一种处理哮喘患者咳嗽音以应用适当治疗的方法和装置
1.相关申请
2.本技术要求2019年8月19日提交的澳大利亚临时专利申请号2019903000的优先权,其公开内容通过引用并入本文以用于所有目的。
技术领域
3.本发明涉及自动地确定受试者哮喘的存在和严重程度。
背景技术:
4.任何对现有技术的方法、装置或文件的引用不应被视为构成任何证据或承认它们已形成或形成公知常识的一部分。
5.哮喘是一种常见的儿童呼吸系统疾病,以喘息、咳嗽和呼吸窘迫为特征。哮喘严重程度可以通过主观的手动评分系统(例如肺部评分)来确定。这些系统需要大量的医学培训和专业知识来评估临床发现,例如喘息特征和呼吸功。正确表征患者哮喘严重程度的能力是有价值的,因为根据例如对支气管扩张药物有反应的哮喘的严重程度,可以实施正确的治疗和管理疗法。
6.急性哮喘的特征是偶发、可逆的气流阻塞,并表现为对支气管扩张药物有反应的喘息、呼吸窘迫和咳嗽[3]。根本的病理生理学是通过部分收缩的小气道和大气道的受限的气流,导致喘息和增加的呼吸功,表现为增加的呼吸频率和辅助呼吸肌的使用。喘息特征可能随着阻塞的增加而改变,而在严重的疾病中,气流可能不足以产生任何喘息,从而导致“寂静胸”。
[0007]
通过听诊检测喘息的能力取决于(i)在肺内产生的声音具有足够的强度以到达胸壁,以被听诊器检测到;(ii)临床医生有足够的听敏度;和(iii)识别其定义特征的临床技能和经验。
[0008]
已经开发了气道阻塞的各种测量。客观测试包括肺量测定法和呼气峰值流速(pefr)测量[6]。在急性情况下,正式的肺量测定法不可用或不实用。pefr测量仪的优点是便宜且便于携带。然而,年幼的儿童(《6岁)和严重呼吸窘迫的人通常无法依从pefr测试,这些测试依赖于技术和努力,并且需要合作。不建议将pefr测量用于12岁以下儿童的日常使用[3]。
[0009]
临床评定量表使用临床特征的组合来指导哮喘管理,衡量对治疗的反应,并确定护理的紧迫性。肺评分(ps)是临床实践中常用的哮喘严重程度量表,与pefr测量相当[9]。它在西澳大利亚州的医院中普遍使用,并在常规临床实践中被广泛依赖[10]。该ps利用呼吸频率(rr)、喘息特征和辅助(胸锁乳突)肌肉(am)使用来生成满分9分的分数(表1)。呼吸频率可以很容易地被确定,即使是经过最少培训或没有培训的非专业用户。然而,喘息特征和am使用的评估和分级需要大量的医学培训和专业知识。喘息的评估需要听诊器检查。虽然ps可以提供在所有环境中管理儿童哮喘的关键信息,但它不是临床实践或医院之外的实用评估工具。本研究的主要目的是开发一种可在社区部署的技术来评估哮喘的严重程度。
[0010][0011]
表1(上):肺评分。临床医生从呼吸频率、喘息和辅助肌肉使用中估计子分数(0-3)。表示受试者哮喘严重程度的总体ps是所有三个子分数的总和。
[0012]
需要一种自动化方法来对哮喘严重程度进行分层,该方法不依赖于喘息严重程度(听诊)或辅助肌肉使用的临床评估。
技术实现要素:
[0013]
根据本发明的第一方面,提供了一种用于对患者哮喘的严重程度进行分层的方法,该方法包括:
[0014]
从声传感器接收对应于患者声音的声学数据;
[0015]
通过处理器识别声学数据中的至少一个咳嗽音;
[0016]
由处理器为一个或多个特征中的每一个确定至少一个咳嗽音的一个或多个总体咳嗽音特征值;
[0017]
通过处理器将总体咳嗽音特征值应用到由处理器实现的分类器,所述分类器已经用来自哮喘和非哮喘受试者群体的特征值的训练集进行了预训练;和
[0018]
监控来自预训练分类器的输出,以将患者咳嗽音视为指示哮喘的多个严重程度之一。
[0019]
在一个实施方式中,一个或多个特征的一个或多个总体咳嗽音特征值包括咳嗽音的小波特征值。
[0020]
在一个实施方式中,严重程度包括“轻度”或“中度至重度”。
[0021]
在一个实施方式中,该方法包括,除了总体咳嗽音特征值之外,由处理器将作为患者呼吸频率或从其导出的值的呼吸频率值应用于预训练分类器,以将患者咳嗽音视作是指示哮喘的多个严重程度之一,其中哮喘的严重程度包括“轻度”、“中度”和“重度”。
[0022]
在一个实施方式中,呼吸频率值包括考虑患者年龄的基于呼吸频率的呼吸指数。
[0023]
在一个实施方式中,该方法包括由处理器将每个至少一个咳嗽音分割成多个片段。
[0024]
在一个实施方式中,该方法包括由处理器针对多个特征中的每一个确定多个片段中的每个片段的片段特征值。
[0025]
在一个实施方式中,多个片段包括三个片段。
[0026]
在一个实施方式中,该方法包括由处理器将除总体咳嗽特征值之外的片段特征值应用于预训练的分类器。
[0027]
在一个实施方式中,该方法包括:由处理器确定多个特征中的每一个的片段特征值包括确定关于一个或多个片段的以下的一个或多个的值:mfcc1、mfcc2、mfcc3、mfcc4、
mfcc6、mfcc9和mfcc12。
[0028]
在一个实施方式中,该方法包括由处理器确定第一片段的峰度值。
[0029]
在一个实施方式中,该方法包括通过处理器确定关于每个片段的以下特征中的一个或多个的值:
[0030]
双谱评分(bgs);
[0031]
非高斯评分(ngs);
[0032]
前n个共振峰频率(ff);
[0033]
对数能量(loge);
[0034]
过零(zcr);
[0035]
峰度(kurt);
[0036]
前n个梅尔倒频谱系数(mfcc)。
[0037]
在一个实施方式中,由处理器为多个特征中的每一个确定片段特征值包括为每个片段确定如下的21个特征值:
[0038][0039]
在一个实施方式中,由处理器为多个特征中的每一个确定片段特征值包括为三个片段中的每一个确定如下的特征值:
[0040][0041]
根据本发明的另一方面,提供了一种系统,该系统包括一个或多个处理器,该处理器被布置为根据前述方法处理人类受试者的声音。
[0042]
根据本发明的另一方面,提供了一种用于确定和呈现患者的哮喘严重程度的哮喘严重程度机器,该机器包括:
[0043]
电子存储器;
[0044]
与电子存储器通信的至少一个处理器,其由存储在电子存储器中的指令配置;
[0045]
与至少一个处理器通信的音频记录组件;
[0046]
与至少一个处理器通信的人机界面;
[0047]
其中电子存储器存储指令,该指令将至少一个处理器配置为:
[0048]
处理患者的数字录音以识别至少一个咳嗽音;
[0049]
针对一个或多个特征中的每一个,提取咳嗽音的一个或多个总体咳嗽音特征值;
[0050]
提供用于哮喘严重程度的预训练的模式分类器,所述分类器已经用来自哮喘和非哮喘受试者群体的特征值的训练集进行了预训练;和;
[0051]
将总体咳嗽音特征值应用于预训练的模式分类器;和
[0052]
操作人机界面,以根据预训练的模式分类器的输出呈现哮喘严重程度分类。
[0053]
在一个实施方式中,电子存储器存储指令,该指令配置至少一个处理器以提取一个或多个总体咳嗽音特征值,包括咳嗽音的小波特征值。
[0054]
在一个实施方式中,电子存储器存储指令,该指令配置至少一个处理器以操作人机界面,以基于来自预训练的模式分类器的输出来呈现哮喘严重程度分类,该输出包括“轻度”或“中度至重度”的分类。
[0055]
在一个实施方式中,电子存储器存储指令,该指令配置至少一个处理器,以将除了总体咳嗽音特征值之外的呼吸频率值(是患者的呼吸频率或从其导出的值)应用于预训练的分类器,以操作人机界面以呈现哮喘的严重程度,包括“轻度”、“中度”和“重度”。
[0056]
在一个实施方式中,电子存储器存储指令,该指令配置至少一个处理器,以将每个至少一个咳嗽音分割成多个片段。
[0057]
在一个实施方式中,电子存储器存储指令,该指令配置至少一个处理器,以针对多个特征中的每一个为多个片段中的每一个片段分割特征值。
[0058]
在一个实施方式中,电子存储器存储指令,该指令配置至少一个处理器,以将除总体咳嗽特征值之外的片段特征值应用于预训练的分类器。
[0059]
在一个实施方式中,电子存储器存储指令,该指令配置至少一个处理器,以确定关于一个或多个的片段的以下中的一个或多个的特征值:mfcc1、mfcc2、mfcc3、mfcc4、mfcc6、mfcc9和mfcc12。
[0060]
在一个实施方式中,电子存储器存储指令,该指令配置至少一个处理器以确定第一个片段的峰度值。
[0061]
在一个实施方式中,电子存储器存储指令,该指令配置至少一个处理器以获得患者呼吸频率的估计值。
[0062]
在一个实施方式中,电子存储器存储指令,该指令配置至少一个处理器以分析来自放置在患者身上或附近的加速度计的信号,以确定患者呼吸频率。
[0063]
在一个实施方式中,电子存储器存储指令,该指令配置至少一个处理器以处理来自用于检测来自患者的呼吸音的声传感器的信号,从而计算呼吸频率估计值。
[0064]
在一个实施方式中,电子存储器存储指令,该指令配置至少一个处理器以监测来自镜头和ccd组件的信号,该镜头和ccd组件定位成捕捉患者胸部的上升和下降的图像,从而从图像产生呼吸频率。
[0065]
根据本发明的另一方面,提供了一种对患者哮喘严重程度进行分层的方法,该方法包括:
[0066]
从放置在患者附近的声传感器接收声学数据;
[0067]
通过处理器识别声学数据中的至少一个咳嗽音;
[0068]
通过处理器将咳嗽音分割成多个片段;
[0069]
由处理器确定多个特征中的每一个的片段特征值;
[0070]
处理器将片段特征值应用到由处理器提供的预训练的分类器;和
[0071]
监控来自预训练的分类器的输出,以将患者咳嗽音视为指示多个严重程度之一。
[0072]
在另一方面,提供了一种用于指示患者哮喘严重程度的哮喘严重程度指示器组件,包括:
[0073]
音频捕获装置,包括麦克风和模数转换电路,其被配置为将患者的数字音频记录存储在电子存储器中;
[0074]
咳嗽识别组件,与存储器通信并被布置为处理数字音频记录,从而识别包括患者咳嗽音的数字音频记录的部分;
[0075]
咳嗽分段组件,响应于咳嗽识别组件并布置成将每个识别的咳嗽分割成多个片段;
[0076]
特征提取处理器,其与咳嗽分段组件通信并布置为处理每个片段,以针对多个特征中的每一个为每个片段生成片段特征值;和
[0077]
模式分类器,其与特征提取处理器通信,被配置为产生将患者咳嗽音指示为多个
严重程度之一的信号。
[0078]
在另一方面,提供了一种用于确定和呈现患者的哮喘严重程度的哮喘严重程度机器,该机器包括:
[0079]
电子存储器;
[0080]
至少一个处理器,其与电子存储器通信,可由存储在电子存储器中的指令配置;
[0081]
与至少一个处理器通信的音频记录组件;
[0082]
与至少一个处理器通信的人机界面;
[0083]
其中电子存储器存储用于处理器的指令,以:
[0084]
处理患者的数字录音以识别至少一个咳嗽音;
[0085]
从咳嗽音及其片段中提取特征;
[0086]
提供针对哮喘严重程度的预训练的模式分类器;
[0087]
将特征应用于预训练的模式分类器;和
[0088]
操作人机界面,以根据预训练的模式分类器的输出呈现哮喘严重程度分类。
[0089]
在另一方面,提供了一种用于对患者的哮喘严重程度进行分层的方法,包括:将患者咳嗽音的特征值应用到已经使用严重程度不同的哮喘患者群体预先训练的模式分类器。
[0090]
在另一方面,提供了一种哮喘严重程度机器,其被布置为捕获患者的咳嗽音并将来自咳嗽音的特征值应用到已经使用哮喘严重程度不同的哮喘患者群体预先训练的模式分类器,并根据模式分类器的输出呈现分类。
附图说明
[0091]
本发明的优选特征、实施方式和变型可以从以下详细描述中辨别出来,该详细描述为本领域技术人员提供了实施本发明的充分信息。详细描述不应被视为以任何方式限制前述发明内容的范围。详细描述将参考如下多个附图:
[0092]
图1是用于呈现患者哮喘严重程度的方法的流程图。
[0093]
图2是用于呈现患者哮喘严重程度的哮喘严重程度机器的框图。
[0094]
图3是对应于由图2的机器捕获的患者音的示例性数字波形。
[0095]
图4a是图2的机器的外部视图,同时处于记录图3的波形的操作中。
[0096]
图4b是图2的机器的外部视图,显示了用于输入患者呼吸频率和年龄的屏幕。
[0097]
图5是示出了由图2的机器识别为咳嗽音的患者声音的记录的部分的图。
[0098]
图6是详细示出了来自图5并且被分割成三个片段的咳嗽音的图。
[0099]
图7是图2的机器的外部视图,示出了总体显示每次咳嗽的咳嗽严重程度等级和平均严重程度等级的屏幕。
[0100]
图8包括四个图,示出了用于诊断哮喘严重程度的四个不同训练的逻辑回归模型中的每一个的置信区间。
具体实施方式
[0101]
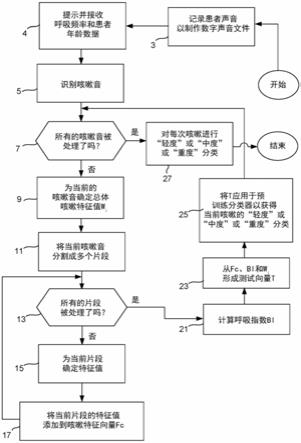
图1是根据本发明的优选实施方式的用于将患者的哮喘分类为“轻度”、“中度”或“重度”之一的方法的流程图。
[0102]
用于实施该方法的装置包括哮喘分层机器或可称为哮喘严重程度指示器组件。哮
喘分层机器可以是专用组件,其包括特定电路以执行将讨论的用于分类哮喘的各种操作。或者,哮喘分层机器可以是台式计算机或便携式计算设备,例如智能手机,其包含与电子存储器通信的至少一个处理器,该电子存储器存储指令,该指令具体配置操作中的处理器以执行将要描述的方法的步骤。应当理解,在没有专用机器或由一个或多个处理器组成的组件或系统的情况下不可能执行该方法,该一个或多个处理器与一个或多个电子存储器通信,所述电子存储器存储指令以专门配置处理器以实现该方法。
[0103]
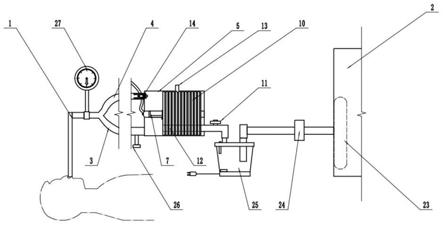
图2是使用智能手机的一个或多个处理器和存储器实现的哮喘分层机器51的框图。哮喘分层机器51包括访问电子存储器55的至少一个处理器(或者可以简称为“处理器”)53。电子存储器55包括例如由处理器53执行的操作系统58,例如安卓操作系统或苹果ios操作系统。电子存储器55还包括根据本发明一个优选实施方式的哮喘分层软件产品或“应用程序”56。哮喘分层应用程序56包括可由处理器53执行的指令,从而专门配置处理器53以便哮喘分层机器51处理来自患者52的声音并将患者52的哮喘严重程度的分类通过lcd触摸屏界面61呈现给临床医生54。应用程序56包括用于处理器53的指令,用于提供模式分类器(例如训练的预测器或决策机器),在本发明的当前描述的优选实施方式中,其包括专门训练的逻辑回归模型(lrm)60。将认识到,在其他实施方式中,可以由在应用程序56的控制下的处理器53实现其他合适的决策机器,例如人工神经网络或贝叶斯决策机器。
[0104]
处理器53通过数据总线57与多个外围组件59至73进行数据通信,如图2所示,数据总线57由金属导体组成,数字信号200沿金属导体在处理器53和各种外围设备59-73之间传送。因此,如果需要,哮喘严重程度机器51能够通过wan/wlan组件73和射频天线79与语音和/或数据通信网络81建立语音和数据通信。该机器还包括其他外围设备,例如镜头和ccd组件59,其影响数码相机,以便在需要时可以捕获患者52的图像。lcd触摸屏界面61包括人机界面,并允许临床医生54读取结果并将命令和数据输入机器51。加速度计62检测与位置和方向变化相关联的加速度,并提供相应数据以供处理器53处理。提供了usb端口65,用于实现与外部存储设备(例如u盘)的串行数据连接,或用于与数据网络或外部屏幕和键盘等进行电缆连接。还提供了辅助存储卡64,用于由存储器55促成的内部数据存储空间之外的附加的辅助存储(如果需要)。音频接口71将麦克风75耦合到数据总线57,并且包括抗混叠滤波电路和模数采样器,以将来自麦克风75的模拟电波形(其对应于患者声波39)转换为包括声学数据66的数字音频信号300(在图3中示出),声学数据66可以存储在存储器55中并由处理器53处理。音频接口71还耦合到扬声器77。音频接口71包括用于将数字音频转换为模拟信号的数模转换器和连接到扬声器71的音频放大器,以便可以回放记录在存储器55或辅助存储64中的音频,以供临床医生54收听。
[0105]
在优选实施方式中,哮喘分层机器51由应用程序56配置为用于对患者的哮喘严重程度进行分类(或本文中称为“哮喘严重程度分层”)的机器,无需外部传感器、与患者52的物理接触或与通信网络81联系。此外,一旦机器51已经存储了声学数据66,机器51就可以处理声学数据以对哮喘严重程度进行分层,而无需患者在场。
[0106]
如前所述,虽然在一个实施方式中,以由应用程序56独特配置的智能手机硬件的形式提供了图2中所示的哮喘分层机器51,但是它可以同样利用一些其他类型的处理组件,例如台式机计算机、膝上型电脑或平板计算设备或甚至在云计算环境中,其中硬件包括用应用程序56专门编程的虚拟机。此外,还可以构建不使用通用处理器的专用电路哮喘分层
机器。例如,这样的专用机器可以具有包括麦克风和模数转换电路的音频捕获装置,该模数转换电路被配置为将患者的数字音频记录存储在电子存储器中。该机器还可以包括咳嗽识别组件,其与存储器通信并且被布置为处理数字音频记录,从而识别包括患者咳嗽音的数字音频记录的部分。提供了一种咳嗽分段组件,其响应于咳嗽识别组件并且布置成将每个识别的咳嗽分割成多个片段。提供特征提取处理器,其与咳嗽分段组件通信并且被布置为处理每个片段,以针对多个特征中的每一个为每个片段生成片段特征值。专用机器还包括与特征提取处理器通信的硬件实现的模式分类器,其被配置为产生将患者咳嗽音指示为代表多个哮喘严重程度之一的信号。
[0107]
哮喘严重程度机器51用来对患者52的哮喘严重程度进行分层并且包括组成应用程序56的指令的程序在图1的流程图中示出,并且现在将被详细描述。
[0108]
在方框3处,来自患者52嘴部的声音39由麦克风75记录并由音频接口71数字化,以产生沿总线57传送到处理器53的数字化信号300(如图3所示)。通常,麦克风75放置在患者嘴部附近,例如在一米内,尽管取决于麦克风的方向性和背景噪音水平,距离可能会发生变化,同时仍能确保捕捉到患者的声音。信号300包括数字化患者声音数据,其从患者52以在16位分辨率下通常是44.1khz的采样频率fs记录,并作为声学数据66(例如作为文件)存储在哮喘严重程度机器51的存储器55中。在方框3的记录过程期间,处理器53操作lcd触摸屏界面61以显示如图4a所示的记录消息屏幕10。临床医生54继续记录过程,直到从患者52采集到至少一个咳嗽,优选地多于一个咳嗽。一旦临床医生54对已经采集的咳嗽的数量感到满意,然后临床医生按下屏幕10上的“ok”按钮,从而记录停止并且处理器53进行到图1流程图的方框4。对于方框4到27中描述的任何操作,患者不需要在场。
[0109]
在方框4处,处理器53操作lcd触摸屏界面61以显示如图4b所示的屏幕12,以供临床医生54输入患者52的年龄(按月计)以及患者的呼吸频率。稍后将在方框21处使用患者年龄和呼吸频率值,以供处理器53计算呼吸指数值。可以省略在方框4中获取呼吸频率和患者年龄数据的步骤以及在方框21中计算呼吸指数的步骤。然而,这种省略导致该方法无法可靠地将患者分类为患有“轻度”、“中度”或“重度”哮喘的三种分类之一,但只能在两种分类之间区分,即“轻度”或“中度至重度”。
[0110]
在方框5处,处理器53处理在方框3处捕获的患者52的数字化声音记录300,以识别声音记录中的咳嗽cg1、...、cgn,如图5所示。识别咳嗽音的过程在现有技术中是已知的,例如在授予本技术人的美国专利号10098569中,其公开内容通过引用并入本文。
[0111]
在方框7处,处理器53确定是否所有识别的咳嗽音cg1、...、cgn都已被后续处理方框以稍后将解释的方式处理。由于最初没有咳嗽音被处理,控制从决策方框7转移到方框9。在方框9处,处理器53为一个或多个特征中的每一个计算当前咳嗽音的一个或多个总体咳嗽音特征值。在当前描述的实施方式中,总体咳嗽音特征值是基于morlet小波的13个小波特征的值w1、...、w13,如在kosasih,k.、u.r.abeyratne和v.swarnkar的wavelet augmented cough analysis for rapid childhood pneumonia diagnosis(ieee trans on biomed eng.,2015.62(4):第1185-1194页)中所详述的,其内容通过引用整体并入本文。
[0112]
在方框11,处理器53将当前咳嗽音cgi分割成三个片段ss(1)、ss(2)和ss(3),如图6所示。在当前描述的实施方式中,存在三个片段并且它们每个都是非重叠的。虽然这被认
为是最好的分段方案,但在其他实施方式中,随后的过程可能利用不同数量的可能重叠的片段。
[0113]
在方框13处,处理器检查是否所有三个片段ss(i)都已在下面的方框15和17中被处理。由于最初没有咳嗽音被处理,因此控制转移到方框15。
[0114]
在方框15,处理器53应用已知算法来确定与当前片段ss(i)相关的多个特征中的至少一个的特征值。在当前描述的实施方式中,计算的值如下:双谱分数(bgs)、非高斯分数(ngs)、前四个共振峰频率(ff)、对数能量(loge)、过零(zcr)、峰度(kurt)和十二个梅尔倒频谱系数(mfcc)。处理器53使用的算法包括组成应用程序56的指令的一部分,该指令记载在abeyratne,u.r.等人的cough sound analysis can rapidly diagnose childhood pneumonia(annals of biomedical engineering,2013.41(11):第2448-2462页),其公开内容通过引用整体并入本文。
[0115]
对于每个咳嗽片段ss(i),处理器在方框15处生成21个特征值,如下表2所示:
[0116][0117]
表2
[0118]
然后将意识到,在当前描述的实施方式中,为每一个咳嗽计算的特征值的总数是3(片段)x 21(每个片段的值) 13(每次总体咳嗽的小波特征)=总共76个特征。
[0119]
在方框17处,处理器53将当前片段的值存储到数据结构中,例如向量阵列,其驻留在存储器55的分配部分中并且包括表示咳嗽特征向量fc的分量的1
×
73实值阵列。
[0120]
一旦已经处理了当前咳嗽的所有片段,使得包括咳嗽特征向量fc的分量已经被填充了这些值,那么控制从决策方框13转移到方框21。如前所述,在方框21处,处理器53根据先前在方框4中捕获的呼吸频率(rr)和患者年龄数据计算呼吸指数bi。
[0121]
bi被定义为:
[0122]
bi=rr-20(如果年龄》=60个月)
[0123]
bi=rr-40(如果年龄《60)。
[0124]
因此,例如,如果年龄是45个月并且rr=60,那么
[0125]
bi=60-40=20
[0126]
对于年龄=45个月和rr=38,那么
[0127]
bi=38-40=-2
[0128]
优选的是,将针对所有特征捕获的所有值在群体中进行归一化。也就是说,在将特征值应用于分类器之前,一个特征(比如bi),通过给它一个类型的变换,使其均值和单位方差为零。任何要分类的新主题优选通过这些归一化方程进行处理。
[0129]
归一化特征=(特征-均值(特征))/标准_偏差(特征)
[0130]
先前引用的论文abeyratne,u.r.等人的cough sound analysis can rapidly diagnose childhood pneumonia(annals of biomedical engineering,2013.41(11):第2448-2462页)讨论了呼吸指数的发展。
[0131]
作为临床医生54直接输入呼吸频率的替代方案,在其他实施方式中,机器51可以被编程以获得呼吸频率的估计值。例如,机器51可以被编程,使得当机器被放置在患者的胸部时,它分析来自加速度计62的信号以确定呼吸频率。在另一个实施方式中,机器51被编程,使得当麦克风75放置在患者52的鼻部/嘴部下方时,处理器53检测来自患者的呼吸音并产生呼吸频率估计值。在另一个实施方式中,镜头和ccd组件59被定位成捕捉患者39的胸部上升和下降的图像,并且微处理器53被编程,以从图像中产生呼吸频率。
[0132]
在方框23处,处理器53形成存储在1x(76 1(bi) 13(wi))=1
×
90阵列数据结构中的测试向量t,该阵列数据结构驻留在存储器55的分配部分中。t包括fc咳嗽向量的所有76个分量以及对应于呼吸指数值bi的分量和在方框9计算的13个小波值。
[0133]
在方框25处,处理器53将测试向量t应用于逻辑回归模型(lrm)60形式的预训练的分类器,其根据包括应用程序56的指令实现。逻辑回归模型60已被训练以将测试向量t分类为表示多个哮喘严重程度之一。在当前描述的实施方式中,哮喘严重程度机器51将每个咳嗽分类为三个严重程度(即“轻度”、“中度”和“重度”)之一。用于训练lrm60的方法将在本说明书的后续部分中讨论。
[0134]
如前面简要提到的,在其他实施方式中,处理器53不执行方框4和21,从而不记录呼吸频率和患者年龄并且不计算呼吸指数。因此,测试向量t只包括通过处理咳嗽音和咳嗽音片段获得的特征。已经发现这样的实施方式在将患者咳嗽音视为指示患者哮喘严重程度的“轻度”或“中度至重度”之一时表现良好,但不用于指示哮喘严重程度的“轻度”、“中度”和“重度”之一。
[0135]
此外,在另一个实施方式中,方框13至17不是由处理器实现的。相反,测试向量t由单独的wi形成,用于区分“轻度”和“中度到重度”,或者由wi和bi值形成,用于区分“轻度”和“中度”以及“重度”。
[0136]
控制然后返回到方框7,重复已描述的过程,直到已被识别的所有咳嗽的所有片段都已被处理并测试了哮喘严重程度。一旦所有咳嗽音都已经被处理,控制就从决策方框7转移到方框27。
[0137]
在方框27,处理器53操作lcd触摸屏界面61以在机器51上生成屏幕14,如图7所示。屏幕14显示已被识别的每个咳嗽的严重程度等级,其考虑了呼吸指数。例如,1号咳嗽显示为具有“轻度”严重程度,3号咳嗽显示为具有“中度”严重程度。还显示了平均严重程度等级,例如平均严重程度等级“轻度”是所有咳嗽的平均严重程度。在这个特定的示例中,没有一个咳嗽被归类为“重度”,但这样的分类是可能的。
[0138]
现在将从临床病例定义的讨论开始讨论图2的lrm 60被预训练的方式。
[0139]
a)急性哮喘:发明人将急性哮喘定义为在对支气管扩张剂试验(bt)有反应的听诊期间,患有喘息或静默肺的儿童的呼吸事件。bt包括以下列剂量在1小时内通过垫片施用沙丁胺醇定量吸入器最多3次:《6岁儿童6喷,》6岁儿童12喷。
[0140]
b)无症状个体:该组被定义为在招募时根据临床判断确定为没有急性呼吸道疾病
0-1到ps≥5的模型训练和验证集。发明人使用留一交叉验证方法来开发和验证模型,其包括使用除一个之外的g1中所有患者的数据来训练模型,并使用其余患者的咳嗽事件来验证模型。该过程被系统地重复,以便将g1中的每个患者用作验证对象一次。lr是线性模型,它使用几个独立的特征来估计分类事件(因变量)的概率。当g1中有属于γ
5-9
的受试者时,发明人设置因变量y=1,否则设置y=0。给定独立输入特征(即f ca={f
0c
,f1,f2,
…ff
}),使用回归函数估计y的概率推导出模型:
[0156][0157]
z=β0 β1.f
0c
β2f2 β
n-1ff
ꢀꢀꢀ
(2)
[0158]
(1)中的函数给出了概率的连续输出。使用接收器操作曲线(roc)计算决策阈值,以确定给定受试者是否属于{γ
5-9
}或
[0159]
在一个实施方式中,提取输入咳嗽特征的方法总结如下:
[0160]
(i)令x表示来自任意咳嗽事件的离散时间声音信号。
[0161]
(ii)将x分为三个大小相等的非重叠片段。设xi表示x的第i个片段,其中i=1、2、3。从每个片段xi计算以下特征[12]:双谱分数(bgs)、非高斯分数(ngs)、前四个共振峰频率(ff)、对数能量(loge)、过零(zcr)、峰度(kurt)和十二个梅尔倒频谱系数(mfcc)。
[0162]
(iii)使用整个咳嗽事件x,基于morlet小波计算13个小波特征,如前所述[13]。
[0163]
从每个咳嗽事件中提取总共76个特征,形成特征向量fc。
[0164]
关于上面的ii)点,即将咳嗽事件分割成三个片段,现在将讨论以这种方式分割咳嗽的动机。发明人意识到咳嗽由几个生理阶段组成。最初,空气被吸入(吸气),然后声门闭合,在闭合处产生高压差(阶段1-3)。然后声门打开,导致空气快速迸发,产生听起来是咳嗽的声音。咳嗽(声音的主要巨响)被认为具有三个诊断上重要的子部分。上升部分,中间和尾部。在上升部分,声能从很小的水平(强度)开始产生,迅速上升到最大值附近;在中间部分,主要是向峰值能量较慢(较小)上升,然后从峰值水平再次较慢(较小)下降。在第三个组成部分(“尾部”)中,观察到了若干特征,例如缓慢、持续地衰减到较低的能级,有时会被第二次较小的巨响(可被称为“咳嗽-咕噜声”)打断。发明人在他们的研究程序中发现,与较少或更多数量的片段相比,将咳嗽分为三个片段并进行分析时,可以获得最佳的诊断结果。使用三个片段的决定是基于这种认识。
[0165]
此外,发明人以基于物理的考虑为指导。在咳嗽的主要巨响的前两片段,大部分声音是在上气道产生的。在咳嗽的尾部,在相对的上气道沉默的情况下,下气道响应的声学响应可以在不同的细节上被观察到。这并不是说发明人在前两个片段没有看到下气道特征,但咳嗽的尾端很可能会携带有关气道更深部分的信息。发明人惊讶地发现咳嗽中有“喘息”,据他们所知,没有其他研究人员以前报告过这样的发现。喘息通常是通过呼吸音(而不是咳嗽)来定义的。
[0166]
在哮喘中,由于平滑肌收缩,气道变窄,从而改变了气道的内部大小以及肌肉张力。当空气以一定的速度通过狭窄的气道时,狭窄的气道会产生回响,产生声音,所述声音具有足够强度的以到达肺部外部。较低的肺空气清除率会导致“更长”的咳嗽和更长的尾部。出于这个原因,咳嗽中也可能存在喘息(气道呼啸)。发明人对分段咳嗽的分析有助于捕捉那些,从而使发明人能够表征哮喘气道。发明人假设诸如肺气肿(导致慢性阻塞性肺病
(copd))之类的疾病会导致肺泡塌陷,肺泡是位于呼吸道最深端的小球形囊。肺失去弹性,影响部分“驱动”咳嗽的反冲(recoil)机制。发明人假设咳嗽的前部片段很可能携带关于此的信息。
[0167]
另一个与信号处理相关的考虑是该方法的实施方式涉及估计数学特征,例如mfcc、共振峰和双频谱。在计算之前将咳嗽分成多个片段有助于更好地保持信号的平稳性。
[0168]
然而,发明人还发现,该方法的较不优选的实施方式可以在没有分段的情况下工作。
[0169]
关于使用整个咳嗽事件x以基于morlet小波计算13个小波特征,不需要保持平稳性。非分割减少了必须处理的参数数量,也为小波提供了更好的机会来表示整个咳嗽信号。例如,当在整个咳嗽音上提取小波时,在一些实施方式中不需要执行分段。
[0170]
发明人使用几种不同的方法训练了lr模型。在最简单的形式中,发明人只使用咳嗽特征进行lr训练。为了研究单个临床子部分对总体临床ps的相对重要性(表1),发明人还使用rr、喘息严重程度和am作为单独输入开发了lr模型。最后,发明人使用从呼吸频率中获得的信息来增强咳嗽特征,因为即使在家庭环境中,患者或监护人也可以轻松报告这些信息。相反,am和喘息严重程度估计需要临床呼吸专业知识,并且外行无法报告。由于希望开发一种社区可部署的技术,发明人认为使用am或喘息严重程度来增强咳嗽功能没有任何意义。
[0171]
在lr模型中,发明人将rr转化为另一个特征,呼吸指数(bi)定义为[12]:对于60个月以上的年龄,bi=rr》20次呼吸/分钟,否则bi=rr》40次呼吸/分钟。这基于发明人从用于对资源贫乏地区的儿童肺炎进行分类的who/imci算法中汲取的灵感。众所周知,年幼儿童的规范rr高于年长儿童的规范rr,bi试图将其编入。在我们的模型中,根据ps评分系统将am的使用分为由经验丰富的临床医生确定的无、轻度增加、增加和最大活动(表1)。
[0172]
独立测试集(g2):
[0173]
一旦在留一交叉验证过程之后完成lr模型训练,按照[12]中的理念选择一个模型。发明人修复了该模型的参数并在迄今为止未使用的测试集上对其进行了测试:(n=164)代表患有中度疾病的受试者和临床上无明显疾病的个体。请注意,集合g1和g2是互斥的。g2的定义使得独立测试成为一项特别严格的测试。γ
2-4
中的受试者以前未经模型测试,中的受试者包括临床正常受试者,报告与训练集中的受试者不同的疾病/药物史。该算法分离具有在临床实践中难以辨别的相似疾病严重程度(即无疾病与轻度/中度)的病例的区分能力得益于一个事实,即第二次测试中使用的数据是迄今为止未经测试的数据。由于这些原因,下面列出的结果可能低估了已经参考图1讨论过的实施方式的真正的判别能力。
[0174]
结果
[0175]
研究人群:
[0176]
224名受试者被纳入分析,其中103名没有急性呼吸系统疾病,121名患有急性哮喘。表3描述了受试者的人口统计数据、咳嗽特征以及训练组和测试组的划分。没有ps》7的受试者被登记,因为他们符合医学不稳定的排除标准。发明人分析了总共3161次咳嗽发作。
[0177]
无症状组受试者的年龄总体上显著高于哮喘组(p《0.0001)。ps=0,1和ps 2-4的哮喘受试者之间没有年龄差异(p=0.45),ps=2-4和ps≥5的组之间也没有年龄差异(p=
0.15)。
[0178]
表3:受试者人口统计数据和咳嗽特征
[0179][0180][0181]
*g1(训练和验证集),
#
g2(独立测试集)
[0182]
训练集g1的留一验证结果(表4):
[0183]
仅基于咳嗽特征的lr模型能够将ps≥5的组与ps≤1的组区分开来,敏感性为82.61%,特异性为78.38%。结果表明,咳嗽音携带了用于分开这些ps组的信息。
[0184]
正如他们作为临床肺评分的组成部分所预期的那样,bi和am使用也独立地分开ps≥5和ps≤1的组。单独的bi获得了与单独的咳嗽分析相似的结果(敏感性69%,特异性81%)。向bi添加咳嗽特征将敏感性提高到91%,特异性提高到97%。am使用本身实现了100%的敏感性和94%的特异性,这并非通过添加咳嗽模型而得到增强。由于am使用在轻度哮喘中很少见,但在重度哮喘中总是存在,因此ps的这一组成部分在这种情况下表现良好也就不足为奇了。am使用需要相当多的临床专业知识来确定,因此在缺乏必要临床专业知识的社区环境中,作为估计ps的特征是不切实际的。由于希望以社区部署为目标,发明人没有看到根据am使用来区分疾病的严重程度的进一步的实用性。
[0185]
表4:训练集(g1)—将ps≥5的受试者与ps≤1的受试者分开的留一法验证结果。
[0186]
诊断特征敏感性%特异性%准确性%咳嗽82.6178.3880.00呼吸指数69.5781.0876.67辅助肌肉使用100.0094.5996.67呼吸指数 咳嗽91.3097.3095.00
[0187]
独立测试集g2结果:
[0188]
区分无疾病与轻度/中度疾病的能力是临床实践的一个组成部分,并且由于疾病严重程度的重叠而更加困难。为了研究lr模型在区分ps 0和ps 2-4(中度疾病)方面的性能,发明人选择了一个lr模型并在独立测试集g2上进行了测试。目的是检查(1)中训练的lr函数的连续输出是否与中度疾病的ps值有任何关系。两组不同的无症状受试者(ps=0)被汇集用于该分析(和),两者均未用于g1测试集。两个数据集的使用测试了算法的检测亚临床呼吸系统症状的判别能力。
[0189]
表5示出了所有ps值的lr输出(平均值和sd)。图1示出了每个测试模型的lr输出(平均值和95%ci)。尽管lr模型经过训练以将ps≥5的受试者与ps≤1的受试者分开,但其输出也对ps 2-4和无症状受试者和做出适当响应。
[0190]
表5:-不同ps值的逻辑回归模型的输出(平均值
±
sd)
[0191][0192]
仅咳嗽模型独立地区分轻度(ps 0-1)和中度(ps 2-4)的哮喘严重程度。然而,超过ps=5之后性能下降(表5)。
[0193]
然而,仅仅bi并不能区分ps 0-1和ps 2-4;它确实将组合的组ps 0-4与ps≥5区分开来。将bi添加到基于咳嗽的数学特征中可以清楚地区分ps 0-1、ps2-4和ps≥5三个组(图1)。
[0194]
仅am使用是区分ps《4的最佳单一临床参数,但是,在此水平以上无法区分。(表5,图1)。
[0195]
图8描绘了对于具有不同ps分数的受试者具有95%置信区间(水平条)的平均逻辑回归输出。ps值0(g1)、0(g2)、1、2、3、4、5、6、7、8、9处的数据点的个数为333、1040、147、387、476、422、233、54、69、0、0。ps=6和7的数据点的数量较少,导致置信区间(ci)较大。
[0196]
从图8可以看出,两个无症状组(ps=0:g1和g2)的lr输出之间没有发现差异。这两组在年龄上存在显著差异(平均差异22个月,se 7,p《0.0022),但lr输出对于仅咳嗽、仅临
床特征或组合的咳嗽和临床特征的模型没有差异。
[0197]
四、讨论
[0198]
来自224名患者的结果表明,咳嗽携带有关哮喘严重程度的有用信息。发明人开发了一种仅咳嗽模型,该模型准确反映了无哮喘、轻度哮喘和中度哮喘(ps 0-5)的儿童的ps。模型性能在大于ps 5时下降,需要原始ps的单个简化分量(呼吸频率)来校正。在严重哮喘中,气道阻塞可能会增加到几乎没有空气可以通过气道的程度,使得这些区域对于声学分析来说是相对不透明的。在这种情况下,听诊可能同样无法检测到喘息。这在原始ps中进行了说明,其中由于最小的空气交换而没有喘息的人获得最高分数。与咳嗽分析方法类似,ps量表被报告为与较小程度的气道阻塞更好地相关[9]。
[0199]
当咳嗽特征与不需要听诊或临床训练(喘息严重程度和am使用评估)的常规获得的临床特征相结合时,模型的性能在更高的ps值下显著提高。ps中的临床体征(rr、am使用)反映了呼吸努力,在更严重的阻塞中呼吸更努力,直到出现疲劳。将rr(作为bi)添加到算法中可以进一步将重度哮喘与中度和轻度哮喘区分;与特定治疗途径一致的重要病例区别[10]。因此,该算法被训练以识别:哮喘患者中寂静胸(不透明的声学特征)和显著升高的bi的组合表明气道阻塞水平增加。ps和算法在确定疾病严重程度时都考虑了bi中的年龄相关的变化性。
[0200]
分级急性哮喘严重程度是疾病管理的一个组成部分。临床护理方案依赖于准确的评估和评分系统,例如ps用于帮助决策,例如治疗开始和反应、临床监测水平、医院分诊/入院和出院计划等。然而,许多量表尚未得到充分评估,并且依赖于对诸如喘息特征和吸气/呼气喘息比率等体征的主观评价。对64项研究的系统评价得出结论:所有测试的儿童哮喘评分均未得到适当验证[7]。在学龄前儿童中也发现了类似的结论[8]。
[0201]
在临床上,相较于从轻度或无疾病区分中度疾病,从轻度加重区分重度加重更容易。实际上,确定增加的rr和am使用可准确识别重度加重,但这些迹象在诊断轻度疾病的存在时不太明确。轻度加重通常表现为rr的最小增加和没有am使用,留下喘息评估(一种需要大量专业知识的技术)作为治疗决策的唯一基础。此外,am使用的识别和分级需要临床培训,父母、护理人员或缺乏经验的临床医生无法使用。相比之下,本模型不需要输入中度疾病(ps 5以下)的附加临床体征,并且仅需要高于此水平的简单rr计数。
[0202]
比较两组无症状儿童(ps=0)。发明人希望确定无症状个体的算法检测性能是否存在明显差异。第一组由使用预防剂的具有慢性可控哮喘的儿童组成,而第二组包含一组以前有过喘息或从未喘息的儿童。确定组之间的lr输出没有差异,表明在发明人使用的人群中缺乏亚临床气道疾病的影响。
[0203]
这项研究有几个局限。与轻度和中度疾病相比,患有严重哮喘(ps》5)的受试者较少。
[0204]
由于主观性、有效性差、评分者间可靠性和可重复性,使用ps作为参考分类器存在固有问题。出于这个原因,发明人选择使用最高和最低严重程度数据来训练算法,然后在低敏度病例(ps《5)上测试开发的模型。由于这些组中的受试者数量较少,因此进行更广泛的研究并在可行的情况下根据气道阻塞的客观测量(包括fev1和pefr)评估该算法将是有益的。
[0205]
患有和不患有活动性疾病的受试者存在年龄差异,但患有轻度和中度或中度至重
度急性哮喘的受试者之间没有年龄差异。由于难以从两岁以下无症状儿童那里获得主动咳嗽,对照组受试者的年龄通常大于急性哮喘患者。然而,患有急性哮喘恶化的任何年龄的儿童都倾向于自发咳嗽。ps=0的两组(g1和g2)的年龄差异显著,但有趣的是lr输出没有差异,这表明年龄可能不是没有急性哮喘的儿童的重要变量。无哮喘的准确检测对临床护理和是否开始适当治疗的决定是重要的。
[0206]
ps和其他类似系统通常用于更年幼的儿童,尽管由于难以获得准确的肺功能参数而仅在年龄较大的群体中进行了验证。本文描述的实施方式可用于任何年龄(如果儿童自发咳嗽)和2-3岁(如果需要主动咳嗽)。这相比6-7岁年龄下限的肺活量测定或峰值流量测量是有利的,但是在比较不同年龄的明确定义的组方面仍然存在困难。
[0207]
本文的实施方式提供了一种自动化系统,该系统可以使用由应用程序的指令专门配置的智能手机的硬件来实现,以执行诸如图1所示的实施方式的方法。这提供了包括可访问性、便携性和易用性的优点,使它适用于家庭监测和与哮喘管理计划整合。许多学校和托儿中心推荐的哮喘管理计划要求护理人员能够根据他们对喘息特征的观察和对呼吸努力(rr和am使用)的评估,迅速评估严重程度。对于护理人员来说,测量呼吸频率比评估辅助肌肉使用程度或喘息程度更容易(表i)。本文提供的实施方式可以改善哮喘行动计划的启动和依从性,因为它只需要咳嗽和rr评估。
[0208]
此外,为了在传统医疗保健环境和社区哮喘行动计划中使用,有可能在远程医疗咨询中使用,在这期间临床医生没有机会进行检查。呼吸系统疾病占远程医疗咨询的30%以上[16]。rr的测量可以很容易地添加到基于咳嗽的模型中,因为它是客观的并且可以在视频会议期间由父母、社区医疗保健工作者或临床医生轻松计算。它在偏远地区的医疗中也很有价值,因为那里受过训练的临床人员非常有限。在这些地区,社区医疗保健工作者使用检测儿童肺炎的who算法已经很好地建立了测量呼吸频率的例行程序[17]。
[0209]
将观察到的是,在已经讨论过的实施方式中,分类器是使用由来自低严重程度(轻度)和最高严重程度(重度)患者的咳嗽音的特征组成的训练向量来训练的,但是训练后的分类器随后被用于仅对中度和低严重程度哮喘患者之间的仅咳嗽音数据(即排除呼吸指数值)进行分类。
[0210]
其一个原因是肺严重程度(ps)评分的临床评估是一项受主观性影响的艰巨任务。即使发现喘息,临床医生也很难彼此达成一致。因此,发明人将参考ps本身视为受人与人之间的差异影响的总指数,因此试图准确估计ps是没有用的。发明人认为重要的是能够从中度 重度ps中区分轻度,这在临床上是最有用和最困难的。发明人没有尝试使用连续的ps分数来训练模型,而是认为最好在训练中使用极值(即重度极值和轻度极值),而将中度分量留在后面。通过这种方式,发明人能够在ps的两个极端之间创建一个
*
可靠的
*
区域。由于ps估计的临床困难,轻度和重度组不太可能相互混合,因此可以更加信任它们。相比之下,由于临床不确定性的数量,轻度和中度组可以更加相互混合,中度和重度组也是如此。因此,发明人按极值进行了训练。较高的逻辑输出分数意味着它将是重度的ps,而更接近0的较小输出表明它是另一端。然后,发明人检查了他们是否已经建立了在中度区域也可以工作的量表,并且发现它可以工作,这是一个重要的发现。
[0211]
从前面的讨论中可以理解,发明人已经设想咳嗽带有关于哮喘严重程度的重要信息。在实施方式中,自动化咳嗽分析单独地将轻度和中度疾病分开,在另一个实施方式中,
analysis for rapid childhood pneumonia diagnosis.ieee trans on biomed eng.,2015.62(4):p.1185-1194.
[0227]
14.sharan,r.v.,et al.,cough sound analysis for diagnosing croup in pediatric patients using biologically inspired features.conf proc ieee eng med biol soc,2017.2017:p.4578-4581.
[0228]
15.sharan,r.v.,et al.,automatic croup diagnosis using cough sound recognition.ieee trans biomed eng,2018.
[0229]
16.uscher-pines,l.and a.mehrotra,analysis of teladoc use seems to indicate expanded access to care for patients without prior connection to a provider.health aff(millwood),2014.33(2):p.258-64.
[0230]
17.world health organization,integrated management of childhood illness:chart booklet.2014:geneva,switzerland.
[0231]
缩略语列表
[0232]
ps肺评分
[0233]
am:辅助肌肉
[0234]
wa:西澳大利亚州
[0235]
lr:逻辑回归
[0236]
ci:置信区间
[0237]
sd:标准偏差
[0238]
bi:呼吸指数
[0239]
rr:呼吸频率
[0240]
pefr:峰值呼气流速
[0241]
fev1:一秒用力呼气量
[0242]
虽然用于测试和训练的优选特征集如表2所示,但发明人发现如下减少的特征集也是可行的:
[0243]
表6:减少的特征集
[0244]
[0245][0246]
在表6中,krt是“峰度”的缩写,mfccn是“第n个mfcc”的缩写,wvl是小波的缩写。
[0247]
术语
[0248]
本文使用的条件语言,例如“可以”、“可能”、“例如”等,除非另有明确说明,或在所使用的上下文中以其他方式理解,通常旨在传达某些实施方式包括,而其他实施方式不包括某些特征、元素和/或状态。因此,这种条件性语言通常不旨在暗示:特征、元素和/或状态以任何方式对于一个或多个实施方式是必需的,或者一个或多个实施方式必然包括用于在有或没有作者输入或提示的情况下决定是否这些特征、元素和/或状态被包括在任何特定实施方式中或将在任何特定实施方式中被执行的逻辑。
[0249]
取决于实施方式,本文描述的方法中的任一项的某些动作、事件或功能可以以不同的顺序执行,可以被添加、合并或完全省略(例如,并非所有描述的动作或事件都是实践方法所必须的)。此外,在某些实施方式中,动作或事件可以同时执行(例如通过多线程处理、中断处理或多个处理器或处理器核心),而不是顺序执行。
[0250]
结合本文公开的实施方式描述的各种说明性逻辑块、模块、电路和算法步骤可以实现为电子硬件、计算机软件或两者的组合。为了清楚地说明硬件和软件的这种可互换性,各种说明性组件、块、模块、电路和步骤已经在上面大体上根据它们的功能进行了描述。这种功能实现为硬件还是软件取决于特定应用和施加在整个系统上的设计约束。所描述的功能可以针对每个特定应用以不同的方式实现,但是这样的实现决策不应被解释为导致偏离本公开的范围。
[0251]
结合本文公开的实施方式描述的各种说明性逻辑块、模块和电路可以用通用处理器、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)或其他可编程逻辑器件、分立门或晶体管逻辑、分立硬件组件或设计用于执行本文所述功能的任何组合来实现或执行。通用处理器可以是微处理器,但替代地,处理器可以是任何常规处理器、控制器、微控制器或状态机。处理器还可以实现为计算设备的组合,例如,dsp和微处理器的组
合、多个微处理器、一个或多个微处理器与dsp核心结合,或任何其他这样的配置。此外,处理器可以是包含多个处理核心的分立集成电路,也可以是布置成相互通信以协作完成处理任务的多个分立集成电路。
[0252]
结合本文所公开的实施方式描述的方法和算法的块可以直接体现在硬件中,体现在由处理器执行的软件模块中,或者体现在两者的组合中。软件模块可以驻留在ram存储器、闪存、rom存储器、eprom存储器、eeprom存储器、寄存器、硬盘、可移动磁盘、cd-rom或本领域已知的任何其他形式的计算机可读存储介质中。示例性存储介质耦合到处理器,使得处理器可以从存储介质读取信息以及将信息写入存储介质。替代地,存储介质可以集成到处理器中。处理器和存储介质可以驻留在asic中。asic可以驻留在用户终端中。替代地,处理器和存储介质可以作为分立组件驻留在用户终端中。
[0253]
本文描述的某些实施方式的任何模块可以被实现为软件模块、硬件模块或其组合。一般而言,如本文所用,词语“模块”可以指代体现在硬件或固件中的逻辑,或指代在处理器上可执行的软件指令的集合。此外,在一些实施方式中,模块或其组件可以在模拟电路中实现。
[0254]
尽管以上详细描述已经显示、描述和指出了应用于各种实施方式的新颖特征,但是应当理解,可以在不背离本公开的精神的情况下,进行所示装置或算法的形式和细节上的各种省略、替换和改变。如将认识到的,本文描述的本发明的某些实施方式可以在不提供本文阐述的所有特征和益处的形式内实现,因为一些特征可以独立于其他特征使用或实践。本文公开的某些发明的范围由所附权利要求而不是由前述描述指示。在权利要求的等效含义和范围内的所有变化都应包含在其范围内。
[0255]
根据法规,本发明已经用或多或少特定于结构或方法特征的语言进行了描述。术语“包括”及其变体,例如“包括”和“由...组成”自始至终以包容的方式使用,而不是排除任何附加特征。
[0256]
应当理解,本发明不限于所示出或描述的特定特征,因为本文描述的手段包括使本发明生效的优选形式。因此,在本领域技术人员适当解释的所附权利要求的适当范围内,本发明以其任何形式或修改被要求保护。
[0257]
在整个说明书和权利要求书(如果存在)中,除非上下文另有要求,否则术语“基本上”或“大约”将被理解为不限于由这些术语限定的范围的值。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。