1.本发明属于智能电网技术领域,尤其涉及一种基于大数据自适应学习的工业园区短期无功负荷预测方法,特别涉及多元线性回归,支持向量回归,交叉验证以及最小绝对收缩和选择算子等工业园区无功功率短期预测技术。
背景技术:
2.相比于工业用户负荷预测,电力系统总负荷受许多外部因素的影响,如气温、时间、人口、经济、地理条件等,而工业负荷则主要由企业的生产经营活动决定,受上述因素的影响较小。
3.负荷预测应用中的术语“负荷”通常是指有功功率(以kw为单位)或能量(以kwh为单位)。
4.无功功率预测对于工业企业和配电网的能源管理至关重要。然而,目前专门研究对工业负荷预测的研究很少,而对无功功率的预测则更少,鲜有研究应对工业园区短期无功功率预测系统的新挑战。工业负荷影响因素较多,如计划过程和工作班次,这在传统广域负荷预测模型中考虑不足。而且,工业负荷由于生产工艺不同,无功功率的特性与有功功率有本质不同,因此经典负荷预测模型中的一些常用变量难以应用于预测无功功率。
5.传统工业有功负荷预测和无功功率预测虽然相关,但具有本质不同。由于许多工厂和工厂的电力消耗很大,因此具有强烈能源管理有序用电需求。从单个设备级到工厂级的准确短期工业无功功率预测可有效辅助工厂及其工业负荷聚合商参与辅助市场服务,且工业企业诸多重要的流程操作均依赖于对无功功率的精准感知,例如电压无功优化、电能质量改善、频率控制及稳态潮流分析。因此,准确的无功功率预测对于配网控制必不可少的,可深入感知未来的无功功率曲线并在配电水平上提高电网的运营安全性和经济性。
6.近年来,智能电网的实际实施和能源市场的开放推动了对准确无功功率预测的辅助市场需求。在智能电网框架中,分布式能源的日前和小时前调度中需要无功功率预测,以确保满足电网运行安全约束。为了追求最优调度,在配电网级和单个工业负荷级都依赖精准预测。同时,电力市场也涉及无功功率预测信息支撑,在许多国家,电力市场只能支持固定时间间隔内的有功功率交易,需要无功功率预测来测试配电网从发电厂到工业负荷的能源路径经济型和安全性,如果超过技术约束,电力市场将重新配置工业负荷辅助服务市场价值。因此,无功功率预测将在不久的将来成为辅助服务市场的重要影响因素。
7.当前无功功率预测的方法是将有功功率预测值乘以与平均功率因数相关的系数,或者是单纯依靠系统操作员经验的方法,预测方法相对模糊,且具有一定的黑箱性和不确定性,难以满足无功功率短期预测精度要求。
技术实现要素:
8.针对上述现有技术中存在的不足之处,本发明提供了一种基于大数据自适应学习的工业园区短期无功负荷预测方法。其目的是为了实现提出一种为工业园区单个设备负荷
28.其中,α,α0是模型的拉格朗日乘子参数变量,符号<,>表示输入之间的点积,给定两个调整参数常量偏差ε和惩罚系数c的条件下,为无功功率的n
tr
个观测值q1,...,q
ntr
设置辅助松弛因子参数支持向量回归svr预测的无功功率为:
[0029][0030]
残差参数变量估计值为:
[0031][0032][0033]
上式中:表示第i点无功功率,λi和为松弛因子,以提高求解的鲁棒性,和为参数变量估计值,它们对应的无功功率样本是支持向量,一般出现在函数变化比较剧烈的位置。
[0034]
更进一步的,步骤3所述利用预测得到的电压和有功功率预测进行无功功率预测,是将步骤2预测得到的有功功率和工业负荷电压作为电气变量,基于两种组合变量选择方法在历史无功功率、日历效应变量,天气变量这三个变量大类中选择出最优变量作为预测结果。
[0035]
一种计算机存储介质,所述计算机存储介质上存有计算机程序,所述计算机程序被处理器执行时实现所述的基于大数据自适应学习的工业园区短期无功负荷预测方法的步骤。
[0036]
本发明具有以下有益效果及优点:
[0037]
本方法首次以工业园区的无功功率为预测对象,提供了针对园区级工业无功负荷短期预测方法,为含工业园区的区域电网电压稳定及无功补偿等提供辅助指导。准确的无功功率预测对于配网控制必不可少的,可深入感知未来的无功功率曲线并在配电水平上提高电网的运营安全性和经济性。
[0038]
本发明方法解决了无功负荷与有功负荷相比有波动性大等特性,用预测有功负荷的模型来预测无功负荷时往往会出现局部误差过大的问题。首先用传统方法预测有功功率和电压,然后将有功功率和电压的预测结果作为电气变量,接着结合天气变量,日历效应变量等来预测无功功率。有功功率,无功功率和电压之间具有强电气连接的耦合特性,本发明方法采用数据驱动的方法表征总无功功率相对于有功功率和相电压的散点图,从而得出三者之间的关系。该方法可应用于无功负荷波动性较大工况,将有效减少误差。
[0039]
本方法基于多元线性回归(multiple linear regression,mlr)和支持向量回归(support vector regression,svr)方法,并组合交叉选择和最小绝对收缩与选择算子这两种方法用于变量选择构建针对园区级工业无功功率短期预测模型。
[0040]
本发明方法提出了适用于工业无功功率预测模型,所提出模型基于组合预测技术(多元线性回归mlr和支持向量回归svr,)和祝贺变量选择方法(交叉验证t1和最小绝对收缩和选择算子t2)构成。最终得到基于两种预测方法和两种变量选择方法的四个预测模型—t1/mlr,t2/mlr,t1/svr和t2/svr。考虑考虑无功功率受有功功率和工业负荷电压的影
响,本方法首次提出将预测到的有功功率和工业负荷电压作为电气变量输入预测模型的思想,并采用组合变量选择方法在历史无功功率、日历效应变量,天气变量这三个变量大类中选择最优变量。基于四种模型分别对不同工业负荷类型的无功负荷进行预测。然后以标准化平均绝对误差(nmae),标准rmse(nrmse)和平均绝对比例误差(mase)作为衡量指标,每种工业负荷类型选择出最优预测模型,并以该预测模型预测出的无功负荷作为预测结果,提高无功预测准确度,辅助工业企业和负荷聚合商智慧管理能量,参与辅助服务市场。
[0041]
本方法解决了短期工业无功功率预测新的问题,且充分考虑了工业有功功率预测和无功功率预测之间耦合关系。由于在模型构建中必须考虑不同且不均匀的无功数据输入,且24/7全天候运行的工厂可能与仅在工作日运行的工厂具有不同的无功功率曲线。手动控制的机器可能具有与熔炉或自动化机器不同的无功功率曲线。另外,无功功率可能或多或少地对消耗的有功功率或电源电压敏感。即使在同一工厂内,设备级别的工业负荷也可能彼此不同。因此,在建立准确的无功功率预测模型之前,必须确定并合理选取日历效应、天气及电气变量。
附图说明
[0042]
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
[0043]
图1是本发明建立无功功率预测的步骤框图;
[0044]
图2是本发明模型组合预测流程图;
[0045]
图3是本发明变量选择流程图。
具体实施方式
[0046]
为了能够更清楚地理解本发明的上述目的、特征和优点,下面将结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本技术的实施例及实施例中的特征可以相互组合。
[0047]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
[0048]
下面参照图1-图3描述本发明一些实施例的技术方案。
[0049]
实施例1
[0050]
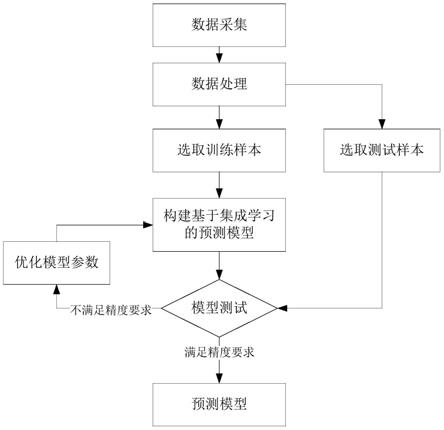
本发明提供了一个实施例,是一种基于大数据自适应学习的工业园区短期无功负荷预测方法。如图1所示,是本发明建立无功功率预测的步骤框图。
[0051]
本发明预测方法,基于工业园区有功预测信息的无功功率预测模型,具体包括以下步骤:
[0052]
步骤1.输入变量选择。
[0053]
本发明提出的输入变量选择方法,虽然在预测模型中增加变量可能会提高预测的准确性,但是添加过多变量或添加干扰变量可能会导致拟合过度,导致预测准确度不佳。因此,变量选择是设计预测模型的重要步骤。分析工业园区无功功率数据特征,选择高价值相关度变量,并从广域分布传感器收集的所有可用输入数据中剔除干扰变量。
[0054]
本发明所采用两种变量选择方法为:十倍交叉验证法t1和最小绝对收缩和选择算子法t2,并组合进行最终优选输入变量。
[0055]
(1)十倍交叉验证法,定义为t1。
[0056]
本发明所述十倍交叉验证法尝试所有考虑的模型,即使用多种不同的变量组合构建模型,并从中选择最优模型。将观察到的目标变量和测试中的相应变量数据分成十个大小相等的子集。在该过程的每次迭代中,九个子集用于训练所有考虑的模型,剩下的子集用于验证模型。对于所考虑的每个模型,通过平均所有十次迭代的误差来获得最终误差。选择呈现最小平均误差的模型,并将其提升到下一步。本方法使用均方根误差作为误差度量。
[0057]
(2)最小绝对收缩和选择算子法,(least absolute shrinkage and selection operator,lasso),定义为t2。
[0058]
多元线性回归mlr模型的参数是通过lasso估算园区负荷数据中的所有候选变量的,它可将平方误差之和与参数绝对值之和减至最小。在数学上,给定n
tr
观测值通过解决以下优化问题来估计参数β:
[0059][0060]
其中φ是分配的非负超参数,与规范化程度相关。通常根据优化问题的尺寸(如,m)凭经验确定。与最小二乘法相比,加罚项类似于对估计参数的绝对值之和加上上限约束。
[0061]
因此,几个估计的参数为零,并且与具有零值的参数相关联的输入将被提出,因为这表征了它们带给模型的信息稀缺程度。其中,超参数的较大值通常导致较少的非空估计参数βj。本方法没有确定非空估计参数的预定最大数量。相反,本方法通过交叉验证来优化超参数。然后,将所选的输入变量用于构建多元线性回归mlr模型。
[0062]
支持向量回归svr模型的参数选择与上述所述执行相同的选择方式。
[0063]
本发明还包括待选的变量,包括:历史无功功率、日历效应变量、天气变量和电气变量。
[0064]
针对不同的工业负荷类型采用两种方法组合,并且可以选择最优输入变量。
[0065]
本发明方法提出的变量选择方法允许在候选变量中选择高价值相关度变量,既限制预测系统输入数据的维度,而不会损失数据变量特征。
[0066]
步骤2.利用所选择的变量进行电压和有功功率预测。
[0067]
本发明利用所选择的两种变量选择方式,十倍交叉验证法t1和最小绝对收缩和选择算子法t2进行组合预测。所述两种预测方法,包括:多元线性回归(multiple linear regression,mlr)和支持向量机(support vector regression,svr))。
[0068]
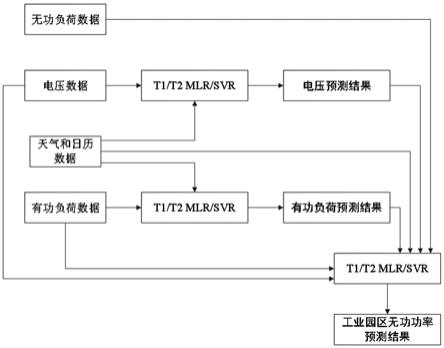
本方法首次提出基于工业园区有功预测信息的无功功率预测框架,其中电压和有功预测部分,所提出模型基于组合预测技术和祝贺变量选择方法构成。最终得到基于两种预测方法和两种变量选择方法的四个不同的组合预测模型—t1/mlr,t2/mlr,t1/svr和t2/svr,生成四种不同的组合预测模型t1/mlr、t2/mlr、t1/svr及t2/svr。如图2所示,图2是本发明模型组合预测流程图。基于这四种组合模型分别对不同工业负荷类型的工业负荷电压
和有功负荷进行预测。然后以标准化平均绝对误差(normal mean absolute error,nmae),标准均方根误差(normal root mean square error,nrmse)和平均绝对比例误差(mean absolute proportional error,mape)作为衡量指标,每种工业负荷类型选择出最优预测模型,并以该预测模型预测出的工业负荷电压和工业负荷有功功率作为预测结果。
[0069]
本发明方法采用多元线性回归mlr和支持向量回归svr的组合预测方法,其中,多元线性回归mlr模型的通用形式可表示为:
[0070]qt
=β0 β1χ
1,t
... βmχ
m,t
[0071]
其中q
t
是在时间t的预测园区无功功率,χ
1,t
,χ
2,t
...χ
m,t
是模型的m个变量,而β={β0,β1...βm}是m 1个参数的向量,将在训练步骤中通过最小二乘法(ordinary least squares,ols)方法进行估算。
[0072]
在为短期无功功率预测建立多元线性回归mlr模型时,利用定量变量、定性变量及其相互作用。定量变量表示物理值,例如环境温度,特定时间的有功或无功功率或电压,而定性变量可以表示日历信息,例如一周中的某天和一天中的几小时。可以通过将相互作用的变量彼此相乘来获得相互作用。添加交互效果使模型是分段的。
[0073]
支持向量回归svr模型将在时间t的预测无功功率q
t
链接到m个变量x
t
={x
1,t
,x
2,t
,...,x
m,t
}.它们可以通过非线性关系f(x
t
)表示特征。在本方法中,使用线性支持向量回归svr与多元线性回归mlr模型进行比较。
[0074]qt
=<α,x
t
> α0[0075]
其中,α,α0是模型的拉格朗日乘子参数变量,符号<,>表示输入之间的点积,给定两个调整参数常量偏差ε和惩罚系数c的条件下,为无功功率的n
tr
个观测值q1,...,q
ntr
设置辅助松弛因子参数支持向量回归svr预测的无功功率为:
[0076][0077]
残差参数变量估计值为:
[0078][0079][0080]
上式中:表示第i点无功功率,λi和为松弛因子,以提高求解的鲁棒性,和为参数变量估计值,它们对应的无功功率样本是支持向量,一般出现在函数变化比较剧烈的位置。
[0081]
步骤3.利用预测得到的电压和有功功率预测进行无功功率预测。
[0082]
如图3所示,图3是本发明变量选择步骤图。由于无功功率受有功功率和工业负荷电压的影响,因此将步骤2预测得到的有功功率和工业负荷电压作为电气变量。同时,基于两种组合变量选择方法在历史无功功率、日历效应变量,天气变量这三个变量大类中选择出最优变量。基于四种模型分别对不同工业负荷类型的无功负荷进行预测。以标准化平均绝对误差nmae、标准均方根误差rmse(nrmse)和平均绝对比例误差mase作为衡量指标,每种工业负荷类型选择出最优预测模型,并以该预测模型预测出的工业园区无功负荷作为预测
结果。
[0083]
该预测结果可以有效提高无功预测准确度,辅助工业企业和负荷聚合商智慧管理能量,参与辅助服务市场。
[0084]
实施例2
[0085]
基于同一发明构思,本发明实施例还提供了一种计算机存储介质,所述计算机存储介质上存有计算机程序,所述计算机程序被处理器执行时实现实施例1所述的一种基于大数据自适应学习的工业园区短期无功负荷预测方法的步骤。
[0086]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0087]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0088]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0089]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0090]
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。