1.本发明属于自动化疲劳检测技术领域,具体涉及基于关键点检测和头部姿态的疲劳状态检测方法及系统。
背景技术:
2.计算机视觉领域的人脸检测和头部姿态估计是指检测图像中的所有人脸,并估计每个人脸可以表示三个方向角:偏航(yaw)、俯仰(pitch)和滚转(roll)。根据头部姿势判断人们的动机、意图,在提供线索和凝视方面都有广泛的应用,例如人类行为分析和凝视估计。尽管人脸检测和姿态估计分别取得了巨大的进步,但实现一个复杂环境下具有良好实时性和鲁棒性的多任务框架仍然是一项艰巨的任务。目前解决人脸检测和头部姿态估计一般采用卷积神经网络(cnn),可以在一系列复杂的计算机视觉任务中取得了非凡的成功如图像分类、人脸识别和物体检测。为了同时解决人脸检测和头部姿态估计,利用人脸检测网络检测出人脸中的所有人脸图像,然后使用头部姿态估计网络进行估计每张脸的姿势,问题是因为两个网络是分开的,人脸检测网络的不准确会影响头部姿态估计的结果。此外,这样的框架不利于两个任务内在相关性促进彼此的表现。同时复杂的卷积神经网络也会影响到头部姿态估计的实时性。常见的头部姿态估计系统首先使用人脸检测网络检测出人脸,然后使用头部姿态估计网络来估计每个人脸的姿态,由于两个网络是分开的,使用的数据集不同,头部姿态估计的性能会受到人脸检测网络的影响。同时常见的卷积神经网络模型较大,预测时难以达到实时性的效果。
技术实现要素:
3.本发明所要解决的技术问题是如何提高自动化人脸疲劳状态检测的实时性,本发明的目的在于提供一种基于关键点检测和头部姿态的疲劳状态检测方法及系统,结合人脸关键点检测和头部姿态估计两个任务的学习目标训练的网络在优化过程中,由于两者之间的相关性可以使用同一个网络,采用主干网络为深度可分离卷积网络的mmc多任务预测模型,将两个任务放在同一个网络中同时进行,可以大幅度的减少需要的参数量和运算量,从而提高了模型的检测速度,进而达到实时的效果。
4.本发明通过下述技术方案实现:
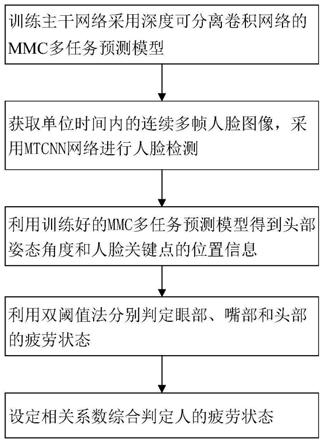
5.一方面,本发明提供一种基于关键点检测和头部姿态的疲劳状态检测方法,包括以下步骤:
6.构建并训练主干网络采用深度可分离卷积网络的mmc多任务预测模型,得到训练好的mmc多任务预测模型;
7.获取单位时间内的若干帧人脸图像,每一帧作为一张图像,采用mtcnn网络检测每张图像的人脸位置并裁剪出头部图像;
8.将头部图像输入训练好的mmc多任务预测模型中,得到头部姿态角度和人脸关键点的位置信息;
9.根据每张图像的头部姿态角度,利用双阈值法判定若干张图像中头部的疲劳状态,同时根据每张图像的人脸关键点中眼部和嘴部的位置信息,利用双阈值法分别判定若干张图像中眼部和嘴部的疲劳状态;
10.根据头部、眼部和嘴部的疲劳状态综合判定人的疲劳状态。
11.在对人的疲劳状态进行检测时,一般基于人脸部分的状态来判断人的疲劳状态,然而单一方法分别获取眼部、嘴部及头部的特征较为繁杂且效果一般,常见的深度卷积神经网络模型又难以达到实时性且较少关注图像空间信息的作用,并且在检测得到眼部、嘴部及头部的特征后还需要建立合适算法判定是否处于疲劳状态,由此构成的卷积神经网络模型较大,预测时难以达到实时性的效果,因此,本发明中考虑到由于人脸检测和头部姿态估计都是与人脸相关的任务,都依赖于潜在的面部特征,因此在训练和预测时可以使用同一个网络同时进行人脸关键点检测和头部姿态估计任务,并且使用同一个网络时,头部姿态信息可以提高人脸关键点定位准确率,反过来人脸关键点定位也能够反映头部姿态的信息,两者之间有着较强的相关性,这种相关性对两个任务都有积极的作用,先采用mtcnn网络检测人脸位置并裁剪出头部图像,将经过预处理的头部图像输入mmc多任务预测模型,得到头部姿态角度和眼睛、嘴巴等人脸关键点的位置信息,在预测过程中,采用双阈值法确定每个部分的疲劳状态,将回归得到的头部姿态角度来判定头部状态,将回归得到人脸关键点中眼部和嘴部的部分特征点坐标分别用于判定眼部和嘴部状态最后综合判定人的疲劳状态,模型的主干网络采用的是深度可分离卷积网络的架构,这样在一个网络中同时实现两个任务,将参数量和运算量大幅度的减少,从而提高了模型的检测速度,能达到实时的效果。
12.进一步地,训练mmc多任务预测模型时采用300w_lp数据集进行训练,300w_lp数据集具有人脸关键点坐标和头部姿态角度标签,在利用300w_lp数据集对mmc多任务预测模型进行训练前,先对数据集中的图像进行预处理,包括:
13.根据数据集中的人脸关键点坐标裁剪图像中多余的背景部分,将裁剪后的图像大小统一为224
ⅹ
224尺寸,并对统一尺寸后的图像进行灰度化处理和归一化处理。
14.进一步地,训练mmc多任务预测模型的过程包括两个任务:
15.人脸关键点检测任务用于根据图像中人脸关键点坐标,定位脸部特征点的位置,使用l2损失函数lossa衡量特征点预测坐标值和真实坐标值之间的差值,回归得到人脸关键点的位置信息,
16.头部估计任务用于根据图像中的头部姿态角度标签,预测出图像中头部在yaw、pitch、roll三个方向上的角度,损失函数为:
[0017][0018]
其中,为yaw、pitch、roll三个方向上头部姿态角度的估计结果,(x1,x2,x3)为三个方向上的头部姿态角度标签;
[0019]
以mmc多任务预测模型的总损失为学习目标进行训练,总损失为人脸关键点检测任务和头部估计任务的损失和:
[0020]
loss=lossa ηlossb[0021]
其中,η为任务分配权重设置为1。
[0022]
进一步地,得到头部姿态角度和人脸关键点的位置信息的过程为:
[0023]
利用mmc多任务预测模型的主干网络对输入的头部图像进行特征提取并融合,得到特征图;所述主干网络采用改进的轻量化卷积mobilenet-v2网络结构,
[0024]
同时利用嵌入主干网络中的ca注意力模块将特征图沿水平方向和垂直方向分别进行池化操作,得到特征图的位置信息;
[0025]
根据特征图的位置信息,分别利用主干网络后的两个全连接层,回归出头部姿态角度和人脸关键点的位置信息。
[0026]
进一步地,改进的轻量化卷积mobilenet-v2网络结构结构分别采用1
ⅹ
1、3
ⅹ
3和5
ⅹ
5的卷积核对输入的头部图像进行特征提取,并将卷积步幅设置为1,并将每个卷积核对应的pad分别设置为0,1,2,改进的轻量化卷积mobilenet-v2网络结构结构大小为4m。
[0027]
进一步地,对于获取到的单位时间内的若干帧连续的人脸图像,利用双阈值法判定各个部分的疲劳状态的过程为:
[0028]
判断每张图像头部的疲劳状态:
[0029]
根据每张图像的头部姿态角度,判断低头时头部姿态角度的pitch姿态角是否大于30
°
,若大于30
°
则判断该张图像头部为疲劳状态;若头部为疲劳状态的图像占所有图像的比例超过30%,则判定头部处于疲劳状态;
[0030]
判断每张图像眼部的疲劳状态:
[0031]
根据每张图像的眼部关键点的位置信息,计算眼部纵横比,判断眼部纵横比是否小于0.2,若小于,则判断该张图像眼部为疲劳状态;若眼部为疲劳状态的图像占所有图像的比例超过40%,则判定眼部处于疲劳状态;
[0032]
判断每张图像嘴部的疲劳状态:
[0033]
根据每张图像的嘴部关键点的位置信息,计算嘴部纵横比,判断嘴部纵横比是否大于0.3,若大于,则判断该张图像嘴部为疲劳状态;若嘴部为疲劳状态的图像占所有图像的比例超过40%,则判定嘴部处于疲劳状态。
[0034]
进一步地,根据头部、眼部和嘴部的疲劳状态对人的疲劳状态的影响权重,对每个部分的疲劳状态设定相关系数综合判定人的疲劳状态z:
[0035]
z=αz
eye
βz
mouth
λz
head
[0036]
其中,z
eye
每表示眼部的疲劳状态,z
mouth
表示嘴部的疲劳状态,z
head
表示头部的疲劳状态,将相关系统α、β、λ分别设为0.2、0.3、0.5;
[0037]
当z大于等于0.5时,则判断人处于疲劳状态。
[0038]
另一方面,本发明提供一种基于关键点检测和头部姿态的疲劳状态检测系统,包括:
[0039]
模型训练模块,用于构建并训练mmc多任务预测模型,得到训练好的mmc多任务预测模型;
[0040]
人脸位置检测模块,用于根据获取到的单位时间内的若干帧人脸图像,以每一帧作为一张图像,采用mtcnn网络检测每张图像的人脸位置并裁剪出头部图像;
[0041]
并行预测模块,用于将头部图像输入训练好的mmc多任务预测模型中,得到头部姿态角度和人脸关键点的位置信息;
[0042]
局部状态检测模块,用于根据每张图像的头部姿态角度,利用双阈值法判定若干
张图像中头部的疲劳状态,同时根据每张图像的人脸关键点中眼部和嘴部的位置信息,利用双阈值法分别判定若干张图像中眼部和嘴部的疲劳状态;
[0043]
综合疲劳状态检测模块,用于根据头部、眼部和嘴部的疲劳状态综合判定人的疲劳状态。
[0044]
进一步地,所述mmc多任务预测模型包括主干网络和分别用于回归头部姿态角度和人脸关键点的位置信息的两个全连接层,主干网络采用改进的轻量化卷积mobilenet-v2网络结构,同时在主干网络中嵌入ca注意力模块,
[0045]
主干网络用于对输入的头部图像进行特征提取并融合,得到特征图,
[0046]
ca注意力模块用于将特征图沿水平方向和垂直方向分别进行池化操作,得到特征图的位置信息。
[0047]
进一步地,改进的轻量化卷积mobilenet-v2网络结构结构分别采用1
ⅹ
1、3
ⅹ
3和5
ⅹ
5的卷积核对输入的头部图像进行特征提取,并将卷积步幅设置为1,并将每个卷积核对应的pad分别设置为0,1,2,改进的轻量化卷积mobilenet-v2网络结构结构大小为4m。
[0048]
本发明与现有技术相比,具有如下的优点和有益效果:
[0049]
本发明通过利用深度可分离卷积网络作为mmc多任务预测模型的主干网络,并根据人脸关键点检测和头部姿态估计的任务相关性,使用同一个网络对两个任务进行训练和预测,可以大幅度的减少需要的参数量和运算量,从而提高了模型的检测速度,进而达到实时的效果;
[0050]
本发明利用改进的轻量化卷积mobilenet-v2网络结构作为主干网络,一方面在主干网络的第一层采用不同尺度卷积提取图片的特征并进行融合,通过多个不同大小的卷积核得到不同的感受野,考虑到人脸中眼睛、鼻子、嘴巴等部位的相对位置对姿态角度的影响,获得更大的感受野可以更好描述这种相关性,从而使得模型在对两个任务进行训练和预测时,速度更快,实时性高,同时在主干网络中嵌入了ca注意力模块,能够在空间上捕捉精确的位置信息,从而实现了在达到实时性的同时还关注到了图像空间信息的作用。
附图说明
[0051]
为了更清楚地说明本发明示例性实施方式的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。在附图中:
[0052]
图1为本发明实施例1中基于人脸关键点和头部姿态的疲劳状态检测方法流程图;
[0053]
图2为本发明实施例中mmc多任务预测模型的网络结构示意图;
[0054]
图3为本发明实施例中300w_lp数据集人脸关键点位置分布图;
[0055]
图4为本发明实施例2中系统结构框图。
具体实施方式
[0056]
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
[0057]
实施例1
[0058]
如图1所示,本实施例1提供一种基于关键点检测和头部姿态的疲劳状态检测方法,包括以下步骤:
[0059]
s1、构建并训练主干网络采用深度可分离卷积网络的mmc多任务预测模型,得到训练好的mmc多任务预测模型;
[0060]
训练mmc多任务预测模型时采用300w_lp数据集进行训练,由于300w_lp数据集广泛用于面部特征识别与头部姿态分析,是常用的野外2d地标数据集,由61225头部姿态图像组成,并通过翻转扩展到122450张图像,且300w_lp数据集具有人脸关键点坐标和头部姿态角度标签,在利用300w_lp数据集对mmc多任务预测模型进行训练前,先对数据集中的图像进行预处理,包括:
[0061]
根据数据集中的人脸关键点坐标裁剪图像中多余的背景部分,有利于提升训练效果,将裁剪后的图像大小统一为224
ⅹ
224尺寸,并对统一尺寸后的图像进行灰度化处理和归一化处理。
[0062]
具体地,主干网络采用改进的轻量化卷积mobilenet-v2网络结构,整体网络结构如图2所示,在主干网络的第一层采用不同尺度卷积提取图像的特征并进行融合,通过多个不同大小的卷积核得到不同的感受野,具体地,分别采用1
ⅹ
1、3
ⅹ
3和5
ⅹ
5的卷积核替换原来单个3
ⅹ
3卷积核对输入的头部图像进行特征提取,并将卷积步幅设置为1,并将每个卷积核对应的pad分别设置为0,1,2,使得卷积后的图像可以得到相同维度的特征,可以直接拼接一起,通过这种增加网络宽度的方式能增加网络的性能,为了减少计算量,使用1
ⅹ
1卷积核来进行降维处理,在确保获得网络性能的同时减少参数量,并引入更多的非线性,提高泛化能力,采用5
ⅹ
5卷积核,获得更大的感受野。考虑到人脸中眼睛、鼻子、嘴巴等部位的相对位置对姿态角度的影响,获得更大的感受野可以更好描述这种相关性。同时在主干网络中嵌入ca注意力模块,ca注意力模块能够在空间上捕捉精确的位置信息,ca方法通过将二维全局池化操作分解为两个一维编码过程,即将全局池化操作分解为沿着输入特征图的水平方向和垂直方向分别进行池化操作,从而获得输入特征图的x、y轴相关的位置信息。在改进后的mobilenet-v2的全连接层后增加两层全连接层,fc1全连接层被用于人脸关键点检测,回归得到68个特征点的坐标,fc2全连接层被用于头部姿态估计,回归三个方向上的姿态角。这样改进的轻量化卷积mobilenet-v2网络结构结构大小为4m。在保证预测精度的同时模型更小,预测时能达到实时性。
[0063]
更加具体地,训练mmc多任务预测模型的过程中包括两个任务:
[0064]
人脸关键点检测任务用于根据图像中人脸关键点坐标,定位脸部特征点的位置,使用l2损失函数lossa衡量特征点预测坐标值和真实坐标值之间的差值,回归得到人脸关键点的位置信息;
[0065]
头部估计任务用于根据图像中的头部姿态角度标签,预测出图像中头部在yaw、pitch、roll三个方向上的角度,学习目标是回归yaw、pitch、roll三个角度来描述头部的位置,损失函数为:
[0066][0067]
其中,为yaw、pitch、roll三个方向上头部姿态角度的估计结果,(x1,x2,
x3)为三个方向上的头部姿态角度标签;
[0068]
以mmc多任务预测模型的总损失为学习目标进行训练,总损失为人脸关键点检测任务和头部估计任务的损失和:
[0069]
loss=lossa ηlossbꢀꢀ
(2)
[0070]
其中,由于人脸关键点检测和头部姿态估计都属于回归任务,故将η任务分配权重设置为1。
[0071]
s2、获取单位时间内的若干帧人脸图像,每一帧作为一张图像,采用mtcnn网络检测每张图像的人脸位置并裁剪出头部图像;
[0072]
s3、将头部图像输入训练好的mmc多任务预测模型中,得到头部姿态角度和人脸关键点的位置信息;
[0073]
具体地,得到头部姿态角度和人脸关键点的位置信息的过程为:
[0074]
利用mmc多任务预测模型的主干网络对输入的头部图像进行特征提取并融合,得到特征图;所述主干网络采用改进的轻量化卷积mobilenet-v2网络结构,
[0075]
同时利用嵌入主干网络中的ca注意力模块将特征图沿水平方向和垂直方向分别进行池化操作,得到特征图的位置信息;
[0076]
根据特征图的位置信息,分别利用主干网络后的两个全连接层,回归出头部姿态角度和人脸关键点的位置信息。
[0077]
s4、根据每张图像的头部姿态角度,利用双阈值法判定若干张图像中头部的疲劳状态,同时根据每张图像的人脸关键点中眼部和嘴部的位置信息,利用双阈值法分别判定若干张图像中眼部和嘴部的疲劳状态。采用双阈值法确定每个部分的疲劳状态,将单位时间设定为30秒,获取到30秒内的连续多帧图像,每一帧作为一张图像,通过计算每个部分所处状态帧数占单位时间总帧数比例来确定每个部分是否处于疲劳状态,例如可以设定眼睛为闭眼状态和嘴巴为打哈欠状态的视频帧数占单位时间帧数40%以上则判定为疲劳状态,设定低头情况下pitch姿态角大于30
°
的视频帧数占单位时间帧数30%以上则判定为疲劳状态,则具体地判断过程如下:
[0078]
1、判断每张图像头部的疲劳状态:
[0079]
由mmc多任务预测模型直接回归得到头部的三个欧拉角(pitch、yaw、roll),由于人在疲劳状态时,pitch的角度变化较大,为了减少计算量,可以重点关注pitch姿态角的变化,设定一定的阈值,将检测的连续多帧图像低头时的pitch姿态角大于30
°
判定为疲劳状态,则根据每张图像的头部姿态角度,判断头部姿态角度的pitch姿态角是否大于30
°
,若大于30
°
则判断该张图像头部为疲劳状态;若头部为疲劳状态的图像占所有图像的比例超过30%,则判定头部处于疲劳状态;
[0080]
2、判断每张图像眼部的疲劳状态:
[0081]
根据每张图像的眼部关键点的位置信息,眼部关键点的位置坐标能反映眼睛的张开闭合程度,在一定时间内眼睛闭合频率过高则判定为疲劳状态。通过计算眼部纵横比ear判断眼睛的睁开状态,判断眼部纵横比是否小于0.2,若小于,则判断该张图像眼部为疲劳状态;若眼部为疲劳状态的图像占所有图像的比例超过40%,则判定眼部处于疲劳状态;根据如图3展示的人脸关键点标号,使用ear计算公式如下:
[0082][0083][0084][0085]
分别对左眼和右眼的坐标进行计算,得到左眼纵横比ear
l
、右眼纵横比earr,最后综合判定眼睛纵横比ear,其中,眼睛的宽度和高度是利用欧几里得距离公式计算,当眼睛处于闭合状态时,ear值为0,初步设定阈值为0.2,小于这个值为闭眼状态,大于这个值则为睁眼状态,不同的人眼睛睁开大小情况不一样,可以根据具体的情况设定不同的阈值。
[0086]
3、判断每张图像嘴部的疲劳状态:
[0087]
同样,根据每张图像的嘴部关键点的位置信息,采用嘴巴纵横比mar来区分嘴部的状态,通过检测上嘴唇和下嘴唇之间的距离以及张嘴的时间,来判断当前状态是否打哈欠。采用内嘴唇的最高点和最低点以及嘴角的坐标来计算mar值,根据如图3展示的人脸关键点标号,计算mar值的公式为:
[0088][0089]
设定mar阈值为0.3,判断嘴部纵横比是否大于0.3,若大于,则判断该张图像嘴部为疲劳状态;若嘴部为疲劳状态的图像占所有图像的比例超过40%,则判定嘴部处于疲劳状态。s5、根据头部、眼部和嘴部的疲劳状态综合判定人的疲劳状态。
[0090]
具体地,考虑到人长时间低头则容易被认为是疲劳状态,且在打哈欠的同时人眼常常处于接近闭合状态,所以对每部分设定相关系数来综合判定人的疲劳状态,根据头部、眼部和嘴部的疲劳状态对人的疲劳状态的影响权重,对每个部分的疲劳状态设定相关系数综合判定人的疲劳状态z:
[0091]
z=αz
eye
βz
mouth
λz
head
ꢀꢀ
(7)
[0092]
其中,z
eye
每表示眼部的疲劳状态,z
mouth
表示嘴部的疲劳状态,z
head
表示头部的疲劳状态,将相关系统α、β、λ分别设为0.2、0.3、0.5;当z大于等于0.5时,则判断人处于疲劳状态。
[0093]
实施例2
[0094]
如图4所示,本实施例提供一种基于关键点检测和头部姿态的疲劳状态检测系统,包括:
[0095]
模型训练模块,用于构建并训练mmc多任务预测模型,得到训练好的mmc多任务预测模型;
[0096]
训练mmc多任务预测模型时采用300w_lp数据集进行训练,由于300w_lp数据集广泛用于面部特征识别与头部姿态分析,是常用的野外2d地标数据集,由61225头部姿态图像组成,并通过翻转扩展到122450张图像,且300w_lp数据集具有人脸关键点坐标和头部姿态角度标签,在利用300w_lp数据集对mmc多任务预测模型进行训练前,先对数据集中的图像
进行预处理,包括:
[0097]
根据数据集中的人脸关键点坐标裁剪图像中多余的背景部分,有利于提升训练效果,将裁剪后的图像大小统一为224
ⅹ
224尺寸,并对统一尺寸后的图像进行灰度化处理和归一化处理。
[0098]
所述mmc多任务预测模型包括主干网络和分别用于回归头部姿态角度和人脸关键点的位置信息的两个全连接层,fc1全连接层被用于人脸关键点检测,回归得到68个特征点的坐标,fc2全连接层被用于头部姿态估计,回归三个方向上的姿态角。主干网络采用改进的轻量化卷积mobilenet-v2网络结构,在主干网络的第一层采用不同尺度卷积提取图像的特征并进行融合,通过多个不同大小的卷积核得到不同的感受野,具体地,分别采用1
ⅹ
1、3
ⅹ
3和5
ⅹ
5的卷积核替换原来单个3
ⅹ
3卷积核对输入的头部图像进行特征提取,并将卷积步幅设置为1,并将每个卷积核对应的pad分别设置为0,1,2,使得卷积后的图像可以得到相同维度的特征,可以直接拼接一起,通过这种增加网络宽度的方式能增加网络的性能,为了减少计算量,使用1
ⅹ
1卷积核来进行降维处理,在确保获得网络性能的同时减少参数量,并引入更多的非线性,提高泛化能力,采用5
ⅹ
5卷积核,获得更大的感受野。考虑到人脸中眼睛、鼻子、嘴巴等部位的相对位置对姿态角度的影响,获得更大的感受野可以更好描述这种相关性。同时在主干网络中嵌入ca注意力模块,ca注意力模块能够在空间上捕捉精确的位置信息,ca方法通过将二维全局池化操作分解为两个一维编码过程,即将全局池化操作分解为沿着输入特征图的水平方向和垂直方向分别进行池化操作,从而获得输入特征图的x、y轴相关的位置信息。这样改进的轻量化卷积mobilenet-v2网络结构结构大小为4m。在保证预测精度的同时模型更小,预测时能达到实时性。
[0099]
人脸位置检测模块,用于根据获取到的单位时间内的若干帧人脸图像,以每一帧作为一张图像,采用mtcnn网络检测每张图像的人脸位置并裁剪出头部图像;
[0100]
并行预测模块,用于将头部图像输入训练好的mmc多任务预测模型中,得到头部姿态角度和人脸关键点的位置信息;
[0101]
局部状态检测模块,用于根据每张图像的头部姿态角度,利用双阈值法判定若干张图像中头部的疲劳状态,同时根据每张图像的人脸关键点中眼部和嘴部的位置信息,利用双阈值法分别判定若干张图像中眼部和嘴部的疲劳状态;
[0102]
采用双阈值法确定每个部分的疲劳状态,将单位时间设定为30秒,获取到30秒内的连续多帧图像,每一帧作为一张图像,通过计算每个部分所处状态帧数占单位时间总帧数比例来确定每个部分是否处于疲劳状态,例如可以设定眼睛为闭眼状态和嘴巴为打哈欠状态的视频帧数占单位时间帧数40%以上则判定为疲劳状态,设定低头情况下pitch姿态角大于30
°
的视频帧数占单位时间帧数30%以上则判定为疲劳状态。
[0103]
综合疲劳状态检测模块,用于根据头部、眼部和嘴部的疲劳状态综合判定人的疲劳状态。考虑到人长时间低头则容易被认为是疲劳状态,且在打哈欠的同时人眼常常处于接近闭合状态,所以对每部分设定相关系数来综合判定人的疲劳状态,根据头部、眼部和嘴部的疲劳状态对人的疲劳状态的影响权重,同样地,对每个部分的疲劳状态设定相关系数利用公式(7)综合判定人的疲劳状态z。
[0104]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实
施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质上实施的计算机程序产品的形式。
[0105]
本技术是参照根据本技术实施例的方法、设备、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0106]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0107]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0108]
本领域普通技术人员可以理解实现上述事实和方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,涉及的程序或者所述的程序可以存储于一计算机所可读取存储介质中,该程序在执行时,包括如下步骤:此时引出相应的方法步骤,所述的存储介质可以是rom/ram、磁碟、光盘等等。
[0109]
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。