过网络采集各种不同网络设备类型的日志,最终汇聚到消息中间件。
18.解析库和分类库分别存放解析模块、分类模块的规则,一般是正则表达式,关键字。
19.解析模块消费消息中间件数据、根据各种算法对原始日志进行字段的提取。
20.分类模块对字段进行分类。
21.脏数据处理模块,主要就是存脏数据到相应的仓库中,可以人工查看。
22.人工校正模块,维护人员根据脏数据对规则进行重新调整。
23.目标库即正常事件录入的仓库。
24.脏数据检测模块是最重要的模块,很多隐秘,难找的脏数据就是经过这个模块进行快速准确的判定:详细流程如下:1、分别对每个分类字段的分类库进行阈值设定。
25.2、内存中加载各种分类库(主要是各种分类值以及判定概率,比如1代表根节点,这种基本上就是代表没分类成功,就是脏数据,概率可设置为0.99)。
26.3、内存中构建分类规则树,这样处理效率比较高。
27.4、针对事件的分类值,对树进行广度优先搜索,找到本事件的分类值,查找出概率值。判断是否脏数据
5、依次对各个字段进行判断,只要其中一项大于我们设置的阈值,就判定为脏数据。
28.如图1所示,为本发明一种日志采集的脏数据快速检测及处理方法的整体处理流程。
29.本发明针对整个日志规范化的过程中,分类规则的概率判断,是基于每个需要分类的字段来判断,判断比较严格,只要其中一项达不到要求,就被判断为脏数据,这样的结果判断更准确,而判断某个字段的概率要求是快速准确,对效率要求比较高。
30.在内存中加载了多个分类字段的分类规则,比如设备类型,事件分类等,针对每个字段的概率判断,也要有对应的准确值,本发明是根据分类值进行概率设置。
31.本发明在库表中定义的分类类型是按行存储的,例如 10代表网络安全事件,1002代表扫描行为,100200代表主机扫描。11代表数据安全事件。本发明把整张表数据构建成一棵树,每个叶子节点由数字代码跟概率值构成,如图2所示。
32.整个表数据在内存中就是一棵完整的树,然后针对字段(如事件)的分类值对整个树进行广度优先遍历,找到这个分类值的概率p1。
33.然后根据广度优先遍历算法分别计算出其他字段的概率p2...pn。
34.最后进行综合判断,只要其中的某个概率值大于既定的阈值,就被判定为脏数据。整体判断流程参见图3所示。
35.以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
技术特征:
1.一种日志采集的脏数据快速检测及处理方法,其特征在于,包括如下步骤:s1、通过网络采集各种不同网络设备类型的日志,最终汇聚到消息中间件;s2、依据解析库中的解析规则对消息中间件中日志进行解析规则匹配,匹配成功的提取字段,并执行步骤s3;匹配不成功的认为是脏数据,并执行步骤s5;s3、依据字段分类库中的字段分类规则对提取的分类字段进行分类;s4、对分类完的字段,依据其对应的分类值,通过广度优先遍历,找到这个分类值的概率,同理找到相应日志下所有字段的分类值的概率,依次对各个字段的分类值的概率进行判断,只要其中一个字段的分类值的概率大于设置的阈值,就判定为脏数据;s5、将脏数据存放到脏数据库中,维护人员根据脏数据库中脏数据对规则进行重新调整。2.根据权利要求1所述的一种日志采集的脏数据快速检测及处理方法,其特征在于,所述段分类规则中字段分类类型是按行进行存储,所述段分类规则是从根节点开始构建成的分类规则树,每个叶子节点由相应字段的分类值即数字代码与对应的概率值构成。
技术总结
本发明涉及一种日志采集的脏数据快速检测及处理方法。包括:S1、采集各种不同网络设备类型的日志,汇聚到消息中间件;S2、依据解析库中解析规则对消息中间件中日志进行解析规则匹配,匹配成功的提取字段,并执行步骤S3;匹配不成功的认为是脏数据,并执行步骤S5;S3、依据字段分类库中的字段分类规则对提取的字段进行分类;S4、对分类完的字段,依据其对应的分类值,通过广度优先遍历,找到这个分类值的概率,同理找到相应日志下所有字段的分类值的概率,依次对各个字段的分类值的概率进行判断,只要其中一个字段的分类值的概率大于设置的阈值,就判定为脏数据;S5、将脏数据存放到脏数据库中,维护人员根据脏数据库中脏数据对规则进行重新调整。重新调整。重新调整。
技术研发人员:黄诗贤 唐敏 张章学 蓝友枢 叶松
受保护的技术使用者:福建省海峡信息技术有限公司
技术研发日:2022.01.07
技术公布日:2022/4/15
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。