1.本发明涉及一种解析装置和解析方法。
背景技术:
2.在生物医学领域中,为了鉴定生物体试样中含有的各种代谢物,进行使用了气相色谱质谱分析装置(gc/ms)或液相色谱质谱分析装置(lc/ms)的多成分同时分析。
3.从gc/ms、lc/ms等分析装置输出的分析数据由用户解读从而鉴定代谢物。分析数据的解读大部分依赖于用户的知识和经验。因此,提出了一种使鉴定生物体试样中含有的各种代谢物所涉及的作业高效化来使验证分析数据高效化的代谢物解析用数据处理装置(参照专利文献1)。在专利文献1的装置中,利用了处理生物体内的代谢的领域中使用的、记载有代谢途径的被称为代谢图的图表。在代谢图中记载有在代谢的过程中发生的化学反应、通过该反应生成的各种化合物(代谢物)、参与该反应的酶等,一眼就能够了解代谢的流程。在专利文献1的装置中,通过在代谢图上注明与生物体试样中含有的代谢物、能够分析某种代谢物的分析条件等有关的信息,来辅助用户进行分析条件的设定作业以及掌握代谢物的信息。
4.为了对基于分析装置的分析数据的代谢物的鉴定结果进行解析并从中导出有价值的信息,进一步利用与分析对象相应的工具。因此,脂质组学(脂质分子(脂质体)解析)、蛋白质组学(蛋白质解析)、代谢组学(代谢组解析)等的作为解析工具的软件分别独立地由研究人员或企业开发出。另外,近年来,为了综合地解析各种组学数据,另外为了能够在生物医学领域所利用的各种软件间互换数据,提供了一种依据应用程序编程接口(api)等的信息平台(参照非专利文献1)。
5.另外,在各种公共数据库中公开了与生物医学领域中的各种发现有关的研究结果。这种数据库之一有由美国国家医学图书馆(national library of medicine:nlm)管理的收录有医学文献信息的数据库medline。例如能够使用美国国家医学图书馆在web上公开的pubmed的检索功能来检索收录在medline中的文献信息(参照非专利文献2)。medline中收录的文献的目录信息(bibliographical information)通过作为医学文献索引典(thesaurus)的mesh(medical subject heading:医学主题词表)进行索引,以适当地进行检索。通过对各文献的目录信息赋予mesh术语和meshid来进行索引。对一个文献赋予多个mesh术语。另外,meshid根据mesh术语的类别而被附加于该mesh术语。
6.另外,在生物医学领域中,有时根据生物体试样的分析数据来对基因、药物、疾病等的关联性进行解析,从而估计基因表达的控制机制、分子间相互作用。在对基因表达控制机制、分子间相互作用的估计中要求阅读并理解与生物医药关联的科学文献来构建图或模型。科学文献的量庞大,另外,科学文献在被细化的专业领域中以不同的观点记述。人难以进行将这种科学文献中记述的内容相互联系的作业。因此,提出了以下一种方法:使用mesh术语来从pubmed提取各种科学文献中记述的与基因、药物、疾病等有关的术语,统计它们的关联性来估计基因表达控制机制、分子间相互作用(参照非专利文献3)。
7.现有技术文献
8.专利文献
9.专利文献1:日本特开2010
‑
216981号公报
10.非专利文献1:garuda platform,特定非营利活动法人系统和生物学研究机构,[线上],[平成31年4月21日检索],因特网<http://www.garuda
‑
alliance.org/about.html>
[0011]
非专利文献2:pubmed,[线上],[平成31年4月17日检索],因特网<url:https://www.ncbi.nlm.nih.gov/pubmed>
[0012]
非专利文献3:stephen joseph wilson等,
‘
automated literature mining and hypothesis generation through a network of medical subject headings’,[线上],biorxiv,[平成31年4月17日检索],因特网,<url:https://www.biorxiv.org/content/10.1101/403667v1>
技术实现要素:
[0013]
发明要解决的问题
[0014]
生物医学领域的分析数据解析用的软件的开发和改良中使用统计学、计算机科学的理论和技术。如果是精通统计学、计算机科学的技术人员,则能够基于所给出的分析数据来使用某种解析方法导出某种结果。然而,根据分析数据而导出的结果在生物学上来看未必是有用的。即,如果不精通分析数据的意义、其背景,则无法判断这种解析方法是否合适,无法得到对于生物医学领域的研究人员来说有用的解析结果。
[0015]
在综合解析基因、蛋白质以及代谢物等的变化的多组学中,研究人员为了对各个组学数据进行解析而应参考的文献庞大,并且这些文献日益增多。即使通过非专利文献3中记载的方法(数据挖掘)获得基因
‑
基因、疾病
‑
基因、药物
‑
基因的关联性来作为知识,研究人员也需要自己阅读文献来进行判断以有效地利用该知识。然而,难以从庞大的量的文献中高效地提取对于该研究人员来说有用的文献。
[0016]
此外,在此说明了解析生物体试样的分析数据的情况下的问题点,但在从生物体试样以外的试样、例如自海水、湖水、河川等采集到的液体试样中含有的环境激素等物质的测定结果中提取对查明环境污染的原因有用的文献的情况下等也存在同样的问题。
[0017]
本发明是为了解决上述问题而完成的,其目的在于能够容易地提取对于对使用分析装置测定试样中含有的物质而得到的结果的理解有用的文档信息。
[0018]
用于解决问题的方案
[0019]
本发明的第一方式是,一种解析装置,具备:信息获取单元,其从使用分析装置测定试样中含有的解析对象物而得到的结果中获取用于确定该解析对象物的信息即第一识别信息;提取单元,其基于由所述信息获取单元获取到的所述第一识别信息,来从存储有文档信息的数据库中提取与所述解析对象物关联的术语即关联术语;以及呈现单元,其向用户呈现由所述提取单元提取出的所述关联术语。
[0020]
本发明的第二方式是,一种解析方法,包括以下步骤:获取使用分析装置测定试样中含有的解析对象物而得到的结果;从测定所述解析对象物而得到的结果中获取用于确定该解析对象物的信息即第一识别信息;基于所述第一识别信息来从存储有文档信息的数据
库中提取与所述解析对象物关联的术语;以及呈现步骤,向用户呈现所述关联术语。
[0021]
发明的效果
[0022]
根据本发明,使用从试样中含有的解析对象物的测定结果中获取到的第一识别信息,来从存储有文档信息的数据库中提取关联术语,并向用户呈现该术语,因此用户能够使用所呈现的关联术语来从所述数据库中容易地找出对于对解析对象物的测定结果的理解有用的文档信息。
附图说明
[0023]
图1是包括本发明的实施方式所涉及的解析装置50的信息提供系统的概要图。
[0024]
图2是示出根据分析数据制作解析用数据的处理的一例的说明图。
[0025]
图3是示出代谢图的显示例的图。
[0026]
图4是示出解析装置50的概要性结构的一例的框图。
[0027]
图5是示出解析装置50的处理的一例的流程图。
[0028]
图6是示出作为解析对象物的识别信息的meshid的集合即meshid组的例子的图。
[0029]
图7是示出关联分析的结果的显示例的图。
[0030]
图8是示出解析装置50的处理的另一例的流程图。
[0031]
图9是示出第一meshid组和第二meshid组的一例的图。
[0032]
图10是示出关联分析的结果的显示例的图。
具体实施方式
[0033]
[包括解析装置的系统的概要]
[0034]
下面,基于附图来说明本发明的实施方式。图1是包括本实施方式所涉及的解析装置50的信息提供系统的概要图。
[0035]
信息提供系统包括:至少安装有一个用于实现用户所期望的处理的软件的多个终端装置、以及针对来自终端装置的询问提供信息的多个数据库41、42、43、44。多个数据库41、42、43、44中分别存储有文档信息。终端装置是平板终端21、个人计算机22等计算机装置。
[0036]
分析装置10由装置主体11和个人计算机12构成,该装置主体11通过机械动作来执行分析,该个人计算机12安装有用于控制装置主体11的动作的控制软件、用于对通过由装置主体11执行分析而得到的数据进行处理的处理软件等。终端装置21、22及个人计算机12与数据库41、42、43、44经由因特网20来连接。在分析装置10的个人计算机12的存储装置中保存分析装置部10的分析数据。个人计算机12能够经由因特网20与终端装置21、22及解析装置50之间发送和接收数据。解析装置50的实体是个人计算机或工作站等计算机装置。解析装置50执行用于基于由分析装置10获取到的试样的分析数据而在用户检索至少一个数据库后向该用户提供术语的解析,该术语帮助取得解读所述分析数据所需的文档信息。
[0037]
能够借助因特网20利用的数据库使用与能够用分析装置10分析的试样的种类相应的各种数据库。例如,作为在生物体试样的情况下利用的数据库,存在基因数据库、蛋白质信息数据库、医药品信息数据库、医学文献数据库等。在医学文献数据库中例如存在由美国国家医学图书馆(national library of medicine:nlm)管理的医学文献数据库
medline。存储于数据库的文档信息中包含论文、书籍、辞典、医药品附加文档等。
[0038]
作为分析装置10,能够使用lc(液相色谱仪)、gc(气相色谱仪)等色谱装置以及在色谱装置中组合了质谱仪而得到的lc/ms和gc/ms等色谱质谱分析装置。在分析装置10是色谱质谱分析装置的情况下,获取色谱、质谱等的图表来作为分析数据。也可以获取表示图表上的各点的坐标数据(例如作为保持时间和信号强度的组、质荷比m/z值和信号强度的组等的数值数据)来作为分析数据。总之,只要能够基于分析数据来确定试样中含有的解析对象物的种类、量,则可以是任意形式的分析数据。另外,向分析装置10提供的试样有液体试样、气体试样。作为液体试样,存在包括人在内的动物的尿、血液以及破坏生物体的细胞构造而得到的粗提取物等生物体试样。在试样是生物体试样的情况下,解析对象物是代谢物、蛋白质、化合物等。
[0039]
[解析装置的结构]
[0040]
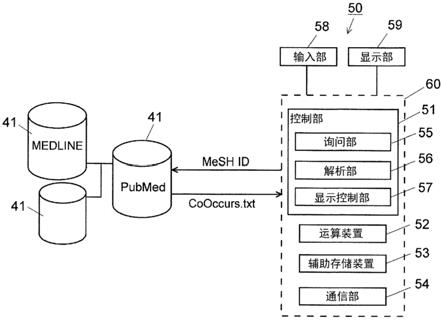
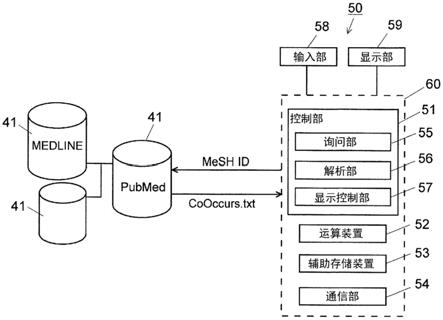
图4是示出解析装置50的概要性结构的框图。
[0041]
解析装置50具备装置主体60以及与该装置主体60连接的输入部58和显示部59。装置主体60具备控制部51、用于执行各种运算处理的cpu等运算装置52、存储解析结果等的辅助存储装置53、以及经由因特网20与数据库41之间发送和接收数据的通信部54。在图4中,作为数据库41,示出了medline以及收录在medline中的文献的检索引擎即pubmed。控制部51具备询问部55、解析部56、显示控制部57来作为功能块。另外,控制部51控制运算装置52、辅助存储装置53、通信部54的动作。
[0042]
解析装置50的实体是个人计算机,通过在该计算机上执行预先安装在该个人计算机中的专用软件来实现控制部51的各功能。输入部58是附设于计算机的键盘、指示设备(鼠标等)。显示部59是计算机的显示监视器。辅助存储装置53是hdd(hard disk drive:硬盘驱动器)或ssd(solid state drive:固态硬盘)等。存储器51、运算装置52、辅助存储装置53及通信部54与控制部51通过内部总线来连接。
[0043]
[由解析装置进行的解析处理]
[0044]
接着,对由解析装置50执行的解析处理进行说明。
[0045]
[解析用数据的制作]
[0046]
向解析装置50输入用于确定被提供到分析装置10的试样中含有的物质中的成为该解析装置50的解析对象的物质(解析对象物)的信息,来作为解析用数据。因而,根据由分析装置10获取到的分析数据的形式,在该分析数据直接成为解析用数据的情况下有时需要对分析数据进行加工或者从该分析数据中提取解析对象物来制作解析用数据的处理。图2是示出根据分析装置10的分析数据来制作解析用数据的处理的一例的说明图。在本实施方式中,解析用数据的制作处理由安装有该处理所需的规定的软件的终端装置进行。因而,在进行解析用数据的制作处理之前,用户将分析数据从分析装置10向终端装置发送。
[0047]
此外,在此举出根据利用lc/ms分析出芽酵母的细胞提取液而得到的数据来制作解析用数据的处理为例来进行说明。出芽酵母的细胞提取液是将野生株(wt)、敲除了参与出芽酵母的代谢的特定基因而得到的突变株(δ1)、与突变株(δ1)不同的敲除了参与出芽酵母的代谢的特定基因而得到的突变株(δ2)分别在相同条件下进行培养之后破坏细胞而得到的粗提取液。分析数据是为了比较出芽酵母的各株的代谢物而通过在同一分析条件下利用lc/ms分析这些细胞提取液而得到的数据。典型的是色谱、质谱,但也可以是由保持时
间和信号强度的组构成的数值数据、由m/z值和信号强度的组构成的数值数据。
[0048]
在lc中,根据柱的性质和洗脱条件来决定试样中的成分的保持时间(rt)。如果作为出芽酵母的代谢物已知的物质的保持时间是已知的,则能够根据针对出芽酵母的各株的细胞提取液而得到的色谱的峰位置的保持时间来鉴定各细胞提取液中含有的代谢物。即使无法根据色谱的保持时间来鉴定代谢物,也能够通过将预先计算并求出的已知的代谢物的m/z的理论值与质谱的峰的m/z值进行对比来鉴定各细胞提取液中含有的代谢物。另外,能够根据色谱的各峰的面积(高度)来计算各细胞提取液中含有的代谢物的量。因而,通过将针对野生株(wt)、突变株(δ1)以及突变株(δ2)分别得到的色谱、质谱进行比较,从而能够选出在野生株(wt)与突变株(δ1)或突变株(δ2)之间细胞提取液中含有的量不同的代谢物、或者选出三种株中共同大量地含有的代谢物等,选出满足特定的条件的代谢物。在解析用数据中包含所选出的一种或多种代谢物的名称。
[0049]
也可以通过由用户手动地选择例如色谱上的峰来进行选出满足特定的条件的代谢物的作业。另外,也可以根据使用规定的解析工具对分析数据进行解析而得到的结果来自动或手动地选出满足特定的条件的代谢物。
[0050]
在视觉识别野生株(wt)和突变株(δ1)(或突变株(δ2))的色谱且能够判断为在野生株与突变株之间峰面积明显不同的情况下,用户能够手动地选出该峰。当峰被选出时,终端装置确定与该峰对应的代谢物。
[0051]
作为所述解析工具,能够列举统计工具31、制图工具32。统计工具31是使用多变量解析等统计方法,根据与多个变量有关的数据来分析这些变量间的相互关联的工具。通过使用统计工具31,从而能够自动地选出例如与野生株(wt)相比在突变株(δ1)(或突变株(δ2))之间存在显著性差异的代谢物。
[0052]
制图工具32是用于制作将代谢途径图表化后的代谢图的工具。通过使用制图工具32,从而能够制作编入了例如野生株(wt)、突变株(δ1)以及突变株(δ2)的各细胞提取液中含有的代谢物的定量值的代谢图,来使通过敲除了特定基因而产生的各代谢物的量的变化可视化。
[0053]
图3是示出代谢图的显示例的图。在该显示例中示出了表示在tca循环(tricarboxylic acid cycle:三羧酸循环)的各反应中产生的代谢物的名称以及各代谢物的野生株(wt)、突变株(δ1)、突变株(δ2)的定量值的柱状图。柱状图从纸面左侧起依次排列地示出了野生株(wt)、突变株(δ1)、突变株(δ2)的定量值。此外,关于lc的柱的性质,对于无法检测的代谢物,图表栏为空栏。在该显示例中,通过图表来表示由于野生株与突变株的差异引起的各代谢物的量的变化。因而,用户能够一边观察tca循环上的图表,一边手动地选出例如与野生株(wt)相比突变株(δ2)中的量明显减少的代谢物。
[0054]
在图3的代谢图中仅显示了tca循环的代谢物的名称,但也可以同时显示对代谢物之间的反应进行催化的酶、与反应有关系的基因、蛋白质等的名称。另外,用节点和边缘来表示代谢图上的代谢物、与代谢有关的催化剂、基因、蛋白质等的关联性,也能够通过利用节点提取工具33提取节点来选出满足特定的条件的代谢物、催化剂、基因、蛋白质等。在该情况下,除了代谢物的名称以外或者代替代谢物的名称而在解析用数据中包含催化剂、基因、蛋白质等的名称。
[0055]
在制图工具32中,除了具有输出图3那样的代谢图的工具以外,还具有被称为网络
可视化工具的工具,该网络可视化工具用于进行网络型的知识的提取和可视化。网络可视化工具通过在用节点和边缘示出代谢物、催化剂、基因、蛋白质等的相关性的网络中组合对分析数据进行统计处理而得到的代谢物的量的增减等信息,从而能够将在网络中占据相对重要的位置的节点和边缘是哪一个、处于何处可视化。对于这样的网络,也能够通过利用节点提取工具33提取节点来选出满足特定的条件的代谢物、催化剂、基因、蛋白质等。
[0056]
在终端装置中,当通过上述的方法选出一个或多个代谢物、催化剂、基因、蛋白质等解析对象物时,将它们的名称设定为解析用数据。所设定的解析用数据经由因特网20从终端装置被发送到解析装置50。另外,在解析用数据中也可以包含解析对象物的名称以及为了识别该解析对象物而预先赋予的id。
[0057]
例如,在为了根据由分析装置10得到的图表(色谱、质谱等)来鉴定代谢物等而参照的代谢物数据库中,对各代谢物赋予了用于识别代谢物的id(代谢物id)。另外,在作为酵母的基因数据库的sgd(saccharomyces genome database:酵母基因组数据库)中,对各基因赋予了用于识别基因的id(基因id)。因而,在解析对象物是代谢物、基因的情况下,能够使它们的名称以及代谢物id、基因id包含在解析用数据中。另外,在sgd中,对该基因赋予了基因id以及与该基因关联的pmid(pubmed分配给各文献的id)。使对被分配了pmid的文献赋予的meshid(对用于管理存储在medline中的文档的mesh术语赋予的id)与该pmid相关联,因此在解析对象物是酵母的基因的情况下,能够使其名称以及基因id、pmid、meshid包含在解析用数据中。
[0058]
[解析装置中的处理]
[0059]
接着,关于解析装置50中的处理,举出将medline用作文献数据库的情况为例来进行说明。
[0060]
(实施例1)
[0061]
图5是示出解析装置50的处理的一例的流程图。
[0062]
从终端装置发送来的解析用数据经由解析装置50的通信部54被输入到控制部51。控制部51参照该解析用数据来获取用于确定解析对象物的识别信息(相当于本发明的第一识别信息)(步骤101)。因而,在本实施例中,控制部51作为信息获取单元发挥功能。
[0063]
在将medline用作文献数据库的情况下,在步骤101中获取到的识别信息是meshid。因而,在利用medline的情况下在解析用数据中包含了meshid时,控制部51从该解析用数据中获取meshid。另一方面,在解析用数据中不包含meshid的情况下,在解析装置50中预先安装了用于将解析对象物的名称、解析对象物的id(代谢物id、基因id等)变换为meshid的id变换工具(未图示)。然后,控制部51利用该id变换工具将从解析用数据中获取到的解析对象物的名称或id变换为meshid。或者,也可以是,在控制部51的控制下,询问部55询问pubmed来获取与从解析用数据中获取到的解析对象物的名称或id对应的meshid。
[0064]
若针对试样中含有的所有解析对象物获取识别信息(meshid),接着,询问部55询问pubmed(数据库)来获取与解析对象物的meshid关联的信息即共现数据(步骤102)。具体地说,所有解析对象物的meshid的集合(以下称为meshid组。参照图6)经由通信部54从解析装置50输出后经由因特网被发送到pubmed侧。pubmed当接收到meshid组时,从作为能够经由pubmed利用的服务之一的、medline co
‑
occurrence(mrcoc)(https://ii.nlm.nih.gov/mrcoc.shtml,[平成31年4月25日检索])取得meshid组中包含的所有meshid的、被存储在
medline中的文献中的共现数据,并将该共现数据发送到解析装置50。共现数据由在存储于medline的文献中将与meshid组中包含的所有mesh术语同时出现的mesh术语及其meshid以及共现频率的值相关联地记述而得到的文本文件(cooccurs.txt)构成。
[0065]
当解析装置50获取从pubmed发送来的共现数据时(步骤103),解析部56对共现数据进行关联分析(步骤104)。在关联分析中,按照采用了置信度(confidence)、支持度(support)以及提升度(lift)中的至少一方的规则,从共现数据中提取解析对象物的关联术语。因而,在该实施例中,pubmed和解析部56相当于本发明的提取单元。
[0066]
在此,关联术语是指与试样中含有的所有解析对象物共同关联的术语,作为具体例,能够列举表示解析对象物中共同的属性(种类、归属等)的术语,在解析对象物是某种代谢途径的代谢物的情况下,能够列举该代谢途径的名称、参与代谢途径的酶、基因等的名称,在解析对象物是与某种特定疾病有关的原因物质的情况下,能够列举该疾病、解析对象物以外的原因物质的名称等。此外,在以下的说明中,设为提取meshid或mesh术语作为关联术语。
[0067]
显示控制部57将关联分析的结果显示在显示部59中(步骤105)。因而,在本实施例中,显示控制部57相当于呈现单元。图7是显示在显示部59中的内容的一例。在该例子中,按照采用了提升度的规则进行了关联分析的结果是,提取出的关联术语被显示在显示部59中。具体地说,使提升度为30(%)以上的meshid、mesh术语的组与提升度一起以按提升度从高到低的顺序排列的方式显示。各组的提升度是与meshid组中包含的四个meshid(参照图6)的各meshid进行组合而计算出的提升度的平均值。
[0068]
在关联分析中,不仅可以设定提升度的规则而且也可以设定组合了置信度、支持度的规则(推荐规则)来限制要提取的meshid。另外,在显示部59中也可以不显示提升度(也就是说,显示meshid和mesh术语的组),也可以仅显示mesh术语或仅显示meshid。
[0069]
用户能够以显示在显示部59中的mesh术语等的列表为参考来检索medline等文献数据库,从而限制对分析数据的解析有用的文献。例如,如果在pubmed的关键词检索中仅输入图6所示的meshid组中包含的mesh术语,则在大量地提取出与检索条件一致的文献的情况下,通过从显示在显示部59中的mesh术语等的列表中将适当的mesh术语添加到关键词,从而能够限制文献。
[0070]
容易想象的是,在对例如出芽酵母的代谢物的分析数据进行解读的情况下,针对代谢途径记述的文献将成为参考。在该情况下,根据用户的兴趣在于某种特定的代谢物,或介入代谢反应的酶的功能,或由代谢异常引起的疾病等中的任一方,限制用的mesh术语不同。与此相对地,在本实施例中,使用关联分析的方法根据与解析对象物的关联性来提取出多个mesh术语并呈现给用户,该mesh术语为用于检索文献数据库来提取文献的关键词。
[0071]
因而,例如在用户对丙酮酸代谢的机制具有强烈的兴趣的情况下,能够选择图7中示出的mesh术语中与丙酮酸代谢有关的mesh术语“丙酮酸代谢障碍,先天性,”并将该mesh术语添加到pubmed的限制检索中。由此,能够高效地提取先天性代谢异常中的与丙酮酸代谢有关的文献。
[0072]
(实施例2)
[0073]
图8是示出解析装置50的处理的另一例的流程图。
[0074]
解析装置50当经由通信部54接收到解析用数据时,控制部51从该解析用数据获取
用于确定解析对象物的识别信息(步骤111)。在该实施例中,与实施例1同样地,也设为控制部51获取的识别信息是meshid。在图9中示出了在本实施例中获取到的meshid的集合。以下,将图9中示出的meshid的集合称为“第一meshid组”。
[0075]
接着,控制部51受理由用户经由输入部58进行的第二识别信息的输入(步骤112)。第二识别信息是用户根据测定试样中含有的解析对象物的目的、试样的种类等来适当地选择出的术语,能够列举疾病、生物种、脏器、器官、人种等术语。在本实施例中,图9所示的“第二meshid组”相当于第二识别信息。用户所输入的字符串也可以是meshid和mesh术语中的任一方。在图9所示的例子中,设为输入了作为乳腺癌的mesh术语的“乳腺癌”。此外,表示“癌症”的术语具有“癌症(cancer)”、“肿瘤(tumor)”、“赘生物(neoplasm)”,但在mesh的索引典中,通过对处理癌症的论文赋予mesh术语“赘生物(neoplasms)”来使表述统一。因而,也可以是,在由用户输入了并非mesh术语的术语来作为第二识别信息的情况下,例如询问部55询问pubmed来获取对应的mesh术语或meshid。另外,也可以是,在接下来的工序中从询问部55接收到询问的pubmed将该第二识别信息变换为medhid。
[0076]
当控制部51获取到第一识别信息和第二识别信息时,接着,询问部55询问pubmed(数据库),来获取与第一识别信息和第二识别信息中包含的meshid关联的术语(步骤113)。在该实施例中,与实施例1同样地,pubmed也将从mrcoc取得的共现数据发送到解析部56。
[0077]
当从数据库41获取到共现数据时(步骤114),解析部56对共现数据进行关联分析(步骤115)。关联分析的内容与实施例1相同,因此省略说明。在该实施例中,与实施例1不同,第一meshid组和第二meshid组被发送到pubmed,因此从pubmed提供的共现数据成为第一meshid组和第二meshid组中共享的共现数据。具体地说,在medline中收录的文献中的与作为第二识别信息的乳腺癌关联的文献中,与第一meshid组中包含的mesh术语同时出现的mesh术语包含在共现数据中。
[0078]
显示控制部57将关联分析的结果显示在显示部59中(步骤116)。图10是显示在显示部59中的内容的一例。在该例子中,使提升度15(%)以上的meshid、mesh术语的组与提升度一起以按提升度从高到低的顺序排列的方式显示。
[0079]
在该实施例中,由于在共现数据中反映出了想要得到乳腺癌关联的信息这一用户侧的要求,因此如图10所示,关联分析的结果是在显示于显示部59的信息中包含与乳腺癌的关联性高的信息。例如,图10中示出的列表的从上数第二个mesh术语“丙醇二酸盐[酯]”包含在报告了将源自人乳腺癌的细胞株用作丙酮酸代谢的抑制剂的研究成果的文献中。因此,即使是对药物不熟悉的用户,也能够知晓抑制剂的名称。
[0080]
这样,在本实施例中,用户能够输入第二识别信息,由此能够预先排除提取解析对象物的关联术语所不需要的信息。
[0081]
[变形例]
[0082]
在上述实施方式中,由一台个人计算机构成了解析装置50,但解析装置50的功能块的一部分也可以搭载于经由通信线路与解析装置50连接的其它个人计算机、平板终端等终端装置。另外,作为解析装置50的各功能块的实体的软件也可以被存储在经由通信线路与解析装置50连接的应用服务器中,并根据需要将软件从应用服务器下载到解析装置50。
[0083]
输入单元不仅可以使用解析装置50的输入部58,而且也可以使用经由因特网20连接的终端装置的输入设备。执行在上述的实施方式中说明的解析方法的计算机在进行用于
解释分析数据的信息收集时显示推荐的关键词或id来提出超出了用户的设想范围的术语。据此,若从其它观点来看,则所述计算机也是信息收集辅助装置。
[0084]
在该实施方式中,在获取共现数据的过程中利用了在pubmed上提供的mrcoc,但也可以使解析装置50具有共现数据的生成功能。通过采用与文档信息的每个数据库相匹配的共现性的指标(例如,戴斯(dice)系数、杰卡德(jaccard)系数、辛普森(simpson)系数、置信度(confidence)等)生成共现数据,从而能够提高成为检索的限制候选的关联术语的有用性。
[0085]
在上述的实施方式中,用解析部56进行了关联分析,但分析方法并不限定于此。关联分析是从庞大的数据中挖掘数据间的相关性或模式的数据挖掘的方法中适于关联发现的分析方法。在该实施方式中,对于询问数据库的术语,想从文献所使用的术语中找到相关性高的术语,因此采用了关联分析。
[0086]
在上述的实施方式中,将pubmed用作了文档信息的数据库,但也可以利用例如出版社等管理的文献信息提供服务等其它数据库。在该情况下,在预处理中,按照在该数据库中对文献类别进行分类所使用的索引典,通过关键词和id来确定分析数据中的生物体试样的含有物。另外,数据库不仅是能够经由因特网利用的现有的数据库,也可以经由任意的通信线路利用独自构建的数据库。
[0087]
在上述的实施方式中,设为在显示部59中显示关联分析的结果的结构,但既可以打印到纸张上,也可以以声音的形式输出。
[0088]
[方式]
[0089]
本领域技术人员理解上述的例示性的实施方式是以下方式的具体例。
[0090]
(第一项)本发明的第一方式所涉及的解析装置具备:信息获取单元,其从使用分析装置测定试样中含有的解析对象物而得到的结果中获取用于确定该解析对象物的信息即第一识别信息;提取单元,其基于由所述信息获取单元获取到的所述第一识别信息,来从存储有文档信息的数据库中提取与所述解析对象物关联的术语即关联术语;以及呈现单元,其向用户呈现由所述提取单元获取到的所述关联术语。
[0091]
(第八项)本发明的第二方式所涉及的解析方法包括以下步骤:获取使用分析装置测定试样中含有的解析对象物而得到的结果;从测定所述解析对象物而得到的结果中获取用于确定该解析对象物的第一识别信息;基于所述第一识别信息来从存储有文档信息的数据库中提取与所述解析对象物关联的术语即关联术语;以及呈现步骤,向用户呈现所述关联术语。
[0092]
根据第一项的解析装置和第八项的解析方法,使用从试样中含有的解析对象物的测定结果获取到的、用于确定该解析对象物的第一识别信息,来从存储有文档信息的数据库中提取所述解析对象物的关联术语,并向用户呈现该术语。向用户呈现的关联术语既可以是一个也可以是多个。用户能够使用第一识别信息和关联术语容易地从数据库中找出对于理解解析对象物的测定结果而言有用的文档信息。
[0093]
(第二项)在第一项所记载的解析装置中,所述信息获取单元针对多个解析对象物获取与各解析对象物对应的第一识别信息,所述提取单元提取与所述多个解析对象物共同关联的关联术语。
[0094]
(第九项)在第八项所记载的解析方法中,获取所述信息的步骤是针对多个解析对
象物获取与各解析对象物对应的第一识别信息的步骤,
[0095]
所述提取的步骤是提取与多个所述第一识别信息共同关联的关联术语的步骤。
[0096]
根据第二项的解析装置和第九项的解析方法,用户能够容易地从数据库中找出与多个解析对象物共同关联的文档信息。例如,质谱分析装置能够一次性地统一测定试样中含有的多个解析对象物。在第二项的解析装置和第九项的解析方法中,能够如质谱分析装置那样向用户呈现对于理解能够同时测定多个解析对象物的分析装置的测定结果而言有用的文件信息。
[0097]
(第三项)在第一项所记载的解析装置中,还具备受理单元,所述受理单元受理来自用户的输入,所述信息获取单元获取所述受理单元受理到的第二识别信息,所述提取单元基于所述第一识别信息和所述第二识别信息这两者来提取所述关联术语。
[0098]
(第十项)在第八项所记载的解析方法中,还包括以下步骤:受理步骤,受理来自用户的第二识别信息的输入;以及获取在所述受理步骤中受理到的第二识别信息,在所述提取的步骤中,基于所述第一识别信息和所述第二识别信息这两者来提取所述关联术语。
[0099]
在第三项的解析装置和第十项的解析方法中,第二识别信息是指为了从数据库中找出对于理解解析对象物的测定结果而言有用的文档信息所需要的信息,该第二识别信息反映了测定解析对象物的目的、研究领域等用户的意思。因而,在第三项的解析装置中,能够限制在用户感兴趣的范围来提取解析对象物的关联术语。
[0100]
(第五项)在第一项所记载的解析装置中,所述提取单元使用数据挖掘的分析方法来提取所述关联术语。
[0101]
(第十二项)在第八项所记载的解析方法中,所述提取的步骤是使用数据挖掘的分析方法来提取所述关联术语的步骤。
[0102]
根据第五项的解析装置和第十二项的解析方法,通过使用数据挖掘的分析方法,从而能够向用户呈现超出了用户设想的范围的、用于获取有用的文档信息的关联术语。
[0103]
(第六项)在第五项所记载的解析装置中,所述提取单元使用关联分析来提取所述关联术语。
[0104]
(第十三项)在第十二项所记载的解析方法中,所述提取的步骤是使用关联分析来提取所述关联术语的步骤。
[0105]
(第七项)在第六项所记载的解析装置中,所述提取单元根据采用了关联分析中的置信度、支持度以及提升度中的至少一方的规则来提取所述关联术语。
[0106]
(第十四项)在第十三项所记载的解析方法中,所述提取的步骤是根据采用了关联分析中的置信度、支持度以及提升度中的至少一方的规则来提取所述关联术语的步骤。
[0107]
(第十五项)一种程序,用于使计算机执行以下处理:获取使用分析装置测定试样中含有的解析对象物而得到的结果;从所述解析对象物的测定结果中获取用于确定所述解析对象物的信息即第一识别信息;基于所述第一识别信息,来从存储有文档信息的数据库中提取与所述解析对象物关联的术语即关联术语;以及向用户呈现所述关联术语。
[0108]
(第十六项)一种计算机可读取的(非临时性的)存储介质,其记录有用于使计算机执行以下处理的程序:获取使用分析装置测定试样中含有的解析对象物而得到的结果;从所述解析对象物的测定结果中获取用于确定所述解析对象物的信息即第一识别信息;基于所述第一识别信息,来从存储有文档信息的数据库中提取与所述解析对象物关联的术语即
关联术语;以及向用户呈现所述关联术语。
[0109]
此外,上述的记载用于说明本发明的实施方式,并不限定本发明。
[0110]
附图标记说明
[0111]
10:分析装置;11:装置主体;12:个人计算机;20:因特网;21:平板终端;22:个人计算机;31:统计工具;32:制图工具;33:节点提取工具;41:数据库;42:数据库;43:数据库;44:数据库;50:解析装置;51:控制部;52:运算装置;53:辅助存储装置;54:通信部;55:询问部;56:解析部;57:显示控制部;58:输入部;59:显示部;60:装置主体。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。